|
libmdbx 0.14.2.310 (2026-07-15T12:48:43+03:00)
One of the fastest compact embeddable key-value ACID storage engine without WAL.
|
|
libmdbx 0.14.2.310 (2026-07-15T12:48:43+03:00)
One of the fastest compact embeddable key-value ACID storage engine without WAL.
|
For the most part, this section is a copy of the corresponding text from LMDB description, but with some edits reflecting the improvements and enhancements were made in MDBX.
MDBX is a Btree-based database management library modeled loosely on the BerkeleyDB API, but much simplified. The entire database (aka "environment") is exposed in a memory map, and all data fetches return data directly from the mapped memory, so no malloc's or memcpy's occur during data fetches. As such, the library is extremely simple because it requires no page caching layer of its own, and it is extremely high performance and memory-efficient. It is also fully transactional with full ACID semantics, and when the memory map is read-only, the database integrity cannot be corrupted by stray pointer writes from application code.
The library is fully thread-aware and supports concurrent read/write access from multiple processes and threads. Data pages use a copy-on-write strategy so no active data pages are ever overwritten, which also provides resistance to corruption and eliminates the need of any special recovery procedures after a system crash. Writes are fully serialized; only one write transaction may be active at a time, which guarantees that writers can never deadlock. The database structure is multi-versioned so readers run with no locks; writers cannot block readers, and readers don't block writers.
Unlike other well-known database mechanisms which use either write-ahead transaction logs or append-only data writes, MDBX requires no maintenance during operation. Both write-ahead loggers and append-only databases require periodic checkpointing and/or compaction of their log or database files otherwise they grow without bound. MDBX tracks retired/freed pages within the database and re-uses them for new write operations, so the database size does not grow without bound in normal use. It is worth noting that the "next" version libmdbx (MithrilDB and Future) will solve this problem.
The memory map can be used as a read-only or read-write map. It is read-only by default as this provides total immunity to corruption. Using read-write mode offers much higher write performance, but adds the possibility for stray application writes thru pointers to silently corrupt the database. Of course if your application code is known to be bug-free (...) then this is not an issue.
If this is your first time using a transactional embedded key-value store, you may find the Getting started section below to be helpful.
For now please refer to chapter of "BoltDB comparison with other databases" which is also (mostly) applicable to libmdbx with minor clarification:
libmdbx is superior to legendary LMDB in terms of features and reliability, not inferior in performance. In comparison to LMDB, libmdbx make things "just work" perfectly and out-of-the-box, not silently and catastrophically break down. The list below is pruned down to the improvements most notable and obvious from the user's point of view.
For DB with default page size libmdbx support keys up to 2022 bytes and up to 32742 bytes for 64K page size. LMDB allows key size up to 511 bytes and may silently loses data with large values.
Benchmarks of the in-tmpfs scenarios, that tests the speed of the engine itself, showned that libmdbx 10-20% faster than LMDB, and up to 30% faster when libmdbx compiled with specific build options which downgrades several runtime checks to be match with LMDB behaviour.
However, libmdbx may be slower than LMDB on Windows, since uses native file locking API. These locks are really slow, but they prevent an inconsistent backup from being obtained by copying the DB file during an ongoing write transaction. So I think this is the right decision, and for speed, it's better to use Linux, or ask Microsoft to fix up file locks.
Noted above and other results could be easily reproduced with ioArena just by make bench-quartet command, including comparisons with RockDB and WiredTiger.
libmdbx manages the database size according to parameters specified by mdbx_env_set_geometry() function, ones include the growth step and the truncation threshold.
Unfortunately, on-the-fly database size adjustment doesn't work under Wine due to its internal limitations and unimplemented functions, i.e. the MDBX_UNABLE_EXTEND_MAPSIZE error will be returned.
During each commit libmdbx merges a freeing pages which adjacent with the unallocated area at the end of file, and then truncates unused space when a lot enough of.
libmdbx database format depends only on the endianness but not on the bitness.
LIFO means that for reuse will be taken the latest becomes unused pages. Therefore the loop of database pages circulation becomes as short as possible. In other words, the set of pages, that are (over)written in memory and on disk during a series of write transactions, will be as small as possible. Thus creates ideal conditions for the battery-backed or flash-backed disk cache efficiency.
libmdbx performs a rough estimate based on common B-tree pages of the paths from root to corresponding keys.
libmdbx provides a lot of information, including dirty and leftover pages for a write transaction, reading lag and holdover space for read transactions.
libmdbx allows one at once with getting previous value and addressing the particular item from multi-value with the same key. libmdbx support massive deletion by bunches of adjacent elements much faster by cutting off entire pages and branches from a B-tree.
libmdbx propose additional trade-off by MDBX_SAFE_NOSYNC with append-like manner for updates, that avoids database corruption after a system crash contrary to LMDB. Nevertheless, the MDBX_UTTERLY_NOSYNC mode is available to match LMDB's behaviour for MDB_NOSYNC.
In addition to those listed for some functions.
Avoid long-lived read transactions, especially in the scenarios with a high rate of write transactions. Long-lived read transactions prevents recycling pages retired/freed by newer write transactions, thus the database can grow quickly.
Understanding the problem of long-lived read transactions requires some explanation, but can be difficult for quick perception. So is is reasonable to simplify this as follows:
A good example of long readers is a hot backup to the slow destination or debugging of a client application while retaining an active read transaction. LMDB this results in MDB_MAP_FULL error and subsequent write performance degradation.
libmdbx mostly solve "long-lived" readers issue by offering to use a transaction parking-and-ousting approach by mdbx_txn_park(), Handle-Slow-Readers MDBX_hsr_func callback which allows to abort long-lived read transactions, and using the MDBX_LIFORECLAIM mode which addresses subsequent performance degradation. The "next" version of libmdbx (aka MithrilDB and Future) will completely solve this.
Nonetheless, situations that encourage lengthy read transactions while intensively updating data should be avoided. For example, you should avoid suspending/blocking processes/threads performing read transactions, including during debugging, and use transaction parking if necessary.
You should also beware of aborting processes that perform reading transactions. Despite the fact that libmdbx automatically checks and cleans readers, as an a process aborting (especially with core dump) can take a long time, and checking readers cannot be performed too often due to performance degradation.
This issue will be addressed in MithrilDB and one of libmdbx releases. To do this, nonsequential GC recycling will be implemented, without stopping garbage recycling on the old MVCC snapshot used by a long read transaction.
After the planned implementation, any long-term reading transaction will still keep the used MVCC-snapshot (all the database pages forming it) from being recycled, but it will allow all unused MVCC snapshots to be recycled, both before and after the readable one. This will eliminate one of the main architectural flaws inherited from LMDB and caused the growth of a database in proportion to a volume of data changes made concurrently with a long-running read transaction.
libmdbx allows you to store values up to 1 gigabyte in size, but this is not the main functionality for a key-value storage, but an additional feature that should not be abused. Such long values are stored in consecutive/adjacent DB pages, which has both pros and cons. This allows you to read long values directly without copying and without any overhead from a linear section of memory.
On the other hand, when putting such values in the database, it is required to find a sufficient number of free consecutive/adjacent database pages, which can be very difficult and expensive, moreover sometimes impossible since b-tree tends to fragmentation. So, when placing very long values, the engine may need to process the entire GC, and in the absence of a sufficient sequence of free pages, increase the DB file. Thus, for long values, libmdbx provides maximum read performance at the expense of write performance.
Some aspects related to GC have been refined and improved in 2022 within the first releases of the 0.12.x series. In particular the search for free consecutive/adjacent pages through GC has been significantly speeded, including acceleration using NOEN/SSE2/AVX2/AVX512 instructions.
This issue will be addressed in MithrilDB and refined within one of 0.15.x libmdbx releases.
A similar situation can be with huge transactions, in which a lot of database pages are retired. The retired pages should be put into GC as a list of page numbers for future reuse. But in huge transactions, such a list of retired page numbers can also be huge, i.e. it is a very long value and requires a long sequence of free pages to be saved. Thus, if you delete large amounts of information from the database in a single transaction, libmdbx may need to increase the database file to save the list of pages to be retired.
This issue was fixed in 2022 within the first releases of the 0.12.x series by Big Foot feature, which now is enabled by default. See MDBX_ENABLE_BIGFOOT build-time option.
The Big Foot feature which significantly reduces GC overhead for processing large lists of retired pages from huge transactions. Now libmdbx avoid creating large chunks of PNLs (page number lists) which required a long sequences of free pages, aka large/overflow pages. Thus avoiding searching, allocating and storing such sequences inside GC.
An libmdbx database configuration will often reserve considerable unused memory address space and maybe file size for future growth. This does not use actual memory or disk space, but users may need to understand the difference so they won't be scared off.
However, on 64-bit systems with a relative small amount of RAM, such reservation can deplete system resources (trigger ENOMEM error, etc) when setting an inadequately large upper DB size using mdbx_env_set_geometry() or mdbx::env::geometry. So just avoid this.
Do not use libmdbx databases on remote filesystems, even between processes on the same host. This breaks file locks on some platforms, possibly memory map sync, and certainly sync between programs on different hosts.
On the other hand, libmdbx support the exclusive database operation over a network, and cooperative read-only access to the database placed on a read-only network shares.
Do not use opened MDBX_env instance(s) in a child processes after fork(). It would be insane to call fork() and any MDBX-functions simultaneously from multiple threads. The best way is to prevent the presence of open MDBX-instances during fork().
The MDBX_ENV_CHECKPID build-time option, which is ON by default on non-Windows platforms (i.e. where fork() is available), enables PID checking at a few critical points. But this does not give any guarantees, but only allows you to detect such errors a little sooner. Depending on the platform, you should expect an application crash and/or database corruption in such cases.
On the other hand, libmdbx allow calling mdbx_env_close() in such cases to release resources, but no more and in general this is a wrong way.
Starting from the v0.13.1 release, the mdbx_env_resurrect_after_fork() is available, which allows you to reuse an already open database environment in child processes, but strictly without inheriting any transactions from a parent process.
There is no pure read-only mode in a normal explicitly way, since readers need write access to LCK-file to be ones visible for writer.
So libmdbx always tries to open/create LCK-file for read-write, but switches to without-LCK mode on appropriate errors (EROFS, EACCESS, EPERM) if the read-only mode was requested by the MDBX_RDONLY flag which is described below.
A thread can only use one transaction at a time, plus any nested read-write transactions in the non-writemap mode. Each transaction belongs to one thread. The MDBX_NOSTICKYTHREADS flag changes this, see below.
Do not start more than one transaction for a one thread. If you think about this, it's really strange to do something with two data snapshots at once, which may be different. libmdbx checks and preventing this by returning corresponding error code (MDBX_TXN_OVERLAPPING, MDBX_BAD_RSLOT, MDBX_BUSY) unless you using MDBX_NOSTICKYTHREADS option on the environment. Nonetheless, with the MDBX_NOSTICKYTHREADS option, you must know exactly what you are doing, otherwise you will get deadlocks or reading an alien data.
Starting from the v0.13.1 release, the mdbx_env_resurrect_after_fork() is available, which allows you to reuse an already open database environment in child processes, but strictly without inheriting any transactions from a parent process.
Do not have open an libmdbx database twice in the same process at the same time. By default libmdbx prevent this in most cases by tracking databases opening and return MDBX_BUSY if anyone LCK-file is already open.
The reason for this is that when the "Open file description" locks (aka OFD-locks) are not available, libmdbx uses POSIX locks on files, and these locks have issues if one process opens a file multiple times. If a single process opens the same environment multiple times, closing it once will remove all the locks held on it, and the other instances will be vulnerable to corruption from other processes.
For compatibility with LMDB which allows multi-opening, libmdbx can be configured at runtime by mdbx_setup_debug(MDBX_DBG_LEGACY_MULTIOPEN, ...) prior to calling other libmdbx functions. In this way libmdbx will track databases opening, detect multi-opening cases and then recover POSIX file locks as necessary. However, lock recovery can cause unexpected pauses, such as when another process opened the database in exclusive mode before the lock was restored - we have to wait until such a process releases the database, and so on.
Within libmdbx, this file is always cleared when the first process starts working with the database. Therefore, in any cases of damage to a LCK-file, it is enough to close a database in all processes using it, or stop all such processes before further restart.
A broken LCK-file can cause sync issues, including appearance of wrong/inconsistent data for readers. When database opened in the cooperative read-write mode the LCK-file requires to be mapped to memory in read-write access. In this case it is always possible for stray/malfunctioned application could writes thru pointers to silently corrupt the LCK-file. There is no any portable way to prevent such corruption, since the LCK-file is updated concurrently by multiple processes in a lock-free manner and any locking is unwise due to a large overhead.
Stale reader transactions left behind by an aborted program cause further writes to grow the database quickly, and stale locks can block further operation. libmdbx checks for stale readers while opening environment and before growth the database.
Stale writers will be cleared automatically by libmdbx. However this is platform-specific, especially of implementation of shared POSIX-mutexes and support for robust mutexes. For now there are no known issues on all supported platforms.
Over the past 10 years, libmdbx has had a lot of significant improvements and innovations. libmdbx has become a slightly faster in simple cases and many times faster in complex scenarios, especially with a huge transactions in gigantic databases. Therefore, on the one hand, the results below are outdated. However, on the other hand, these simple benchmarks are evident, easy to reproduce, and are close to the most common use cases.
The following all benchmark illustrative results were obtained in 2015 by IOArena and multiple scripts runs on my laptop (i7-4600U 2.1 GHz, SSD MZNTD512HAGL-000L1).
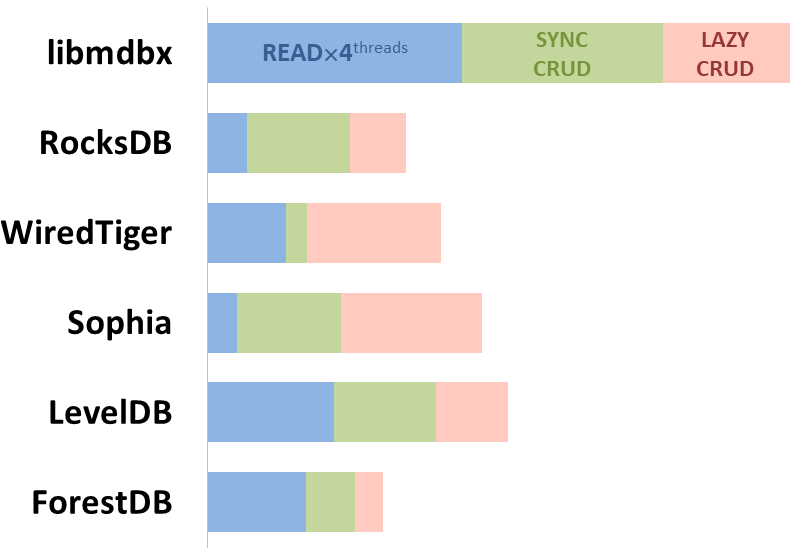
Here showed sum of performance metrics in 3 benchmarks:
Reasons why asynchronous mode isn't benchmarked here:
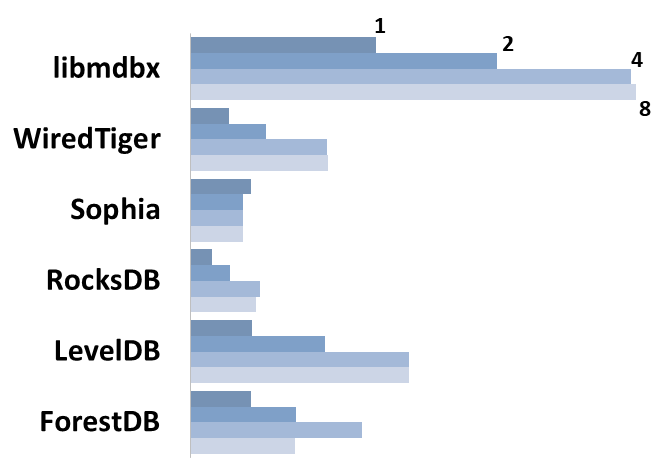
Summary performance with concurrent read/search queries in 1-2-4-8 threads on the machine with 4 logical CPUs in HyperThreading mode (i.e. actually 2 physical CPU cores).
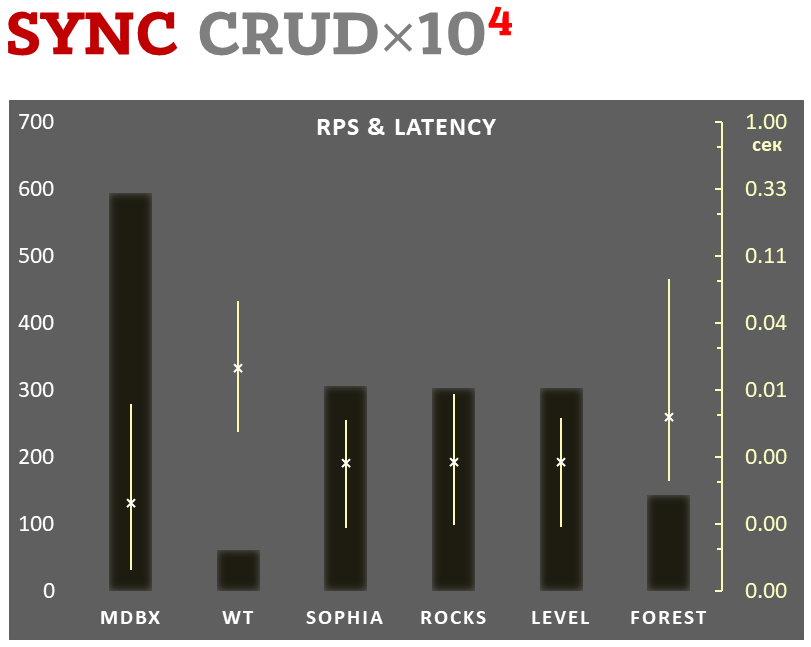
10,000 transactions in sync-write mode. In case of a crash all data is consistent and conforms to the last successful transaction. The fdatasync syscall is used after each write transaction in this mode.
In the benchmark each transaction contains combined CRUD operations (2 inserts, 1 read, 1 update, 1 delete). Benchmark starts on an empty database and after full run the database contains 10,000 small key-value records.
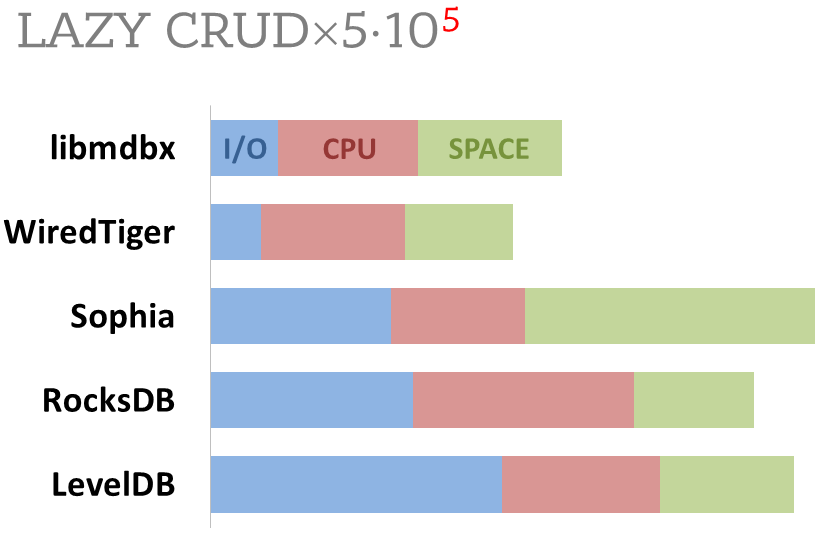
100,000 transactions in lazy-write mode. In case of a crash all data is consistent and conforms to the one of last successful transactions, but transactions after it will be lost. Other DB engines use WAL or transaction journal for that, which in turn depends on order of operations in the journaled filesystem. libmdbx doesn't use WAL and hands I/O operations to filesystem and OS kernel (mmap).
In the benchmark each transaction contains combined CRUD operations (2 inserts, 1 read, 1 update, 1 delete). Benchmark starts on an empty database and after full run the database contains 100,000 small key-value records.
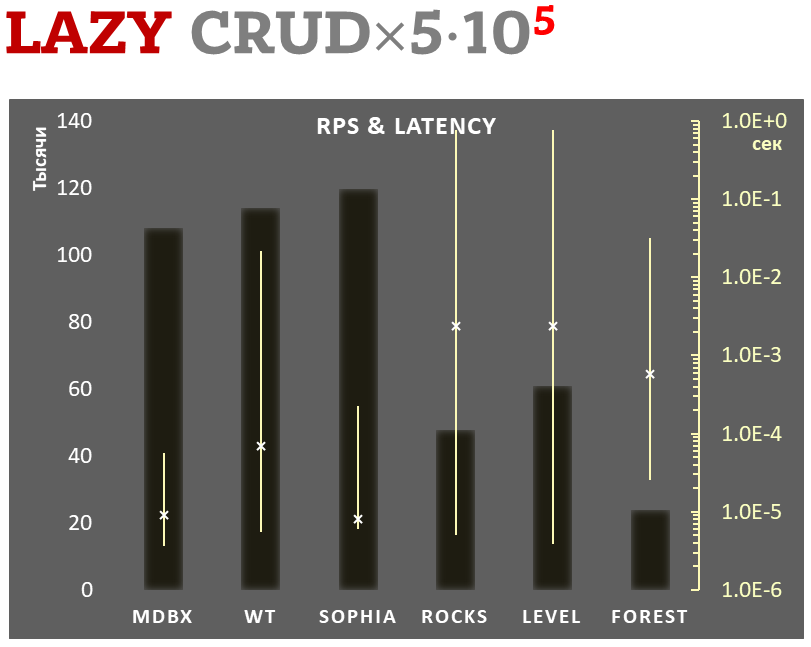
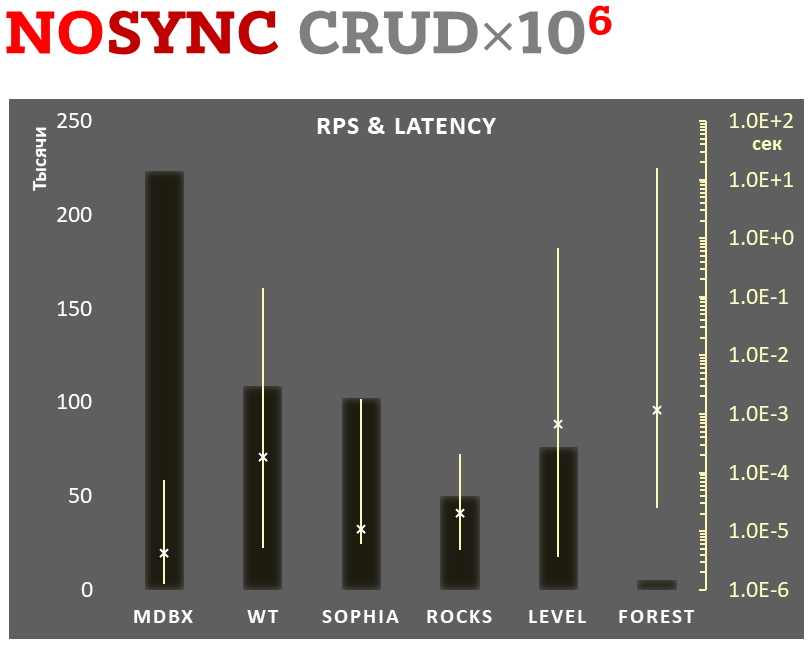
1,000,000 transactions in async-write mode. In case of a crash all data is consistent and conforms to the one of last successful transactions, but lost transaction count is much higher than in lazy-write mode. All DB engines in this mode do as little writes as possible on persistent storage. libmdbx uses msync(MS_ASYNC) in this mode.
In the benchmark each transaction contains combined CRUD operations (2 inserts, 1 read, 1 update, 1 delete). Benchmark starts on an empty database and after full run the database contains 10,000 small key-value records.
Summary of used resources during lazy-write mode benchmarks:
ForestDB is excluded because benchmark showed it's resource consumption for each resource (CPU, IOPs) much higher than other engines which prevents to meaningfully compare it with them.
All benchmark data is gathered by getrusage() syscall and by scanning the data directory.