libmdbx (2021-01-29 ... 2021-06-08)
Previous messages



 Next messages
Next messages
29 January 2021
AV
16:57
Artem Vorotnikov
во время их выполнения мой рантайм растаскивает логические треды по системным как ему вздумается - при этом код в корутине выполняется последовательно, строчка за строчкой
Л(
16:57
Леонид Юрьев (Leonid Yuriev)
@vorot93, если вам необходимо работать с БД только из одного "растового" процесса, то можно сделать так:
- открывать БД в эксклюзивном режиме, т.е. другие процессы не смогут с ней работать.
- добавить в libmdbx дополнительную функцию открытия БД с предоставлением callback-ов для замены mutex-ов.
- открывать БД в эксклюзивном режиме, т.е. другие процессы не смогут с ней работать.
- добавить в libmdbx дополнительную функцию открытия БД с предоставлением callback-ов для замены mutex-ов.
17:05
In reply to this message
Во всех приличных фрейворках есть возможность на время монополизировать использование треда (иначе просто беда с любым внешним кодом).
Это _должно_ быть в rust, тогда достаточно "пиннить" текущий тред перед стартом пишущей транзакции и "отпиннивать" после завершения.
Технически это может выглядеть и называть по-разному. Например, изъятие треда из пула и возврат назад, и т.п.
Это _должно_ быть в rust, тогда достаточно "пиннить" текущий тред перед стартом пишущей транзакции и "отпиннивать" после завершения.
Технически это может выглядеть и называть по-разному. Например, изъятие треда из пула и возврат назад, и т.п.
AV
17:23
Artem Vorotnikov
In reply to this message
В расте (а точне, во фреймворке Tokio, который де факто стандарт) можно или запустить корутину на общем многопоточном экзекьюторе (только если она
https://doc.rust-lang.org/nomicon/send-and-sync.html
Send, то бишь все структуры внутри неё можно двигать между потоками), или запустить прибитой к треду от начала и до конца (но можно даже если `!Send`). Динамически прикрепить и открепить нельзя, потому что это риск UB из безопасного кода.https://doc.rust-lang.org/nomicon/send-and-sync.html
Л(
17:27
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Тогда два варианта:
1. Запускать работающие с _пишущими_ транзакциями короутины на отдельном треде.
В целом этом 100% логично, так как пишущие транзакции и операции внутри них строго сериализуются (т.е. строго последовательны).
2. Костылить:
- открывать БД в эксклюзивном режиме, т.е. другие процессы не смогут с ней работать.
- добавить в libmdbx дополнительную функцию открытия БД с предоставлением callback-ов для замены mutex-ов
1. Запускать работающие с _пишущими_ транзакциями короутины на отдельном треде.
В целом этом 100% логично, так как пишущие транзакции и операции внутри них строго сериализуются (т.е. строго последовательны).
2. Костылить:
- открывать БД в эксклюзивном режиме, т.е. другие процессы не смогут с ней работать.
- добавить в libmdbx дополнительную функцию открытия БД с предоставлением callback-ов для замены mutex-ов
NK
17:42
Noel Kuntze
Please add a way to build the original source code without it being in a git repo, so one can use the zip and tar gz archive links of github and still use the tests
17:43
I'd rather not fiddle around with the source again and make all the metadata the Makefile pulls from the git repo settable via the args
AV
17:44
Artem Vorotnikov
In reply to this message
хм, т.е. вариант открыть в эксклюзивном режиме и вместо мутекса подставить пустышку?
Л(
18:03
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Please fill an issue at github if you needed this.
However, so far I don't see any sense in this, because:
- if necessary, you can independently package the entire git repo in tarball.
- git allows you to limit the depth when cloning to reduce overhead.
Nonetheless, I will accept a PR if you implement (for instance) such make-target.
However, so far I don't see any sense in this, because:
- if necessary, you can independently package the entire git repo in tarball.
- git allows you to limit the depth when cloning to reduce overhead.
Nonetheless, I will accept a PR if you implement (for instance) such make-target.
NK
18:03
Noel Kuntze
It's for building a distribution package
18:04
And for obvious reasons there shouldn't be a need to make an extra tarball of the sources to provide to the build mechanism if the source is already available as a tar ball, although without the git archive
18:05
If a package is built from a git repo, it has to have the suffix -git in it and that implies it's unstable
Л(
18:05
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Ну не пустышку, а методы объекта, который вы будете использовать для серилизации/упорядочевания пишущих транзакцию внутри rust-процесса.
NK
18:06
Noel Kuntze
(because the grand majority of the packages that are sourced from git directly, without a tarball, generate specific package versions depending on the current git head in order to version the package)
18:06
(Because otherwise there's no proper versioning between two builts from the same repo at different times and with different contents, but the same build rules/scripts)
18:07
It's been common practice to build from git repos by fetching the tar balls at certain versions and checking their checksum
18:07
the tar ball then doesn't contain the .git folder
18:08
So commonly, the git history of a piece of software is not availabe at build time (because it's not needed, because there's no special versioning required when the release itself is already properly named. E.g. v0.9.2)
Л(
18:08
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Ok. Please file the issue with rationale as you described here.
I'll think about doing it when I have the time.
I'll think about doing it when I have the time.
NK
18:09
Noel Kuntze
At least the Alpine devs will (probably) refuse to accept the package if I just point it at the head or a tagged release because it's a git repo and we can't easily checksum that, AFAIK
18:09
(Reason being the existing automated code for verifying the checksum likely doesn't have the special case of checking a whole git repo)
NK
19:45
Noel Kuntze
When building from source, libmdbx just got a runtime dependency on libgcc_s.so. Do you know from the top of your head if that's normal or if I just forgot to turn of debug building?
19:45
I passed -DNODEBUG=1 via CFLAGS just in case
Л(
19:54
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Nope.
This only depends on the compiler (i.e. GCC) and how it is configured to and implements support the target platform.
For instance, the
In addition, if the library was built with support for a new interface for C++, then there will be a dependency on the C++ runtime, which in turn may have a dependency on
This only depends on the compiler (i.e. GCC) and how it is configured to and implements support the target platform.
For instance, the
libgcc_s.so may contain long division functions, support for C11 atomics, etc...In addition, if the library was built with support for a new interface for C++, then there will be a dependency on the C++ runtime, which in turn may have a dependency on
libgcc_s.so.
30 January 2021
AS
06:03
Alex Sharov
In reply to this message
Вообще это одна из полезных фич: не останавливая процесса, поковыряться в его базе снаружи, позапускать аналитику, погрепать, ...
06:05
Концептуально не имеет большого смысла делать пишущие транзакции на work-stealing пуле, потому что: пишущая транзакция всегда только одна.
06:08
Подумай - может имеет смысл прямо в типах реализовать тот факт что пишущая транзакция всегда только одна, а не претворяться что пишущие транзакции не отличаются от читающих.
06:22
Это наложит на приложение определенные good practices ограничения - возможно это хорошо
06:31
Еще: под нагрузкой - количество читающих транзакций будет ограниченно
mdbx_env_set_maxreaders. Не знаю проблема это или нет.
2 February 2021
Л(
02:32
Леонид Юрьев (Leonid Yuriev)
В ветке
Заинтересованным предлагается поучаствовать в тестировании = для этого достаточно запустить сценарий
Пару слов об этом тестовом сценарии:
- "из каробки" поддерживаются Darwin (MacOS/iOS), FreeBSD и Linux, а для прочих ОС требуется правки скрипта по-месту (для Windows рекомендуется создание RAMDISK).
- сценарий не предполагает фиксированного времени выполнения (потенциально может работать несколько лет), но де-факто завершится либо из-за нехватки ОЗУ, либо достижения лимитов установленных по-умолчанию (размер списка грязных страниц и т.п.).
- предлагается запустить скрипт на 1-N суток и предоставить логи когда он завершиться из-за какой-то ошибки.
devel на github завершен ряд доработок, см. https://github.com/erthink/libmdbx/blob/devel/ChangeLog.mdЗаинтересованным предлагается поучаствовать в тестировании = для этого достаточно запустить сценарий
./test/long_stochastic.sh находясь в корне git repo.Пару слов об этом тестовом сценарии:
- "из каробки" поддерживаются Darwin (MacOS/iOS), FreeBSD и Linux, а для прочих ОС требуется правки скрипта по-месту (для Windows рекомендуется создание RAMDISK).
- сценарий не предполагает фиксированного времени выполнения (потенциально может работать несколько лет), но де-факто завершится либо из-за нехватки ОЗУ, либо достижения лимитов установленных по-умолчанию (размер списка грязных страниц и т.п.).
- предлагается запустить скрипт на 1-N суток и предоставить логи когда он завершиться из-за какой-то ошибки.
Л(
20:39
Леонид Юрьев (Leonid Yuriev)
Would you like get the next release now or wait for a more features?
Anonymous poll
- Release now 3 votes, chosen vote
- Wait for a features from the TODO list
3 votes
NK
21:06
Noel Kuntze
Release often please. That way distros don't need to make and apply patches in between, but can just point the source URL at the newest tarball
21:06
It saves 15 to 60 minutes per release
21:06
(because you need to check if the package afterwards still builds fine manually
21:06
)
21:07
(Also, it looks much cleaner)
21:08
It's also better for new users/developers, because the newest release will include the most bugfixes. Otherwise they first need to go over the issue tracker or the devel branch to check for patches that aren't in the newest release yet
Л(
NK
23:02
Noel Kuntze
Hi, I started work on writing Python 3 bindings for libmdbx, but the mdbx.h++ file is more than 4500 lines in size. Can I just skip all the helper functions you defined together with their bodies, or are they necessary for the functioning of libmdbx?
23:03
Also, why *are* they defined in the header file, instead of just being declared?
4 February 2021
NK
01:33
Noel Kuntze
Nvm, I figured it out. You can't inline them otherwise. :P
01:39
@erthink I implemented setting the MDBX_ vars during compile time from the cmdline: https://gitlab.alpinelinux.org/alpine/aports/-/blob/c0979bac716b859b4649e7cc685f4ec1816d0d6e/testing/libmdbx/0001-Make-MDBX_-vars-specifyable-via-args.patch
Л(
16:05
Леонид Юрьев (Leonid Yuriev)
In reply to this message
It's good that you came to this conclusion yourself.
There is no perfect solution here:
- Almost all the functions there do not make sense to take out in the DSO, since the cost of preparing arguments in the stack is commensurate with the body of the functions when ones inlined.
- In addition, the visibility of the function body complements the documentation - so it is easier to understand it and how it works.
- Unfortunately, all this increases the size of the header file. But still, I prefer to supply a single header file and recommend using convenient IDEs to work with the code.
There is no perfect solution here:
- Almost all the functions there do not make sense to take out in the DSO, since the cost of preparing arguments in the stack is commensurate with the body of the functions when ones inlined.
- In addition, the visibility of the function body complements the documentation - so it is easier to understand it and how it works.
- Unfortunately, all this increases the size of the header file. But still, I prefer to supply a single header file and recommend using convenient IDEs to work with the code.
16:11
In reply to this message
This easy solution, but it is wrong (
All the hassle with getting information from the
Your solution certainly works, but it makes it easy to make an error by simply forgetting to update the value passed in the arguments.
All the hassle with getting information from the
git is necessary to avoid human error when generating version information.Your solution certainly works, but it makes it easy to make an error by simply forgetting to update the value passed in the arguments.
16:13
@thermi, as I wrote before, please submit the issue at github with the reasoning you provided here earlier.
9 February 2021
AS
07:24
Alex Sharov
what is right way to get GC size in runtime -
mdbx_dbi_stat(FREE_DBI)?
Л(
07:27
Леонид Юрьев (Leonid Yuriev)
In reply to this message
This way you can get the number of entries in the GC/Freelist and the space ones occupied, but not the number of pages placed in the GC/Freelist.
AS
07:31
Alex Sharov
In reply to this message
yes, I looking for size of GC DBI itself, not amount of page ids holded inside. thank
Л(
07:56
Леонид Юрьев (Leonid Yuriev)
На всякий, не забывайте, что обновление GC происходит только при коммите, т.е. если текущая транзакция много помешает или берет из GC, то изнутри её вы в GC этого не увидите.
AS
07:59
Alex Sharov
да, печатаю размеры DBI и GC сразу после коммита, а всякую дебажную статистику TxInfo (
space_dirty, space_retired) сразу перед коммитом.
Л(
08:02
Леонид Юрьев (Leonid Yuriev)
Ещё в space_dirty сейчас есть забытый баг - величина считается по кол-во грязных страниц, без учёта что некоторые могут быть overflow/large.
AS
08:03
Alex Sharov
у нас осталось не много overflow страниц, будем считать что это не страшно.
10 February 2021
basiliscos invited basiliscos
Л(
20:15
Леонид Юрьев (Leonid Yuriev)
@AskAlexSharov, могли бы уточнить зачем вам были нужны вложенные транзакции и почему теперь их вычищаете?
11 February 2021
AS
05:19
Alex Sharov
In reply to this message
Мы искали где-бы их применить. Не нашли потому что в lmdb вложенные транзакции не бездимитны. Ну и вообще похоже что нет юзкейсов у нас для них.
AS
06:11
Alex Sharov
Пред-предыдущая версия софта работала на leveldb - совсем без транзакций.
AS
06:56
Alex Sharov
в биндинги я их верну сегодня. просто автор не знал что это app-agnostic биндинги
Л(
07:13
Леонид Юрьев (Leonid Yuriev)
👍
Л(
07:45
Леонид Юрьев (Leonid Yuriev)
Вложенные транзакции нужны только если логика работы приложения предполагает их отмену в каких-то ситуациях.
AS
Л(
07:59
Леонид Юрьев (Leonid Yuriev)
👍
AS
Ruslan invited Ruslan
R
23:30
Ruslan
Привет, подскажите пожалуйста как правильно на lmdbx/lmdb реализовывать LRU кеш? Сейчас реализовал простую очередь, но она все равно не работает: задал mdb_env_set_mapsize равный ~300mb, кидаю значения с размерами от 7 до 15 mb, через код контролирую заполнение базы не более чем на 80% (удаляю то что выпадает из очереди). В итоге получаю "MDBX_MAP_FULL: Environment mapsize limit reached", через MDBX_stat вижу, что база занимает 212353024 байт, а лимит 300003328 байт. Что я делаю не так? Минимальный пример - https://pastebin.com/2NdKy5aj
Л(
23:40
Леонид Юрьев (Leonid Yuriev)
In reply to this message
TL;DR;
У вас там (видимо, скорее всего) где-то текут (не закрываются) читающие транзакции, либо данные не удаляются (транзакции абортятся).
Советую запустить под отладчиком и между транзакциями посмотреть:
- заполненность БД посредством
- активных читателей посредством
У вас там (видимо, скорее всего) где-то текут (не закрываются) читающие транзакции, либо данные не удаляются (транзакции абортятся).
Советую запустить под отладчиком и между транзакциями посмотреть:
- заполненность БД посредством
mdbx_chk и/или mdbx_stat;- активных читателей посредством
mdbx_stat -r.
23:42
Еще хотелось-бы чтобы вы попробовали C++ API.
R
23:43
Ruslan
In reply to this message
Да, сейчас проверю замечания, спасибо. Код наколеночный, извиняюсь
Л(
23:52
Леонид Юрьев (Leonid Yuriev)
И на всякий случай, для понимания:
Большие/длинные значения в MDBX/LMDB хранятся в "overflow pages" (устоявшийся термин), которые физически является последовательностями смежных страниц.
Т.е. для размещения 1 mb данных нужно 1024/4 = 256 свободных страниц БД, расположенных последовательно.
Поэтому:
- места в БД может не хватать из-за фрагментации.
- лучше при создании БД задать максимальный размер страницы (64K).
Большие/длинные значения в MDBX/LMDB хранятся в "overflow pages" (устоявшийся термин), которые физически является последовательностями смежных страниц.
Т.е. для размещения 1 mb данных нужно 1024/4 = 256 свободных страниц БД, расположенных последовательно.
Поэтому:
- места в БД может не хватать из-за фрагментации.
- лучше при создании БД задать максимальный размер страницы (64K).
R
23:52
Ruslan
In reply to this message
Получается как то так https://pastebin.com/wqUw1166 , в целом по коду транзакции течь не должны, читатели всегда абортятся, а писатели закрываются через коммит, но если не было коммита, тогда они заабортятся.
23:54
In reply to this message
Как раз на фрагментацию и грешим, можно ли на рантайме как то уменьшить фрагментацию или быть уверенным заранее, что буфер размером 10мб сможет уместиться в базу? Копировать базу не вариант
Л(
23:55
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Если в
retained нули, то значит читатели не мешают переработки мусора.
R
12 February 2021
Л(
00:02
Леонид Юрьев (Leonid Yuriev)
In reply to this message
1.
При попытке помещения очередного значения будет либо SUCCESS, либо ошибка из-за отсутствия места.
2.
Сейчас это приведет к пометке транзакции как ошибочной, но можно сделать правку чтобы просто возвращалась ошибка.
Либо добавить в API функцию проверки наличия места и/или поиска максимального span of free pages.
3.
Исторический LMDB/MDBX позволяют хранить большие значения, но умеют это только в последовательных страницах (линейных кусках БД).
В libmdbx это поведение изменено не будет, а в MithrilDB появиться опция = можно будет использовать потоковое API для записи/чтения BLOB-ов.
Соответственно, проблему нехватки места из-за фрагментации можно будет обойти.
При попытке помещения очередного значения будет либо SUCCESS, либо ошибка из-за отсутствия места.
2.
Сейчас это приведет к пометке транзакции как ошибочной, но можно сделать правку чтобы просто возвращалась ошибка.
Либо добавить в API функцию проверки наличия места и/или поиска максимального span of free pages.
3.
Исторический LMDB/MDBX позволяют хранить большие значения, но умеют это только в последовательных страницах (линейных кусках БД).
В libmdbx это поведение изменено не будет, а в MithrilDB появиться опция = можно будет использовать потоковое API для записи/чтения BLOB-ов.
Соответственно, проблему нехватки места из-за фрагментации можно будет обойти.
R
Л(
00:08
Леонид Юрьев (Leonid Yuriev)
In reply to this message
К пункту 2 выше можно добавить еще один workaround - использовать вложенные транзакции, тогда при ошибке поломается вложенная транзакция, а родительская останется целой.
R
00:23
Ruslan
In reply to this message
А в каком порядке выделяются станицы для данных? В моем примере я вообще то последовательно удаляю наиболее старые данные используется простую очередь fifo, то есть при определенных настройках думаю можно было бы избежать фрагментации
Л(
00:34
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Если не уходить в детальное объяснение, то в "обычном" порядке, но не трогая MVCC-снапшоты используемые читателями.
Если у вас много асинхронно работающих читателей, то они могут блокировать переработку мусора.
Чтобы поймать такую ситуацию используйте
Если у вас много асинхронно работающих читателей, то они могут блокировать переработку мусора.
Чтобы поймать такую ситуацию используйте
mdbx_env_set_hsr(), см https://erthink.github.io/libmdbx/group__c__err.html#gaedc09dd7e0634163be8aafdf00d7db77.MDBX_COALESCE в вашем случае особо не влияет, поскольку при поиске места движок будет читать и объединять записи из GC пока не найдет последовательности достаточной длинны, т.е. MDBX_COALESCE как-бы включается вынужденно.
00:36
In reply to this message
Еще, при большом размере БД (большом кол-ве страниц), возможно, нужно увеличить лимит
MDBX_opt_rp_augment_limit, см https://erthink.github.io/libmdbx/group__c__api.html#gga671855605968c3b1f89a72e2d7b71eb3a9fe64bcad43752eac6596cbb49a2be2d.
R
00:51
Ruslan
In reply to this message
В том примере кода есть только читатели, которые высчитвают размер бд через mdbx_dbi_stat и тут же абортятся. Читатели с писателями в примере при этом не пересакаются. Можно убрать читателей и высчитвать размер самим, но это тоже не помогает
Л(
01:27
In reply to this message
Чуть поправил ваш код, чтобы для скорости БД была в
Запустил под отладчиком, поставит точку остановки на #226: throw std::runtime_error(std::string("exception :") + mdbx_strerror(res));
Поймал
mem: 218796032/300003328 bytes, inserted = 905, shrinked = 888, real_used_space = 218684634, used_keys = 17
mem: 227213312/300003328 bytes, inserted = 929, shrinked = 906, real_used_space = 227109072, used_keys = 23
mem: 223158272/300003328 bytes, inserted = 952, shrinked = 932, real_used_space = 223030154, used_keys = 20
При этом
Не останавливая отладку запустил
Processing '@GC'...
- key-value kind: ordinal-key => single-value, flags: integerkey (0x08), dbi-id 0
- page size 4096, entries 16
- b-tree depth 1, pages: branch 0, leaf 1, overflow 20
- fixed key-size 8
transaction 2029, 918 pages, maxspan 907
transaction 2030, 926 pages, maxspan 926
transaction 2031, 1018 pages, maxspan 1018
transaction 2032, 1018 pages, maxspan 682
transaction 2033, 1018 pages, maxspan 1018
transaction 2034, 1018 pages, maxspan 1018
transaction 2035, 1018 pages, maxspan 1018
transaction 2036, 1018 pages, maxspan 749
transaction 2037, 1018 pages, maxspan 1018
transaction 2038, 1018 pages, maxspan 1018
transaction 2039, 1018 pages, maxspan 556
transaction 2040, 1017 pages, maxspan 726
transaction 2041, 18 pages, maxspan 6
transaction 2042, 3411 pages, maxspan 3407
transaction 2043, 20 pages, maxspan 4
transaction 2044, 3411 pages, maxspan 3407
- summary: 16 records, 0 dups, 128 key's bytes, 75596 data's bytes, 0 problems
- space: 73243 total pages, backed 73243 (100.0%), allocated 72285 (98.7%), remained 958 (1.3%), used 53402 (72.9%), gc 18883 (25.8%), detained 3411 (4.7%), reclaimable 15472 (21.1%), available 164
Другими словами, вполне очевидно в GC нет последовательности из 3699 свободных страниц, т.е. причина в фрагментации.
/dev/shm/.Запустил под отладчиком, поставит точку остановки на #226: throw std::runtime_error(std::string("exception :") + mdbx_strerror(res));
Поймал
MDBX_MAP_FULL = -30792 с хвостом в консоли:mem: 218796032/300003328 bytes, inserted = 905, shrinked = 888, real_used_space = 218684634, used_keys = 17
mem: 227213312/300003328 bytes, inserted = 929, shrinked = 906, real_used_space = 227109072, used_keys = 23
mem: 223158272/300003328 bytes, inserted = 952, shrinked = 932, real_used_space = 223030154, used_keys = 20
При этом
db_value.iov_len = 15149103, т.е. (15149103 + 4096 - 1) / 4096 = 3699 страниц.Не останавливая отладку запустил
./mdbx_chk -cvvvv /dev/shm/, среди прочего вижу:Processing '@GC'...
- key-value kind: ordinal-key => single-value, flags: integerkey (0x08), dbi-id 0
- page size 4096, entries 16
- b-tree depth 1, pages: branch 0, leaf 1, overflow 20
- fixed key-size 8
transaction 2029, 918 pages, maxspan 907
transaction 2030, 926 pages, maxspan 926
transaction 2031, 1018 pages, maxspan 1018
transaction 2032, 1018 pages, maxspan 682
transaction 2033, 1018 pages, maxspan 1018
transaction 2034, 1018 pages, maxspan 1018
transaction 2035, 1018 pages, maxspan 1018
transaction 2036, 1018 pages, maxspan 749
transaction 2037, 1018 pages, maxspan 1018
transaction 2038, 1018 pages, maxspan 1018
transaction 2039, 1018 pages, maxspan 556
transaction 2040, 1017 pages, maxspan 726
transaction 2041, 18 pages, maxspan 6
transaction 2042, 3411 pages, maxspan 3407
transaction 2043, 20 pages, maxspan 4
transaction 2044, 3411 pages, maxspan 3407
- summary: 16 records, 0 dups, 128 key's bytes, 75596 data's bytes, 0 problems
- space: 73243 total pages, backed 73243 (100.0%), allocated 72285 (98.7%), remained 958 (1.3%), used 53402 (72.9%), gc 18883 (25.8%), detained 3411 (4.7%), reclaimable 15472 (21.1%), available 164
Другими словами, вполне очевидно в GC нет последовательности из 3699 свободных страниц, т.е. причина в фрагментации.
R
Л(
01:41
Леонид Юрьев (Leonid Yuriev)
In reply to this message
В качестве эксперимента сделал
Но только с предварительным удалением БД и до открытия, когда можно задать размер страницы.
Т.е. динамический размер (с увеличением, но без уменьшения) от минимального до вдвое большего и с максимальным размером страницы.
Результат:
- уже 100К итераций.
- размер БД 320192 Кб.
+ средний размер использованного места около 222 Мб.
mdbx_env_set_geometry(env, -1, 0, cache_size * 2, -1, 0, 65536) вместо mdbx_env_set_mapsize().Но только с предварительным удалением БД и до открытия, когда можно задать размер страницы.
Т.е. динамический размер (с увеличением, но без уменьшения) от минимального до вдвое большего и с максимальным размером страницы.
Результат:
- уже 100К итераций.
- размер БД 320192 Кб.
+ средний размер использованного места около 222 Мб.
R
Л(
02:06
Леонид Юрьев (Leonid Yuriev)
In reply to this message
На всякий для FIFO (когда вставка всегда идёт в порядке возрастания ключей) лучше добавлять данные с опцией
MDBX_APPEND.
Л(
13 February 2021
AS
13:27
Alex Sharov
hypotetical question: is it possible to implement drop_prefix (or drop_range) method - which will not touch leaf pages (or touch only first/last leaf pages only)? For example by visiting only branch nodes and adding id of all leaf nodes to GC.
also - we already have cursor_delete(
reason why i'm asking: we some fear like "deleting large range may take unpredictable time - because we need to read all data in range" - I wounder - how real is our fear.
also - we already have cursor_delete(
MDBX_NODUPDATA) - to drop sub-db - how it works now? (I don't understand from source code).reason why i'm asking: we some fear like "deleting large range may take unpredictable time - because we need to read all data in range" - I wounder - how real is our fear.
Л(
15:03
Леонид Юрьев (Leonid Yuriev)
In reply to this message
1.
Yes, it is possible (delete a range without reading most of a leaf pages).
Please file an issue on the github.
2.
Essentially MDBX stores multi-values (aka duplicates) in a nested b+tree, i.e. single key + subtree of values.
So the`mdbx_cursor_del(MDBX_ALLDUPS)` just drops such nested b+tree.
3.
While dropping a whole tree of pages we can avoid read the leaf pages, since only page numbers is needed but not the data.
This is true for canonical b-tree, where leaf pages just holds data but not refs to an any other pages.
But this is false in case when b+tree includes an overflow/large page(s), i.e. at least one leaf page has a reference to an overflow/large page(s).
Yes, it is possible (delete a range without reading most of a leaf pages).
Please file an issue on the github.
2.
Essentially MDBX stores multi-values (aka duplicates) in a nested b+tree, i.e. single key + subtree of values.
So the`mdbx_cursor_del(MDBX_ALLDUPS)` just drops such nested b+tree.
3.
While dropping a whole tree of pages we can avoid read the leaf pages, since only page numbers is needed but not the data.
This is true for canonical b-tree, where leaf pages just holds data but not refs to an any other pages.
But this is false in case when b+tree includes an overflow/large page(s), i.e. at least one leaf page has a reference to an overflow/large page(s).
AS
16:55
Alex Sharov
It means - if place “big range” in 1 dupsort sub-tree - then already can drop sub-tree (instead of creating new api), and technically it’s 1 leaf page touch (no overflow pages here). If yes, then I will not file issue for now - will discuss concept with our team first.
Л(
17:28
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Yes, if you need delete a whole
dupsort sub-tree for the key - this is done by current API.
AS
17:30
Alex Sharov
In reply to this message
And it’s equal to 1 leaf page touch (no overflow), right?
Л(
17:33
Леонид Юрьев (Leonid Yuriev)
No.
This required CoW'ing a stroke of pages from the root to the leaf of a main tree.
This required CoW'ing a stroke of pages from the root to the leaf of a main tree.
AS
17:33
Alex Sharov
Yes, branch pages are ok
14 February 2021
Денис Гура invited Денис Гура
15 February 2021
EdgarArout invited EdgarArout
Л(
19:19
Леонид Юрьев (Leonid Yuriev)
Завтра планирую быть на http://www.mcst.ru/elbrus-tech-day-1617-fevralya-2021-goda
16 February 2021
NK
14:22
Noel Kuntze
Hi, I need some help writing the type caster for the Python bindings. I'd appreciate any help! I did a short summary of what I need help with in issue #147 (https://github.com/erthink/libmdbx/issues/147).
Л(
14:34
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Thank you, I will definitely look and answer you later.
17 February 2021
NK
21:29
Noel Kuntze
Hey Leonid, did you take a look?
18 February 2021
Л(
12:11
Леонид Юрьев (Leonid Yuriev)
In reply to this message
I'm sorry for the delay, I'll answer just now.
NK
16:35
Noel Kuntze
Thank you for your comment on the threat
22 February 2021
b
19:08
basiliscos
@erthink , поскажите, а с помощью курсора можно сканирование по префиксу ключа произвести? Т.е. у меня префикс
abc_*, хочу выбрать все ключи со значениями, по этой бинарной маске?
Л(
20:06
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Да, конечно, как в любой СУБД.
Установите курсор на первый подходящий ключ и итерируйте вперед пока не выйдите за пределы нужного префикса.
Установите курсор на первый подходящий ключ и итерируйте вперед пока не выйдите за пределы нужного префикса.
b
20:13
basiliscos
спасибо )
23 February 2021
Виталий invited Виталий
В
12:17
Виталий
Здравствуйте!
У меня данные гарантированно идут в алфавитном порядке. В leveldb они таким же образом и записаны на диск, что повышает скорость чтения. Предоставляет ли libmdbx такую возможность?
У меня данные гарантированно идут в алфавитном порядке. В leveldb они таким же образом и записаны на диск, что повышает скорость чтения. Предоставляет ли libmdbx такую возможность?
Л(
17:32
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Если просто вставлять данные в пустую БД в порядке сортировки, то на диске страницы с данными будут преимущественно в последовательном порядке.
Но при этом заполнение страниц будет 50% (при полном заполнении крайняя листовая страницы будет разделаться на две, и так далее).
Для полного заполнения страниц при последовательной вставке следует использовать опции
Кроме этого "выпрямить" порядок страниц можно сделав копию БД с компактификаций (утилитой
Но при этом заполнение страниц будет 50% (при полном заполнении крайняя листовая страницы будет разделаться на две, и так далее).
Для полного заполнения страниц при последовательной вставке следует использовать опции
MDBX_APPEND и MDBX_APPENDDUP.Кроме этого "выпрямить" порядок страниц можно сделав копию БД с компактификаций (утилитой
mdbx_copy -c или mdbx_env_copy()), а также сделав дамп-восстановление утилитами mdbx_dump + mdbx_load).
В
25 February 2021
AS
05:02
Alex Sharov
Подскажите, Чего мне подебажить чтобы понять причину: https://github.com/erthink/libmdbx/issues/164
05:14
Еще мы видим что mdbx на наших данных почему-то на 13% лучше сжимается при запуске на “zfs with enabled compression”, но не знаем почему :-)
Л(
11:14
Сейчас я занят и не могу отвлекаться/переключаться.
AS
11:24
Alex Sharov
sure
Л(
23:27
Леонид Юрьев (Leonid Yuriev)
In reply to this message
В целом всё выглядит довольно странно.
Пока у меня три "гипотезы":
- в libmdbx есть какой-то недочет, который проявляется в вашем сценарии.
- некая особенность libmdbx провоцирует/усугубляет некий недочет в ядре ОС, либо в драйвере диска или (даже) в его внутренней прошивке.
- наибольшее подозрение сейчас вызывает madvise.
С другой стороны, лучшее сжатие и одновременно худшая производительность могут быть объяснены увеличением (не важно по какой причине) реального размера БД.
Но, наверное, вы бы это заметили?
———
С учетом того, что тестовые прогоны достаточно дороги (как минимум по времени), я бы попросил вас сделать разумный минимум:
0.
Не стоит использовать
Это скорее внутренняя около-отладочная опция для проверки влияния авто-компактификации на производительность и другие показатели.
1. Если сохранились базы после прогонов с LMDB и MDBX, то предоставить вывод
Если же базы НЕ созранились, до сделать это после очередного прогона.
Причем желательно сохранить базу MDBX (на момент явного отставания), чтобы после (при необходимости) посмотреть её более детально.
2. В дальнейшем запускать тесты через утилиту
Так мы получим от системы базовую информацию по потраченным ресурсам, что (предположительно) позволит понять что происходит или сузить гипотезы.
3. В MDBX отключить
Т.е. есть подозрение что madvise-подсказки выдаются либо неверно/неоптимально, либо проявляют недочет в ядре.
———
Дополнительно стоит собирать и добавить на график(и) метрики от
Видимо лучше будет сделать два graphana-like графика по-отдельности для LMDB и MDBX.
Тогда можно будет увидеть корреляцию деградацию с изменением каких-то параметров.
Но пока этого делать не стоит, точнее не стоит если вам что-то подобное не нужно самими.
———
Кроме вышесказанного, я постараюсь прогнать тесты для сценария БД > ОЗУ.
Пока у меня три "гипотезы":
- в libmdbx есть какой-то недочет, который проявляется в вашем сценарии.
- некая особенность libmdbx провоцирует/усугубляет некий недочет в ядре ОС, либо в драйвере диска или (даже) в его внутренней прошивке.
- наибольшее подозрение сейчас вызывает madvise.
С другой стороны, лучшее сжатие и одновременно худшая производительность могут быть объяснены увеличением (не важно по какой причине) реального размера БД.
Но, наверное, вы бы это заметили?
———
С учетом того, что тестовые прогоны достаточно дороги (как минимум по времени), я бы попросил вас сделать разумный минимум:
0.
Не стоит использовать
MDBX_ENABLE_REFUND=0, по крайней мере в production.Это скорее внутренняя около-отладочная опция для проверки влияния авто-компактификации на производительность и другие показатели.
1. Если сохранились базы после прогонов с LMDB и MDBX, то предоставить вывод
mdb_stat -aef и mdbx_stat -aef.Если же базы НЕ созранились, до сделать это после очередного прогона.
Причем желательно сохранить базу MDBX (на момент явного отставания), чтобы после (при необходимости) посмотреть её более детально.
2. В дальнейшем запускать тесты через утилиту
/usr/bin/time -v (лучше не путать с time встроенной в bash).Так мы получим от системы базовую информацию по потраченным ресурсам, что (предположительно) позволит понять что происходит или сузить гипотезы.
3. В MDBX отключить
madvise(), сейчас я добавлю соответствующую опцию сборки.Т.е. есть подозрение что madvise-подсказки выдаются либо неверно/неоптимально, либо проявляют недочет в ядре.
———
Дополнительно стоит собирать и добавить на график(и) метрики от
getrusage() (за вычетом не поддерживаемых на Linux, см. man getrusage), а также основные параметры "геометрии БД": backed, allocated, used, gc (mdbx_stat -ef) и соответствующие им для LMDB (mdb_stat -ef, но там меньше информации и я не помню подробностей).Видимо лучше будет сделать два graphana-like графика по-отдельности для LMDB и MDBX.
Тогда можно будет увидеть корреляцию деградацию с изменением каких-то параметров.
Но пока этого делать не стоит, точнее не стоит если вам что-то подобное не нужно самими.
———
Кроме вышесказанного, я постараюсь прогнать тесты для сценария БД > ОЗУ.
26 February 2021
𝓜𝓲𝓬𝓱𝓪𝓮𝓵 invited 𝓜𝓲𝓬𝓱𝓪𝓮𝓵
?
02:24
𝓜𝓲𝓬𝓱𝓪𝓮𝓵
Здравствуйте! Я правильно понимаю, что бд не поддерживает шифрование из коробки?
Л(
02:30
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Да, правильно.
В libmdbx сквозного/прозрачного шифрования нет и не будет, так как это требует:
- изменение формата БД, т.е. нарушение совместимости.
- поддержку внутреннего кэша расшифрованных страниц, что нарушает исходно заложенный дизайн и предполагает другие сценарии использования.
Такое шифрование планируется в MithrilDB и LMDB 1.0 (уже сейчас есть в devel-прототипе в ветке master3).
Если вам требуется шифрование с libmdbx, то потребуется делать "руками" перед помещением данных в БД и после чтения.
В libmdbx сквозного/прозрачного шифрования нет и не будет, так как это требует:
- изменение формата БД, т.е. нарушение совместимости.
- поддержку внутреннего кэша расшифрованных страниц, что нарушает исходно заложенный дизайн и предполагает другие сценарии использования.
Такое шифрование планируется в MithrilDB и LMDB 1.0 (уже сейчас есть в devel-прототипе в ветке master3).
Если вам требуется шифрование с libmdbx, то потребуется делать "руками" перед помещением данных в БД и после чтения.
?
02:30
𝓜𝓲𝓬𝓱𝓪𝓮𝓵
Хорошо, спасибо
AS
05:43
Alex Sharov
In reply to this message
Спасибо. Сделаю. 0. Я просто проверял что существующие ручки не помогают изменить картину (в проде использовать будем refund и coalesce). 5. Графана у нас есть, но я хочу туда протащить pagecachemiss из cachestat (https://github.com/iovisor/bcc). 6. Без внешнего сжатия база получается на 5% больше, со сжатием на 13% меньше. Причиной того что со сжатием работает быстрее может быть тот факт что zfs дефолтный размер блока сжатия - 128Кb.
Л(
13:57
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Просьба по-возможности отписывать в issue на github.
Тогда эта информация индексируется и становится доступной остальным.
Тогда эта информация индексируется и становится доступной остальным.
Л(
15:52
Леонид Юрьев (Leonid Yuriev)
In reply to this message
1.
Из этого следует, что сначала нужно понять откуда +5%.
Предположительно дело в том, что в libmdbx достаточно строго выполняется стратегия слияния страниц = если страница заполнена менее чем на 25%, то она сливается с наименее заполненным соседом.
В среднем это обеспечивает более-менее рациональный баланс между рыхлостью и скоростью вставок:
- если страницы заполнены слишком сильно, то при вставках будет часто производиться разделение страниц (со вставкой ключей-ссылок в родительские страницы и т.д.);
- если страницы заполнены слишком рыхло, то страниц просто много, а БД просто больше по размеру;
- т.е. компромисс между потерями на вводе-выводе и затратами на разделение страниц.
Золотого сечения тут нет, но в среднем для больших БД выгоднее заполнять страницы плотнее, и наоборот для маленьких БД.
Можно попробовать подкрутить этот параметр, так чтобы для больших БД уже чувствовалась разница, а для маленьких деградация была еще не заметна.
Сейчас я сделаю соответствующие правки, чтобы вы могли попробовать.
А в дальнейшем - вынести в runtime опции, если это даст положительный эффект.
2.
Лучшее сжатие частично можно объяснить рыхлостью страниц, чуть более регулярной структурой и обнуленными хвостами large/overflow страниц.
Тем не менее, для меня тут нет полной ясности.
В том числе, на 13% лучше - это относительно сжатого размера LMDB, или разница в сжатии?
3.
Если на zfs со сжатием работает быстрее, то из-за суммы двух причин:
- сжатие уменьшает I/O bandwidth с диском.
- при чтении блоки по 128К вынуждают page cache работать не с отдельными 4К страниц, а как-бы блоками по 32 страницы.
т.е. это некий micro read ahead, который увеличивает I/O bandwidth, но немного уменьшает IOPS.
- при записи блоки по 128К вынуждают коагулировать все write requests в пределах блока в одну IO-операцию.
т.е. это некий write micro batching, который увеличивает I/O bandwidth, но немного уменьшает IOPS.
Итоговый эффект принципиально зависит от того как много I/O операций удается схлопнуть в одну (от 1 до 32) и от суммарных накладных расходов на одну I/O операцию (как в ядре, так и у диске, включая seek / pagezone switch).
Тем не менее, если вы видите выгоду, то вероятно есть смысл попробовать более крупный размер страниц в БД (8/16/32/64K).
Из этого следует, что сначала нужно понять откуда +5%.
Предположительно дело в том, что в libmdbx достаточно строго выполняется стратегия слияния страниц = если страница заполнена менее чем на 25%, то она сливается с наименее заполненным соседом.
В среднем это обеспечивает более-менее рациональный баланс между рыхлостью и скоростью вставок:
- если страницы заполнены слишком сильно, то при вставках будет часто производиться разделение страниц (со вставкой ключей-ссылок в родительские страницы и т.д.);
- если страницы заполнены слишком рыхло, то страниц просто много, а БД просто больше по размеру;
- т.е. компромисс между потерями на вводе-выводе и затратами на разделение страниц.
Золотого сечения тут нет, но в среднем для больших БД выгоднее заполнять страницы плотнее, и наоборот для маленьких БД.
Можно попробовать подкрутить этот параметр, так чтобы для больших БД уже чувствовалась разница, а для маленьких деградация была еще не заметна.
Сейчас я сделаю соответствующие правки, чтобы вы могли попробовать.
А в дальнейшем - вынести в runtime опции, если это даст положительный эффект.
2.
Лучшее сжатие частично можно объяснить рыхлостью страниц, чуть более регулярной структурой и обнуленными хвостами large/overflow страниц.
Тем не менее, для меня тут нет полной ясности.
В том числе, на 13% лучше - это относительно сжатого размера LMDB, или разница в сжатии?
3.
Если на zfs со сжатием работает быстрее, то из-за суммы двух причин:
- сжатие уменьшает I/O bandwidth с диском.
- при чтении блоки по 128К вынуждают page cache работать не с отдельными 4К страниц, а как-бы блоками по 32 страницы.
т.е. это некий micro read ahead, который увеличивает I/O bandwidth, но немного уменьшает IOPS.
- при записи блоки по 128К вынуждают коагулировать все write requests в пределах блока в одну IO-операцию.
т.е. это некий write micro batching, который увеличивает I/O bandwidth, но немного уменьшает IOPS.
Итоговый эффект принципиально зависит от того как много I/O операций удается схлопнуть в одну (от 1 до 32) и от суммарных накладных расходов на одну I/O операцию (как в ядре, так и у диске, включая seek / pagezone switch).
Тем не менее, если вы видите выгоду, то вероятно есть смысл попробовать более крупный размер страниц в БД (8/16/32/64K).
AV
16:44
Artem Vorotnikov
@erthink флаги для sync-режимов, liforeclaim, coalesce и writemap не учитываются при
MDBX_RDONLY?
Л(
17:17
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Их негде/некогда/незачем учитывать если процесс открывает БД только для чтения.
28 February 2021
Л(
15:38
Леонид Юрьев (Leonid Yuriev)
AS
15:43
h,H,b,txSenders - можно убрать. Они изначально были неравными немного и в эксперименте не апдейтились.
Л(
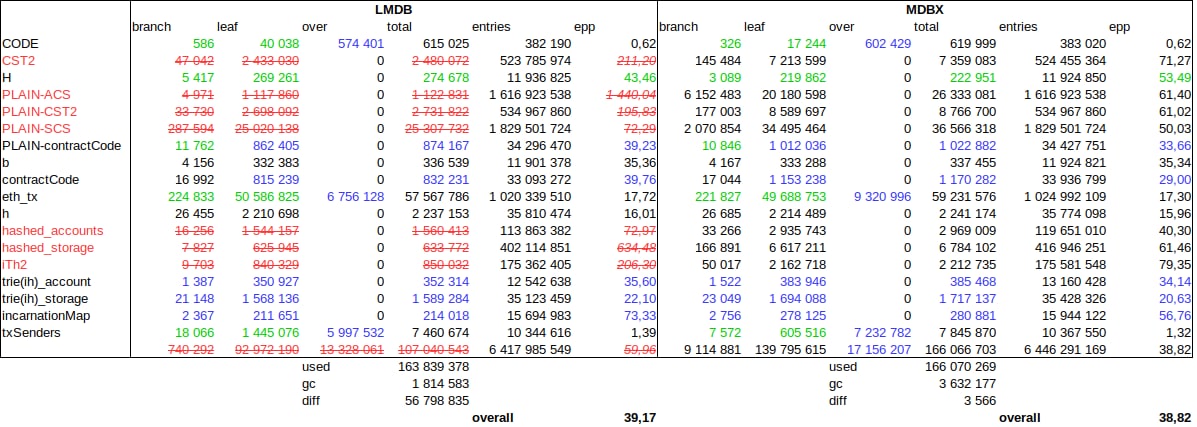
AS
15:46
Alex Sharov
Смотреть нужно на: PLAIN-ACS, PLAIN-SCS, PLAIN-CST2
они в основном обновлялись.
PLAIN-ACS, PLAIN-SCS - через APPEND
PLAIN-CST2 - через UPSERT
они в основном обновлялись.
PLAIN-ACS, PLAIN-SCS - через APPEND
PLAIN-CST2 - через UPSERT
Л(
15:46
Леонид Юрьев (Leonid Yuriev)
Легенда:
- краным/зачеркнутым = там где статистики LMDB нельзя верить из-за ошибок.
- синее = в LMDB менее рыхлые страницы.
- зеленое = в MDBX менее рыхлые страницы.
- колона epp = Entries Per Page
- overall снизу = общее "по больнице" значение EPP.
- краным/зачеркнутым = там где статистики LMDB нельзя верить из-за ошибок.
- синее = в LMDB менее рыхлые страницы.
- зеленое = в MDBX менее рыхлые страницы.
- колона epp = Entries Per Page
- overall снизу = общее "по больнице" значение EPP.
AS
15:47
Alex Sharov
блин 🙂 и они все DUPSORT поэтому lmdb показывает не правду про них
Л(
15:48
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Да, то только когда дубликаты реально есть и выносятся в отдельные nested b-tree
15:50
Важнее overall снизу - там посчитано по используемым страницам, при этом в diff видно "неучтенку":
- для LMDB видим 56M страниц из-за багов;
- для MDBX видим 3.5K потому что здесь не учтены расходы на GC и мелкие таблицы.
- для LMDB видим 56M страниц из-за багов;
- для MDBX видим 3.5K потому что здесь не учтены расходы на GC и мелкие таблицы.
AS
15:54
Alex Sharov
прикольно. я такого никогда не считал.
Л(
17:17
Леонид Юрьев (Leonid Yuriev)
В "сухом остатке" на текущий момент:
1.
Базы разные, в том числе с разной историей и разным кол-ом таблиц.
Заполнение страниц зависит от всех вставок/удалений в истории и не меняется при mdbx_copy.
Поэтому чтобы отвязаться от истории нужно mdbx_dump + mdbx_load, при этом подумать нужен ли append-режим для load (ключик
2.
"В среднем по больнице" заполнение страниц у MDBX и LMDB примерно одинаковое.
При этом у MDBX дерево более выгодное (меньше branch-станиц, больше leaf/overflow = уже сверку, шире снизу).
Но у MDBX намного больше overflow-страниц (на ~15Gb), поэтому суммарно размер больше, т.е. "хотели как лучше, а получилось как всегда" ;)
Это лучше всего видно на таблице
3.
Если отбросить заведомо недостоверную статистику LMDB, но просуммировать разницу по overflow страница и страница в GC/Freelist, то получится (17156207-13328061 + 3632177-1814583)*4/1024/1024 = 22.054 Gb.
Примерно тоже самое если посмотреть на "Number of pages used: 163839378" в LMDB и "Allocated: 169702446" в MDBX, то разница (169702446-163839378)*4/1024/1024 = 22.365 Gb.
Отсюда можно сделать выводы:
- в MDBX получилось на (17156207-13328061)*4/1024/1024 = 14.954 Gb больше overflow страниц.
- скорее всего, часть из этих страниц обновлялась в последнюю транзакции и поэтому предыдущая версия осела в GC: (3632177-1814583)*4/1024/1024 = 7,100 Gb.
- если основная часть эти overflow-данных горячая, то это объясняет нажор RSS.
—-
Итого:
- Похоже что причина увеличения БД и увеличения RSS в большем кол-ве overflow страниц, из которых большинство горячие.
- Я посмотрю почему в MDBX получается больше overflow-страниц, но уже не сегодня.
- При таком кол-ве overflow-страниц, т.е. длинных значений, вам стоит попробовать большие размеры страницы. Причем начать с 64K и двигаться вниз.
P.S.
Размер страницы можно задать вызвав mdbx_env_set_geometry() перед open для еще не существующей БД.
1.
Базы разные, в том числе с разной историей и разным кол-ом таблиц.
Заполнение страниц зависит от всех вставок/удалений в истории и не меняется при mdbx_copy.
Поэтому чтобы отвязаться от истории нужно mdbx_dump + mdbx_load, при этом подумать нужен ли append-режим для load (ключик
-a).2.
"В среднем по больнице" заполнение страниц у MDBX и LMDB примерно одинаковое.
При этом у MDBX дерево более выгодное (меньше branch-станиц, больше leaf/overflow = уже сверку, шире снизу).
Но у MDBX намного больше overflow-страниц (на ~15Gb), поэтому суммарно размер больше, т.е. "хотели как лучше, а получилось как всегда" ;)
Это лучше всего видно на таблице
txSenders.3.
Если отбросить заведомо недостоверную статистику LMDB, но просуммировать разницу по overflow страница и страница в GC/Freelist, то получится (17156207-13328061 + 3632177-1814583)*4/1024/1024 = 22.054 Gb.
Примерно тоже самое если посмотреть на "Number of pages used: 163839378" в LMDB и "Allocated: 169702446" в MDBX, то разница (169702446-163839378)*4/1024/1024 = 22.365 Gb.
Отсюда можно сделать выводы:
- в MDBX получилось на (17156207-13328061)*4/1024/1024 = 14.954 Gb больше overflow страниц.
- скорее всего, часть из этих страниц обновлялась в последнюю транзакции и поэтому предыдущая версия осела в GC: (3632177-1814583)*4/1024/1024 = 7,100 Gb.
- если основная часть эти overflow-данных горячая, то это объясняет нажор RSS.
—-
Итого:
- Похоже что причина увеличения БД и увеличения RSS в большем кол-ве overflow страниц, из которых большинство горячие.
- Я посмотрю почему в MDBX получается больше overflow-страниц, но уже не сегодня.
- При таком кол-ве overflow-страниц, т.е. длинных значений, вам стоит попробовать большие размеры страницы. Причем начать с 64K и двигаться вниз.
P.S.
Размер страницы можно задать вызвав mdbx_env_set_geometry() перед open для еще не существующей БД.
AS
17:24
Alex Sharov
1. более аккуратные данные будут через несколько дней
3. "часть из этих страниц обновлялась в последнюю транзакции" - мне кажется что это не так, потому что работа которую делал процесс после mdb_copy -c писала в DUPSORT таблицы.
4. Эксперимент с бОльшими страницами запущу - когда получу результаты по
3. "часть из этих страниц обновлялась в последнюю транзакции" - мне кажется что это не так, потому что работа которую делал процесс после mdb_copy -c писала в DUPSORT таблицы.
4. Эксперимент с бОльшими страницами запущу - когда получу результаты по
MADVISE
AS
18:15
Alex Sharov
Там наши люди просят перейти на английский. Хотят читать этот чат.
Л(
Л(
20:53
Леонид Юрьев (Leonid Yuriev)
In reply to this message
I duplicated my last answers in (pidgin) English into the issue at github.
https://github.com/erthink/libmdbx/issues/164
https://github.com/erthink/libmdbx/issues/164
f
21:43
fuunyK
thank you!
1 March 2021
AV
18:44
Artem Vorotnikov
is it OK to open (and use) multiple write cursors within the same write transaction?
Л(
18:45
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Yes, of cause.
Including multiple cursors for a particular key-value map.
Including multiple cursors for a particular key-value map.
AV
18:47
Artem Vorotnikov
also all methods are OK to be called from multiple threads, provided that NOTLS/CHECKOWNERS=0 and write tx constructor/destructor is run from the same thread?
Л(
18:50
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Yes, but you MUST NEVER use write txn and/or write cursor(s) from multiple threads simultaneously !
Including close/open cursor(s) !
Including close/open cursor(s) !
AV
18:51
Artem Vorotnikov
In reply to this message
ah, so concurrent, behind mutex, from multiple threads is OK, but parallel is not?
Л(
18:55
Леонид Юрьев (Leonid Yuriev)
In reply to this message
The "concurrent" may be confusing here.
You may use _cooperative_ multi-threading, but no more, i.e. sure not "parallel".
+Oops, I was wrong in terms, correctly say "cooperative multithreading".
You may use _cooperative_ multi-threading, but no more, i.e. sure not "parallel".
+Oops, I was wrong in terms, correctly say "cooperative multithreading".
AV
18:56
Artem Vorotnikov
yeah, I phrased poorly, sorry
basically, it's OK to share write transaction and cursor across threads, as long as I put it behind a mutex
basically, it's OK to share write transaction and cursor across threads, as long as I put it behind a mutex
Л(
AV
18:59
Artem Vorotnikov
a bit of context: I tried using existing Rust LMDB/MDBX binding (heed), but being a dual binding makes it a jack of all trades. Besides, I got negative feedback from some of its users (segfaults), and it also obscures real libmdbx API, and provides its own, which is rather different
19:00
so I returned to porting Mozilla's LMDB bindings, but am also trying to tailor the API specifically to libmdbx guarantees / usage conditions, so that much would be checked by compiler
Л(
19:00
Леонид Юрьев (Leonid Yuriev)
In reply to this message
AFAIK: heed is designed (and tested) for Mellisearch only.
19:05
In reply to this message
👍
In this case, I would like to repeat: Please take a look at the C++ API; I think it is better to repeat modern C++ API in Rust rather than legacy C API, with making changes if necessary (including in the C++sources).
In this case, I would like to repeat: Please take a look at the C++ API; I think it is better to repeat modern C++ API in Rust rather than legacy C API, with making changes if necessary (including in the C++sources).
AV
19:33
Artem Vorotnikov
do I have to manually close databases before closing the environment?
Л(
19:44
Леонид Юрьев (Leonid Yuriev)
In reply to this message
No, if you mean the closing of a DBI-handles.
2 March 2021
AS
04:44
Alex Sharov
Is it possible to achieve reproducible (to match checksum) db files - when loading 2 collections to new db by Append. For example if i will load everything within 1 transaction and then run mdbx_copy -c.
AS
05:07
Alex Sharov
Another theoretical question: is it possible to get any benefits from “forward-only version of GET_RANGE”?
Л(
07:25
In reply to this message
The forward-direction iteration may be little bit faster than reverse.
AS
08:03
Alex Sharov
FYI: we changed our data model - and don't use custom comparators anymore.
Л(
AV
15:43
Artem Vorotnikov
cursors become invalid and cannot be used anymore after dbi is dropped?
Л(
15:46
Леонид Юрьев (Leonid Yuriev)
In reply to this message
In general, yes.
But take look at the
But take look at the
mdbx_cursor_bind().
AV
15:57
Artem Vorotnikov
In reply to this message
bytes written into provided
iovec through mdbx_get also should not be used after dbi drop?
Л(
16:16
Леонид Юрьев (Leonid Yuriev)
In reply to this message
This is generally a more complex question for write transactions case.
- it is the major difference is where the data is located, in a "dirty" or "clean" page.
- a data in the "clean" pages will be valid, since these pages are inside an ancestor (i.e. frozen/committed) MVCC snapshot, which will always be intact within the current transaction.
- a data in a "dirty" pages will become invalid, because after DBI dropping these pages (shadow copies) can be released or reused.
Therefore, in writing transactions, you should carefully work with pointers to data inside the database.
If the data is in a dirty page, it may become invalid in any subsequent operation that changes the contents of the database.
See
- it is the major difference is where the data is located, in a "dirty" or "clean" page.
- a data in the "clean" pages will be valid, since these pages are inside an ancestor (i.e. frozen/committed) MVCC snapshot, which will always be intact within the current transaction.
- a data in a "dirty" pages will become invalid, because after DBI dropping these pages (shadow copies) can be released or reused.
Therefore, in writing transactions, you should carefully work with pointers to data inside the database.
If the data is in a dirty page, it may become invalid in any subsequent operation that changes the contents of the database.
See
mdbx_is_dirty() = https://erthink.github.io/libmdbx/group__c__statinfo.html#ga32a2b4d341edf438c7d050fb911bfce9
16:19
r u got this?
NK
17:11
Noel Kuntze
Hey, I got some questions regarding the C++ API:
1) What's the generally necessary code to open a new env and open an existing map? I didn't find any such method that allows me to make a new env and then open a map relative to it in the C++ API, just in the C API.
2) Why did you keep the implementation details in mdbx.h++ instead of moving them into a seperate header file? That way one needs to look through far fewer lines.
1) What's the generally necessary code to open a new env and open an existing map? I didn't find any such method that allows me to make a new env and then open a map relative to it in the C++ API, just in the C API.
2) Why did you keep the implementation details in mdbx.h++ instead of moving them into a seperate header file? That way one needs to look through far fewer lines.
17:13
Also, are there any projects or public code examples using the C++ API?
AV
17:46
Artem Vorotnikov
In reply to this message
I'm not sure I can cover this cleanly in API contract - I guess I will make the bytes' lifetime dependent on dbi
17:48
also, if write transaction drops dbi, existing read transactions can still work with dbi safely until commit/abort?
AV
18:29
Artem Vorotnikov
In reply to this message
what if I write into an iovec with
mdbx_get, then run mdbx_del for the same key? will an iovec remain valid?
Л(
18:49
Леонид Юрьев (Leonid Yuriev)
In reply to this message
1. https://erthink.github.io/libmdbx/classmdbx_1_1env__managed.html#a1f9cddca614bcccd9033e9f056fc5083
2. I prefer to supply a single header file and an online API description.
2. I prefer to supply a single header file and an online API description.
NK
18:50
Noel Kuntze
I see, ty
Л(
Л(
19:05
Леонид Юрьев (Leonid Yuriev)
In reply to this message
This is the cost of zero-copy.
i.e. we should either always copy data during read (abandon zero-copy like most of storage engines) or check for dirty and make copy conditionally.
i.e. we should either always copy data during read (abandon zero-copy like most of storage engines) or check for dirty and make copy conditionally.
AV
19:11
Artem Vorotnikov
so, API will look roughly like this:
lines represent lifetime dependency
Env
^
|
Txn
^
|
Database <-------\
^ |
| |
Cursor Values (&[u8])
lines represent lifetime dependency
19:12
what this means is that e.g. Txn instance must not outlive Env (commit/abort before closing env)
19:13
the major difference is that Dbi is now more than just a handle, but an entity of its own, to which cursor and values are bound, not to txn
19:14
cannot drop dbi if value slices are still alive, as that would make those slices dangling pointers
AA
19:25
Alexey Akhunov
you meant "Txn must NOT outlive Env" perhaps
AV
Л(
19:27
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Please read my explanations again.
Для ясности я поясню по-русски:
- БД состоит из страниц, в которых размещаются ключи и значения;
- изменения всегда вносятся в копии страницы (CoW, page shadowing);
- не записанные на диск (временные, в ОЗУ) страницы называются "грязными";
- "грязные" страницы обновляются в ОЗУ, а "чистые" на диске не меняются;
- при чтении в iovec возвращается указатель на данные, которые транзакции чтения-записи могут быть как в "чистой" странице, так и в "грязной";
- любая "грязная" страница может быть обновлена или освобождена при последующих изменениях в ходе транзакции;
- указатель в iovec при этом не изменится, но будет указывать на мусор.
Примеры борьбы с этим:
1. см
2. см использование
Для ясности я поясню по-русски:
- БД состоит из страниц, в которых размещаются ключи и значения;
- изменения всегда вносятся в копии страницы (CoW, page shadowing);
- не записанные на диск (временные, в ОЗУ) страницы называются "грязными";
- "грязные" страницы обновляются в ОЗУ, а "чистые" на диске не меняются;
- при чтении в iovec возвращается указатель на данные, которые транзакции чтения-записи могут быть как в "чистой" странице, так и в "грязной";
- любая "грязная" страница может быть обновлена или освобождена при последующих изменениях в ходе транзакции;
- указатель в iovec при этом не изменится, но будет указывать на мусор.
Примеры борьбы с этим:
1. см
struct data_preserver внутри template<> class buffer в https://github.com/erthink/libmdbx/blob/master/mdbx.h%2B%2B#L828 2. см использование
mdbx_is_dirty() внутри libfpta, например https://github.com/erthink/libfpta/blob/master/src/data.cxx#L690-L694
Л(
19:51
Леонид Юрьев (Leonid Yuriev)
На всякий для информации о возможной дополнительной поддержки Rust:
В MithrilDB будет генерализированное безопасное mostly zero-copy чтение, упрощенно:
- любое чтение данных из БД будет требовать предоставление указателя на iovec и callback для копирования данных при необходимости;
- если возвращаемые в iovec данные расположены в грязной странице, то при её модификации будет вызван callback для копирования данных или учета их перемещения;
Технически этот механизм можно бэк-портировать в MDBX, ибо при этом не затрагивается (уже зафиксированный) формат БД.
Но я бы предпочел не тратить на это время без крайней необходимости.
В MithrilDB будет генерализированное безопасное mostly zero-copy чтение, упрощенно:
- любое чтение данных из БД будет требовать предоставление указателя на iovec и callback для копирования данных при необходимости;
- если возвращаемые в iovec данные расположены в грязной странице, то при её модификации будет вызван callback для копирования данных или учета их перемещения;
Технически этот механизм можно бэк-портировать в MDBX, ибо при этом не затрагивается (уже зафиксированный) формат БД.
Но я бы предпочел не тратить на это время без крайней необходимости.
AV
19:58
Artem Vorotnikov
пока попробую извратить API и при этом избежать копирования
19:59
если что, Rust здесь никак не мешает, просто я хочу "казусы" использования перенести из документации в API благо Rust как раз на это заточен
20:00
грубо говоря, весь код на С/С++ - как unsafe Rust, можно получить сегфолт
я же хочу с помощью языковых инструментов языка сделать "неубиваемый" биндинг
я же хочу с помощью языковых инструментов языка сделать "неубиваемый" биндинг
20:00
чтобы без блока unsafe нельзя было получить падение
20:02
чтобы все ошибки при использовании ловились компилятором на уровне очень крутой системы типов
Л(
20:02
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Гипотетически (наверное) можно как-то описать, что прочитанные данные "живут" до следующей модифицирующей операции или до конца транзакции.
Но как это сделать технически в Rust я (откровенно говоря) не знаю.
Поэтому будет любопытно посмотреть на реализацию.
Но как это сделать технически в Rust я (откровенно говоря) не знаю.
Поэтому будет любопытно посмотреть на реализацию.
AV
20:05
Artem Vorotnikov
impl Database {
...
pub fn get<K>(&self, key: &K) -> Result<&[u8]>
where
K: AsRef<[u8]>
...
pub fn del<K>(&mut self, key: &K, data: Option<&[u8]>) -> Result<()>
where
K: AsRef<[u8]>
...
}
...
pub fn get<K>(&self, key: &K) -> Result<&[u8]>
where
K: AsRef<[u8]>
...
pub fn del<K>(&mut self, key: &K, data: Option<&[u8]>) -> Result<()>
where
K: AsRef<[u8]>
...
}
Л(
20:05
Леонид Юрьев (Leonid Yuriev)
На всякий - 50/50 что MithrilDB будет переписан (если так можно сказать про текущие не-публичные PoC-и) на Rust.
Во многом этом зависит от успехов МЦСТ с запуском Rust на Эльбрусах, ну и в целом от явно заявленных потребностей/требований.
Во многом этом зависит от успехов МЦСТ с запуском Rust на Эльбрусах, ну и в целом от явно заявленных потребностей/требований.
AV
20:06
Artem Vorotnikov
In reply to this message
тут всё зависит от портирования LLVM - rustc всего лишь "морда" к нему
Л(
AV
20:06
Artem Vorotnikov
точнее, генератор HIR и MIR - LLVM используется как байтогенератор
20:08
In reply to this message
если по-русски, то
чтобы вызвать
Database::get отдаёт слайс байтов, который "захватывает" ссылку на экземпляр Databaseчтобы вызвать
Database::del нужно взять эксклюзивную ссылку на Database - это невозможно пока живы любые ссылки на этот же экземпляр
20:08
в принципе, +- стандартный API растовых коллекций
Л(
AV
20:19
Artem Vorotnikov
только вот вопрос: если у меня несколько dbi, то операция в одной dbi может инвалидировать данные в грязных страницах другой dbi?
20:25
от этого зависит могу ли я сделать
Database::del/put, который захватит только dbi, или мне нужно делать Transaction::del/put и блокировать всю write-транзакцию
Л(
20:33
Леонид Юрьев (Leonid Yuriev)
Нет, но при должном упорстве можно добиться подобного неподобающим использованием API:
1. добавить key-value запись в
2. создать именоманную subDB (открыть DBI > 1), что косвенно помещает данные в
1. добавить key-value запись в
@MAIN (pre-defined DBI == 1) и прочитать эту запись;2. создать именоманную subDB (открыть DBI > 1), что косвенно помещает данные в
@MAIN, что может вызвать изменение страницы с данными добавленными и прочитанными на первом шаге.
AV
20:37
Artem Vorotnikov
In reply to this message
а почему это неподобающее использование? ) т.е. что-то типа такого может поломаться?
let txn = env.begin_rw_txn();
let mut db = txn.open_db(None);
db.put("hello", "world");
let world = db.get("hello");
txn.open_db(Some("foo")).put("bar", "quux");
println!("world должно равняться {}", String::from_utf8(world).unwrap());
let txn = env.begin_rw_txn();
let mut db = txn.open_db(None);
db.put("hello", "world");
let world = db.get("hello");
txn.open_db(Some("foo")).put("bar", "quux");
println!("world должно равняться {}", String::from_utf8(world).unwrap());
Л(
20:42
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Ну формально`MAIN_DBI` (==0) сейчас не определено в API, поэтому "подабающим" использованием - нельзя.
Но если же сделать как описано всевдокодом - то
Но если же сделать как описано всевдокодом - то
world может "поломаться".
AV
20:58
Artem Vorotnikov
In reply to this message
А, т.е. это не безымянная база (name=NULL в mdbx_dbi_open)?
20:59
Так эта функция вызывается в псевдокоде, в случае foo
Л(
20:59
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Наоборот, она родимая (я уже сам забыл что и так можно...)
AV
21:00
Artem Vorotnikov
Т.е. нельзя использовать безымянную базу при включённых именованных?
21:01
Иначе получается, что это правильное использование API )
Л(
21:03
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Да, выходит что так )
От LMDB унаследовано много "кульбитов", как в API, так и в реализации...
От LMDB унаследовано много "кульбитов", как в API, так и в реализации...
AV
21:04
Artem Vorotnikov
В теории это можно выключить )
А если бы было два именованных dbi?
А если бы было два именованных dbi?
Л(
21:08
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Для именованных DBI взаимовлияние ИСКЛЮЧЕНО:
- создаются вложенные b+tree, с собственной корневой страницей для каждого;
- до коммита транзакции обновления не "всплывают" дальше этих nested roots;
- обновление
- создаются вложенные b+tree, с собственной корневой страницей для каждого;
- до коммита транзакции обновления не "всплывают" дальше этих nested roots;
- обновление
@MAIN (установка актуальных ссылок на nested b+tree для subDB) происходит только при коммите транзакции.
AV
21:11
Artem Vorotnikov
In reply to this message
Понял, спасибо!
В биндингах безымянных таблиц не будет
В биндингах безымянных таблиц не будет
3 March 2021
AV
19:04
Artem Vorotnikov
In reply to this message
подумав ещё больше, я понял, что пользователь может дважды создать
скорее всего выкину zero-cost и &mut в Database - буду при каждом
Database (`mdbx_dbi_open`) и сделать get/put/del в произвольном порядкескорее всего выкину zero-cost и &mut в Database - буду при каждом
get проверять is_dirty, и если да - копировать данные
Л(
19:12
Леонид Юрьев (Leonid Yuriev)
In reply to this message
В MithrilDB функция API открытия DBI будет принимать дополнительный параметр - указатель на пользовательский объект, и возвращать ошибку при попытке открыть DBI с использованием разных указателей.
Т.е. внутри движка будет механизм позволяющий предотвратить создание более одного пользовательского binding-интерфейса к DBI-хендлу.
Т.е. внутри движка будет механизм позволяющий предотвратить создание более одного пользовательского binding-интерфейса к DBI-хендлу.
AV
Л(
AV
19:14
Artem Vorotnikov
ну пользователь открыл таблицу, БД вписала хендл в указатель
его надо тащить через всю программу, потому что если он потеряется, повторно открыть таблицу будет невозможно
его надо тащить через всю программу, потому что если он потеряется, повторно открыть таблицу будет невозможно
Л(
19:21
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Не так:
- если передается ненулевой указатель, то есть экземпляр интерфейсного объекта, который "обёртывает" DBi-хендл в биндингах пользователя, и этот объект связывается с DBI-хендлом.
- внутри биндингов этот объект должен использоваться _вместо_ DBI-хендла, в том числе закрытие хендла должно выполняться посредством разрушения этого объекта.
- движок же просто предотвращает создание двух таких интерфейсных объектов.
- если передается ненулевой указатель, то есть экземпляр интерфейсного объекта, который "обёртывает" DBi-хендл в биндингах пользователя, и этот объект связывается с DBI-хендлом.
- внутри биндингов этот объект должен использоваться _вместо_ DBI-хендла, в том числе закрытие хендла должно выполняться посредством разрушения этого объекта.
- движок же просто предотвращает создание двух таких интерфейсных объектов.
AV
19:23
Artem Vorotnikov
а, ну то есть
let dbi1 = txn.open_db("test")?; // Ok
let dbi2 = txn.open_db("test")?; // Err(Error::Busy)
let dbi1 = txn.open_db("test")?; // Ok
let dbi2 = txn.open_db("test")?; // Err(Error::Busy)
Л(
AV
19:24
Artem Vorotnikov
let dbi1 = txn.open_db("test")?; // Ok
std::mem::drop(dbi1);
let dbi2 = txn.open_db("test")?; // Ok
std::mem::drop(dbi1);
let dbi2 = txn.open_db("test")?; // Ok
Л(
19:24
Леонид Юрьев (Leonid Yuriev)
Да, в том числе при
close вместо drop.
AV
19:25
Artem Vorotnikov
ну да, close забирает весь объект и внутри себя делает drop )
19:26
у меня была идея подумать над split borrows и чёрной магией дженериков
Л(
19:26
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Хм, на всякий - не нужно путать drop (удаление kv-таблицы из БД) и close.
AV
19:29
Artem Vorotnikov
struct Txn {
pub db1: Database,
pub db2: Database,
}
....
Rust позволяет брать mut/const ссылки на разные поля в любой комбинации (при условии что по 1 mut/N const на одно поле) - это бы решило дилемму и позволило бы сохранить zero-copy
но я уже не стал в такие дебри уходить
pub db1: Database,
pub db2: Database,
}
....
Rust позволяет брать mut/const ссылки на разные поля в любой комбинации (при условии что по 1 mut/N const на одно поле) - это бы решило дилемму и позволило бы сохранить zero-copy
но я уже не стал в такие дебри уходить
4 March 2021
AV
17:00
Artem Vorotnikov
что будет если забыть заполнить массив
MDBX_RESERVE, в нём будут случайные данные?
Л(
17:03
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Примерно да, останется то что было до выделения места.
Но могут быть и нули, если была выделена новая страница.
Но могут быть и нули, если была выделена новая страница.
AV
18:01
Artem Vorotnikov
лайфтайм у байтов в чистых страницах mdbx - dbi или вся транзакция? т.е. их можно читать после mdbx_dbi_drop?
Л(
18:04
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Технически можно читать до конца транзакции, так как данные физически расположены в зафиксированном предыдущем MVCC-снимке.
Но логически - это WTF, ибо читаем уничтоженное.
Но логически - это WTF, ибо читаем уничтоженное.
AV
18:06
Artem Vorotnikov
ну я про сами байты, а не mdbx_get )
юзер может захотеть сделать drop, при это продолжить работу с уже прочитанными данными, не копируя их
юзер может захотеть сделать drop, при это продолжить работу с уже прочитанными данными, не копируя их
Л(
5 March 2021
AV
22:39
Artem Vorotnikov
mdbx_cursor_get вернул ENODATA, хотя в доке этой ошибки нет
6 March 2021
AS
08:50
Alex Sharov
If we have read-only db file (will never open for writes) - then it’s safe open 1 tx and never close it (until db close). Yes?
Л(
15:28
In reply to this message
This is reasonable, as long as there are no other processes running writing transactions.
Otherwise you will get https://erthink.github.io/libmdbx/intro.html#long-lived-read
Otherwise you will get https://erthink.github.io/libmdbx/intro.html#long-lived-read
AV
18:33
Artem Vorotnikov
я смог починить почти все ошибки в тестах, и осталась одна - после удаления dbi, снова могу её открыть как ни в чём ни бывало
18:45
точнее так, в рамках транзакции dbi реально удалена (MDBX_NOT_FOUND), но если закоммитить и открыть новую транзакцию - там dbi снова есть, данные на месте
18:52
при этом если в рамках той же транзакции ещё записать данные в другую таблицу, то dbi будет реально удалена
18:53
@erthink получается, что dbi будет реально удалена только когда её страница будет переиспользована?
AS
18:56
Alex Sharov
по-моему это когда-то всплывало и мы решили это не чинить, потому что редкий кейс.
Л(
18:57
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Нет, конечно.
Похоже на какой-то регресс, причем свежий.
Похоже на какой-то регресс, причем свежий.
AV
19:01
Artem Vorotnikov
поправка: запись данных не влияет - влияет наличие другой базы
если создать ещё одну dbi, не важно до или после, dbi будет удалена
если создать ещё одну dbi, не важно до или после, dbi будет удалена
Л(
Л(
19:39
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Подтверждаю, есть баг - регресс в результате микро-оптимизации.
Сегодня поправлю.
Спасибо за сообщение.
https://github.com/erthink/libmdbx/issues/168
Сегодня поправлю.
Спасибо за сообщение.
https://github.com/erthink/libmdbx/issues/168
AV
19:49
Artem Vorotnikov
In reply to this message
👍🏻
у меня такой вопрос: насколько пользователям необходима возможность динамического создания/удаления dbi?
дело в том, что если от неё отказаться, ввести обязательную "карту транзакции" со списком всех dbi, то я таки смогу сделать безопасный API без копирования грязных страниц
у меня такой вопрос: насколько пользователям необходима возможность динамического создания/удаления dbi?
дело в том, что если от неё отказаться, ввести обязательную "карту транзакции" со списком всех dbi, то я таки смогу сделать безопасный API без копирования грязных страниц
19:51
получится лочить борроу-чекером отдельные dbi для put/del, а не всю транзакцию
Л(
19:59
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Видимо я не понял сути вопроса.
Отказаться от создания/eудаления dbi нельзя, вроде-бы это очевидно.
Но во многих случаях удобно вместо двух видов транзакций сделать три: read-only, read-write data & read-only schema, full read-write.
Отказаться от создания/eудаления dbi нельзя, вроде-бы это очевидно.
Но во многих случаях удобно вместо двух видов транзакций сделать три: read-only, read-write data & read-only schema, full read-write.
AV
20:00
Artem Vorotnikov
(речь на самом деле про биндинги, в mdbx ничего менять не надо)
20:05
я могу сделать при начале транзакции предсоздание dbi по этой карте транзакций
потом когда пользователь захочет работать с dbi, он берёт карту у транзакции и заимствует dbi оттуда
struct MyTxnChart {
dbi1: Database,
dbi2: Database,
}
impl RwTransaction<TxnChart> {
fn get_chart(&mut self) -> &mut TxnChart;
}
...
env.begin_rw_txn::<MyTxnChart>().get_chart().dbi1.put("hello", "world");
потом когда пользователь захочет работать с dbi, он берёт карту у транзакции и заимствует dbi оттуда
struct MyTxnChart {
dbi1: Database,
dbi2: Database,
}
impl RwTransaction<TxnChart> {
fn get_chart(&mut self) -> &mut TxnChart;
}
...
env.begin_rw_txn::<MyTxnChart>().get_chart().dbi1.put("hello", "world");
20:07
так мы делаем split mutable borrow - то что по факту и есть в mdbx, мутации в одной dbi не инвалидируют данные в другой dbi
Л(
20:15
Леонид Юрьев (Leonid Yuriev)
А, теперь понял о какой "динамике/статике" идет речь.
На мой взгляд для storage engine нельзя требовать декларативного описания БД-сущностей, так как в общем случае они могут описываться более высокоуровневой схемой получаемой от пользователя в runtime.
На вскидку, libfpta в качестве примера - там таблицы и колонки описываются динамически через API уровнем выше, т.е. описать
На мой взгляд для storage engine нельзя требовать декларативного описания БД-сущностей, так как в общем случае они могут описываться более высокоуровневой схемой получаемой от пользователя в runtime.
На вскидку, libfpta в качестве примера - там таблицы и колонки описываются динамически через API уровнем выше, т.е. описать
struct MyTxnChart либо не возможно, либо только в виде struct MyTxnChart { array[10000]: Database }.
20:16
Т.е. если такое сделать в биндингах, то это сделает невозможным их использование для реализации более высокоуровневых СУБД.
AV
21:09
Artem Vorotnikov
In reply to this message
хм, логично
в принципе подумаю над вариантом "динамической" карты, которая предоставит такой же интерфейс как сегодня
в принципе подумаю над вариантом "динамической" карты, которая предоставит такой же интерфейс как сегодня
21:10
правда, в ней наверное не будет возможности более одного раза открыть dbi (будет как в Mithril)
7 March 2021
AV
21:13
Artem Vorotnikov
Можно ли использовать данные из чистых страниц, если их ключ потом удалён через del или mdbx_dbi_drop?
Л(
21:16
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Да. Чистые страницы входят в MVCC-снимок, который точно сохранится до конца текущей пишущей транзакции.
8 March 2021
AS
04:36
Alex Sharov
In reply to this message
Это вроде киллер-фичи - что данные вынутые из базы можно без копирования использовать, чтобы не происходило в текущей/соседней транзакции.
AV
04:38
Artem Vorotnikov
In reply to this message
да, про соседние транзакции понятно
необычно то что del в текущей транзакции не инвалидирует прочитанные данные даже по этому же ключу
необычно то что del в текущей транзакции не инвалидирует прочитанные данные даже по этому же ключу
AS
04:48
Alex Sharov
In reply to this message
Тогда пользователь начнет от этого корнер кейса защищаться самым простым способом «копировать все».
04:50
Плюс: это транзакции нельзя двигать между тредами, а данные можно. Получается может возникнуть race condition если инвалидировать.
04:51
Короче внезапно - всякие безлимитные транзакции и иммутабельные данные - сильно упрощают код приложения
AV
04:53
Artem Vorotnikov
In reply to this message
ну кстати в расте не всё так просто - std::thread::spawn требует лайфтайм 'static, так что в лоб запустить тред с этими данными не получится
единственное что лучше - async рантайму не-'static - не помеха для work-stealing-а - в отличие от RW-транзакций
единственное что лучше - async рантайму не-'static - не помеха для work-stealing-а - в отличие от RW-транзакций
AS
04:57
Alex Sharov
Теоретически это должно быть удобно для раста - потому что у всех данных 1 лайфтайм=лайфтайм транзакции, а не что-то плохо формализуемое вроде «пока не удалят этот ключ».
AV
05:03
Artem Vorotnikov
In reply to this message
с одной стороны да
с другой - всё ещё остаётся кейс грязных страниц
он хоть и более нишевой, но всё равно кого-то надо будет прогибать: или крутить лайфтайм и шаманить с заимствованиями для чистых страниц - или копировать байты из грязных страниц
с другой - всё ещё остаётся кейс грязных страниц
он хоть и более нишевой, но всё равно кого-то надо будет прогибать: или крутить лайфтайм и шаманить с заимствованиями для чистых страниц - или копировать байты из грязных страниц
05:03
сейчас в биндингах второе
AS
14:03
Alex Sharov
Is it bad idea to run mdbx on virtualized disks (like Amazon Elastic Block Storage), right?
Л(
15:52
Леонид Юрьев (Leonid Yuriev)
In reply to this message
It depends on the use case, the DB size, and the chosen EBS volume type.
So it could be very slowly and/or very costly.
Nonetheless:
- it is desirable that page size match I/O block size (i.e. AFAIK 8K for most cases).
- performance in scenarios with intensive I/O will be lower due to virtualization overhead.
So it could be very slowly and/or very costly.
Nonetheless:
- it is desirable that page size match I/O block size (i.e. AFAIK 8K for most cases).
- performance in scenarios with intensive I/O will be lower due to virtualization overhead.
AS
16:02
Alex Sharov
Yes, this what i expected
NK
17:38
Noel Kuntze
Is there some way to get a callback or something from the lib if a specific value in the DB is deleted?
17:38
That way I could return read-only memoryview objects (without copying the value from the DB) and invalidate them if the value is deleted from the DB. If we can't do that, I'll need to copy the value from the DB each time it's retrieved.
17:40
(Talking about making Python bindings for mdbx)
AS
18:13
Alex Sharov
What means “invalidate” in your case?
NK
18:15
Noel Kuntze
raise IndexError Python Exception when trying to access the data from the memoryview (because it's gone)
AS
18:19
Alex Sharov
But this value was read from db before it been deleted. Means value is valid - same as you did copy the value (just for free - without copy).
NK
18:22
Noel Kuntze
A Python Memoryview is a wrapper around either a native Python object (that is garbage collected and refcounted) or around a C buffer (char *ptr, size_t len). The latter is not refcounted or garbage collected. So we can't increase any reference count there and make sure to keep that memory in that location (also because it's in the DB, the DB will eventually reuse that particular memory address for other values or keys). So when the memoryview is created, no data is copied from the object or buffer that it is wrapped around.
AS
18:24
Alex Sharov
In reply to this message
Memory will stay valid until end of transaction (doesn’t matter did app delete key or not). After end of transaction - any memory can become invalid (doesn’t matter did app delete key or not).
NK
18:25
Noel Kuntze
Hmmmh. So I rely on the user not to do funny business and copy the data he/she wants before ending the transaction?
18:25
I'll see what I can do to make sure there is a native Python Exception if the user does funny things.
AS
18:26
Alex Sharov
If you need data outside of transaction - do copy, if need data only during transaction - can don’t copy.
NK
18:26
Noel Kuntze
Makes sense, thank you.
18:27
I'll just make sure to only allow storing of serializable objects and store the serialized version of them.
11 March 2021
NK
18:49
Noel Kuntze
Hmmh. Why is there no convenience function for making a whole operate_parameters (except the integers) from flags?
12 March 2021
NK
22:22
Noel Kuntze
Is it deliberate that calling
mdbx_env_info_ex on an env that was created successfully immediately before by using mdbx_env_create crashes the program?
22:23
(Also: How do I get debug symbols in the mdbx-example binary? I tried passing CFLAGS and so on, but it didn't get me any symbols)
NK
23:00
Noel Kuntze
Got it. Crash in core.c:5182
23:00
code from devel branch and master branch both crash
23:03
5118 MDBX_meta *head = mdbx_meta_recent(mode, env, m0, m1);
23:13
I opened issues #170 and #171 about the two crashes/problems I found.
13 March 2021
Л(
12:59
Леонид Юрьев (Leonid Yuriev)
In reply to this message
In general this is right approach.
On the other hand, it should be able to read-write non-Python objects.
On the other hand, it should be able to read-write non-Python objects.
13:09
In reply to this message
Since
operate_parameters contains more options that could defined by flags.
NK
13:12
Noel Kuntze
In reply to this message
The api takes and returns only bytes types objects. That's the simplest, most versatile primitive I can implement. What the user makes out of the bytes is then his/hers decision.
Btw, the api only stores the bytes, not the whole Bytes python object.
Btw, the api only stores the bytes, not the whole Bytes python object.
Л(
13:13
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Historically no, since
So there is no info to be returned by
+ On the other hand, this is not reason to crash, i.e. this is a minor bug (I will fix today).
mdbx_env_create() create just a "handle" without binding to the some DB.So there is no info to be returned by
mdbx_env_info().+ On the other hand, this is not reason to crash, i.e. this is a minor bug (I will fix today).
NK
13:14
Noel Kuntze
In reply to this message
I wanted to figure out in a quick way what the geometry default values were because of that other issue I had.
Л(
13:20
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Depending on the tools used (compiler and linker) and flags/options, debugging symbols can be at the end of executable files, or separately.
For gcc/clang at least the
For gcc/clang at least the
-g option should be used, and symbols will be inside an executables by default.
Melbourne Channel Moderator invited Melbourne Channel Moderator
MM
21:24
Melbourne Channel Moderator
Trying to write a replicable db with libmdbx. should i put a separate sequential replication log (not libmdbx) alongside libmdbx or is there some special mechanism i miss or better suggestion on how to do this replication for libmdbx? because would like to hv failsafe downtime across multiple server nodes.
21:25
and... also i think with a replication log, means i can replicate means i can do read only db on one libmdbx instance and one for pure write only (master)
Л(
22:34
Леонид Юрьев (Leonid Yuriev)
In reply to this message
There is no WAL in libmdbx and no other log/journal that can be used for replication (i.e. to replay transactions on a remote side).
Therefore, for a changelog-based replication, you must maintain your own log, which can be either inside the DB or separately, and each option has its pros and cons:
1. The log inside the same DB is easier to implement and use, but on average the WAF (write amplification factor) will be larger.
This is not a suitable solution for update/write-intensive scenarios with requirements for data durability (since all b-tree based DB engines not good for such cases).
2. With the log outside of DB you may engage compression and use benefits of
This way you will get better (i.e. less) WAF and provide (relatively) high TPS with data durability.
However, this way is not easy to implement, especially if you didn't made it before.
So you should have the reasons to do a replication on the libmdbx basis, i.e. in the other words - don't use (semi)ready solutions but get several benefits from the libmdbx instead.
Therefore, for a changelog-based replication, you must maintain your own log, which can be either inside the DB or separately, and each option has its pros and cons:
1. The log inside the same DB is easier to implement and use, but on average the WAF (write amplification factor) will be larger.
This is not a suitable solution for update/write-intensive scenarios with requirements for data durability (since all b-tree based DB engines not good for such cases).
2. With the log outside of DB you may engage compression and use benefits of
O_APPEND flag.This way you will get better (i.e. less) WAF and provide (relatively) high TPS with data durability.
However, this way is not easy to implement, especially if you didn't made it before.
So you should have the reasons to do a replication on the libmdbx basis, i.e. in the other words - don't use (semi)ready solutions but get several benefits from the libmdbx instead.
22:43
@MelbourneModerator
In addition, sometimes "content replication/synchronization" can be useful instead of "traditional transaction-replay" replication.
Take look to the http://www.rfc-base.org/rfc-4533.html for more information (but don't use or clone openldap's implementation, since it have a lot of bugs!).
In addition, sometimes "content replication/synchronization" can be useful instead of "traditional transaction-replay" replication.
Take look to the http://www.rfc-base.org/rfc-4533.html for more information (but don't use or clone openldap's implementation, since it have a lot of bugs!).
MM
22:46
Melbourne Channel Moderator
talking about write amplification, i dont see any documentation that talks about tihs or how to do (tweak) the setting. i'm getting around 2x of write amplification for data stored in libmdbx using it as a simple kv store. this "appears" to be a lot.
22:48
the rfc-base.org link u sent it not working
22:51
what do u suggest for content replication / sync? coz transaction replay is definitely what most people want since this is "ACID" db. basically will want to implement as master-slave situation with data consistency.
i'm proficient enough to write my own wal etc.
i've written memory kv store, will be using libmdbx to back the storage on disk and do replication so to have master-slave redundant node (or be used in read only slave and write only master)
i'm proficient enough to write my own wal etc.
i've written memory kv store, will be using libmdbx to back the storage on disk and do replication so to have master-slave redundant node (or be used in read only slave and write only master)
Л(
22:59
In reply to this message
These values are known from general DB theory and b+tree properties.
In short, for a b-tree with MVCC-based isolation, updating a single record requires updating all pages from the root to the leaf with the target record, i.e. the WAF in pages == the height of b-tree.
In short, for a b-tree with MVCC-based isolation, updating a single record requires updating all pages from the root to the leaf with the target record, i.e. the WAF in pages == the height of b-tree.
Л(
23:33
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Replay-based replication has known flaws:
- you should store the log since the last "synchronized point", i.e. in some cases it can be large than the data itself.
- in some cases log-replay is costly than just copy the whole data.
- some application don't need serialized view of data, but just an eventually consistent set of items (for instance LDAP).
On the other hand, content-based replication/synchronization required support for long read transaction and large write transaction with full ACID-ly isolation.
You either have to accept this or find a compromise(s).
- you should store the log since the last "synchronized point", i.e. in some cases it can be large than the data itself.
- in some cases log-replay is costly than just copy the whole data.
- some application don't need serialized view of data, but just an eventually consistent set of items (for instance LDAP).
On the other hand, content-based replication/synchronization required support for long read transaction and large write transaction with full ACID-ly isolation.
You either have to accept this or find a compromise(s).
23:42
@MelbourneModerator, to continue:
In MithrilDB (the next version of MDBX), I plan to implement:
- built-in WAL (which could be placed on separated HDD with cold data items).
- hidden row attributes for 4533-based synchronization.
- transport-independent (i.e. sockets) and eventloop-independent implementation of optional replay-based synchronization with optional fallback to content-based.
This cannot be done in MDBX, as drastic changes are required with a change both in the API and the DB format.
Therefore libmdbx is not good enough candidate to integration within Tarantool (for instance as part of GSoC "b+tree for Tarantool").
However, such PoC-like integration will allow me to better understand how MithrilDB should be organized.
In MithrilDB (the next version of MDBX), I plan to implement:
- built-in WAL (which could be placed on separated HDD with cold data items).
- hidden row attributes for 4533-based synchronization.
- transport-independent (i.e. sockets) and eventloop-independent implementation of optional replay-based synchronization with optional fallback to content-based.
This cannot be done in MDBX, as drastic changes are required with a change both in the API and the DB format.
Therefore libmdbx is not good enough candidate to integration within Tarantool (for instance as part of GSoC "b+tree for Tarantool").
However, such PoC-like integration will allow me to better understand how MithrilDB should be organized.
14 March 2021
MM
01:29
Melbourne Channel Moderator
to be honest, making libmdbx as it is is "good enough", (with the incremental value as on the github issue enhnacement)
just need to make sure it's stable with wider adoption for bug free stability and it'll be a very solid foundation to build a lot of things on.
as for mithril, wal, replication etc. complications can be kept separately. hope that someday libmdbx will be "complete" like archived boltdb (though bolt (not the etcd bbolt) has some "bugs")
as it is, i'm running fine now with libmdbx in test use case. without "replication", it's not very reassuring putting all data into it, afterall ACIDity is important BUT you should not implement this as part of libmdbx of course. keeping it like boltdb direction is the right way to do. however, "sidecar" like wal / replication log etc should of course have suggestions from the author of libmdbx is correct. so thx for the input.
just my thoughts.
just need to make sure it's stable with wider adoption for bug free stability and it'll be a very solid foundation to build a lot of things on.
as for mithril, wal, replication etc. complications can be kept separately. hope that someday libmdbx will be "complete" like archived boltdb (though bolt (not the etcd bbolt) has some "bugs")
as it is, i'm running fine now with libmdbx in test use case. without "replication", it's not very reassuring putting all data into it, afterall ACIDity is important BUT you should not implement this as part of libmdbx of course. keeping it like boltdb direction is the right way to do. however, "sidecar" like wal / replication log etc should of course have suggestions from the author of libmdbx is correct. so thx for the input.
just my thoughts.
MM
08:49
Melbourne Channel Moderator
is there a special reason why u always mention tarantool? will libmdbx be used as tarantool backend? just curious
Anton Ermak invited Anton Ermak
Л(
21:41
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Some time ago, this topic (using libmdbx as Tarantool backend) was discussed, including here.
And now the creation of a b+tree engine for Tarantool is included in this year's GSoC.
So just in case, I repeat what I said earlier about libmdbx and MithrilDB.
And now the creation of a b+tree engine for Tarantool is included in this year's GSoC.
So just in case, I repeat what I said earlier about libmdbx and MithrilDB.
В
22:16
Виталий
Do not use MDBX databases on remote filesystems, even between processes on the same host.
Правильно понял, что только один процесс может читать-писать базу, но в рамках одного процесса, несколько тредов могут владеть транзакцией (каждому отдельную)?
Правильно понял, что только один процесс может читать-писать базу, но в рамках одного процесса, несколько тредов могут владеть транзакцией (каждому отдельную)?
Roman Inflianskas invited Roman Inflianskas
Л(
22:27
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Про треды и транзакции написано чуть выше, cм "One thread - One transaction".
На "сетевых дисках" базу можно открывать в двух режимах:
1) В эксклюзивном (с флагом
2) В режиме только для чтения, когда сам сетевой ресурс не доступен для записи. При этом с БД смогут работать несколько процессов, с любым кол-вом тредов внутри.
+ MDBX делает максимум проверок с тем чтобы не допустить некорректное использование БД на сетевых дисках, но при желании эти проверки можно обойти.
Кроме этого, не во всех ОС есть возможность проверить находиться ли файл на локальном диске или "на сетевом".
Поэтому тут нужно действовать продуманно/осторожно, и конечно не отключать проверки "патчами" (как когда-то было сделано в мессенджере Miranda NG).
На "сетевых дисках" базу можно открывать в двух режимах:
1) В эксклюзивном (с флагом
MDBX_EXCLUSIVE). При этом с БД сможет работать только один процесс с любым кол-вом тредов внутри. 2) В режиме только для чтения, когда сам сетевой ресурс не доступен для записи. При этом с БД смогут работать несколько процессов, с любым кол-вом тредов внутри.
+ MDBX делает максимум проверок с тем чтобы не допустить некорректное использование БД на сетевых дисках, но при желании эти проверки можно обойти.
Кроме этого, не во всех ОС есть возможность проверить находиться ли файл на локальном диске или "на сетевом".
Поэтому тут нужно действовать продуманно/осторожно, и конечно не отключать проверки "патчами" (как когда-то было сделано в мессенджере Miranda NG).
В
22:43
Виталий
In reply to this message
Вот у меня локалхост и на нем два процесса. Один пишет другой читает. Я так понял, что это нормально, если сетевые протоколы не задействовать?
Л(
MM
23:07
Melbourne Channel Moderator
sorry for asking very amateur question. is it possible to get the total number of items in the database?
i'm wondering when is most appropriate to use dupsort / dupfix
or multi wrapper functions
i'm wondering when is most appropriate to use dupsort / dupfix
or multi wrapper functions
23:09
Vitaly
Leonid Yuriev
About threads and transactions is written a little higher, see "One thread - One transaction". On "network drives", the database can be opened in two p
Here I have a localhost and there are two processes on it. One writes the other reads. As far as I understand, it's okay if you don't use network protocols?
Leonid Yurievadmin
Vitaly
Here I have a localhost and there are two processes on it. One writes the other reads. I understand that this is normal if the network protocols are not
Yes, that's okay (c)
Leonid Yuriev
About threads and transactions is written a little higher, see "One thread - One transaction". On "network drives", the database can be opened in two p
Here I have a localhost and there are two processes on it. One writes the other reads. As far as I understand, it's okay if you don't use network protocols?
Leonid Yurievadmin
Vitaly
Here I have a localhost and there are two processes on it. One writes the other reads. I understand that this is normal if the network protocols are not
Yes, that's okay (c)
23:11
In reply to this message
how can memory being used effectively / optimumly? or how should txn begin / end for optimum efficiency for large database with mulitple keys-value inside?
when is good to use dupsort / dupfix etc?
when is good to use dupsort / dupfix etc?
Л(
23:19
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Yes, see
The main benefit of
For example, if there are several million rows in the database and only a few unique values in an indexed column, then with DUPSORT the index will contain a few nested b-trees (one for each unique value) with ordered lists of the corresponding rowids.
mdbx_dbi_stat(), https://erthink.github.io/libmdbx/group__c__statinfo.html#ga7582460beceb078cec8b515a5280d568.The main benefit of
dupsort feature is when building (secondary or non-clustered) indexes for low-cardinality data.For example, if there are several million rows in the database and only a few unique values in an indexed column, then with DUPSORT the index will contain a few nested b-trees (one for each unique value) with ordered lists of the corresponding rowids.
MM
23:34
Melbourne Channel Moderator
In reply to this message
Ok thx. Got it. What's dup fixed for then? In terms of memory usage is better for fixed space?
Л(
23:37
Леонид Юрьев (Leonid Yuriev)
In reply to this message
DUPFIXED will save a few bytes per item, since length of data is fixed and will not be stored internally.
MM
23:42
Melbourne Channel Moderator
For long running write intensive txn, when is a good time to ... stop and run another transaction again?
23:43
Mmap of file is only segment read into memory. Correct? If I do binary search is more cost effective mem use than linear for large data sets?
Л(
23:51
Леонид Юрьев (Leonid Yuriev)
In reply to this message
For dupsort the
mdbx_cursor_count() and mdbx_get_ex() may be useful, since return number of duplicates/multivalues.
15 March 2021
Л(
00:01
Леонид Юрьев (Leonid Yuriev)
In reply to this message
In short, no.
Simplified:
- the OS kernel will cache the data mapped to memory (aiming to LRU policy, taking in account available memory and other activity).
- MDBX will engage readahead when reasonable.
- internally b-tree engages binary search, however b-tree tends to random patterns of page access.
Simplified:
- the OS kernel will cache the data mapped to memory (aiming to LRU policy, taking in account available memory and other activity).
- MDBX will engage readahead when reasonable.
- internally b-tree engages binary search, however b-tree tends to random patterns of page access.
AE
02:38
Anton Ermak
https://www.opennet.ru/opennews/art.shtml?num=52147
MDBX совсем не подойдет, если:
- много изменений, которые нельзя потерять = нужна БД с WAL.
Привет. Подскажите, почему это проблема?
MDBX совсем не подойдет, если:
- много изменений, которые нельзя потерять = нужна БД с WAL.
Привет. Подскажите, почему это проблема?
Л(
02:59
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Имелась в виду ситуация, когда требуется фиксировать (т.е. записывать на диск) много пишущих транзакций в секунду.
Проблема в том, что в b-tree с MVCC (коим является MDBX) каждое изменение (вставка, удаление, обновление) требует изменения всей цепочки страниц: от листовой (где лежат данные), до корня дерева.
Т.е. кол-во страниц, которые необходимо записать на диск после одного точечного изменения, плюс/минус равно высоте дерева.
Поэтому получается относительно большой трафик данных на диск.
Причем записываемые/обновляемые страницы будут стремиться к случайному порядку.
Для сравнения, в БД с WAL запись в журнал происходит преимущественно последовательно, а для мелких транзакцию объем записываемых данных может не превышать одной страницы.
Соответственно, проблема крайне актуальна для HDD и фактически не актуальна для https://software.intel.com/content/www/us/en/develop/topics/persistent-memory.html
Проблема в том, что в b-tree с MVCC (коим является MDBX) каждое изменение (вставка, удаление, обновление) требует изменения всей цепочки страниц: от листовой (где лежат данные), до корня дерева.
Т.е. кол-во страниц, которые необходимо записать на диск после одного точечного изменения, плюс/минус равно высоте дерева.
Поэтому получается относительно большой трафик данных на диск.
Причем записываемые/обновляемые страницы будут стремиться к случайному порядку.
Для сравнения, в БД с WAL запись в журнал происходит преимущественно последовательно, а для мелких транзакцию объем записываемых данных может не превышать одной страницы.
Соответственно, проблема крайне актуальна для HDD и фактически не актуальна для https://software.intel.com/content/www/us/en/develop/topics/persistent-memory.html
MM
03:24
Melbourne Channel Moderator
just finished testing libmdbx. very very good performance etc.
but 2 things not very sure. pls help me understand these two areas
1. what do you recommend for a key with 32bytes and value of 32bytes' page size to be? optimally?
2. the limit of 128TB for 64kb page size... means how much data can i store with key of 32 bytes and value of 32 bytes effectively? or should I just use lower page size since the limit is at number of items?
128TB / 64bytes (32b for key, 32b for value) = 2 000 000 000 000 effective items storable <- is this a good estimation?
great piece of work. if there's no limit on space and page size will be perfect.
4. if there's a limit to 128TB, does that mean i should create multiple db files so i can have more than 128TB storage?
5. Advisable to split up file db if keys values are unique?
but 2 things not very sure. pls help me understand these two areas
1. what do you recommend for a key with 32bytes and value of 32bytes' page size to be? optimally?
2. the limit of 128TB for 64kb page size... means how much data can i store with key of 32 bytes and value of 32 bytes effectively? or should I just use lower page size since the limit is at number of items?
128TB / 64bytes (32b for key, 32b for value) = 2 000 000 000 000 effective items storable <- is this a good estimation?
great piece of work. if there's no limit on space and page size will be perfect.
4. if there's a limit to 128TB, does that mean i should create multiple db files so i can have more than 128TB storage?
5. Advisable to split up file db if keys values are unique?
03:25
i dont think i hv anymore questions after these.
AE
03:29
Anton Ermak
In reply to this message
Да, это понятно. Спасибо. Меня насторожила строчка "которые нельзя потерять", подумал что есть вероятность потери данных, что вроде бы после фиксации не должно быть.
Л(
04:24
Леонид Юрьев (Leonid Yuriev)
In reply to this message
1. Five factors to choose the page size:
- requirements for keys length, i.e. maximum ≈¼ pagesize.
- to reduce the length of lists of page numbers (currently its requires linear sequences of pages to store).
- expected I/O block size (4K or 8K for most SSD, etc).
- expected default OS page size (4K for most platforms).
- expected DB size, i.e. no more than 2^31 pages.
2. No, your estimate is not quite correct.
You should take into account costs of a tree structure, i.e. the branch-pages.
3. MDBX is not designed for huge databases.
On the other hand, the 2^31 page limit reduces many overhead costs.
4. Yes, perhaps, but it must be your decision.
5. In general, this is impractical if there are no obvious reasons:
- data does not fit into a one database;
- if the use cases involves massive deletion operations (hundreds of gigabytes per transaction), then tl;dr; this increases a tolerance to DB fragmentation.
- requirements for keys length, i.e. maximum ≈¼ pagesize.
- to reduce the length of lists of page numbers (currently its requires linear sequences of pages to store).
- expected I/O block size (4K or 8K for most SSD, etc).
- expected default OS page size (4K for most platforms).
- expected DB size, i.e. no more than 2^31 pages.
2. No, your estimate is not quite correct.
You should take into account costs of a tree structure, i.e. the branch-pages.
3. MDBX is not designed for huge databases.
On the other hand, the 2^31 page limit reduces many overhead costs.
4. Yes, perhaps, but it must be your decision.
5. In general, this is impractical if there are no obvious reasons:
- data does not fit into a one database;
- if the use cases involves massive deletion operations (hundreds of gigabytes per transaction), then tl;dr; this increases a tolerance to DB fragmentation.
04:26
Ruby bindings is available now by Mahlon E. Smith.
https://rubygems.org/gems/mdbx/
https://rubygems.org/gems/mdbx/
MM
05:23
Melbourne Channel Moderator
ok thx
05:33
final question
Value size:
minimum 0,
maximum 2146435072 (0x7FF00000) bytes for maps, ~2GB
≈¼ pagesize for multimaps (1348 bytes for default 4K pagesize, 21828 bytes for 64K pagesize).
sorry i'm a bit too new. this is the last question. what is multimaps or why is it so much lower than maps? one is 2gb one is 1/4 of page size. can you pls elaborate how to do / use multimaps?
Value size:
minimum 0,
maximum 2146435072 (0x7FF00000) bytes for maps, ~2GB
≈¼ pagesize for multimaps (1348 bytes for default 4K pagesize, 21828 bytes for 64K pagesize).
sorry i'm a bit too new. this is the last question. what is multimaps or why is it so much lower than maps? one is 2gb one is 1/4 of page size. can you pls elaborate how to do / use multimaps?
AS
05:52
Alex Sharov
In reply to this message
"multipmaps" word means same as "dupsort". When use Dupsort - values are stored as keys in sub-b-tree. Keys are have limitation on size = 1/4 page. This is reason why in Dupsort values have same limitation as keys in "Normal" DBI's.
MM
05:54
Melbourne Channel Moderator
≈¼ pagesize for multimaps (1348 bytes for default 4K pagesize, 21828 bytes for 64K pagesize).
this mentioned only about Value not Keys.
this mentioned only about Value not Keys.
AS
05:55
Alex Sharov
In reply to this message
"When use Dupsort - values are stored as keys in sub-b-tree"
05:55
values are keys - of sub-b-tree, when using Dupsort
MM
05:56
Melbourne Channel Moderator
oh... ok. so the values are the keys... each key is 1348b or 21828b. but total values of keys can be up to 2gb?
AS
05:58
Alex Sharov
In reply to this message
there is no "values" in Dupsort - only keys in main b-tree and keys in sub-b-trees (can change word "b-tree" to "table" or "collection" for better understanding). That's it - no values in this scheme. Values are exist only in non-Dupsort.
06:00
it sounds a bit weird, but it doesn't change much. just in Dupsort - keys are searchable and "values" withing 1 key are also searchable - because "values" are stored as "keys".
06:02
Dupsort - is feature to build inverted indices - and usually you don't store huge values in inverted indices.
MM
06:02
Melbourne Channel Moderator
i see. i get it now
06:03
so how big can the array list be? up to 2gb total?
AS
MM
06:03
Melbourne Channel Moderator
... means how many items in the list / array?
06:03
oh... hmm... ok
MM
06:22
Melbourne Channel Moderator
libmdbx manages the database size according to parameters specified by mdbx_env_set_geometry() function, ones include the growth step and the truncation threshold.
Can i ask why do we need automatic on the fly db size adjustment? i set the highest setting so i can forget about trying to get problems later.
env.SetGeometry(-1, -1, int(128000000000000), int(10240000), 1024000, 64*1024)
this is my setting. what can be the issue with it?
Can i ask why do we need automatic on the fly db size adjustment? i set the highest setting so i can forget about trying to get problems later.
env.SetGeometry(-1, -1, int(128000000000000), int(10240000), 1024000, 64*1024)
this is my setting. what can be the issue with it?
AS
06:28
Alex Sharov
In reply to this message
Windows can't growth automatically mmap file. Maybe integer overflow. There are many-many requrements: https://github.com/erthink/libmdbx/blob/master/src/core.c#L10695
MM
06:31
Melbourne Channel Moderator
ok. so as long as not using windows we dont hv to care about this right? coz i'm only linux / android / iphone person.
AS
06:32
Alex Sharov
you don't have chose 🙂 can't avoid setGeometry method
MM
06:33
Melbourne Channel Moderator
env.SetGeometry(-1, -1, int(128000000000000), int(10240000), 1024000, 64*1024)
is this ok once and for all?
is this ok once and for all?
06:34
any problems / gotchas?
AS
06:55
Alex Sharov
I don't know - hard to count zeroes by eyes. can leave "shrinkThreshold" -1 to use default.
MM
07:02
Melbourne Channel Moderator
trying to build a replication log for libmdbx for high availability in clusters.
any suggestions on how to get it done or possible to use some built in feature of libmdbx i missed?
any suggestions on how to get it done or possible to use some built in feature of libmdbx i missed?
AS
07:03
no replication log ❤️
MM
07:04
Melbourne Channel Moderator
that's why i'm asking here. i'm trying to do that. any suggestions on how to get it done or possible to use some built in feature of libmdbx i missed?
AS
07:08
Alex Sharov
Yuri will answer better. But I think there is no API for replication or subsribtion to changes or WAL.
В
07:09
Виталий
In reply to this message
Т.е. получается, что-то вроде колоночной бд?
ключ1{ключ1.1:значение1.1, ключ1.2:значение1.2} ?
ключ1{ключ1.1:значение1.1, ключ1.2:значение1.2} ?
AS
07:09
Alex Sharov
mdbx_env_pgwalk is some low-level primitive - but it's not enough for replication.
В
AS
07:12
Alex Sharov
In reply to this message
На самом деле вот так - Ключ1{Ключ1.1, Ключ1.2, ...}.
Используется для поисковых индексов - признак1{встречался в объектах с id: 1,5,32,57,138,...}
Используется для поисковых индексов - признак1{встречался в объектах с id: 1,5,32,57,138,...}
07:13
только внутри этого списка доступны все операции базы данных - как на обычных ключах
07:14
поиск, перебор курсором, удаление любого одного, вставка в середину, .... все как с обычными ключами - потому что физически это и есть обычные ключи только в под-коллекции
07:15
размер под-коллекций не ограничен
MM
08:03
Melbourne Channel Moderator
it's a great piece of work after i read through the doc. thx for the software. as it is, need to be proven complete bulletproof and maybe fine tune for performance / mem usage will do i guess.
if it doesnt hv corruption issues, then it's the best db overall.
if it doesnt hv corruption issues, then it's the best db overall.
08:18
i'm not good enough to write in c++. only good enough for using the golang binding. so cant write on top of db...
i have question memory usage "buffer" in "your transaction already is a buffer".
i understand how btree works but i'm not sure how mem is mapped to the disk file.
if i use map (dupsort), if my map is 1,000,000 items of 32bytes each, i want to access item 888,888. in the "memory" buffer txn, how much memory is being used for this "memory mapped" file "page"? the page size of 64kb (my page size)?
i'm trying to figure how best to optimally use the memory in very very very large db. like 60TB or so. whether to do dupsort for multi value keys in a single hash map of 1,000,000 items or split up into segments etc to fit page size etc. so any guidance or suggestions on how memory is used is appreciated.
i have question memory usage "buffer" in "your transaction already is a buffer".
i understand how btree works but i'm not sure how mem is mapped to the disk file.
if i use map (dupsort), if my map is 1,000,000 items of 32bytes each, i want to access item 888,888. in the "memory" buffer txn, how much memory is being used for this "memory mapped" file "page"? the page size of 64kb (my page size)?
i'm trying to figure how best to optimally use the memory in very very very large db. like 60TB or so. whether to do dupsort for multi value keys in a single hash map of 1,000,000 items or split up into segments etc to fit page size etc. so any guidance or suggestions on how memory is used is appreciated.
08:19
In reply to this message
this question specifically target updates in txn only. read... i'm sure it just does cursor pointer to the btree location
AS
08:21
Alex Sharov
yep, all by pages. pagesize - you define, default 4kb. if your keys are co-located - then you will read from the same page. OS will take care evictions of Pages from RAM. amount of RAM - doesn't depend on how big is your DB - it depends on how big is "hot part of your DB" if you never read/write 59.9TB because it's some historical data - then you will now waste RAM on it. OS will know which pages are "hot" and which are "cold" and will use all available RAM and will evict if OS need RAM for another application on this machine.
08:22
If you don't use
MDBX_WRITEMAP flag - then "writes" are actually "reads+copy in RAM" - so totally same rules of page size, page eviction, ...
MM
08:24
Melbourne Channel Moderator
In reply to this message
does that mean if ram is overused, the txn may be lost if it's evicted on oom situation? i tried creating a db just now with 12gb db on my 5gb free out of 8gb ram and the mem usage for the golang application is very high while CPU load is also v high BUT i cant get it to work anymore. it just like... "doing something there but db file not expanding".
08:25
i see it now. the pointer cursor on pages. i get it now.
AS
08:26
Alex Sharov
Nothing lost, just OS will flush to Disk part of tx which not “hot enough”. Then TX is basically unlimited.
08:27
Check your geometry - don’t know.
08:28
Pages memory doesn’t belongs to Go application it belongs to OS.
MM
08:29
Melbourne Channel Moderator
in that case... possible to fork one > 128TB limit? this seems like a good thing for almost anything.
AS
08:30
Alex Sharov
Maybe.. i have only 1 Tb case, so i don’t really care about limit.
08:34
Many limitations - only 1 write tx per time, too long read transactions will cause db growth - to keep consistency and isolation - it stores all versions of data since slowest tx start. So, short transactions is a good things, but even 1 min it’s short-enough.
08:35
Also because PageCache belongs to OS - then if another app will read your db on the same machine - os can re-use same pages.
MM
08:38
Melbourne Channel Moderator
u are suggesting splitting up the db into multiple db files is better then. if this automatic file splitting is built in will be great. partitioning db files by % num of cores-threads (1 tx per thread)
08:39
sounds good? shld be a feature opt then
SetThreadsNum()
SetThreadsNum()
AS
08:44
Alex Sharov
Only if you need parallel writes. We don’t need. No parallel writes - no locks, no conflicts, ... - faster writes. Bottleneck will-be the Disk anyway. Then you can just run multiple go apps on different servers and keep on each machine only data of this shard. MDBX_APPEND can speedup inserts.
MM
08:46
Melbourne Channel Moderator
👌
09:01
In reply to this message
Shrink threshold -1 means don't shrink? Anything zero or lower means no compaction right?
AS
MM
09:26
Melbourne Channel Moderator
Sry missed the bottom part
09:26
Thx
MM
12:46
Melbourne Channel Moderator
everything sounds and feels too good to be true.
one final final question... is memory reclaimation automatic? coz i read somewhere lmdb dirty cache will only be reclaimed if it hits 100%. (if libmdbx works this way too, my vps hosting will kill the process because of oom-killer) so does mem get reclaimed before hitting 100%?
one final final question... is memory reclaimation automatic? coz i read somewhere lmdb dirty cache will only be reclaimed if it hits 100%. (if libmdbx works this way too, my vps hosting will kill the process because of oom-killer) so does mem get reclaimed before hitting 100%?
Л(
13:00
Леонид Юрьев (Leonid Yuriev)
In reply to this message
I don't know anything about the "LMDB dirty cache".
However, you should not ask questions like "Why is the dawn happening?".
If you need to understand how MDBX works, then there is about the only way:
1. Learn how LMDB works, i.e. study the available information, including all presentations by Howard Chu and all articles by Oren Eini.
The https://en.wikipedia.org/wiki/Lightning_Memory-Mapped_Database may useful to start from.
2. Explore improvements to MDBX relative to LMDB.
In most cases, it is enough to read the README and documentation.
However, you should not ask questions like "Why is the dawn happening?".
If you need to understand how MDBX works, then there is about the only way:
1. Learn how LMDB works, i.e. study the available information, including all presentations by Howard Chu and all articles by Oren Eini.
The https://en.wikipedia.org/wiki/Lightning_Memory-Mapped_Database may useful to start from.
2. Explore improvements to MDBX relative to LMDB.
In most cases, it is enough to read the README and documentation.
MM
13:05
Melbourne Channel Moderator
ok. i think application specific use case then. not lmdb / mdbx.
thx for the guidance.
thx for the guidance.
MM
23:22
Melbourne Channel Moderator
if for example i SetGeometry to 1GB max.
1. if the file size is 2GB, it will not be able to write to the db. correct?
2. what happens to reads? does it affect reads? if i have 999mb writing transaction, i have 10 threads reading another 888mb file, will the read be affected too?
1. if the file size is 2GB, it will not be able to write to the db. correct?
2. what happens to reads? does it affect reads? if i have 999mb writing transaction, i have 10 threads reading another 888mb file, will the read be affected too?
16 March 2021
Л(
00:50
Леонид Юрьев (Leonid Yuriev)
In reply to this message
It is impossible to shrink the DB file to be less than the last used page, including all MVCC-snapshots that are currently used by any of reader(s).
MM
01:51
Melbourne Channel Moderator
ok thx
MM
02:28
Melbourne Channel Moderator
is there a possibility to limit the tree height? or it's "fixed"
Л(
02:30
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Please READ the https://en.wikipedia.org/wiki/B-tree
AE
02:30
Anton Ermak
In reply to this message
Just got interested in implementation details. Thank you for pointing out to the Ayende blog! Although it’s not so deep enough to understand inner machinery but the approach and discussion with the LMDB author were pretty enjoyable.
Also I’ve cloned the lmdb and checked the source. Actually the code looks like from the another planet or generated from the high level language at the first (and the second too) glance. How much time did you spend to understand the source?
Also I’ve cloned the lmdb and checked the source. Actually the code looks like from the another planet or generated from the high level language at the first (and the second too) glance. How much time did you spend to understand the source?
MM
02:31
Melbourne Channel Moderator
In reply to this message
I did. Ok. I know. Sry for asking that question
MM
06:26
Melbourne Channel Moderator
sry to ask here again, i canf seem to find easily online.
transaction.put(b'mykey', b'value1')
transaction.put(b'mykey', b'value1')
transaction.put(b'mykey', b'value2')
this is for dupsort = true. so does mykey have 2 values or 3 values? means duplicate value1 is overwritten? is there any settings to make value unique or duplicate possible?
i normally only see value1,2 and 3 in examples.
transaction.put(b'mykey', b'value1')
transaction.put(b'mykey', b'value1')
transaction.put(b'mykey', b'value2')
this is for dupsort = true. so does mykey have 2 values or 3 values? means duplicate value1 is overwritten? is there any settings to make value unique or duplicate possible?
i normally only see value1,2 and 3 in examples.
06:27
to do more than 1 write per transaction, is doing a write buffer the only way to work around this issue? i'm using golang. curious if there are other ways to get it to work around to read and write at the same time flushing to db every 1s or when txn hits a certain byte
AS
06:41
Alex Sharov
In reply to this message
Values are unique in dupsort - because physically they stored as keys and keys are unique. No settings here.
06:42
What’s wrong with mdbx_env_set_syncperiod method?
MM
AV
17:08
Artem Vorotnikov
do all
mdbx_cursor_get ops set data? which of those set not just data, but key as well?
Л(
17:11
Леонид Юрьев (Leonid Yuriev)
In reply to this message
depending on the operation, see description(s)
AV
17:15
Artem Vorotnikov
In reply to this message
i've been looking at the docs for the past hour
the answer to this question is not in the docs
the answer to this question is not in the docs
Л(
17:21
Леонид Юрьев (Leonid Yuriev)
In reply to this message
what operation(s) do you have doubts about?
AV
17:22
Artem Vorotnikov
all of them?...
the docs only describe mutations of cursor's internal state, not what each op returns
the docs only describe mutations of cursor's internal state, not what each op returns
Л(
17:33
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Hmm, the name of function is "cursor get", i.e., it returns both the key and the data, unless something else is described for a specific op.
Nonetheless, PR(s) for clarification are welcome ;)
Nonetheless, PR(s) for clarification are welcome ;)
AV
19:01
Artem Vorotnikov
ну вот например GET_BOTH
в доках ничего особенного не прописано
но при этом у меня упал тест потому что на выходе в key ничего не записано
в доках ничего особенного не прописано
но при этом у меня упал тест потому что на выходе в key ничего не записано
19:04
как я понял, есть 3 категории операций
1. вписывают только значение
2. вписывают значение и могут вписать ключ
3. гарантированно вписывают и ключ и значение
какой вид у каждой операции - в доках ничего не прописано
1. вписывают только значение
2. вписывают значение и могут вписать ключ
3. гарантированно вписывают и ключ и значение
какой вид у каждой операции - в доках ничего не прописано
19:05
ну или не знаю - "молчание знак согласия"? - если операция не поменяла значение key, то это и есть результат? 😵
Л(
19:11
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Прописано "MDBX_DUPSORT -only: Position at key/data pair", т.е. для
Тут конечно можно поспорить насколько это хорошее описание, но это пришло из LMDB и там с этим "кактусом" живут ~10 лет.
Со своей стороны я стараюсь не "переписывать все" и предлагаю использовать C++ API.
MDBX_GET_BOTH key и data являются входными аргументами.Тут конечно можно поспорить насколько это хорошее описание, но это пришло из LMDB и там с этим "кактусом" живут ~10 лет.
Со своей стороны я стараюсь не "переписывать все" и предлагаю использовать C++ API.
AV
19:12
Artem Vorotnikov
да
key и data будут вписаны после операции? )
key и data будут вписаны после операции? )
19:21
In reply to this message
если я правильно понял логику, то лучше было бы если бы mdbx всегда вписывал ключ (т.е. вместо 2. заменить на 3.) - так я смогу избежать аллокации потому что аргумент - временная переменная, а ключ может быть в чистой странице
Л(
19:45
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Логика там несколько иная = покрыть наиболее частые сценарии использования при минимальном кол-ве действий машины, но простота и единообразие принесены в жертву.
Соответственно, операции можно разделить на категории примерно так:
1. Перемещения относительно текущей позиции, а также LAST и FIRST.
Тут не нужны входящие значения key/data. Поэтому аргументы key/data используются как выходные, если указатели не нулевые.
Логика такого поведения = перемещаем курсор и можем сразу опционально получить ключ и/или значение.
2. Операции поиска, т.е. установки курсора на передаваемые значения key/data.
Эти операции не изменяют значения входящих/input аргументов (в зависимости от операции), если не указано иное.
Логика такого поведения = при поиске нам незачем получать значения, которые были у нас до операции.
3.
Логика такого поведения = для этих операция явно описано получение данных.
Соответственно, операции можно разделить на категории примерно так:
1. Перемещения относительно текущей позиции, а также LAST и FIRST.
Тут не нужны входящие значения key/data. Поэтому аргументы key/data используются как выходные, если указатели не нулевые.
Логика такого поведения = перемещаем курсор и можем сразу опционально получить ключ и/или значение.
2. Операции поиска, т.е. установки курсора на передаваемые значения key/data.
Эти операции не изменяют значения входящих/input аргументов (в зависимости от операции), если не указано иное.
Логика такого поведения = при поиске нам незачем получать значения, которые были у нас до операции.
3.
MDBX_GET_CURRENT и операции из второго пункта для которых прописан возврат результатов в key и/или data.Логика такого поведения = для этих операция явно описано получение данных.
17 March 2021
MM
10:55
Melbourne Channel Moderator
https://github.com/LumoSQL/LumoSQL
anyone can implement this into sqlite or mysql? there's sqlightning
anyone can implement this into sqlite or mysql? there's sqlightning
10:55
p
11:10
puɐɯǝıu
In reply to this message
LOL! Latest version is SQLite3 :) SQLite4 was experimental version back-ported to SQLite3. Read notes - https://sqlite.org/src4/doc/trunk/www/index.wiki
MM
12:59
Melbourne Channel Moderator
ok i didnt know. anyway will be best if someone did the port
12:59
TxId <- anyways to set txn id of a transaction?
13:00
... for the purpose of tracking replication. i'm writing a replication log so i can hv multiple writer on my write buffer
13:00
would like to set txid to the nanosecond timestamp so i know when last txn is committed. and if replicated, will begin with that txnid timestamp
13:02
otherwise... shld i write the txnid and last commit timestamp to a separate db name and a key of "lasttxtime" ? what do u guys think?
Л(
17:47
Леонид Юрьев (Leonid Yuriev)
In reply to this message
some decisions you need to make yourself.
like a relationship with a woman, to know who the father is.
)
like a relationship with a woman, to know who the father is.
)
MM
17:49
Melbourne Channel Moderator
In reply to this message
what do u suggest? since u fathered this software? i'm just the bystander who's looking for expert knowledge :D
17:50
anyways to set the txn id for each transaction?
17:59
oh, feature request, possible to make the txn id to be the nanosecond of time?
AV
18:01
Artem Vorotnikov
In reply to this message
возвращаясь к вопросу
как я понял, mdbx_cursor_set не вписывает key в случае GET_BOTH и GET_BOTH_RANGE - так и должно быть?
как я понял, mdbx_cursor_set не вписывает key в случае GET_BOTH и GET_BOTH_RANGE - так и должно быть?
Л(
18:02
Леонид Юрьев (Leonid Yuriev)
In reply to this message
No, sure.
But can make this in the you own fork.
But can make this in the you own fork.
18:16
In reply to this message
На всякий:
- такое api унаследовано от lmdb и теперь уже точно его не стоит менять;
- при желании сделайте pr с уточнением документации;
- у меня локально не будет электричества, примерно сутки. Т.е я буду в offline.
- такое api унаследовано от lmdb и теперь уже точно его не стоит менять;
- при желании сделайте pr с уточнением документации;
- у меня локально не будет электричества, примерно сутки. Т.е я буду в offline.
AV
18:19
Artem Vorotnikov
In reply to this message
🤷♂️ менять - отдельный вопрос
мне бы для начала разобраться 🙂
PR будет
мне бы для начала разобраться 🙂
PR будет
18:21
(я бы вообще поделил на разные функции и убрал безликий get из API)
Л(
AV
18:28
Artem Vorotnikov
я не могу прикручивать биндинги к h++ :)
18:30
для меня ценность C не в C (в гробу его видал), а в том что это основание для растового биндинга
18 March 2021
MM
01:07
Melbourne Channel Moderator
In reply to this message
where do i change the txn id to nano second time? can u pls guide me to the location of the file? i only need this so can try do replication
AS
04:15
Alex Sharov
Just save any data you need in db usual way.
MM
05:05
Melbourne Channel Moderator
it's cleaner with nanosecond as txn id. i think i'll fork and change the code coz it's more efficient and i dont have to purposely txn.put another value anywhere else.
anyone knows where to change this value?
anyone knows where to change this value?
AS
05:24
Alex Sharov
You know which function opens transaction. Just search it’s name in codebase.
MM
05:25
Melbourne Channel Moderator
ok thx
05:30
i just git clone libmdbx but i cant find
__inline_mdbx_txn_begin <- this function.
__inline_mdbx_txn_begin <- this function.
05:31
grep -rnH 'inline_mdbx_txn_begin' .
./libmdbx/src/core.c:7262: return __inline_mdbx_txn_begin(env, parent, flags, ret);
./libmdbx/src/core.c:7262: return __inline_mdbx_txn_begin(env, parent, flags, ret);
05:31
does anyone know where __inline_mdbx_txn_begin is?
NK
05:40
Noel Kuntze
Remove the __inline_
MM
05:53
Melbourne Channel Moderator
i'm apparently not a c programmer.
quick glance at this libmdbx code makes me realise what the impressiveness they are talking about. it's definitely state of the art.
quick glance at this libmdbx code makes me realise what the impressiveness they are talking about. it's definitely state of the art.
05:54
i wonder how long it took to write lmdb and how many years of experience u need to write lmdb
MM
11:29
Melbourne Channel Moderator
What happens to uncommitted transactions? let's say i cancel the program while running. what happens to those that is txn.Put but never get to be committed while the program is terminated?
MM
12:25
Melbourne Channel Moderator
Unterminated transactions can adversly effect database performance and cause the database to grow until the map is full.
12:25
for unterminated transactions, how do i clear them?
12:26
...manually
AS
12:58
Alex Sharov
It’s about too long read transactions while app works. If app terminated - you don’t need to do anything.
MM
13:05
Melbourne Channel Moderator
oic. i get it. the explanation is not very ... complete
NK
15:44
Noel Kuntze
I've tried implementing the python bindings using the C++-API and so far only had trouble. I'm switching over to python's CFFI (C foreign function interface) and the libmdbx C API.
15:44
The trouble I had exactly is that memory allocation issues have come up immediately after passing objects to other functions, resulting in immediate crashes or bad allocations.
15:45
The C interface doesn't have those issues and there are already pthon bindings for lmdb. Using those bindings as basis should be much faster (because the structure is the same as libmdbx).
NK
20:10
Noel Kuntze
Leonid, do you have any example C++ files using the mdbx C++ API?
Л(
19 March 2021
NK
00:15
Noel Kuntze
:(
MM
14:33
Melbourne Channel Moderator
write txn is really slow. i've set the
env.Open("./ldb", mdbx.SafeNoSync, 0644)
//env.Open("./ldb", 0, 0644)
env.SetOption(mdbx.OptSyncPeriod, 30*65536)
env.SetOption(mdbx.OptSyncBytes, 16*1024*1024)
with or without safenosync, no difference. it's around 5s for 1000 put, the speed of my laptop ssd iops i guess
env.Open("./ldb", mdbx.SafeNoSync, 0644)
//env.Open("./ldb", 0, 0644)
env.SetOption(mdbx.OptSyncPeriod, 30*65536)
env.SetOption(mdbx.OptSyncBytes, 16*1024*1024)
with or without safenosync, no difference. it's around 5s for 1000 put, the speed of my laptop ssd iops i guess
14:33
what am i doing wrong? i'm using golang
AS
14:54
Alex Sharov
nobody can say what's wrong with your benchmark if you don't show it.
15:07
how much writes per second you need to handle?
15:15
I never used SyncPeriod or SyncBytes options. In my small benchmark
SafeNoSync is 250 times slower than Durable (on big amount of small write transactions, on macbook). So, i don't know.
Л(
15:15
Леонид Юрьев (Leonid Yuriev)
In reply to this message
200 TPS is good enough for laptop (i.e. not highend SSD).
15:22
In reply to this message
For high TPS you need battery-backed write-back cache (i.e. RAID controller) and
Another way - you should lose durability in a system/power failure case (but not an application failure).
MDBX_LIFORECLAIM option.Another way - you should lose durability in a system/power failure case (but not an application failure).
MM
16:25
Melbourne Channel Moderator
...200 TPS shld be the iops of the ssd. lsm shld be much faster... i think they append write first then only do processing.
Л(
17:53
Леонид Юрьев (Leonid Yuriev)
In reply to this message
This has been explained and discussed many times:
1.LSM shows good write performance, and is especially ideal for short-lived data.
2. On the other hand, LSM shows (relatively):
- low read performance;
- high probability of huge latency peaks;
- generally does not provide ACID (or it does so at the cost of a significant drop in performance).
3. In addition, storage engines with WAL always show better write performance. But you have to pay for this by having to restore (i.e. log replay) after a system failure.
So, there's no golden ratio and you should choice a DB depending of your use cases, etc, with a close study of the pros and cons of each engine.
For instance, some the pros and cons of MDBX:
- you can get incredible high TPS with battery-backed write-back cache and
- you can get non-blocking reads with linear scaling up to the memory bandwidth;
- no recovery phase since no WAL, but the same time thus (relatively) high WAF and low write performance especially on low-end hardware.
- etc, etc, etc...
1.LSM shows good write performance, and is especially ideal for short-lived data.
2. On the other hand, LSM shows (relatively):
- low read performance;
- high probability of huge latency peaks;
- generally does not provide ACID (or it does so at the cost of a significant drop in performance).
3. In addition, storage engines with WAL always show better write performance. But you have to pay for this by having to restore (i.e. log replay) after a system failure.
So, there's no golden ratio and you should choice a DB depending of your use cases, etc, with a close study of the pros and cons of each engine.
For instance, some the pros and cons of MDBX:
- you can get incredible high TPS with battery-backed write-back cache and
MDBX_LIFORECLAIM.- you can get non-blocking reads with linear scaling up to the memory bandwidth;
- no recovery phase since no WAL, but the same time thus (relatively) high WAF and low write performance especially on low-end hardware.
- etc, etc, etc...
MM
18:20
Melbourne Channel Moderator
In reply to this message
Yes I understand. But I will make the write transaction faster with wal. I tot it will be nice feature to have. Definitely will be fastest read write in the world with a wal
20 March 2021
AS
19:35
Alex Sharov
What is recommended way to backup db? mbdx_dump?
21 March 2021
AS
11:49
Alex Sharov
mdbx_env_set_syncperiod - this option must be used with MDBX_SAFE_NOSYNC only or with MDBX_NOMETASYNC+MDBX_SAFE_NOSYNC?
AV
15:45
Artem Vorotnikov
In reply to this message
у семафоров выше оверхед чем у pthread мутекса? я бы включил их вместо - чтобы можно было закрывать write-транзакцию из другого потока
22 March 2021
Л(
08:13
In reply to this message
Это можно выбрать опциями сборки, см. https://github.com/erthink/libmdbx/blob/master/src/options.h#L130-L154
Сборки библиотеки с разной опцией
Сборки библиотеки с разной опцией
MDBX_LOCKING не смогут работать с одной БД одновременно, а только по-очередно.
AS
15:55
Alex Sharov
In reply to this message
As I can see in source code - it done in single read tx, right? (means need to stop app for backup)
MM
15:57
Melbourne Channel Moderator
mdbx is working fine so far. extremely happy with it. thank you all so much for the help extended. just ran it in production and everything's fine so far. pls just make it more complete and concise if possible ( optimization for being bulletproof database )
as it is, it's very good. thx
as it is, it's very good. thx
AS
16:00
Alex Sharov
I'm shooting with 1Tb bullet
MM
16:02
Melbourne Channel Moderator
what's the 1tb data about? just curious
16:02
1tb is a lot of data
Л(
16:08
Леонид Юрьев (Leonid Yuriev)
In reply to this message
The
However, copying a large database can take a while, i.e. this could be a trouble with long-lived read transaction.
Please read the https://erthink.github.io/libmdbx/intro.html#long-lived-read
mdbx_copy will make a consistently copy of the MVCC snapshot.However, copying a large database can take a while, i.e. this could be a trouble with long-lived read transaction.
Please read the https://erthink.github.io/libmdbx/intro.html#long-lived-read
AS
18:10
Alex Sharov
я почему-то тупил - думал что увеличение размера страницы увеличит базу - но дошло что 50% это 50% 🙂
сегодня гонял мелкий тест - база даже уменьшилась.
сегодня гонял мелкий тест - база даже уменьшилась.
Л(
18:13
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Там очень сложная зависимость от "узора" в размере ключей и данных.
Поэтому кроме тривиальных или сильно простых случаев предсказать результат практически не возможно - нужно пробовать.
Поэтому кроме тривиальных или сильно простых случаев предсказать результат практически не возможно - нужно пробовать.
23 March 2021
MM
03:20
Melbourne Channel Moderator
feature request. this one really hope it can be implemented then truly complete. it's not easy...
db.Batch() <- batch processing like bbolt
https://github.com/etcd-io/bbolt
db.Batch() <- batch processing like bbolt
https://github.com/etcd-io/bbolt
03:20
do you think it's possible to add as a feature?
Л(
03:30
Леонид Юрьев (Leonid Yuriev)
In reply to this message
No, sure.
Just use a nested transactions instead.
Just use a nested transactions instead.
MM
03:35
Melbourne Channel Moderator
nested transactions? i'm using golang so i can just use a goroutine and do go "db.Batch()" offloading write to write in batches. so not sure if it can be done this way
AS
04:02
Alex Sharov
In reply to this message
It’s about consistent partial rollback. Not about speed of inserting data. Also nested transaction must be in same goroutine with main transaction (no parallelism here)
Л(
04:05
Леонид Юрьев (Leonid Yuriev)
In reply to this message
MDBX provides nested transactions, which are not a no-cost (i.e. slightly slower than normal transactions).
You can use them depending on your needs (you may need to modifty the bindings).
There is a simple rule to understand whether you need nested transactions or not: If the logic/workflow of an application requires an explicit aborting of some changes before the general commit, then nested transactions will be useful, but otherwise not.
However, if you need trivial batching, then just make more changes in a each transaction (i.e. commit ones less often).
You can use them depending on your needs (you may need to modifty the bindings).
There is a simple rule to understand whether you need nested transactions or not: If the logic/workflow of an application requires an explicit aborting of some changes before the general commit, then nested transactions will be useful, but otherwise not.
However, if you need trivial batching, then just make more changes in a each transaction (i.e. commit ones less often).
MM
05:00
Melbourne Channel Moderator
anyways to implement trivial batching in mdbx? that'll be fantastic because golang binding can only hv 1 txn at a time and cant do the Batch() function
Л(
AS
05:10
Alex Sharov
In my understanding - this is what MDBX_SAFE_NOSYNC+
About 1 write tx at a time - it’s lmdb/mdbx requirement - not bindings - because it allows simplify code, avoid deadlocks and update conflicts.
mdbx_env_set_syncperiod does. "Doesn't write to disk at tx.Commit, but write to disk periodically".About 1 write tx at a time - it’s lmdb/mdbx requirement - not bindings - because it allows simplify code, avoid deadlocks and update conflicts.
05:11
Also - to gain more write speed from mdbx - you can add WriteMap flag.
05:13
To get more read speed from Go bindings you can set tx.RawRead flag: https://github.com/torquem-ch/mdbx-go/blob/master/mdbx/txn.go#L56
05:18
Also Bolt’s batch - is working on same logic as MDBX_UTTERLY_NO_SYNC - can corrupt. Because Lmdb and Bolt don’t have analog of MDBX_SAFE_NO_SYNC flag(which safer but slower). Their batch/nosync is equal to MDBX_UTTERLY_NO_SYNC flag.
05:21
We in our App using in-memory write buffer (flushing when it full) - for random writes. You can make it thread-safe if you need (if your scenario is as simple as get/put/delete) - by just 1 RWMutex.
Mark invited Mark
M
08:13
Mark
Is there a Paypal address to donate to? So far very impressed with libmdbx.
MM
11:32
Melbourne Channel Moderator
In reply to this message
what is writemap flag? 1tx at a time... actualyl i tested. no much difference at 200 writes / second. not sure how to set for higher writes. a real example posted online will be better. exact settings example please.
MM
15:23
Melbourne Channel Moderator
In reply to this message
if i make this mutex etc. possible to avoid db corruption? i hv no idea how the mechanism for batch works. i thought it's about atomic batch txn writing by flushing txns out.
15:25
i dunno how to simulate a db corruption when it corrupts, does it mean the db will fail to work or is still working just that the db's values are mixed up or... loss? huge loss or minor loss? what does "corrupt" mean?
15:25
or what can "corrupt" mean. anyone experienced db corruption can share thoughts on this?
24 March 2021
Л(
15:02
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Batching is when many simple operations are performed in a single transaction, rather than step-by-step.
However, batching of the transactions itselves is generally not possible, except in the form of using nested transactions.
I do not know how batching works in BoltDB, but I think Alex knows what he is talking about, and then this is the wrong way because you can lose whole the DB in the case of a system crash before the results of such "batching" are completed and written to disk.
However, batching of the transactions itselves is generally not possible, except in the form of using nested transactions.
I do not know how batching works in BoltDB, but I think Alex knows what he is talking about, and then this is the wrong way because you can lose whole the DB in the case of a system crash before the results of such "batching" are completed and written to disk.
15:10
In reply to this message
There are different types of corruption but in this context we are talking about as a result of a system accident (poweroff, etc.), only a part of the modified b-tree structure has time to write to the disk.
Thus, links inside the b-tree can point to a garbage but instead of the desired data.
In the worst case, this can happen with the b-tree root page and then there is very little chance of recovering anything from such a DB.
Thus, links inside the b-tree can point to a garbage but instead of the desired data.
In the worst case, this can happen with the b-tree root page and then there is very little chance of recovering anything from such a DB.
MM
15:14
Melbourne Channel Moderator
In reply to this message
that's a complete nono unacceptable situation! ok. then... dont do anything more if corruption is unavoidable (with whatever speed magic)
however, i do hope there's a 1s delay with a queued transaction "batching" so we can at least hv some sort of guaranteed async built into it.
also since this is the case, i hv no idea why txn id is not a nanosecond value since we can also track / rollback the last successful txn commit.
however, i do hope there's a 1s delay with a queued transaction "batching" so we can at least hv some sort of guaranteed async built into it.
also since this is the case, i hv no idea why txn id is not a nanosecond value since we can also track / rollback the last successful txn commit.
15:14
maybe no need nanosecond. just micro or just second
Л(
15:17
Леонид Юрьев (Leonid Yuriev)
In reply to this message
You ask why it works "(not) like this" without knowing how it works exactly.
Please don't do this.
Please don't do this.
MM
15:19
i understand what u mean by the corruption. but since the txn commit is ok, what i am suggesting is just another temporary way to do async just to hv a lot more performance from writing that's all... maybe to be used like a dirty cache
Л(
15:20
Леонид Юрьев (Leonid Yuriev)
In reply to this message
OK, please learn how LMDB and (then) MDBX works.
MM
15:20
Melbourne Channel Moderator
for example, if u are doing mithrildb, i'm sure u'll write the wal / repl log (sooner or later), which will be using some sort of timing to recover from last crash txn
15:21
ok i think i understand what u mean. it'll be quite complicated to add more into this. i think it's good enough as it is.
Л(
16:10
Леонид Юрьев (Leonid Yuriev)
In reply to this message
In fact, MDBX (but not LMDB) allows you to do all this if necessary.
However, it's easy to get misunderstood here. Briefly:
1) In LMDB/MDBX, there is always an one writer, i.e. a write transactions are strictly ordered/serialized.
There are a lot of reasons for this, but also a lot of important consequences.
2) Since the writing transactions are strictly sequential, there is no good reason to commit them asynchronously with saving ACID properties (a changes should not be visible for any reader AND FOR a consecutive writer until commit completes).
I.e. the next writing transaction should not be started until the previous one is committed.
So there is no reason to bother with fully asynchronous commit changes to disk.
3) Nonetheless in some cases, for the sake of performance and at your own risk, you may wanna to run the next writing transaction before the previous one completes.
This will not be an error if such an operation does not return any results before committing its transaction (since the dirty reading of uncommitted data will not be visible outside).
Such use case is possible with MDBX (but not with LMDB), with a LOT of simplification:
- start write transaction with MDBX_NOSYNC;
- immediately after commit schedule mdbx_env_sync() in a other thread;
- do not show transaction-related results until mdbx_env_sync() completes.
In general, this is possible since MDBX have three meta-pages (instead of two as in LMDB), and thus a next one NOSYNC-commit could NOT break DB after a previous sync/steady-commit.
On the other hand, this is quite complicated, and I preferred not to bring it to the full readiness (including the description) until necessary.
However, it's easy to get misunderstood here. Briefly:
1) In LMDB/MDBX, there is always an one writer, i.e. a write transactions are strictly ordered/serialized.
There are a lot of reasons for this, but also a lot of important consequences.
2) Since the writing transactions are strictly sequential, there is no good reason to commit them asynchronously with saving ACID properties (a changes should not be visible for any reader AND FOR a consecutive writer until commit completes).
I.e. the next writing transaction should not be started until the previous one is committed.
So there is no reason to bother with fully asynchronous commit changes to disk.
3) Nonetheless in some cases, for the sake of performance and at your own risk, you may wanna to run the next writing transaction before the previous one completes.
This will not be an error if such an operation does not return any results before committing its transaction (since the dirty reading of uncommitted data will not be visible outside).
Such use case is possible with MDBX (but not with LMDB), with a LOT of simplification:
- start write transaction with MDBX_NOSYNC;
- immediately after commit schedule mdbx_env_sync() in a other thread;
- do not show transaction-related results until mdbx_env_sync() completes.
In general, this is possible since MDBX have three meta-pages (instead of two as in LMDB), and thus a next one NOSYNC-commit could NOT break DB after a previous sync/steady-commit.
On the other hand, this is quite complicated, and I preferred not to bring it to the full readiness (including the description) until necessary.
MM
19:28
Melbourne Channel Moderator
Well, if u can solve both read and write speed... that'll be something. Without corruption that is.
27 March 2021
Л(
00:03
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Thank you, but currently no.
But will be available (hope) soon.
But will be available (hope) soon.
Л(
02:45
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Done.
Checkout the sponsor button at the https://github.com/erthink/libmdbx
Checkout the sponsor button at the https://github.com/erthink/libmdbx
M
02:46
Mark
Awesome. Will do after shabbat dinner. Thanks
MM
05:09
Melbourne Channel Moderator
if err = env.SetGeometry(-1, -1, int(1024000000000), int(10240), -1, 64*1024); err != nil {
1. can i ask what will be the problem if db size is greater than ram? but file size is lower than ram
2. long running read transactions will be slow / halt?
3. why do we need to set the geometry for the 3rd value, why cant it be the max size 128TB of the db? what will happen if so?
1. can i ask what will be the problem if db size is greater than ram? but file size is lower than ram
2. long running read transactions will be slow / halt?
3. why do we need to set the geometry for the 3rd value, why cant it be the max size 128TB of the db? what will happen if so?
05:10
my app is using a lot of ram but i'm not sure if will use 100%. i think it's taking up 30% more ram than normal if not using mdbx
05:11
In reply to this message
i know some of these are explained but set geometry is different from lmdb so would really hope can clear my doubts on the ram usage
AS
05:21
Alex Sharov
In reply to this message
1. No problem, but no magic. OS will manage PageCache - load/evict data to/from RAM. Readahead feature works only when db<ram. 2. Db stores all versions of data up to oldest read transaction (it require DB to grow). 3. What is name of “3rd value”? It can. Different projects have different requirements. For example max size is way smaller in 32bits OS. Software which doesn’t have any limits it’s generally bad practice - can’t expect that everything is fine if normally your db is 1gb and suddenly became 100Tb. It’s your friend - OOM killer :-)
05:22
In reply to this message
If you set max db size in LMDB - then on Windows it will immediately create file of this size on disk. Only on Linux it grows slowly.
05:26
You can use underscore digits notation in go: 1024_000_000. Or can use existing constant from mdbx code.
MM
06:32
Melbourne Channel Moderator
if err = env.SetGeometry(-1, -1, int(1024000000000), int(10240), -1, 64*1024); err != nil {
int(1024000000000) <- this is the 3rd value
int(1024000000000) <- this is the 3rd value
06:33
i only use 64bit linux server. so any others will not take into consideration
06:36
In reply to this message
normally db is 1gb and suddenly 100tb.... that's not bad also right? it means u need to keep a lot of data. ok, maybe it's better to ask this way:
for a key of 32 bytes, value of 4mb, system of 8GB ram, disk is 192tb (as a scenario), mostly as key value store, and a bit of range search.
can the db be 128TB? it's only 8GB ram. it's running like an custom made s3 connector file server. to store and retrieve data from mdbx.
for a key of 32 bytes, value of 4mb, system of 8GB ram, disk is 192tb (as a scenario), mostly as key value store, and a bit of range search.
can the db be 128TB? it's only 8GB ram. it's running like an custom made s3 connector file server. to store and retrieve data from mdbx.
06:37
for key of 32 bytes, value of 8mb, system ram 8GB and disk 192tb, what is the recommended size of the db? 128tb possible? if making a CDN, will there be any concern / limitations need to look out for?
MM
07:03
Melbourne Channel Moderator
i'm test running as a http s3-file connector. though the memory is taking up 30% more space than without. i'm running inside 4GB ram with if err = env.SetGeometry(-1, -1, int(1024000000000), int(10240), -1, 64*1024); err != nil {
not sure if the ram will ever touch 100%. app alone is using 50% (2gb), mdbx is using 30%. total 80% but i'm not very sure if it will ever be 100% triggering oom killer. possible to limit how much ram the db will use?
not sure if the ram will ever touch 100%. app alone is using 50% (2gb), mdbx is using 30%. total 80% but i'm not very sure if it will ever be 100% triggering oom killer. possible to limit how much ram the db will use?
MM
07:20
Melbourne Channel Moderator
since using as KV store, i was wondering if it's better to split the db into 2GB each or as one. i think as 64 000 x 2GB (128tb total) each will be more mem efficient instead of 1x 128tb db file. right?
AS
07:34
In reply to this message
I told you already that PageCache belings to OS, not to your app. OOM can’t come to OS.
07:36
In reply to this message
Mdbx has no control over PageCache. To limit - use OS settings (like run in docker or something else).
07:44
There is some research about sharding mmap files: https://arxiv.org/pdf/2005.13762.pdf but i think it’s not very well explored area. And much depends on hardware and app.
MM
08:01
Melbourne Channel Moderator
In reply to this message
yes i know but the golang-binding seems to be taking the memory usage into the app. i'm not sure if it's my app's memory or the page cache memory included. i have bbolt db... as it's still test running i need a longer time and larger db size to see actual results.
since u explained so, then pagecache usage will not be reflected inside golang app i presume. i will wait a few days more for the actual production results to show. i've only ran it for less than 24 hours.
since u explained so, then pagecache usage will not be reflected inside golang app i presume. i will wait a few days more for the actual production results to show. i've only ran it for less than 24 hours.
08:05
what i am saying is, is it better to have 1 128tb db than 64000 2gb? opening and closing the db as i move along. because 1x 128tb ... oom situation seemed very probable.
08:05
... with 4gb ram
AS
08:18
Alex Sharov
1. separate “memory owned by app” from “virtual memory owned by OS - PageCache” (google how)
2. https://golang.org/doc/diagnostics#profiling - see heap profiling of your app - maybe you have memory leak
3. set tx.RawRead=true
4. DB sharding - no proof that it will work better. Because it will share same OS PageCache. If your hot data > RAM, then it will > RAM and after sharding.
5. I don't understand you problem with geometry - it's just settings - if you don't like current value of them, just change them 🙂
6. DB file size isn't really important - what is important - is "hot part" of your db > RAM or < RAM. if < RAM - you will face PageCache-miss - OS will evict something less hot from RAM and load from disk data you requesed. Everything simple: if OS has enough RAM - it will store everything in RAM, if not - it will store in RAM most important things and go to disk for everything else.
7. Read docs of WRITE_MAP option of mdbx - if you have high-load app.
2. https://golang.org/doc/diagnostics#profiling - see heap profiling of your app - maybe you have memory leak
3. set tx.RawRead=true
4. DB sharding - no proof that it will work better. Because it will share same OS PageCache. If your hot data > RAM, then it will > RAM and after sharding.
5. I don't understand you problem with geometry - it's just settings - if you don't like current value of them, just change them 🙂
6. DB file size isn't really important - what is important - is "hot part" of your db > RAM or < RAM. if < RAM - you will face PageCache-miss - OS will evict something less hot from RAM and load from disk data you requesed. Everything simple: if OS has enough RAM - it will store everything in RAM, if not - it will store in RAM most important things and go to disk for everything else.
7. Read docs of WRITE_MAP option of mdbx - if you have high-load app.
MM
09:47
Melbourne Channel Moderator
In reply to this message
txn.RawRead = true
1. any possible ways to set all txn as rawread = true by default?
2. thx. extremely helpful and very informative.
5. setting the geometry is fixed right? u cant change it after set up.
7. i will forgo all trading safety for speed thing. safety is priority. speed is secondary if i cant hv both.
1. any possible ways to set all txn as rawread = true by default?
2. thx. extremely helpful and very informative.
5. setting the geometry is fixed right? u cant change it after set up.
7. i will forgo all trading safety for speed thing. safety is priority. speed is secondary if i cant hv both.
AS
09:52
Alex Sharov
1. nope.
5. only pagesize can't change later.
5. only pagesize can't change later.
MM
10:27
Melbourne Channel Moderator
currently it's 1 file per db + 1 lock file
any settings to make it use multiple files? just curious as so many GB in 1 file is not "easy to maintain". or is there a way for it to use multiple file limited by size? e.g. 1 file max 2GB size. like lsm.
any settings to make it use multiple files? just curious as so many GB in 1 file is not "easy to maintain". or is there a way for it to use multiple file limited by size? e.g. 1 file max 2GB size. like lsm.
AS
10:45
Alex Sharov
No such setting - need implement sharding on APP side. And of course no cross-shard transactions.
MM
10:48
Melbourne Channel Moderator
ok thx. appreciate everything and all help extended.
10:48
looking forward to the next go binding upgrade!
AA
11:17
Alexey Akhunov
I also wanted to say: great love and respect for @erthink for what he does and how he does it 🙂
I
11:34
Igor Mandrigin @ Gateway.fm
100%
MM
13:20
Melbourne Channel Moderator
110%
13:21
and of course to the langunage binding porters. well done. thx
Л(
15:40
Леонид Юрьев (Leonid Yuriev)
Thanks for support
Л(
16:02
Леонид Юрьев (Leonid Yuriev)
Some good news:
- seems I succeeded to fence a couple more behavior "features" inherited from the LMDB's code.
- the result is a 50% increase in the maximum key size and pages have auto-fills tightly during an insertion sequences of ordered keys (both for asc/desc).
After testing, this code will be available in the devel branch at the next week.
- seems I succeeded to fence a couple more behavior "features" inherited from the LMDB's code.
- the result is a 50% increase in the maximum key size and pages have auto-fills tightly during an insertion sequences of ordered keys (both for asc/desc).
After testing, this code will be available in the devel branch at the next week.
MM
16:09
Melbourne Channel Moderator
sounds... terrific. though i hv no idea what it means.
f
Л(
f
16:20
fuunyK
Yepiii 🚀
MM
18:51
Melbourne Channel Moderator
sry, what's TG? telegram?
I
MM
18:56
Melbourne Channel Moderator
what's the performance benchmark of TG vs eth? also, how do i use it? like go-ethereum? exactly?
I
19:02
Igor Mandrigin @ Gateway.fm
In reply to this message
archive node 1.1TB vs 4.6TB in geth. Full sync from genesis in less than 3 days on my machine comparing to 30+ days of go-Ethereum in archive mode.
AA
19:02
Alexey Akhunov
vs 6.5Tb in geth 🙂
I
19:04
Igor Mandrigin @ Gateway.fm
Oops, underestimated a bit. Wasn’t it less than 5TB a couple of months ago?
MM
20:08
Melbourne Channel Moderator
wow... so many eth people here. great. i'm into eth too.
AA
20:34
Alexey Akhunov
In reply to this message
It crossed 5Tb mark in August 2020: https://etherscan.io/chartsync/chainarchive
20:34
currently 6.7 Tb, my 8Tb SSD will soon overfill, but I hope I won't need it anymore by then 🙂
I
23:27
Igor Mandrigin @ Gateway.fm
In reply to this message
👏 yeah, we are in process of moving our node to use mdbx
28 March 2021
MM
05:28
Melbourne Channel Moderator
wow... so much trust in this.
the original eth developer here?
the original eth developer here?
AA
09:48
Alexey Akhunov
it is not trust, we have been testing MDBX vs LMDB for months and months 🙂
MM
10:09
Melbourne Channel Moderator
so... is it production ready?
I
10:36
Igor Mandrigin @ Gateway.fm
We are working to identify and iron out the areas where it is not yet there. But I think we are quite optimistic.
10:38
lmdb is not perfect either, otherwise we would just stick to it. ;-)
AA
11:22
Alexey Akhunov
In reply to this message
There is no "catch all" definition of "production ready". It depends on your intended use. For our use (as a backend of turbo-geth and silkworm), it is almost ready for beta version, just need to level out performance
MM
29 March 2021
MM
11:42
Melbourne Channel Moderator
i think i discovered a "bug" to improve.
if memory not sufficient, it will mention could not allocate memory when env open
mdbx_env_open: cannot allocate memory
so... should this be a concern or how to remedy? opening multiple mdbx db
if memory not sufficient, it will mention could not allocate memory when env open
mdbx_env_open: cannot allocate memory
so... should this be a concern or how to remedy? opening multiple mdbx db
MM
14:45
Melbourne Channel Moderator
mdbx_env_open: cannot allocate memory
i tried opening 20,000 DBs with and i still have ram left but i'm getting this error. on a laptop with 8GB ram and 4GB free when i used to test opening multiple mdbx dbs at the same time. can anyone try? i hv 127mb ram left, not sure what's the issue. it runs even when mem is lower than 500mb but not lower.
this is my set geometry
SetGeometry(-1, -1, int(2048000000), int(10240), -1, 64*1024)
i tried opening 20,000 DBs with and i still have ram left but i'm getting this error. on a laptop with 8GB ram and 4GB free when i used to test opening multiple mdbx dbs at the same time. can anyone try? i hv 127mb ram left, not sure what's the issue. it runs even when mem is lower than 500mb but not lower.
this is my set geometry
SetGeometry(-1, -1, int(2048000000), int(10240), -1, 64*1024)
Л(
14:57
Леонид Юрьев (Leonid Yuriev)
In reply to this message
I don't quite understand what you are trying to do/test and why you expect to get a result different from the observed one?
MM
15:54
Melbourne Channel Moderator
i'm trying to open 20000 db for testing memory usage etc. with 127mb left, why cant i open more db without showing mdbx_env_open: cannot allocate memory?
Л(
16:24
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Because one of the mmap-syscalls returned an ENOMEM error (you can examine this by
Please dig more to the reason by yourself.
strace tool).Please dig more to the reason by yourself.
MM
16:39
Melbourne Channel Moderator
Ok thx
30 March 2021
MM
05:35
Melbourne Channel Moderator
option to change the db name?
05:35
... will be a great feature.
AS
07:20
Alex Sharov
What is profit of renaming file over renaming folder?
MM
09:33
Melbourne Channel Moderator
u dont hv to declare so many folders.
09:33
folder is to store db files
AV
13:35
Artem Vorotnikov
такой вопрос:
можно ли работать с разными курсорами одной write-транзакции параллельно из нескольких потоков? MDBX использует SysV-семафоры
можно ли работать с разными курсорами одной write-транзакции параллельно из нескольких потоков? MDBX использует SysV-семафоры
13:37
(курсоры в своих потоках, никуда не двигаются, обращения только из своих потоков - но write-транзакция общая)
Л(
14:28
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Для курсоров связанных с одним DBI-хендлом реализуется трекинг:
- для курсоров формируется связанный список;
- при изменении данных, это изменение проецируется на состояние и позицию остальных курсоров;
- например, при вставке записи в самое начало, остальные курсоры стоящие на той-же странице БД должны быть сдвинуты вперед.
Кроме этого, операции модификации данных связаны с аллокацией/освобождением страниц, перемещением их между внутренними списками и т.д.
Соответственно, работая с одной write-транзакцией из разных потоков, вы должны:
- гарантировать отсутствие наложений операций модифицирующих данные с какими-либо другими операциями;
- гарантировать отсутствие наложения операций открытия/закрытия курсоров по одинаковым DBI-хендлам;
- гарантировать отсутствие операций открытия/закрытия DBI-хендлов.
Поэтому параллельно можно только читать данные и перемещать курсоры, но не изменять что-либо и не создавать/разрушать какие-либо объекты связанные с БД.
Причем я не могу гарантировать что эта возможность сохранится в будущем, или не добавятся какие-либо ограничения.
- для курсоров формируется связанный список;
- при изменении данных, это изменение проецируется на состояние и позицию остальных курсоров;
- например, при вставке записи в самое начало, остальные курсоры стоящие на той-же странице БД должны быть сдвинуты вперед.
Кроме этого, операции модификации данных связаны с аллокацией/освобождением страниц, перемещением их между внутренними списками и т.д.
Соответственно, работая с одной write-транзакцией из разных потоков, вы должны:
- гарантировать отсутствие наложений операций модифицирующих данные с какими-либо другими операциями;
- гарантировать отсутствие наложения операций открытия/закрытия курсоров по одинаковым DBI-хендлам;
- гарантировать отсутствие операций открытия/закрытия DBI-хендлов.
Поэтому параллельно можно только читать данные и перемещать курсоры, но не изменять что-либо и не создавать/разрушать какие-либо объекты связанные с БД.
Причем я не могу гарантировать что эта возможность сохранится в будущем, или не добавятся какие-либо ограничения.
31 March 2021
MM
05:06
Melbourne Channel Moderator
will libmdbx be used as tarantool backend?
05:06
... anyone porting it as storage engine for mysql?
1 April 2021
MM
18:58
Melbourne Channel Moderator
for MDB_DUPFIXED if i put z,a,y will the order be the same if i didnt put dupsorted.
AS
19:02
Alex Sharov
DUPSORT - stands for Sorted Duplicates
19:04
Dupfixed flag can be used only with Dupsort flag
19:05
So, everything sorted
MM
19:05
Melbourne Channel Moderator
In reply to this message
ok thx. sorry wasnt thinking much.
and this is the answer i was looking for... need to put inside the docs.
and this is the answer i was looking for... need to put inside the docs.
19:19
should i store meta data of value in a separate db or shld i store it together as key?
scenario 1)
for a key, k as key32bytesfixed, v as somevalue, meta info is fixed 8bytes
1 DB only, stored as
k == key32bytesfixed+[8bytesfixed meta information]
v == somevalue
scenario 2), with 2 DBs
db1 : k == key32bytesfixed, v == somevalue
db2 : k == key32fbytesfixed, v == 8bytesfixed meta information
i'm thinking about getting k. scenario 1 can only be found with Cursor / iterator command? will it be as fast as scenario 2 for millions of keys?
obviously scenario 2 will be faster but takes more storage requirement.
which is more advisable?
scenario 1)
for a key, k as key32bytesfixed, v as somevalue, meta info is fixed 8bytes
1 DB only, stored as
k == key32bytesfixed+[8bytesfixed meta information]
v == somevalue
scenario 2), with 2 DBs
db1 : k == key32bytesfixed, v == somevalue
db2 : k == key32fbytesfixed, v == 8bytesfixed meta information
i'm thinking about getting k. scenario 1 can only be found with Cursor / iterator command? will it be as fast as scenario 2 for millions of keys?
obviously scenario 2 will be faster but takes more storage requirement.
which is more advisable?
AS
19:33
Alex Sharov
Too abstract. Not clear why in scenario 1 you need search something by cursor. If you need search by key and by metadata - you can store it as Dupsort: key -> metadata+value
MM
19:43
Melbourne Channel Moderator
ok. thx
MM
20:59
Melbourne Channel Moderator
dupsort... i want the lowest value as first item. how is the lowest value defined?
[]byte("0"),[]byte("0a"),[]byte("0aa")
1. aa1, Aa1, aa10, aa100
2. ab, aa1, ab1
3. abc, ad, adc
4. ad, abc, adc
[]byte("0"),[]byte("0a"),[]byte("0aa")
1. aa1, Aa1, aa10, aa100
2. ab, aa1, ab1
3. abc, ad, adc
4. ad, abc, adc
21:07
how do you pop the first value? and left insert value to be used as a list feature?
2 April 2021
AS
04:43
Alex Sharov
Default order: https://github.com/erthink/libmdbx/blob/master/src/core.c#L12404
Anti-order: https://github.com/erthink/libmdbx/blob/master/mdbx.h#L1338
Please read docs of available cursor methods (there is all you need to implement list/queue/deque): https://github.com/erthink/libmdbx/blob/master/mdbx.h#L1460
Anti-order: https://github.com/erthink/libmdbx/blob/master/mdbx.h#L1338
Please read docs of available cursor methods (there is all you need to implement list/queue/deque): https://github.com/erthink/libmdbx/blob/master/mdbx.h#L1460
M
06:23
Mark
Is therr an optimal way to delete all values in a database besides the obvious of doing so with a cursor?
AS
06:34
Second line in: https://erthink.github.io/libmdbx/usage.html#autotoc_md46
M
06:35
Mark
But that closes it.
06:35
Carry out order there may be other threads using that database handle.
AS
M
06:35
Mark
During startup I have a single thread make a transaction and get all the database handles. I then spawn multiple threads to use it.
06:36
Is that a bad use scenario?
AS
06:37
Alex Sharov
"you can't move write transaction between threads" https://erthink.github.io/libmdbx/usage.html#autotoc_md41
"you can't move write transaction between threads" https://erthink.github.io/libmdbx/usage.html#autotoc_md41
"you can't move write transaction between threads" https://erthink.github.io/libmdbx/usage.html#autotoc_md41
"you can't move write transaction between threads" https://erthink.github.io/libmdbx/usage.html#autotoc_md41
🙂
"you can't move write transaction between threads" https://erthink.github.io/libmdbx/usage.html#autotoc_md41
"you can't move write transaction between threads" https://erthink.github.io/libmdbx/usage.html#autotoc_md41
"you can't move write transaction between threads" https://erthink.github.io/libmdbx/usage.html#autotoc_md41
🙂
M
06:38
Mark
Oh I'm not doing that. Each thread uses its own transaction.
06:38
But there are multiple threads potentially doing transactions against the same database
06:38
So when I start up I grab the database handle and put it into a global variable
AS
06:38
Alex Sharov
ah, sorry 🙂
M
06:39
Mark
Each thread will then occasionally when certain events in my system happen perform a transaction against the database. Using the global handle that I obtained during startup
AS
06:39
Alex Sharov
yes, for DBI handles - no problem. handles are just usual digits.
M
06:39
Mark
My concern with using mdbx_drop is that it will close the handles when another thread may potentially want to do a query
06:39
I'm dropping the databases in a mode that does a factory reset. The other threads will still be running handling hardware events.
06:40
So I basically want to transaction that just empties out records in certain databases with the normal acid properties.
06:40
So you are saying I can ignore the fact that it closes the database?
AS
M
06:41
Mark
Gotchya
06:41
I understand what it's doing now. So I basically was confusing delete and empty.
06:41
Thanks Alex!
06:41
I'll have to send a little more coin your way
06:42
Although it seems like that doesn't take a transaction handle
06:42
Oh wait never mind
06:43
It's late here...
MM
07:51
Melbourne Channel Moderator
curious, if i call cursor.Get() and i only want the Key only, (closest match) if my value is 1GB (which i want to ignore), will the db get the 1gb value also and then ignore the value? coz it's using go binding.
i just want to return Key without going through / touching value
k, _, err := cur.Get(nil, nil, Next) <- i think it will get Value too right? and then ignore it. is there a way to get key only without the additional value processing (getting) overhead?
i just want to return Key without going through / touching value
k, _, err := cur.Get(nil, nil, Next) <- i think it will get Value too right? and then ignore it. is there a way to get key only without the additional value processing (getting) overhead?
MM
08:10
Melbourne Channel Moderator
cursor.Get() is faster or just Get() or same speed?
asking because would like to change my key to store changing metadata, incremental counter of hits/visits.
e.g. key[8byte counter] <- each time key is access/requested. +1 to [8byte counter]. to get this value. i can either do:
1st scenario) separate
db 1: key = 8byte counter ,
db 2: key = value
2nd scenario) or i can use 1 db and do
key[8byte counter] = value
1st scenario require using Get(key)
2nd scenario require cursor.Get(key ... SetRange)
so which is faster?
asking because would like to change my key to store changing metadata, incremental counter of hits/visits.
e.g. key[8byte counter] <- each time key is access/requested. +1 to [8byte counter]. to get this value. i can either do:
1st scenario) separate
db 1: key = 8byte counter ,
db 2: key = value
2nd scenario) or i can use 1 db and do
key[8byte counter] = value
1st scenario require using Get(key)
2nd scenario require cursor.Get(key ... SetRange)
so which is faster?
08:13
3rd scenario)
key = [8byte counter]+value
this is not in consideration because value can be 1gb in length
key = [8byte counter]+value
this is not in consideration because value can be 1gb in length
08:26
In reply to this message
and most importantly this is because value will be updated frequently coz of the incrementing counter. which is impractical / not too safe to mess around with getting the value and inputting it. maybe it can be done but my programming skill is not that advance.
AS
08:29
Alex Sharov
It for sure make sense to separate "frequently changing data" from "unfrequently changing data" from "never changing data".
MM
08:30
Melbourne Channel Moderator
given the above scenario. which is best then? 1 or 2?
08:30
1? more space.
2. more processing (that's why i asked about the cursor.get to check whether there's additional overhead for the cursor)
2. more processing (that's why i asked about the cursor.get to check whether there's additional overhead for the cursor)
AS
08:37
Alex Sharov
- txn.Get using cursor.Get under the hood
- I already saw here joke about making decisions: https://t.me/libmdbx/1461
- For me: make sense to separate "frequently changing data" from "unfrequently changing data" from "never changing data" - even if it requre a bit more processing, because PageCache will work better. But only you know - requirementes for your app - frequency of updates, frequency of reads, amount of ram, amount of hot data, etc...
- I already saw here joke about making decisions: https://t.me/libmdbx/1461
- For me: make sense to separate "frequently changing data" from "unfrequently changing data" from "never changing data" - even if it requre a bit more processing, because PageCache will work better. But only you know - requirementes for your app - frequency of updates, frequency of reads, amount of ram, amount of hot data, etc...
MM
08:40
Melbourne Channel Moderator
In reply to this message
txn.Get using cursor.Get... btree is really "fast".
MM
13:16
Melbourne Channel Moderator
what is the default growth step?
growth_step <- extremely difficult to find online
growth_step <- extremely difficult to find online
13:17
... and how does one recommend a default growth_step?
13:17
segments of 256mb is it ok?
AS
14:43
Alex Sharov
MM
15:16
Melbourne Channel Moderator
https://github.com/erthink/libmdbx/wiki <- enable this so everyone can contribute the documentation and tutorial written here
f
17:45
fuunyK
@erthink could you add an etherum address on the section “sponsor this project” on github please. I hate paypal.
AV
3 April 2021
MM
09:40
Melbourne Channel Moderator
i know i can read from multiple programs for libmdbx db.
can i write to libmdbx from multiple different programs? is it "safe"?
can i write to libmdbx from multiple different programs? is it "safe"?
Л(
20:19
Леонид Юрьев (Leonid Yuriev)
Hi guys!
It took me a few days to deal with personal matters.
I'll be back to work on Monday.
If there are still unanswered questions, then it is better to repeat them tomorrow evening (but not now).
It took me a few days to deal with personal matters.
I'll be back to work on Monday.
If there are still unanswered questions, then it is better to repeat them tomorrow evening (but not now).
4 April 2021
MM
19:31
Melbourne Channel Moderator
curious SetMaxDBs(32000) <- what's the advantage of setting low values vs the limit? 32NNN?
5 April 2021
Л(
13:51
Леонид Юрьев (Leonid Yuriev)
Hi ALL!
I was sick and almost recovered, but I can't devote much time to maintaining libmdbx yet.
Please wait a couple more days.
I was sick and almost recovered, but I can't devote much time to maintaining libmdbx yet.
Please wait a couple more days.
MM
13:51
Melbourne Channel Moderator
no problem. get well soon.
Л(
13:54
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Basically, to using less memory and to less overhead copying internal structures during a transaction(s).
MM
14:04
Melbourne Channel Moderator
In reply to this message
so means i can also have multiple programs writing to the file right? 1 write transaction with a lock on the file... but multiple programs. i see. ok
Л(
14:09
Леонид Юрьев (Leonid Yuriev)
In reply to this message
General rules:
- the single writer rule = no more than one write transaction simultaneously;
- the non-blocking readers rule = there can be a lot of read transactions and they are not blocked (not counting reader(s)/thread(s) registration);
- the single writer rule = no more than one write transaction simultaneously;
- the non-blocking readers rule = there can be a lot of read transactions and they are not blocked (not counting reader(s)/thread(s) registration);
6 April 2021
Л(
7 April 2021
Misha Nikanorov invited Misha Nikanorov
11 April 2021
AS
10:18
Alex Sharov
Here is one point about “moving overflow pages to another drive” - it was not implemented, right? https://youtu.be/HwatuAVGe1M
f
Л(
12:48
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Yes, not implemented.
This feature requires a change the DB format (which is frozen for MDBX) and a big rework the engine internals.
So, this feature is for MithrilDB: a large/overflow nodes will be include a zone-id and npages.Thus:
- a set of different (i.e. fast/slow) disks/medias could be used for an one DB;
- such nodes/pages could be allocated and released/retired without reading ones from a media (which is required for MDBX/LMDB).
This feature requires a change the DB format (which is frozen for MDBX) and a big rework the engine internals.
So, this feature is for MithrilDB: a large/overflow nodes will be include a zone-id and npages.Thus:
- a set of different (i.e. fast/slow) disks/medias could be used for an one DB;
- such nodes/pages could be allocated and released/retired without reading ones from a media (which is required for MDBX/LMDB).
MM
13:02
Melbourne Channel Moderator
In reply to this message
where is this place physically? so few people actually notice this youtube
13:02
the auto google translation in english is... excruciatingly painful to read
Л(
13:08
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Basically you don't need this.
Information about LMDB (including internals) and (then) MDBX's readme should be enough.
Information about LMDB (including internals) and (then) MDBX's readme should be enough.
MM
13:24
Melbourne Channel Moderator
the youtube translate says even lmdb author doesnt know how lmdb internal works. is that true?
13:24
... and mdbx authors do not 100% understand how it all works too. but as long as it works like a black box...
13:25
to be honest. i dont even know how a lot of things i've wrote work 100% too. i just know it works. :D
Л(
14:03
Леонид Юрьев (Leonid Yuriev)
There's kind of a joke(s) about Howard's "the rebus" code style - i.e. nobody knows the code after a 5 min since it was written ;)
On the other hand, LMDB has some obvious bugs.
On the other hand, LMDB has some obvious bugs.
MM
14:34
Melbourne Channel Moderator
curious, instead of mithrildb, why dont port as storage engine for mariadb? of course the commercial value is there i understand. but if port as mariadb storage engine is possible, that'll really change the world.
MM
18:27
Melbourne Channel Moderator
how long will it take to finish writing an write ahead log and replication log? does anyone know? how many programmers in how many days
12 April 2021
MM
00:00
Melbourne Channel Moderator
mdbx_env_open: resource temporarily unavailable <- how do i resolve this? i tried to do open envs open twice
i want to open for readonly for one of the programs. i realised i cant open multiple same mdbx db at the same time
i want to open for readonly for one of the programs. i realised i cant open multiple same mdbx db at the same time
Л(
00:08
Леонид Юрьев (Leonid Yuriev)
In reply to this message
You're doing something wrong:
- do not open the same ENV(s) twice from the one process.
- be careful with fork(), i.e. not to open ENV before, or in a pinch close it immediately after.
- with MDBX_EXCLUSIVE a ENV could be open only by single process.
- do not open the same ENV(s) twice from the one process.
- be careful with fork(), i.e. not to open ENV before, or in a pinch close it immediately after.
- with MDBX_EXCLUSIVE a ENV could be open only by single process.
MM
00:10
Melbourne Channel Moderator
ok i think i know the problem. thx
13 April 2021
NK
03:32
Noel Kuntze
Is there a way to iterate over all keys and values in a database?
AS
03:51
Alex Sharov
if you open root DBI - and iterate over it - then you will get all DBI names. So you need 2 loops: 1 by DBI's, 2-nd by keys/values in each DBI.
NK
03:54
Noel Kuntze
How do I know which DB names there are? I haven't found any functions for that
03:54
And also haven't found a function for getting all keys
03:55
Right now I only know how to get a DB or key whos name I know.
AS
04:32
Alex Sharov
In reply to this message
something like:
root, err := tx.OpenDBI(0)
if err != nil {
return nil, err
}
c, err := tx.OpenCursor(root)
if err != nil {
return nil, err
}
for k, _, _ := c.Get(nil, nil, mdbx.First); k != nil; k, _, _ = c.Get(nil, nil, mdbx.Next) {
tableNames = append(tableNames, string(k))
}
return tableNames, nil
04:33
In reply to this message
then just loop over tableNames array and for each table do cursor loop with First/Next methods.
NK
04:33
Noel Kuntze
Now I need to see what you did with the get function because mdbx_get doesn't tolerate NULL keys or values in arguments
AS
NK
04:33
Noel Kuntze
Aha
04:34
So with cursor, I can iterate over all keys and values by specifying a NULL key and value first?
04:35
That wasn't evident from the documentation. I just found that one can get the values of a multi-value record
AS
04:35
Alex Sharov
In reply to this message
for First and Next operators - yes, can be NULL. But there is much operators for cursor: https://github.com/erthink/libmdbx/blob/0dd27a46eeb0ef3ba197c512775ccf27ad947e41/mdbx.h#L1456
NK
04:36
Noel Kuntze
Thank you
AS
04:38
Alex Sharov
Sorry, I'm broken man - I vener read documentation online if I can read it in code 🙂
So, yes, cursors API is main thing in mdbx - and mdbx_get is just syntax sugar around cursors.
So, yes, cursors API is main thing in mdbx - and mdbx_get is just syntax sugar around cursors.
MM
21:00
Melbourne Channel Moderator
possible to make libmdbx faster with a wal?
21:01
write speed i mean
14 April 2021
MM
01:59
Melbourne Channel Moderator
can we not setgeometry for the max size and let it grow to the max size of the db's limit? i set 128tb as max size but not sure what it means if i set lower
MM
10:50
Melbourne Channel Moderator
any limits to the number of items that can be stored in the db?
e.g. if limit of db is 128tb and the data stored is 32bytes each,
that means limit is around 4 000 000 000 000 data items? can i assume this?
e.g. if limit of db is 128tb and the data stored is 32bytes each,
that means limit is around 4 000 000 000 000 data items? can i assume this?
Л(
11:00
Леонид Юрьев (Leonid Yuriev)
In reply to this message
MDBX is a memory-mapped DB.
So your system (CPU, RAM, OS kernel) must be able/enough to
I.e. a DB can't be larger than 128 Tb, BUT actual limit may be significantly lower depending of abilities of your system/machine.
So your system (CPU, RAM, OS kernel) must be able/enough to
mmap() the entire DB into the RAM.I.e. a DB can't be larger than 128 Tb, BUT actual limit may be significantly lower depending of abilities of your system/machine.
11:06
In reply to this message
No, this is wrong approximation.
You should take into account the costs of page titles, incomplete page filling (slackness), and the tree structure itself (a branch pages).
Approximately can be estimated between
You should take into account the costs of page titles, incomplete page filling (slackness), and the tree structure itself (a branch pages).
Approximately can be estimated between
DB_SIZE / 2 / ITEM_SIZE and DB_SIZE / 4 / ITEM_SIZE.
MM
11:41
Melbourne Channel Moderator
In reply to this message
i only read a section of the db and not all the db data. so does that mean the db can be larger than ram? as long as it's not used for all db reads / write
11:41
i was thinking of sharding db files into 2GB each so i wont hv any oom issues. is that advisable?
AS
14:39
We run 1Tb db on machines from 8Gb to 256Gb RAM.
MM
14:41
Melbourne Channel Moderator
i think data type is important. i understand this is ethereum blockchain info but i wonder what kind of other case studies / benchmark available, data types etc.
with page cache, i can only guess the performance with small ram and large db. so not sure how much to stretch or there's a guidelines for reference. actual use case production scenario of heavy read/write
with page cache, i can only guess the performance with small ram and large db. so not sure how much to stretch or there's a guidelines for reference. actual use case production scenario of heavy read/write
AS
14:47
Alex Sharov
Hope somebody will answer here, you also can google “lmdb benchmarks”
MM
15:53
Melbourne Channel Moderator
lmdb is designed for fast read and not writes for openldap. i think it's not easy to find anything else
15 April 2021
Zero Xia invited Zero Xia
ZX
03:56
Zero Xia
Hi, I need to manage some cache files, requirement is that the disk usage cannot exceed 20GB, can I get the disk usage of current db file?
AS
04:35
Alex Sharov
All programming languages have function to get size of file. It’s best way. Also funcs env_info (or env_stat) exist
ZX
04:44
Zero Xia
Comparing the two ways, which is more efficient?
AS
ZX
05:30
Zero Xia
I don't know much about mmap. If the database is 20GB size, does it mean I need 20GB memory to use mdbx?
AS
06:39
Alex Sharov
Let me google "lmdb large db RAM" for you:
https://symas.com/understanding-lmdb-database-file-sizes-and-memory-utilization/
https://lmdb.readthedocs.io/en/release/#memory-usage
https://erthink.github.io/libmdbx/intro.html#characteristics
https://stackoverflow.com/questions/52862176/lmdb-open-large-databases-in-a-limited-memory-system
https://blogs.kolabnow.com/2018/02/13/using-and-abusing-memory-with-lmdb-in-kube
https://github.com/erthink/libmdbx/blob/0e0682ff7ada5d96fdcaa405ab58d90358e2c661/mdbx.h#L1019
https://symas.com/understanding-lmdb-database-file-sizes-and-memory-utilization/
https://lmdb.readthedocs.io/en/release/#memory-usage
https://erthink.github.io/libmdbx/intro.html#characteristics
https://stackoverflow.com/questions/52862176/lmdb-open-large-databases-in-a-limited-memory-system
https://blogs.kolabnow.com/2018/02/13/using-and-abusing-memory-with-lmdb-in-kube
https://github.com/erthink/libmdbx/blob/0e0682ff7ada5d96fdcaa405ab58d90358e2c661/mdbx.h#L1019
06:41
Also answered this question 5 messages above 🙂 https://t.me/libmdbx/1749
ZX
08:40
Zero Xia
Thank you very much.
08:42
Is the C++ API recommended to use now with version 0.9.3?
AS
08:54
Alex Sharov
If your app is in C++ - then yes. But if you have feedback - on how to improve C++ API - please share.
ZX
08:56
Zero Xia
I see in change log the c++ api is to be finalized, is it clear when will that happen?
AS
08:58
Alex Sharov
I don’t know. Yuri will answer this question when he can.
ZX
09:14
Zero Xia
Another question, not quite related though...
The sources require Visual C++ version as follows:
# error "At least \"Microsoft C/C++ Compiler\" version 19.00.24234 (Visual Studio 2015 Update 3) is required."
My company uses visual studio 2015 update 3, but the cl version is 19.00.24223.
I tried to install update KB3165756, but the cl version is still 19.00.24223.
Googling the version "19.00.24234", got very few results, the top ones are the github sources of user erthink.
Do you know how to update the compiler version for Visual Studio 2015 Update 3?
The sources require Visual C++ version as follows:
# error "At least \"Microsoft C/C++ Compiler\" version 19.00.24234 (Visual Studio 2015 Update 3) is required."
My company uses visual studio 2015 update 3, but the cl version is 19.00.24223.
I tried to install update KB3165756, but the cl version is still 19.00.24223.
Googling the version "19.00.24234", got very few results, the top ones are the github sources of user erthink.
Do you know how to update the compiler version for Visual Studio 2015 Update 3?
Л(
17:10
Леонид Юрьев (Leonid Yuriev)
In reply to this message
M$ has some oddities with these version numbers...
There are several builds called "2015 update 3" distinguished in the latest version number and there is no any official information (I could not find) about the differences.
In the past, libmdbx was built and tested with MSVC 2013 and 2015.
But now locally I don't use MSVC 2015 or any previous versions.
So I decided that it is best to specify the minimum version of the compiler with used of CI at the https://ci.appveyor.com/project/leo-yuriev/libmdbx/
I recommend using the compiler from the latest update/version of Microsoft Visual Studio 2017, because it looks the least buggy and acceptably smart for modern C++.
However, I don't think there will be any problems with the version you are using.
Nonetheless, you will have to lower the requirements for the compiler version by local edits, because I will not dare to do this in the mainstream without having robust verification.
There are several builds called "2015 update 3" distinguished in the latest version number and there is no any official information (I could not find) about the differences.
In the past, libmdbx was built and tested with MSVC 2013 and 2015.
But now locally I don't use MSVC 2015 or any previous versions.
So I decided that it is best to specify the minimum version of the compiler with used of CI at the https://ci.appveyor.com/project/leo-yuriev/libmdbx/
I recommend using the compiler from the latest update/version of Microsoft Visual Studio 2017, because it looks the least buggy and acceptably smart for modern C++.
However, I don't think there will be any problems with the version you are using.
Nonetheless, you will have to lower the requirements for the compiler version by local edits, because I will not dare to do this in the mainstream without having robust verification.
17:18
In reply to this message
Presumably at the end of this year.
However, I don't think there will be any revolutionary/ideological changes (for no one has pointed out any significant design flaws) but more methods and overloads for convenience.
However, I don't think there will be any revolutionary/ideological changes (for no one has pointed out any significant design flaws) but more methods and overloads for convenience.
AV
17:36
Artem Vorotnikov
@erthink do you know if this will affect MDBX in any way, e.g. hosting on GitHub?
AV
17:36
Artem Vorotnikov
S
SecAtor 15.04.2021 16:48:53
Позитивам прилетело от Министерства финансов США.
Мы разберём этот кейс позднее, а пока давайте пожелаем коллегам спокойствия и хладнокровия.
Мы разберём этот кейс позднее, а пока давайте пожелаем коллегам спокойствия и хладнокровия.
Л(
Л(
18:06
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Nonetheless, I assume that this will not affect
On the other hand, this was expected after Positive Technologies hits to Gartner's quadrant multiple times and IPO plans.
i.e. US purposefully strangles non-US tech companies with leadership claims.
libmdbx, since (theoretically) this sanctions do not apply to individuals, and I personally (yet) do not enter any sanctions lists.On the other hand, this was expected after Positive Technologies hits to Gartner's quadrant multiple times and IPO plans.
i.e. US purposefully strangles non-US tech companies with leadership claims.
AV
18:08
Artem Vorotnikov
In reply to this message
they still could do the IPO in Russia, but I suppose now all top Russian banks (Sber, VTB etc) will chicken out (as usual)
AA
18:11
Alexey Akhunov
IPOs are not cool anymore (after Coinbase). Now you can list directly, no need to pay Goldman Sachs 🙂
AV
18:12
Artem Vorotnikov
In reply to this message
yeah, but the worst sanctions will be inflicted by the Russian financial institutions, who don't want to risk the wrath of US themselves
clear cut case of prisoner's dilemma
clear cut case of prisoner's dilemma
18:13
where do you list if Moscow Exchange shows you the finger
Л(
18:26
Леонид Юрьев (Leonid Yuriev)
An IPO (i.e. make the public company) is a long story...
... and it is not a topic/subject for this group ;)
... and it is not a topic/subject for this group ;)
MM
18:28
Melbourne Channel Moderator
telegram is controlled by russia now too :)
16 April 2021
NK
14:14
Noel Kuntze
Preliminary, test Python bindings are there.
14:15
Please don't give me crap for the low quality but wishes for improvement.
Л(
C
23:49
CZ
does anybody know, if there are any restrictions on mdbx or software that use mdbx, due to affiliation with Positive Technologies and sanctions against this company?
Л(
17 April 2021
C
00:17
CZ
In reply to this message
well, you not being in a sanction list does not not giving guarantees at all i guess. Also, you speaking about conspiracy and making tough political statements in github doesn't help at all 🙂
AA
00:26
Alexey Akhunov
I don't think you'll find any guarantees against sanctions. If you are worried, you may consider using LMDB, for example, because it would be weird if US sanctions NSA: https://github.com/NationalSecurityAgency/lemongraph
00:26
lemongraph uses LMDB
Л(
00:28
Леонид Юрьев (Leonid Yuriev)
AA
00:29
Alexey Akhunov
yeah, that would be cool if they switched lemongraph to MBDX
C
00:30
CZ
In reply to this message
we use two different DB engines, lmdb and mdbx, i personally like mdbx more for many reasons and we have a lot of respect to Leo and his work, just have some concerns about perception of Leo’s work in our international community, and also we have to be careful about possible legal consequences.
00:32
and mdbx_env_set_geometry is one of the things make mdbx better then lmdb
AA
00:32
Alexey Akhunov
you may also want to do some searching, for example: https://law.stackexchange.com/questions/32981/do-international-sanctions-have-an-impact-on-open-source-software
Л(
01:43
Леонид Юрьев (Leonid Yuriev)
on-topic news:
1. Seems the https://github.com/erthink/libmdbx/issues/164 is fixed/resolved now in the
Right now (thanks to access to the ledgerwatch/turbo-geth stands) I can see that MDBX is about 6-7% faster (avg 27.2 ops/s vs 25.5) than LMDB in a highload usecase with a 1 Tb sized DB.
😎
2. However, during the latest refinement an OSX/Darwin/Mach kernel issue/bug was noticed (see https://github.com/erthink/libmdbx/issues/185).
Therefore, all OSX users are kindly requested to check the robustness of the added workaround (the
1. Seems the https://github.com/erthink/libmdbx/issues/164 is fixed/resolved now in the
devel branch.Right now (thanks to access to the ledgerwatch/turbo-geth stands) I can see that MDBX is about 6-7% faster (avg 27.2 ops/s vs 25.5) than LMDB in a highload usecase with a 1 Tb sized DB.
😎
2. However, during the latest refinement an OSX/Darwin/Mach kernel issue/bug was noticed (see https://github.com/erthink/libmdbx/issues/185).
Therefore, all OSX users are kindly requested to check the robustness of the added workaround (the
devel branch for now) in own use cases.
AA
01:47
Alexey Akhunov
thanks a lot, great news (1). We are going to do a bit more testing and then we will be ready to transition from LMDB
C
19 April 2021
Л(
10:57
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Для объективности стоит отметить, что наблюдаемое ранее опережение на 7% оказалось результатом эффекта "моментального среднего" (усреднение за недостаточно длительный период).
По последним данным от @AskAlexSharov, общее время работы с MDBX оказалось на ~0.1% (~5 минут) больше чем с LMDB.
Однако, причины этой разницы объяснимы:
1) в MDBX заголовок страницы на 4 байта больше, а место под данные на 4 байта меньше.
Причин для этого достаточно. Поэтому Говард Чу примерно повторил это решение в следующей версии LMDB (ветка
2) Разница в 4 байта составляет ~0.1%, т.е. из-за этого в БД будет примерно на 0.1% больше страниц с данными, и потребуется на те же 0.1% больше времени на их запись/чтение.
3) Тест оценивает работу с БД размером около 1 Tb на машине с 16 Gb ОЗУ.
Поэтому все результаты всех улучшений MDBX растворяются в затратах на обмен с диском.
По последним данным от @AskAlexSharov, общее время работы с MDBX оказалось на ~0.1% (~5 минут) больше чем с LMDB.
Однако, причины этой разницы объяснимы:
1) в MDBX заголовок страницы на 4 байта больше, а место под данные на 4 байта меньше.
Причин для этого достаточно. Поэтому Говард Чу примерно повторил это решение в следующей версии LMDB (ветка
mdb.master3).2) Разница в 4 байта составляет ~0.1%, т.е. из-за этого в БД будет примерно на 0.1% больше страниц с данными, и потребуется на те же 0.1% больше времени на их запись/чтение.
3) Тест оценивает работу с БД размером около 1 Tb на машине с 16 Gb ОЗУ.
Поэтому все результаты всех улучшений MDBX растворяются в затратах на обмен с диском.
10:59
Увеличенный размер заголовка страницы (наличие номер транзакции) будет сохранён в MDBX, так как позволяет реализовать дополнительные фичи:
- additional DB integrity control;
- transparent spilling/flushing of pages in the WRITEMAP mode.
The second feature was postponed, but now it is 75% ready in the
So I recommend you:
- wait for the "transparent spilling" feature;
- switch to using
- try using 8 Kb pages.
- additional DB integrity control;
- transparent spilling/flushing of pages in the WRITEMAP mode.
The second feature was postponed, but now it is 75% ready in the
devel branch and will be ready soon.So I recommend you:
- wait for the "transparent spilling" feature;
- switch to using
MDBX_WRITEMAP mode;- try using 8 Kb pages.
Л(
11:26
Леонид Юрьев (Leonid Yuriev)
Ранее сделанные доработки (уже доступные в ветке
- либо устраняли деградацию MDBX после экспериментальных/пробных доработок;
- либо были незаметны, так как в ledgerwatch/turbo-geth применяется сортировка для собственных нужд с последующей вставкой в
Таким образом, для сценариев ledgerwatch/turbo-geth наиболее значимым/полезным оказалось исправление auto-readahead feature:
- The defect was that readahead (an intensive caching) enabled for a small database size stay enabled for the beginning of the DB file when it grew.
- This affected the internal heuristics of the Linux kernel much more than expected, as a result, extra data was constantly being pumped from the disk to RAM.
- Now, when a DB size is increased the
master) для более плотного заполнения страниц, показывают улучшение в большинстве сценариев использования. Как минимум пока где-либо не видно ухудшения. Но для ledgerwatch/turbo-geth они не дали эффекта:- либо устраняли деградацию MDBX после экспериментальных/пробных доработок;
- либо были незаметны, так как в ledgerwatch/turbo-geth применяется сортировка для собственных нужд с последующей вставкой в
MDBX_APPEND и/или MDBX_APPEND_DUP режимах.Таким образом, для сценариев ledgerwatch/turbo-geth наиболее значимым/полезным оказалось исправление auto-readahead feature:
- The defect was that readahead (an intensive caching) enabled for a small database size stay enabled for the beginning of the DB file when it grew.
- This affected the internal heuristics of the Linux kernel much more than expected, as a result, extra data was constantly being pumped from the disk to RAM.
- Now, when a DB size is increased the
MADV_RANDOM is enabled for the entire DB and this was enough to fix "the trouble".
AS
11:33
Alex Sharov
🔥great work.
8kb pages - test stared (It's very important for us to decide about 8K pages now - because can't change later).
Writemap - will test after "transparent spilling" - but unlikely Rust - Go can't declare immutable peice of memory - to guarantee safety.
FYI: we will have test results on 256Gb RAM in near future.
8kb pages - test stared (It's very important for us to decide about 8K pages now - because can't change later).
Writemap - will test after "transparent spilling" - but unlikely Rust - Go can't declare immutable peice of memory - to guarantee safety.
FYI: we will have test results on 256Gb RAM in near future.
Л(
11:47
Леонид Юрьев (Leonid Yuriev)
In reply to this message
The
You can get a noticeable (up to 2 times or more) increase in performance on the current
This is the first thing I recommend to try.
MDBX_WRITEMAP is very-very-much useful for TG usecase (1Tb DB, large transactions,16 Gb RAM).You can get a noticeable (up to 2 times or more) increase in performance on the current
devel branch, but for now you need to manually increase the MDBX_opt_txn_dp_limit to the DB size.This is the first thing I recommend to try.
AS
11:48
Alex Sharov
sure
AA
12:01
Alexey Akhunov
That definitely sounds very interesting
f
Л(
12:59
Леонид Юрьев (Leonid Yuriev)
In reply to this message
This is highly dependent on how huge the transactions are and on other details.
But the fundamental difference is that without WRITEMAP, additional memory is required for shadow copies of pages.
Thus, in the worst case, without WRITEMAP:
- if there is not enough RAM (as in your case), any modified (aka dirty) page can discard/ousts other pages from RAM, either be swapped-out itself.
- on transaction commit this can double I/O, i.e a swap-in a dirty page(s) and then write-out it(s) to the DB file, eiher a swap-in other ousted pages
On the other hand, with WRITEMAP and "transparent spilling" feature (even completed partially as it is now in the
But the fundamental difference is that without WRITEMAP, additional memory is required for shadow copies of pages.
Thus, in the worst case, without WRITEMAP:
- if there is not enough RAM (as in your case), any modified (aka dirty) page can discard/ousts other pages from RAM, either be swapped-out itself.
- on transaction commit this can double I/O, i.e a swap-in a dirty page(s) and then write-out it(s) to the DB file, eiher a swap-in other ousted pages
On the other hand, with WRITEMAP and "transparent spilling" feature (even completed partially as it is now in the
devel branch) a dirty page(s) will ousted to DB file by the OS kernel with LRU policy, without requiring any further actions until a such page(s) would be read or changes/altered again.
13:00
Moreover, this should make more benefits on the newest and a future kernels with the latest LRU-patches from Google.
Melbourne Channel Moderator invited Melbourne Channel Moderator
MM
15:05
Melbourne Channel Moderator
https://sudonull.com/post/64006-Key-value-for-storing-metadata-in-storage-Testing-Embedded-Databases-RAIDIX-Blog
what do u think of this blog? is it still accurate today? it was done in 2017
what do u think of this blog? is it still accurate today? it was done in 2017
Л(
15:24
Леонид Юрьев (Leonid Yuriev)
In reply to this message
I advised the authors of that article how to do testing, attended their report at the Highload++ conference, and even spoke there many times myself.
Unfortunately, the study of the results showed that the benchmark was made with obvious errors. These values cannot be trusted, and the conclusions are wrong.
Unfortunately, the study of the results showed that the benchmark was made with obvious errors. These values cannot be trusted, and the conclusions are wrong.
15:24
In reply to this message
I will try to find a link to my comments with comments.
As far as I remember, RocksDB turned out to be faster there, only because the authors did not take into account that the Linux kernel can use all available memory for file cache, without restrictions set on a memory use by a specific process and/or cgroup.
Thus, RockDB, even with random reads, received much more data from the cache, rather than from SSD - this is exactly what is visible in the results (the latency value is too small for random reads of data that could not fit in RAM).
As far as I remember, RocksDB turned out to be faster there, only because the authors did not take into account that the Linux kernel can use all available memory for file cache, without restrictions set on a memory use by a specific process and/or cgroup.
Thus, RockDB, even with random reads, received much more data from the cache, rather than from SSD - this is exactly what is visible in the results (the latency value is too small for random reads of data that could not fit in RAM).
MM
15:25
Melbourne Channel Moderator
looking forward to the comment
Л(
15:29
Try translate by Google or Yandex
MM
15:30
Melbourne Channel Moderator
ok thx
21 April 2021
Л(
13:49
Леонид Юрьев (Leonid Yuriev)
https://www.ptsecurity.com/ww-en/about/news/positive-technologies-official-statement-following-u-s-sanctions/
imho: The US sanctions are an achievement -- means we are doing something essential and necessary for our country.
imho: The US sanctions are an achievement -- means we are doing something essential and necessary for our country.
13:49
23 April 2021
MM
19:39
Melbourne Channel Moderator
how do you use compaction or trigger it manually?
Л(
19:47
Леонид Юрьев (Leonid Yuriev)
In reply to this message
https://github.com/erthink/libmdbx#added-features, sub-item 4
"4. Automatic continuous zero-overhead database compactification.
During each commit libmdbx merges suitable freeing pages into unallocated area at the end of file, and then truncates unused space when a lot enough of."
"4. Automatic continuous zero-overhead database compactification.
During each commit libmdbx merges suitable freeing pages into unallocated area at the end of file, and then truncates unused space when a lot enough of."
24 April 2021
MM
03:17
Melbourne Channel Moderator
No idea why it does not reclaim size. Still same after deletion. I try check again i guess
AV
07:16
Artem Vorotnikov
Л(
12:34
Леонид Юрьев (Leonid Yuriev)
In reply to this message
I don't mind (i.e. will accept a PR) if someone does it properly:
- with support for a similar set of options;
- with CI on Linux/Windows/macOS/FreeBSD;
- for the amalgamated source code;
- optionally: for the non-amalgamated source code, but with gathering version information from git.
However, I do not use Canon, so I will not undertake to do it myself.
On the other hand, this should be easy for the amalgamated source code (i.e. for results of
- with support for a similar set of options;
- with CI on Linux/Windows/macOS/FreeBSD;
- for the amalgamated source code;
- optionally: for the non-amalgamated source code, but with gathering version information from git.
However, I do not use Canon, so I will not undertake to do it myself.
On the other hand, this should be easy for the amalgamated source code (i.e. for results of
make dist).
25 April 2021
MM
10:45
Melbourne Channel Moderator
i wish this db breaks compatibility with lmdb. it's very good and shld stand on its own.
10:45
or at least fork one that breaks compatibility
MM
11:14
Melbourne Channel Moderator
sorry asking something which i think is quite useful but not sure if it's already implemented...
is there a way to compress the db "automatically"? it's ok if it's not but just curious if there's an option to do so because the db is quite large compared with rocksdb-lsm (auto compaction) ones.
i can live with the large db size but would hope to hv some sort of suggestions on how to reduce db size... if any.
is there a way to compress the db "automatically"? it's ok if it's not but just curious if there's an option to do so because the db is quite large compared with rocksdb-lsm (auto compaction) ones.
i can live with the large db size but would hope to hv some sort of suggestions on how to reduce db size... if any.
Л(
14:27
Леонид Юрьев (Leonid Yuriev)
In reply to this message
A b-tree has a set of (well-known) properties and characteristics.
One of ones is that for most DB use cases data altering, the DB pages are freed in pseudo-random/stochastic order.
As a result, with any page allocation strategy, the used and unused pages in the DB file are mixed in pseudo-random/stochastic order.
Moving pages in a b-tree (i.e. defragmenting a b-tree DB) is expensive, because when you move a page, you need to update all the links to it (i.e. update/rewrite all pages with such links).
Thus, defragmenting a b-tree DB at cost is equivalent to copying it, which is done by the
So MDBX does not perform full automatic defragmentation, as this requires copying the database and subsequent changes to the data will again lead to fragmentation.
On the other hand, MDBX performs (mostly with zero cost) partial auto-compaction on each change.
During each commit libmdbx merges the adjacent freed pages with the unallocated area at the end of the file, and then truncates the unused space when there is enough of it.
However, this does not work when the page adjacent to the unallocated portion of DB file is stay used for a long time.
In contrast, in LSM DB files are continuously copied for merge sorting and filtering out deleted data.
One of ones is that for most DB use cases data altering, the DB pages are freed in pseudo-random/stochastic order.
As a result, with any page allocation strategy, the used and unused pages in the DB file are mixed in pseudo-random/stochastic order.
Moving pages in a b-tree (i.e. defragmenting a b-tree DB) is expensive, because when you move a page, you need to update all the links to it (i.e. update/rewrite all pages with such links).
Thus, defragmenting a b-tree DB at cost is equivalent to copying it, which is done by the
mdbx_copy utility and the mdbx_env_copy(), mdbx_env_copy2fd() function(s).So MDBX does not perform full automatic defragmentation, as this requires copying the database and subsequent changes to the data will again lead to fragmentation.
On the other hand, MDBX performs (mostly with zero cost) partial auto-compaction on each change.
During each commit libmdbx merges the adjacent freed pages with the unallocated area at the end of the file, and then truncates the unused space when there is enough of it.
However, this does not work when the page adjacent to the unallocated portion of DB file is stay used for a long time.
In contrast, in LSM DB files are continuously copied for merge sorting and filtering out deleted data.
MM
20:44
Melbourne Channel Moderator
ok i'm splitting the db into 2gb segments. i think the maintennance cost of a very large db is going to be very expensive. how big should the db be for a system of 8gb ram (trying to use as NAS server) and 16gb ram? my db will be bigger than ram and each data size max at 4mb
26 April 2021
Л(
11:39
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Obviously, good performance will be when the entire DB(s) completely fit in RAM and the system does not have to read pages that do not fits in memory.
So system should have enough RAM for systems itself, other applications/processes, file system cache and your DB(s).
So system should have enough RAM for systems itself, other applications/processes, file system cache and your DB(s).
Л(
18:33
Леонид Юрьев (Leonid Yuriev)
The LRU-Spilling feature is ready for testing in the
Spilling = Writing to disk some of the modified (aka dirty) pages in large transactions in order to reduce RAM usage.
LRU = https://en.wikipedia.org/wiki/Cache_replacement_policies#Least_recently_used_(LRU)
devel branch.Spilling = Writing to disk some of the modified (aka dirty) pages in large transactions in order to reduce RAM usage.
LRU = https://en.wikipedia.org/wiki/Cache_replacement_policies#Least_recently_used_(LRU)
Л(
18:54
Леонид Юрьев (Leonid Yuriev)
The LRU-spilling should notable increase performance in a highload write scenarios with huge transactions and lack of RAM.
27 April 2021
MM
00:08
Melbourne Channel Moderator
In reply to this message
any special flag to declare for lru spilling?
Л(
MM
MM
00:33
Melbourne Channel Moderator
this is a great addition. just curious, any roadmaps for the development for libmdbx? coz improvements like this is worth the wait for upgrades. so was wondering what's the roadmap like etc.
MM
01:44
Melbourne Channel Moderator
In reply to this message
this is extremely good but i'm trying to reduce current db size.
i've done 10 mil items entry and deletion of all 10 mil entries and the db size doesnt change. is there a way to trigger a reduction / compaction in the db size manually?
i've done 10 mil items entry and deletion of all 10 mil entries and the db size doesnt change. is there a way to trigger a reduction / compaction in the db size manually?
01:44
it's around 400mb of entries for <32 bytes items
01:44
... for 10 mil entries
AS
04:39
Alex Sharov
1. Free space can be reused only after write transaction commit. 2. Then If you do inserts and deletes - make sense do deletes in one transaction then inserts in another. 3. Make sense to use Coalesce flag and have more smaller transactions - because Coalesce flag logic triggered on every commit. 4. Make sense to reduce shrink step - to shrink more often (i think better reduce growth step and leave shrink -1). 5. Disks are cheap - 400mb from 20Gb it’s 2% - maybe you don’t need this saving. 6. Free pages are filled by zeroes (also free space on used pages are filled by zeroes) - means if after backup of db you will pass it throw any compressor (like lz4) - it will well compress all that zeroes. 7. If you sharding your data - maybe make sense to store each shard in own DBI - and delete them by mdbx_dbi_drop - it will faster and mdbx may have some free space optimizations there (not sure if it’s already there, but dbi_drop looks for me as a good place to do some additional job to sort/defragment pages - because mdbx knows that need delete all if them - while during normal delete key-by-key it works only with 1 page at a time and doesn’t have whole picture). 8. Maybe sorting of large batches of update/deletes before sending them to mdbx may help to reduce db size and fragmentation. 9. Do backups after deletion of shard - maybe not good idea - because if by some reason/bug it will delete too much - then you will not able to restore broken node from backup, so maybe do backup before big moves - because big moves are destructive.
MM
09:42
Melbourne Channel Moderator
In reply to this message
Hmm...
Just give me a way to trigger compaction on the db directly will do. When ibdo shard migration. This will make more sense
Just give me a way to trigger compaction on the db directly will do. When ibdo shard migration. This will make more sense
Л(
10:31
Леонид Юрьев (Leonid Yuriev)
In reply to this message
These are the
mdbx_copy utility, the mdb_new_copy() and mdx_copy2fd() functions.
Л(
10:49
Леонид Юрьев (Leonid Yuriev)
In reply to this message
This depends on the usage scenarios and the specific actions (on a pattern of pages changing). So 0%-100%.
29 April 2021
AS
07:38
Alex Sharov
About db size - there is something like env.info.geo.current - don’t remember exactly.
MM
07:40
Melbourne Channel Moderator
i think page size * leaf pages is the closest. is that it? i'm testing now
MM
07:58
Melbourne Channel Moderator
i think this is the closest match. if hv the geo.current function / feature (i cant find it) pls mention thx. for the moment i'll use page size * leaf pages
Л(
16:58
Леонид Юрьев (Leonid Yuriev)
In reply to this message
You're banging on an open door.
Please just read theinstructions
Please just read the
mdbx.h completely once.
30 April 2021
MM
10:47
Melbourne Channel Moderator
i spent so much time to realised that... Stat() only means for the env. instance. so once out of the env.Update() etc, it's a new Stat()
how can i get the total Stat() for all the leaf pages so i can multiply with page size to get the total size of the actual db (without calculating the empty "nodes"). i want the actual data size used and not the file size of the db.
how can i get the total Stat() for all the leaf pages so i can multiply with page size to get the total size of the actual db (without calculating the empty "nodes"). i want the actual data size used and not the file size of the db.
10:47
geo.current shows the db file size right?
10:48
i dont want to know the db file size coz i can use system commands to get the directory size.
10:59
env.Info().Geo and env.Info().PageOps support <- which one will show the actual "active pages"? coz i will delete items and would like to know exact total data size "in actual use" inside the db file. (not the size of db file)
11:00
this is my last last question. all i need to know is this and i'm so done. spent too much time understanding libmdbx... almost 1 mth + 1 week... appreciate this last bit of help
Л(
11:30
Леонид Юрьев (Leonid Yuriev)
In reply to this message
1. After each change in the database, you can get new
2. When you insert the new data, a filled leaf- branch-pages will split and these splits will accounted in the
3. when you delete data, a emptied leaf- and branch-pages will merge and these merges will be accounted in the
4. When enough unused space/pages accumulates at the end of the DB file, the file will be truncated according to the previously set
mdbx_new_stat() and `mdbx_new_info() values, including pgop_stat, which will reflect the changes made.2. When you insert the new data, a filled leaf- branch-pages will split and these splits will accounted in the
proc_start.split and other stats.3. when you delete data, a emptied leaf- and branch-pages will merge and these merges will be accounted in the
pgop_stat.merge and other stats.4. When enough unused space/pages accumulates at the end of the DB file, the file will be truncated according to the previously set
geo.shrink_threshold.
MM
11:30
Melbourne Channel Moderator
Thx.
Л(
11:38
Леонид Юрьев (Leonid Yuriev)
In reply to this message
imho, all of the above are obvious/expected.
1 May 2021
MM
02:55
Melbourne Channel Moderator
In reply to this message
it wasnt updated in my go binding. it was just updated just now by @AskAlexSharov
Thx
Thx
MM
04:24
Melbourne Channel Moderator
1. i'm trying to get the number of "active" entries of the DB
how do i get that?
2. i've tried adding 40mil data of int 1-40000000, it grows to 1.9gb. when i deleted 30mil data, the db file size didnt shrink at all. i put the shrink at 2mb.
3. i've added 10mil data and delete 5 mil, the db size actually grows larger.
my most important question is still 1. how do i get the number of entries of the db? so i can multiply with page size to get the "actual" active items?
how do i get that?
2. i've tried adding 40mil data of int 1-40000000, it grows to 1.9gb. when i deleted 30mil data, the db file size didnt shrink at all. i put the shrink at 2mb.
3. i've added 10mil data and delete 5 mil, the db size actually grows larger.
my most important question is still 1. how do i get the number of entries of the db? so i can multiply with page size to get the "actual" active items?
MM
04:48
Melbourne Channel Moderator
In reply to this message
can help with this last issue? it's really to calculate the "active" entries. that's all i need. it's my last question actually. i dunno how to get the "in use" Entries of the whole db.
Л(
10:38
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Once again:
You can always get the number of items in a database, the height of the b-tree and number an each kind of pages used.
See
But there is only the number of elements, but no "actual" nor "active" etc.
You can always get the number of items in a database, the height of the b-tree and number an each kind of pages used.
See
mdbx_env_stat_ex() and struct MDBX_stat.But there is only the number of elements, but no "actual" nor "active" etc.
10:38
In reply to this message
Once again:
During any modification (including deletion) a net MVCC snapshot is created inside DB file.
This new shapshot share all non-changed pages with previous one, but for any change to the page, a copy of it is made.
See https://en.wikipedia.org/wiki/Multiversion_concurrency_control and https://en.wikipedia.org/wiki/Copy-on-write
Thus any modification operation could increase database size.
For instance, a deletion at least require update a leaf page, and then links from a branch-page(s) for a whole chain up to btree root.
During any modification (including deletion) a net MVCC snapshot is created inside DB file.
This new shapshot share all non-changed pages with previous one, but for any change to the page, a copy of it is made.
See https://en.wikipedia.org/wiki/Multiversion_concurrency_control and https://en.wikipedia.org/wiki/Copy-on-write
Thus any modification operation could increase database size.
For instance, a deletion at least require update a leaf page, and then links from a branch-page(s) for a whole chain up to btree root.
10:41
In reply to this message
Once again:
One of b-btree properties is that for most DB use cases data altering, the DB pages are freed in pseudo-random/stochastic order.
MDBX performs (mostly with zero cost) partial auto-compaction on each change.
During each commit libmdbx merges the adjacent freed pages with the unallocated area at the end of the file, and then truncates the unused space when there is enough of it.
However, this does not work when the page adjacent to the unallocated portion of DB file is stay used for a long time.
One of b-btree properties is that for most DB use cases data altering, the DB pages are freed in pseudo-random/stochastic order.
MDBX performs (mostly with zero cost) partial auto-compaction on each change.
During each commit libmdbx merges the adjacent freed pages with the unallocated area at the end of the file, and then truncates the unused space when there is enough of it.
However, this does not work when the page adjacent to the unallocated portion of DB file is stay used for a long time.
MM
10:44
Melbourne Channel Moderator
ok i think i get it. i was wondering how to get the compacted size of the db without performing compaction. i guess it's not possible.
AS
11:05
Alex Sharov
Cli tool “mdbx_stat -ef” does printing much different stats (including free space - named GC or FreeList), you can see in source code of mdbx_stat which functions it calling to get this stats.
MM
11:30
Melbourne Channel Moderator
ok i see something now... testing it. it's not easy to test the db
11:39
wow! this is great! it's very very good! everything's there. sorry for asking so much. i see it with stats now.
AS
11:45
Alex Sharov
In reply to this message
“We choose to go to the moon in this decade and do the other things, not because they are easy, but because they are hard.” https://youtu.be/C6-pxKOnvyo
MM
13:30
Melbourne Channel Moderator
feature request : show the pages used quickly without cycling through all values
MM
13:30
Melbourne Channel Moderator
AS
Alex Sharov 01.05.2021 13:26:11
GC stores - 1 key per transaction - all free space past transactions leave there, when all free pages of some tx used - key removed from GC.
13:30
Then just do feature request to mdbx
Л(
13:35
Леонид Юрьев (Leonid Yuriev)
This information (actually much more) is already available via
Nothing todo.
mdbx_dbi_stat(), mdbx_env_stat_ex(), mdbx_env_info_ex().Nothing todo.
AS
15:05
Alex Sharov
looks like:
I will create github issue?
(then as a workaround - for now can iterate over all DBI's and call mdbx_dbi_stat)
mdbx_env_stat_ex returns stats of Main DBI instead of stats of whole db. and lmdb does the same. I will create github issue?
(then as a workaround - for now can iterate over all DBI's and call mdbx_dbi_stat)
Л(
15:09
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Oops, this is the historical behavior of LMDB, which I thought I fixed a long time ago...
Yes, fill an issue, please.
Yes, fill an issue, please.
AS
15:10
Alex Sharov
ok
2 May 2021
MM
00:45
Melbourne Channel Moderator
i thought there was something wrong with my code. i did so many err checks.
MM
06:40
Melbourne Channel Moderator
how long will the devel branch be up before being merged into main? curious question. coz the last update on devel seemed significant
MM
07:28
Melbourne Channel Moderator
In reply to this message
because i'm using golang bindings, i'm not well verse with the internal mechanics or able to express what i thought was "supposed to be". this stat is important.
Sorry wasn't able to express myself as clearly as Alex did coz he can bridge two languages. Hope I didn't cause any inconvenience to the development. It's a great piece of software.
Hope to see it remedied asap. Thx in advance.
Sorry wasn't able to express myself as clearly as Alex did coz he can bridge two languages. Hope I didn't cause any inconvenience to the development. It's a great piece of software.
Hope to see it remedied asap. Thx in advance.
MM
07:43
Melbourne Channel Moderator
In reply to this message
(i cant believe lmdb didnt fix this issue.)
Л(
3 May 2021
MM
06:38
Melbourne Channel Moderator
i can compile 0.9.2 but cant compile 0.9.4
06:38
/usr/local/src/mdbx-go-0.10.2/mdbx/dist# make
## TIP: Use
MDBX_BUILD_OPTIONS =-DNDEBUG=1
## TIP: Use
CFLAGS =-std=gnu11 -O2 -g -Wall -Werror -Wextra -Wpedantic -ffunction-sections -fPIC -fvisibility=hidden -pthread -Wno-error=attributes
CXXFLAGS =-std=gnu++17 -O2 -g -Wall -Werror -Wextra -Wpedantic -ffunction-sections -fPIC -fvisibility=hidden -pthread -Wno-error=attributes
LDFLAGS =-Wl,--gc-sections,-z,relro,-O1 -lrt -pthread
## TIP: Use
MAKE config.h
CC mdbx-static.o
mdbx.c:1677:44: error: missing binary operator before token "("
#define MDBX_ASSUME_MALLOC_OVERHEAD (sizeof(void *) * 2u)
^
mdbx.c:1678:7: note: in expansion of macro 'MDBX_ASSUME_MALLOC_OVERHEAD'
#elif MDBX_ASSUME_MALLOC_OVERHEAD < 0 || MDBX_ASSUME_MALLOC_OVERHEAD > 64 || \
^
GNUmakefile:179: recipe for target 'mdbx-static.o' failed
make: *** [mdbx-static.o] Error 1
## TIP: Use
make V=1 for verbose.MDBX_BUILD_OPTIONS =-DNDEBUG=1
## TIP: Use
make options to listing available build options.CFLAGS =-std=gnu11 -O2 -g -Wall -Werror -Wextra -Wpedantic -ffunction-sections -fPIC -fvisibility=hidden -pthread -Wno-error=attributes
CXXFLAGS =-std=gnu++17 -O2 -g -Wall -Werror -Wextra -Wpedantic -ffunction-sections -fPIC -fvisibility=hidden -pthread -Wno-error=attributes
LDFLAGS =-Wl,--gc-sections,-z,relro,-O1 -lrt -pthread
## TIP: Use
make help to listing available targets.MAKE config.h
CC mdbx-static.o
mdbx.c:1677:44: error: missing binary operator before token "("
#define MDBX_ASSUME_MALLOC_OVERHEAD (sizeof(void *) * 2u)
^
mdbx.c:1678:7: note: in expansion of macro 'MDBX_ASSUME_MALLOC_OVERHEAD'
#elif MDBX_ASSUME_MALLOC_OVERHEAD < 0 || MDBX_ASSUME_MALLOC_OVERHEAD > 64 || \
^
GNUmakefile:179: recipe for target 'mdbx-static.o' failed
make: *** [mdbx-static.o] Error 1
06:40
v
Using built-in specs.
COLLECT_GCC=gcc
COLLECT_LTO_WRAPPER=/usr/lib/gcc/x86_64-linux-gnu/9/lto-wrapper
OFFLOAD_TARGET_NAMES=nvptx-none:hsa
OFFLOAD_TARGET_DEFAULT=1
Target: x86_64-linux-gnu
Configured with: ../src/configure -v --with-pkgversion='Ubuntu 9.3.0-17ubuntu1~20.04' --with-bugurl=file:///usr/share/doc/gcc-9/README.Bugs --enable-languages=c,ada,c++,go,brig,d,fortran,objc,obj-c++,gm2 --prefix=/usr --with-gcc-major-version-only --program-suffix=-9 --program-prefix=x86_64-linux-gnu- --enable-shared --enable-linker-build-id --libexecdir=/usr/lib --without-included-gettext --enable-threads=posix --libdir=/usr/lib --enable-nls --enable-clocale=gnu --enable-libstdcxx-debug --enable-libstdcxx-time=yes --with-default-libstdcxx-abi=new --enable-gnu-unique-object --disable-vtable-verify --enable-plugin --enable-default-pie --with-system-zlib --with-target-system-zlib=auto --enable-objc-gc=auto --enable-multiarch --disable-werror --with-arch-32=i686 --with-abi=m64 --with-multilib-list=m32,m64,mx32 --enable-multilib --with-tune=generic --enable-offload-targets=nvptx-none=/build/gcc-9-HskZEa/gcc-9-9.3.0/debian/tmp-nvptx/usr,hsa --without-cuda-driver --enable-checking=release --build=x86_64-linux-gnu --host=x86_64-linux-gnu --target=x86_64-linux-gnu
Thread model: posix
gcc version 9.3.0 (Ubuntu 9.3.0-17ubuntu1~20.04)
Using built-in specs.
COLLECT_GCC=gcc
COLLECT_LTO_WRAPPER=/usr/lib/gcc/x86_64-linux-gnu/9/lto-wrapper
OFFLOAD_TARGET_NAMES=nvptx-none:hsa
OFFLOAD_TARGET_DEFAULT=1
Target: x86_64-linux-gnu
Configured with: ../src/configure -v --with-pkgversion='Ubuntu 9.3.0-17ubuntu1~20.04' --with-bugurl=file:///usr/share/doc/gcc-9/README.Bugs --enable-languages=c,ada,c++,go,brig,d,fortran,objc,obj-c++,gm2 --prefix=/usr --with-gcc-major-version-only --program-suffix=-9 --program-prefix=x86_64-linux-gnu- --enable-shared --enable-linker-build-id --libexecdir=/usr/lib --without-included-gettext --enable-threads=posix --libdir=/usr/lib --enable-nls --enable-clocale=gnu --enable-libstdcxx-debug --enable-libstdcxx-time=yes --with-default-libstdcxx-abi=new --enable-gnu-unique-object --disable-vtable-verify --enable-plugin --enable-default-pie --with-system-zlib --with-target-system-zlib=auto --enable-objc-gc=auto --enable-multiarch --disable-werror --with-arch-32=i686 --with-abi=m64 --with-multilib-list=m32,m64,mx32 --enable-multilib --with-tune=generic --enable-offload-targets=nvptx-none=/build/gcc-9-HskZEa/gcc-9-9.3.0/debian/tmp-nvptx/usr,hsa --without-cuda-driver --enable-checking=release --build=x86_64-linux-gnu --host=x86_64-linux-gnu --target=x86_64-linux-gnu
Thread model: posix
gcc version 9.3.0 (Ubuntu 9.3.0-17ubuntu1~20.04)
06:43
cc -std=gnu11 -O2 -g -Wall -Werror -Wextra -Wpedantic -ffunction-sections -fPIC -fvisibility=hidden -pthread -Wno-error=attributes -DNDEBUG=1 '-DMDBX_CONFIG_H="config.h"' -ULIBMDBX_EXPORTS -c src/alloy.c -o mdbx-static.o
In file included from src/internals.h:181:0,
from src/alloy.c:15:
src/options.h:176:44: error: missing binary operator before token "("
#define MDBX_ASSUME_MALLOC_OVERHEAD (sizeof(void *) * 2u)
^
src/options.h:177:7: note: in expansion of macro 'MDBX_ASSUME_MALLOC_OVERHEAD'
#elif MDBX_ASSUME_MALLOC_OVERHEAD < 0 || MDBX_ASSUME_MALLOC_OVERHEAD > 64 || \
^
GNUmakefile:391: recipe for target 'mdbx-static.o' failed
make: *** [mdbx-static.o] Error 1
In file included from src/internals.h:181:0,
from src/alloy.c:15:
src/options.h:176:44: error: missing binary operator before token "("
#define MDBX_ASSUME_MALLOC_OVERHEAD (sizeof(void *) * 2u)
^
src/options.h:177:7: note: in expansion of macro 'MDBX_ASSUME_MALLOC_OVERHEAD'
#elif MDBX_ASSUME_MALLOC_OVERHEAD < 0 || MDBX_ASSUME_MALLOC_OVERHEAD > 64 || \
^
GNUmakefile:391: recipe for target 'mdbx-static.o' failed
make: *** [mdbx-static.o] Error 1
06:44
sry, anxious to get back the days i spent testing and debugging. need to quickly make sure my prototype works else i'll be fired. need to show something to boss soon
AS
07:34
Alex Sharov
You didn’t run make config.h before building mdbx. I advise you use makefile of bindings: https://github.com/torquem-ch/mdbx-go/blob/master/Makefile#L36
MM
09:03
Melbourne Channel Moderator
ok... works.
upgrade gcc if u want it working.
i'm using gcc10
upgrade gcc if u want it working.
i'm using gcc10
09:04
u need to be half a rocket scientist to get this to work.
09:04
gcc 4.8.5 default with ubuntu 18.04 does not work.
AS
MM
09:11
Melbourne Channel Moderator
has anyone faced bug in linux of cpu before? is it frequent? that kind of sucks to be honest. how do u wait for it to be fixed?
AS
09:28
Alex Sharov
On github CI - "ubuntu 16.04" has default version of gcc 5.5.0
https://github.com/torquem-ch/mdbx-go/runs/2489865120#step:6:6
So, to support 4.8.5 need some trics, your PR is welcome.
https://github.com/torquem-ch/mdbx-go/runs/2489865120#step:6:6
So, to support 4.8.5 need some trics, your PR is welcome.
MM
09:48
Melbourne Channel Moderator
sudo apt-get update -y &&
sudo apt-get upgrade -y &&
sudo apt-get dist-upgrade -y &&
sudo apt-get install build-essential software-properties-common -y &&
sudo add-apt-repository ppa:ubuntu-toolchain-r/test -y &&
sudo apt-get update -y &&
sudo apt-get install gcc-10 g++-10 -y &&
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-10 60 --slave /usr/bin/g++ g++ /usr/bin/g++-10 &&
sudo update-alternatives --config gcc
sudo apt-get upgrade -y &&
sudo apt-get dist-upgrade -y &&
sudo apt-get install build-essential software-properties-common -y &&
sudo add-apt-repository ppa:ubuntu-toolchain-r/test -y &&
sudo apt-get update -y &&
sudo apt-get install gcc-10 g++-10 -y &&
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-10 60 --slave /usr/bin/g++ g++ /usr/bin/g++-10 &&
sudo update-alternatives --config gcc
09:48
this is my trick for 18.04
i dunno how to do PR for this. you guys can do the PR. hope it helps
i dunno how to do PR for this. you guys can do the PR. hope it helps
MM
10:14
Melbourne Channel Moderator
just curious, mdbx working fine so far, how else can we crash or corrupt it? in theory everything shld work just fine so i'm really curious. other than some special setting of nosync etc. is there anyways to crash / corrupt it other than disk failure.
asking because i'm almost about to migrate crucial data to use this soon.
asking because i'm almost about to migrate crucial data to use this soon.
MM
10:57
Melbourne Channel Moderator
i "feel" faster read speed after upgrade gcc (expected) but i saw performance regression with benchmark for high write transaction.
10:58
can someone look into this? the performance regression is quite serious. what took 7 sec for 10 mil entries is now 22 sec
AS
11:05
Alex Sharov
- take a look to profiler picture first, maybe slow-down is on app side.
- you can create github issue with details about your case. how big entries/transactions/etc... any info you can provide. otherwise unlikely somebody can help.
- You just switched to new LRU and you have big transactions - then you can try increase
- you can create github issue with details about your case. how big entries/transactions/etc... any info you can provide. otherwise unlikely somebody can help.
- You just switched to new LRU and you have big transactions - then you can try increase
MDBX_opt_txn_dp_limit 2 times. And see if it helped or not.
MM
11:16
Melbourne Channel Moderator
ok will try tml.
Л(
11:16
Леонид Юрьев (Leonid Yuriev)
In reply to this message
1. nosync cases with system crash (power failure, kernel oops, etc).
2. misuse API (It is difficult to say anything specific, but with misuse could create some problem or conditions for the manifestation of some defect/error).
3. wrong/invalid pointer dereference, especially in the MDBX_WRITEMAP mode.
4. a disk error.
5. hardware failure (due to the hit of a charged particle from cosmic rays, etc)ю
2. misuse API (It is difficult to say anything specific, but with misuse could create some problem or conditions for the manifestation of some defect/error).
3. wrong/invalid pointer dereference, especially in the MDBX_WRITEMAP mode.
4. a disk error.
5. hardware failure (due to the hit of a charged particle from cosmic rays, etc)ю
MM
Л(
11:18
Леонид Юрьев (Leonid Yuriev)
In reply to this message
This is really strange and unexpected.
I don't have any ideas about the reasons yet.
I don't have any ideas about the reasons yet.
MM
Л(
11:24
In reply to this message
Please provide more info:
1. Commit hash of both (old/fast and new/slowly) versions.
For instance the out of
2. Run your benchmark/test with
1. Commit hash of both (old/fast and new/slowly) versions.
For instance the out of
mdbx_chk -V.2. Run your benchmark/test with
/usr/bin/time util and show it's output.
11:25
In reply to this message
Yes, RAM with ECC reduces the probability of such a problem several times.
11:28
In reply to this message
This should be done automatically for now
https://github.com/erthink/libmdbx/commit/89558657ea504d00ff94281abb8c2e97ff877db8
https://github.com/erthink/libmdbx/commit/89558657ea504d00ff94281abb8c2e97ff877db8
AS
12:18
Alex Sharov
This one is great.
MM
12:43
Melbourne Channel Moderator
In reply to this message
so i dont need to test that right? i just test what Leonid Yuriev mentioned
MM
13:06
Melbourne Channel Moderator
Stat() showing up nicely. appreciate it. cant believe it's fixed so fast.
13:18
i'm "kind of" ok with the current "regression" for the moment. coz behind sched, need to focus on other parts of the db implementation's "wrapper programs" for it to be useful.
cant contribute much to testing speed for now.
when i find anything "not working as expected" will inform here. it's good enough in terms of speed for now for me (even with the "regression")
keep it up!
cant contribute much to testing speed for now.
when i find anything "not working as expected" will inform here. it's good enough in terms of speed for now for me (even with the "regression")
keep it up!
4 May 2021
Michael Lazarev invited Michael Lazarev
7 May 2021
MM
16:15
Melbourne Channel Moderator
i know long running deletion takes up space in mdbx. can the deletion use another db file? as "temporary" working set "cache",
i did delete when db max size is detected as 75% (and then i shard key values to another db file and delete the moved entries). (but geo maxed coz of the long running deletion) so i lowered to 20% of max size detection (which works). but i dont think this is a good solution. feedback appreciated.
i did delete when db max size is detected as 75% (and then i shard key values to another db file and delete the moved entries). (but geo maxed coz of the long running deletion) so i lowered to 20% of max size detection (which works). but i dont think this is a good solution. feedback appreciated.
AS
16:23
Alex Sharov
I did run "cmake" on win
What
What
LDFLAGS need use on Win to link with mdbx?
Л(
17:59
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Hmm, with CMake you don't need care about
Another case: If you use a library built using CMake in another project without CMake, then you need to use "a usual"
LDFLAGS but just add mdbx (or mdbx-static) to you exe/lib CMake's targets.Another case: If you use a library built using CMake in another project without CMake, then you need to use "a usual"
LDFLAGS which depends from toolchain you are using.
AS
18:09
Alex Sharov
lmdb we did build by golang's toolchain, because it had no dependencies. but mdbx has config.h and other moving parts, so - will see.
Л(
18:20
Леонид Юрьев (Leonid Yuriev)
In reply to this message
No, this is impossible.
MDBX is MVCC with ACID.
I.e. the integrity of the database is guaranteed in the event of a failure at any time.
Therefore MDBX never overwrite the pages that form the already committed MVCC snapshots, and which are accessible for non-blocked readers (i.e. other processes).
So, MDBX always write a new versions of changed pages and at the last step update oldest/unused meta-page to be pointed to the new MVCC with corresponding (the new) TXNID.
Thus, the integrity of the database is guaranteed, with the assumption that the meta page update will either be completely successful or will not be committed (this is guaranteed by all decent disks).
Once again, please study the available information about the MDBX/LMDB properties, architecture and internal mechanics before giving questions about "how the universe works".
Otherwise, I will have to stop answering your questions.
https://en.wikipedia.org/wiki/Lightning_Memory-Mapped_Database#Technical_description
MDBX is MVCC with ACID.
I.e. the integrity of the database is guaranteed in the event of a failure at any time.
Therefore MDBX never overwrite the pages that form the already committed MVCC snapshots, and which are accessible for non-blocked readers (i.e. other processes).
So, MDBX always write a new versions of changed pages and at the last step update oldest/unused meta-page to be pointed to the new MVCC with corresponding (the new) TXNID.
Thus, the integrity of the database is guaranteed, with the assumption that the meta page update will either be completely successful or will not be committed (this is guaranteed by all decent disks).
Once again, please study the available information about the MDBX/LMDB properties, architecture and internal mechanics before giving questions about "how the universe works".
Otherwise, I will have to stop answering your questions.
https://en.wikipedia.org/wiki/Lightning_Memory-Mapped_Database#Technical_description
Л(
23:18
Леонид Юрьев (Leonid Yuriev)
I think everything is ready for v0.10.0 release, which is scheduled for May 9.
Suggestions are welcome!
Suggestions are welcome!
AA
23:29
Alexey Akhunov
Wohoo!
MN
23:41
Misha Nikanorov
@erthink about v0.10 - 👏
one suggestion, can you take a look on this defines:
https://github.com/erthink/libmdbx/blob/db4e2cec9c0c14b12473b213dbb11997ea2c8fff/mdbx.h%2B%2B#L213
> ‘path' is unavailable: introduced in iOS 13.0
it breaks build with target under iOS 13.0
one suggestion, can you take a look on this defines:
https://github.com/erthink/libmdbx/blob/db4e2cec9c0c14b12473b213dbb11997ea2c8fff/mdbx.h%2B%2B#L213
> ‘path' is unavailable: introduced in iOS 13.0
it breaks build with target under iOS 13.0
Л(
23:52
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Ok, but I haven't mac at all.
So I can only fix it with your help.
Can you specify since what exactly value
So I can only fix it with your help.
Can you specify since what exactly value
__MAC_OS_X_VERSION_MAIN_REQUIRED in the C++ library for iOS, support for ::std::filesystem::path is implemented ?
MN
23:53
Misha Nikanorov
yeah, sure
Л(
23:56
Леонид Юрьев (Leonid Yuriev)
Might be the easiest way is just to
fprintf() this value for an app built for iOS 13.
8 May 2021
MN
00:01
Misha Nikanorov
hm…can’t attach a screenshots here 😄
basically apple have:
which is
basically apple have:
_LIBCPP_AVAILABILITY_FILESYSTEM_PUSHwhich is
# define _LIBCPP_AVAILABILITY_FILESYSTEM_PUSH \
_Pragma("clang attribute push(__attribute__((availability(macosx,strict,introduced=10.15))), apply_to=any(function,record))") \
_Pragma("clang attribute push(__attribute__((availability(ios,strict,introduced=13.0))), apply_to=any(function,record))") \
_Pragma("clang attribute push(__attribute__((availability(tvos,strict,introduced=13.0))), apply_to=any(function,record))") \
_Pragma("clang attribute push(__attribute__((availability(watchos,strict,introduced=6.0))), apply_to=any(function,record))")
Л(
00:04
Леонид Юрьев (Leonid Yuriev)
This are just a custom Apple's pragmas for LLVM/CLANG, i.e. the useless info.
MN
00:05
Misha Nikanorov
yeah, I’m looking for the right define atm
Л(
00:07
Леонид Юрьев (Leonid Yuriev)
Ok, what is the latest XNU version ?
https://opensource.apple.com/source/xnu/
https://opensource.apple.com/source/xnu/
00:09
Ok, seems the xnu-7195.81.3, lets dig it...
https://github.com/apple/darwin-xnu
https://github.com/apple/darwin-xnu
MN
00:13
Misha Nikanorov
kk, I think it should be this
__IPHONE_OS_VERSION_MIN_REQUIRED 130100
Л(
MN
00:13
Misha Nikanorov
and
__MAC_OS_X_VERSION_MIN_REQUIRED is undefined
00:17
I guess this section should be:
#if defined(DOXYGEN) || \
(defined(__cpp_lib_filesystem) && __cpp_lib_filesystem >= 201703L && \
((defined(__MAC_OS_X_VERSION_MIN_REQUIRED) && __MAC_OS_X_VERSION_MIN_REQUIRED >= 101500) || \
(defined(__IPHONE_OS_VERSION_MIN_REQUIRED) && __IPHONE_OS_VERSION_MIN_REQUIRED >= 130100)))
Л(
00:19
Леонид Юрьев (Leonid Yuriev)
Yes, but what about
__TVOS_VERSION_MIN_REQUIRED and __WATCHOS_VERSION_MIN_REQUIRED ?
MN
00:21
Misha Nikanorov
hmm…. let me try to find that too, never thought about tvos and watchos in case of mdbx
Л(
MN
00:25
Misha Nikanorov
oh, nice 😄
Л(
00:27
Леонид Юрьев (Leonid Yuriev)
Ok, rip ones...
00:28
Please check the https://github.com/erthink/libmdbx/tree/devel
MN
00:31
Misha Nikanorov
yeah, I think looks good, going to double-check one more time
Л(
00:31
Леонид Юрьев (Leonid Yuriev)
👍
MN
00:35
Misha Nikanorov
yup, works perfect now
> ARCHIVE SUCCEEDED [12.528 sec]
> XCFFramework checksum: 5ea71f57c5933f19f30e89febcfdba861be594d723cd0a0ffb9913cafd1d8baa
> ARCHIVE SUCCEEDED [12.528 sec]
> XCFFramework checksum: 5ea71f57c5933f19f30e89febcfdba861be594d723cd0a0ffb9913cafd1d8baa
00:35
thank you!
Л(
00:36
Леонид Юрьев (Leonid Yuriev)
Thanks for reporting this issue.
MN
00:38
Misha Nikanorov
thanks for the making great product!
MM
02:50
Melbourne Channel Moderator
In reply to this message
ok thx for the feedback. i know the limitations etc. Just trying to push the limitations / explore other options to make it more universal to fit different use cases. thx i get the idea how to work around the db.
9 May 2021
Л(
Л(
22:51
Леонид Юрьев (Leonid Yuriev)

22:51

22:51

22:51

10 May 2021
Александр Авраменко invited Александр Авраменко
14 May 2021
MM
05:49
Melbourne Channel Moderator
sry, can i ask this question...
i've tested rocksdb and it seems to be faster in insertion, lesser space used and
For Read
libmdbx = 250k read /s
rocksdb = 150k read /s
For Write
libmdbx = 10k/s (sync + special customization with WAL, otherwise is 250/s for normal ssd sync write)
rocksdb = 150k/s write for nosync.
Storage Capacity
libmdbx = 20GB
rocks = 16GB (after compaction)
to me, it seems if the data is mostly immutable and less often changing (so it's read more, write less) libmdbx is undoubtly the best choice. but other than that... rocksdb seemed better in most use case scenarios. with advancement in lsm tech and wisckey etc. do you think libmdbx can be improved on with the btree it is?
i've tested rocksdb and it seems to be faster in insertion, lesser space used and
For Read
libmdbx = 250k read /s
rocksdb = 150k read /s
For Write
libmdbx = 10k/s (sync + special customization with WAL, otherwise is 250/s for normal ssd sync write)
rocksdb = 150k/s write for nosync.
Storage Capacity
libmdbx = 20GB
rocks = 16GB (after compaction)
to me, it seems if the data is mostly immutable and less often changing (so it's read more, write less) libmdbx is undoubtly the best choice. but other than that... rocksdb seemed better in most use case scenarios. with advancement in lsm tech and wisckey etc. do you think libmdbx can be improved on with the btree it is?
05:51
my only current problem after using for 1 mth on libmdbx is... large data deletion (i thought i can do migration with "compaction") but realised that the size of db actually increases with large single transaction deletion. storage wise, it's not very practical in this sense.
and compaction by copy and delete of original db file is not... practical from application programming point of view.
and compaction by copy and delete of original db file is not... practical from application programming point of view.
NK
06:48
Noel Kuntze
Then use a different DB TBH
M
06:49
Mark
I am wrestling with the same problem
MM
08:59
Melbourne Channel Moderator
In reply to this message
I am using another db now. But i am also hoping theres something here for everyone. I spent 1 mth on libmdbx afterall. Its a great work no doubt
NK
09:00
Noel Kuntze
The compacting issue was explained by Leonid earlier and it's due to the DB's data structure. It's not reasonably implementable.
MM
09:00
Melbourne Channel Moderator
I understand.
09:01
Other than blockchain and mostly immutable db, what else is libmdbx used in so far? Backend for mithrildb?
AS
12:01
Alex Sharov
If you have big write transactions - try next commit strategy - to avoid touch disk for “spill pages”: commit when Tx is half-full:
env.GetOption(OptTxnDpLimit) < 2*txn.Info(true).SpaceDirty
env.GetOption(OptTxnDpLimit) < 2*txn.Info(true).SpaceDirty
Л(
13:32
Леонид Юрьев (Leonid Yuriev)
In reply to this message
As I explained earlier LMDB/MDBX have some problems with large deletions, i.e. with the large lists of retired pages.
Now this is explicitly noted https://github.com/erthink/libmdbx/commit/009e3d6c0f0c09656ff59ae16b890c027e864bf9
To fix this a design of GC/freelist design and the DB format should be changed.
Therefore it impossible for MDBX since DB format was frozen.
This issue will be solved in MithrilDB, where the design of the GC/freelist structure will be quite different (shows better results than state of the art integer compression algorithms, like roaring bitmaps, etc).
Unfortunately, there is no good workaround for the problem of large deletions in MDBX/LMDB.
All you can do is divide/spread ones into smaller transactions.
Now this is explicitly noted https://github.com/erthink/libmdbx/commit/009e3d6c0f0c09656ff59ae16b890c027e864bf9
To fix this a design of GC/freelist design and the DB format should be changed.
Therefore it impossible for MDBX since DB format was frozen.
This issue will be solved in MithrilDB, where the design of the GC/freelist structure will be quite different (shows better results than state of the art integer compression algorithms, like roaring bitmaps, etc).
Unfortunately, there is no good workaround for the problem of large deletions in MDBX/LMDB.
All you can do is divide/spread ones into smaller transactions.
MM
13:41
Melbourne Channel Moderator
In reply to this message
Mithril will be based on mysql or postgres?
Л(
13:42
Леонид Юрьев (Leonid Yuriev)
In reply to this message
MithrilDB is a "MDBX 2.0"
https://erthink.github.io/libmdbx/index.html#MithrilDB
https://erthink.github.io/libmdbx/index.html#MithrilDB
MM
13:43
Melbourne Channel Moderator
Oh ok.
13:44
Any roadmap on launching date?
Л(
14:07
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Mostly of an information will only be available after the first successful (non-public) implementation/use within Positive Technologies products.
17 May 2021
Aleksei Zolotov invited Aleksei Zolotov
24 May 2021
NK
18:49
Noel Kuntze
I want/need to implement automatic compaction of the database after changes were made. I'd like to do that as part of my python bindings. Is it sufficient to acquire the lock file, read the DB and write it out as a new DB, then move the new db files in place of the old ones?
18:50
e.g. pseudocode
acquire-lock
read-write copy DB
mv new old
release-lock
Л(
20:57
Леонид Юрьев (Leonid Yuriev)
The
mdbx_env_copy() and mdbx_env_copy2fd() are allows to copy the database with compactification/defragmentatioin.
NK
22:17
Noel Kuntze
Okay. If I then wanted to replace the old DB, I'd still need to move the files, right?
25 May 2021
AV
12:30
Artem Vorotnikov
@erthink I wonder if it's possible to make a point release with the latest fix?
Л(
12:53
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Hmm, you're asking about the obvious.
So I'm not sure if you understood my original answer correctly:
- there are a couple of functions that make a copy of the database with compactification.
- you can use ones and then replace the DB file, i.e rename the DXB and simply remove both LCKs, but this must be done strictly with the closed database in all processes use it.
- full in-place compactification will never be available in libmdbx, as there is no other way to do it than the above.
- explicit (more than zero-cost automatic) partial compaction can be implemented in libmdbx, but I wouldn't want to waste effort unless absolutely necessary.
So I'm not sure if you understood my original answer correctly:
- there are a couple of functions that make a copy of the database with compactification.
- you can use ones and then replace the DB file, i.e rename the DXB and simply remove both LCKs, but this must be done strictly with the closed database in all processes use it.
- full in-place compactification will never be available in libmdbx, as there is no other way to do it than the above.
- explicit (more than zero-cost automatic) partial compaction can be implemented in libmdbx, but I wouldn't want to waste effort unless absolutely necessary.
NK
12:54
Noel Kuntze
Ty!
Л(
12:55
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Yes, but I would like to complete a couple of TODOs while the tests are running.
Л(
17:03
Леонид Юрьев (Leonid Yuriev)
In reply to this message
For instance, the re-fix for https://github.com/erthink/libmdbx/issues/97 should be confirmed
26 May 2021
S invited S
29 May 2021
Л(
16:10
Леонид Юрьев (Leonid Yuriev)
Ветка master прошла всевозможные тесты и готова для корректирующего релиза v0.10.1.
Основная устраненная проблема = https://github.com/erthink/libmdbx/issues/195
На днях будет релиз.
The master branch has passed all sorts of tests and (seems) is ready for a corrective release v0.10.1.
In a few days it will be.
Основная устраненная проблема = https://github.com/erthink/libmdbx/issues/195
На днях будет релиз.
The master branch has passed all sorts of tests and (seems) is ready for a corrective release v0.10.1.
In a few days it will be.
30 May 2021
AV
02:16
Artem Vorotnikov
@erthink я правильно понимаю, что нельзя вызывать
mdbx_cursor_open на одном MDBX_txn из нескольких потоков одновременно?
Л(
AV
02:18
Artem Vorotnikov
кстати, вопрос с Send и транзакцией на запись пока решил специальным тредом при открытии окружения
02:18
специальный тред для begin/commit/abort
Л(
02:19
Леонид Юрьев (Leonid Yuriev)
Да, это должен быть рабочий вариант, хотя и с оверхедем.
AV
02:19
Artem Vorotnikov
попробовал просто поменять мутексы на SYSV-семафоры (`MDBX_LOCKING=5`) - но почему-то как минимум на макоси отвалились 🤷♂️
Л(
02:22
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Странно.
Насколько помню я тестировал (на виртуалках) всевозможные варианты.
Т.е.
Насколько помню я тестировал (на виртуалках) всевозможные варианты.
Т.е.
make test ломается если задать =5 через MDBX_OPTIONS ?
AV
02:23
Artem Vorotnikov
а, я не смотрел make test
02:23
гонял тесты в эригоне
02:24
причём на макоси конкретно было падение с сигналом
под линуксом может быть просто вскрылся косяк в наших тестах - LockOSThread может просто скрывает некоторые баги у нас
под линуксом может быть просто вскрылся косяк в наших тестах - LockOSThread может просто скрывает некоторые баги у нас
Л(
02:27
Леонид Юрьев (Leonid Yuriev)
Ну пробовать лучше сначала с
Я бы сам попробовал, но сейчас оборудование занято...
make check, а уже потом остальное.Я бы сам попробовал, но сейчас оборудование занято...
AV
02:27
Artem Vorotnikov
да, я посмотрю, спасибо что напомнили 🙂
Л(
02:29
Леонид Юрьев (Leonid Yuriev)
Хотя есть принципиальная разница/недоделка - мои тесты много-процессные, но одно-поточные.
А у вас примерно наоборот.
А у вас примерно наоборот.
AV
02:30
Artem Vorotnikov
да, как раз хотел написать 🙂
02:30
я пробовал одновременно замену на семафоры и снятие прибития корутины к потоку
02:31
кстати, опцию POSIX-семафоров лучше вообще не предлагать на макоси
Л(
02:31
Леонид Юрьев (Leonid Yuriev)
Надо будет поковыряться, но я смогу минимум через неделю, не раньше
AV
02:31
Artem Vorotnikov
они не реализованы и падают с SIGBUS 🙂
Л(
02:41
Леонид Юрьев (Leonid Yuriev)
Ох, я уже всё это проходил... и решил оставить как есть:
- если отлаженный код компилируется и падает, то это проблемы OSX/Apple;
- если (вдруг) починят, то будет работать;
- вроде-бы есть заплатки через ld-preload (не помню как это называется в OSX) и кто-то может попробовать.
- ...
- если отлаженный код компилируется и падает, то это проблемы OSX/Apple;
- если (вдруг) починят, то будет работать;
- вроде-бы есть заплатки через ld-preload (не помню как это называется в OSX) и кто-то может попробовать.
- ...
Л(
18:52
Леонид Юрьев (Leonid Yuriev)
In reply to this message
На всякий, если видите в этом какую-либо необходимость, то я могу попробовать реализовать.
"Попробовать" в том смысле, что будет работать, если у Apple не припасено еще каких-нибудь упрощений/заглушек/сюрпризов.
"Попробовать" в том смысле, что будет работать, если у Apple не припасено еще каких-нибудь упрощений/заглушек/сюрпризов.
AV
19:52
Artem Vorotnikov
In reply to this message
ну мне не так важно sysv или posix - скорее чтобы был рабочий способ закрывать транзакцию из другого потока
19:53
(говоря растовым языком - чтобы MDBX_txn был Send)
19:53
это очень сильно упростит жизнь всем кто пишет на асинхронных M:N рантаймах, в любом языке программирования
Л(
20:08
Леонид Юрьев (Leonid Yuriev)
Да, но... тут есть проблема.
Для этого нужно для _каждой_ поддерживаемой платформы найти замену мьютексам, работающую между процессами и для которой release из другого треда не является UB.
А там где такой замены нет, самостоятельно городить send-санки.
Для этого нужно для _каждой_ поддерживаемой платформы найти замену мьютексам, работающую между процессами и для которой release из другого треда не является UB.
А там где такой замены нет, самостоятельно городить send-санки.
Л(
20:37
Леонид Юрьев (Leonid Yuriev)
Причем:
- сборки библиотеки с разными примитивами IPC не могут работать с одной БД.
- все приличные реализации мьютексов работаю через futex-ы, т.е. в fastpath в разы дешевле любых семафоров.
Поэтому нельзя просто переключить с мьютексов на семафоры, ибо это потеря эффективности в большинстве сценариев использования.
- сборки библиотеки с разными примитивами IPC не могут работать с одной БД.
- все приличные реализации мьютексов работаю через futex-ы, т.е. в fastpath в разы дешевле любых семафоров.
Поэтому нельзя просто переключить с мьютексов на семафоры, ибо это потеря эффективности в большинстве сценариев использования.
20:50
Соответственно, получается что при использовании мьютексов нужно делать send-санки, а это специфический геморрой:
В общем случае, следует рассчитывать что треды стартующие и завершающие транзакцию могут тусоваться как угодно.
Поэтому через межтредовый пинг-понг нужно делать как старт, так и остановку пишущих транзакций.
В итоге получается, что следует делать санки для pthread_mutex_lock() и pthread_mutex_unlock() через отдельный тред.
Внутренняя очередь, межтредоыве сигналы или even loop, какой-то механизм отмены запросов поставленных в очередь, обработка сигналов для тредов ждуших в очереди...
Всё это отладить, задокументировать, обложить тестами и проверками для ловли ошибок использования...
В общем случае, следует рассчитывать что треды стартующие и завершающие транзакцию могут тусоваться как угодно.
Поэтому через межтредовый пинг-понг нужно делать как старт, так и остановку пишущих транзакций.
В итоге получается, что следует делать санки для pthread_mutex_lock() и pthread_mutex_unlock() через отдельный тред.
Внутренняя очередь, межтредоыве сигналы или even loop, какой-то механизм отмены запросов поставленных в очередь, обработка сигналов для тредов ждуших в очереди...
Всё это отладить, задокументировать, обложить тестами и проверками для ловли ошибок использования...
20:55
Всё это реализуемо, но важно что требуется именно для асинхронных рантаймов, где как-раз уже реализованы все эти очереди и send-санки.
Получается что удобства асинхронных рантаймов внутри libmdbx нужно повторить часть функционала этих рантаймов.
:)
Получается что удобства асинхронных рантаймов внутри libmdbx нужно повторить часть функционала этих рантаймов.
:)
21:08
@vorot93, с учетом вышеизложенного предлагаю так:
- внутри MDBX каких-либо send-санок не будет, ибо это будет плохим/урезанным аналогом любого асинхронного фреймворка/рантайма.
- в API добавляется функция позволяющая узнать позволяет ли используемый механизм IPC делать unlock из другого потока, либо требует санок.
- в API добавляется флажок позволяющий отключить контроль треда-хозяина для пишущих транзакций.
Соответственно, в своём коде вы сможете избавиться от накладных расходов в тех случаях, когда возможен ipc-unlock из другого потока.
Тогда можно уже сейчас всё это отлаживать, а также переходить на семафоры и обратно.
Что скажете ?
- внутри MDBX каких-либо send-санок не будет, ибо это будет плохим/урезанным аналогом любого асинхронного фреймворка/рантайма.
- в API добавляется функция позволяющая узнать позволяет ли используемый механизм IPC делать unlock из другого потока, либо требует санок.
- в API добавляется флажок позволяющий отключить контроль треда-хозяина для пишущих транзакций.
Соответственно, в своём коде вы сможете избавиться от накладных расходов в тех случаях, когда возможен ipc-unlock из другого потока.
Тогда можно уже сейчас всё это отлаживать, а также переходить на семафоры и обратно.
Что скажете ?
31 May 2021
Л(
14:42
Леонид Юрьев (Leonid Yuriev)
@vorot93, еще как-то забыл написать что
Поэтому для замены POSIX
dispatch_semaphore_t - это внутри-процессный семафор, т.е. для синхронизации потоков внутри _одного_ процесса.Поэтому для замены POSIX
sem_t не годятся.
AV
14:43
Artem Vorotnikov
на самом деле очень контринтуитивно что мутексы работают между процессами, но нельзя разблокировать из другого потока 😕
14:45
In reply to this message
будет круто если будет функция на уровне
а чем флажок будет отличаться от
MDBX_env, которая позволит понять нужно ли делать спецпоток или нета чем флажок будет отличаться от
MDBX_TXN_CHECKOWNER?
Л(
14:50
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Ну так POSIX придумали.
Реально оно работает на многих системах, но вызывает возврат ошибок при включенном контроле и ругань санитайзеров/анализаторов.
Реально оно работает на многих системах, но вызывает возврат ошибок при включенном контроле и ругань санитайзеров/анализаторов.
14:53
In reply to this message
MDBX_TXN_CHECKOWNER - это опция сборки, а флажок будет делать тоже самое (отключать контроль), но не везде (get/put будет без контроля, а commit/abort с контролем).
AV
15:07
Спасибо 🙂
ПО
16:59
Павел Осипов
В рамках выступления на стартовавшей сегодня конфе Podlodka Crew запилил демо-приложение, использующее LMDB на iOS. Основано на опыте применения данной БД в мобильных приложениях для iOS и Android Облака Mail_ru. Возможно, кто-то найдёт это для себя полезным. Буду рад ответить на любые вопросы.
https://github.com/pavelosipov/PodlodkaFiles
https://github.com/pavelosipov/PodlodkaFiles
Л(
Л(
23:21
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Пока еще не за что.
https://github.com/erthink/libmdbx/issues/200
https://github.com/erthink/libmdbx/issues/200
3 June 2021
Alexander invited Alexander
4 June 2021
AS
11:13
Alex Sharov
If key length is 28bytes and value size
(28+8+1950+8) * 2 = 3988 bytes for data
4096 - 3988 = 108 bytes for metadata
1950bytes - will mdbx able place 2 such records on 1 page? (28+8+1950+8) * 2 = 3988 bytes for data
4096 - 3988 = 108 bytes for metadata
Л(
11:14
Леонид Юрьев (Leonid Yuriev)
Yes
5 June 2021
Л(
15:01
Леонид Юрьев (Leonid Yuriev)
off-topic:
- ищу где в Москве можно купить (сделать предзаказ) на Intel Xeon 5317 и матплату Supermicro X12SPA-TF.
- оба продукта совсем новые (Q2 2021).
- требуются для реализации и отладки полноценной поддержки Persistent Memory в libmdbx.
- ищу где в Москве можно купить (сделать предзаказ) на Intel Xeon 5317 и матплату Supermicro X12SPA-TF.
- оба продукта совсем новые (Q2 2021).
- требуются для реализации и отладки полноценной поддержки Persistent Memory в libmdbx.
6 June 2021
AV
12:17
Artem Vorotnikov
@erthink а курсоры на запись в одну dbi синхронизируются между собой? их можно в разных потоках использовать?
Л(
12:19
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Да, изменения сделанные через один курсор сразу видны через другой.
Курсоры можно использовать из разных потоков (при отключенном контроле), но не одновременно.
Курсоры можно использовать из разных потоков (при отключенном контроле), но не одновременно.
AV
12:20
Artem Vorotnikov
но если одновременно вызвать два курсора, то будет гонка? т.е. должно быть по мутексу на каждую dbi?
Л(
12:21
Леонид Юрьев (Leonid Yuriev)
В пишущей транзакции ничего нельзя делать одновременно из разных потоков, даже с разными dbi.
AV
12:22
Artem Vorotnikov
о как, понятно, т.е. один большой мутекс на всё
12:22
спасибо!
Л(
12:23
Леонид Юрьев (Leonid Yuriev)
По исходному дизайну пишущей транзакцией владеет один поток и при этом владеет глобальным мутексом защищающем запись в БД.
12:26
Аналогично и с читающими транзакциями (одна транзакция = один поток), только одни могут выполняться параллельно.
Но с никакой одной транзакцией нельзя одновременно из разных потоков, включая создание/закрытие курсоров.
Но с никакой одной транзакцией нельзя одновременно из разных потоков, включая создание/закрытие курсоров.
8 June 2021
Станислав Очеретный invited Станислав Очеретный
СО
10:54
Станислав Очеретный
Добрый день.
@erthink, можно ли использовать LMDX в таком сценарии:
1. Целевая платформа Windows
2. Один пишущий поток
3. Один читающий поток в GUI
4. В этом читающем GUI потоке по таймеру обновляются widget-ы при этом создаются читающие транзакции.
5. Может быть ситуация, когда создается новая транзакция при незаконченной предыдущей
Будет ли в этой ситуации Deadlock?
@erthink, можно ли использовать LMDX в таком сценарии:
1. Целевая платформа Windows
2. Один пишущий поток
3. Один читающий поток в GUI
4. В этом читающем GUI потоке по таймеру обновляются widget-ы при этом создаются читающие транзакции.
5. Может быть ситуация, когда создается новая транзакция при незаконченной предыдущей
Будет ли в этой ситуации Deadlock?
Л(
11:10
Леонид Юрьев (Leonid Yuriev)
In reply to this message
0. s/LMDX/MDBX/
1. Да
2. Да
3. Да
4. Да
5.
Да, будет работать, но есть ограничения:
5.1.
Каждая транзакция должна использоваться и завершаться только создавшим её потоком.
В каждом потоке для БД одновременно может быть только одна транзакция.
Есть варианты как снять/обойти эти ограничения, но так делать настоятельно не рекомендуется (легко допустить сложно-обнаруживаемые ошибки, трудно отлаживать, невозможно верифицировать).
5.2 Одновременно может быть не более одной пишущей транзакции, запустить следующую можно только после завершения предыдущей.
5.3. Каждая читающая транзакция будет видеть свой снимок данных, который был последним на момент её старта.
1. Да
2. Да
3. Да
4. Да
5.
Да, будет работать, но есть ограничения:
5.1.
Каждая транзакция должна использоваться и завершаться только создавшим её потоком.
В каждом потоке для БД одновременно может быть только одна транзакция.
Есть варианты как снять/обойти эти ограничения, но так делать настоятельно не рекомендуется (легко допустить сложно-обнаруживаемые ошибки, трудно отлаживать, невозможно верифицировать).
5.2 Одновременно может быть не более одной пишущей транзакции, запустить следующую можно только после завершения предыдущей.
5.3. Каждая читающая транзакция будет видеть свой снимок данных, который был последним на момент её старта.
СО
11:19
Станислав Очеретный
Приложение appverif.exe показывает рекурсивный вызов mdbx_srwlock.
База используется с флагом MDBX_NOTLS
Первая транзакция захватывает lock
if (txn->mt_flags & MDBX_RDONLY) {
#if defined(_WIN32) || defined(_WIN64)
if ((size > env->me_dbgeo.lower && env->me_dbgeo.shrink) ||
(mdbx_RunningUnderWine() &&
/* under Wine acquisition of remap_guard is always required,
* since Wine don't support section extending,
* i.e. in both cases unmap+map are required. */
size < env->me_dbgeo.upper && env->me_dbgeo.grow)) {
txn->mt_flags |= MDBX_SHRINK_ALLOWED;
mdbx_srwlock_AcquireShared(&env->me_remap_guard);
}
Вторая транзакция при незаконченной первой лочится на
MDBX_INTERNAL_FUNC int mdbx_rdt_lock(MDBX_env *env) {
mdbx_srwlock_AcquireShared(&env->me_remap_guard);
База используется с флагом MDBX_NOTLS
Первая транзакция захватывает lock
if (txn->mt_flags & MDBX_RDONLY) {
#if defined(_WIN32) || defined(_WIN64)
if ((size > env->me_dbgeo.lower && env->me_dbgeo.shrink) ||
(mdbx_RunningUnderWine() &&
/* under Wine acquisition of remap_guard is always required,
* since Wine don't support section extending,
* i.e. in both cases unmap+map are required. */
size < env->me_dbgeo.upper && env->me_dbgeo.grow)) {
txn->mt_flags |= MDBX_SHRINK_ALLOWED;
mdbx_srwlock_AcquireShared(&env->me_remap_guard);
}
Вторая транзакция при незаконченной первой лочится на
MDBX_INTERNAL_FUNC int mdbx_rdt_lock(MDBX_env *env) {
mdbx_srwlock_AcquireShared(&env->me_remap_guard);
11:20
Первая лочится в функции mdbx_txn_renew0
11:20
Вторая в mdbx_rdt_lock
11:26
Из документации:
Shared mode SRW locks should not be acquired recursively as this can lead to deadlocks when combined with exclusive acquisition.
Shared mode SRW locks should not be acquired recursively as this can lead to deadlocks when combined with exclusive acquisition.