libmdbx (2022-05-10 ... 2022-12-21)
Previous messages

Исторически такой возможности в явном виде нет.
Причина в том, что для совместимости/схожести с LMDB (а у LMDB с более ранними движками) поддерживает работа без именованных subDB, когда DBI-хендл открывается с name==NULL.
В этом режиме key-value пары хранятся в основном b-tree (aka MainDB), вместе с вложенными b-tree именованных subDB.
Соответственно, чтобы увидеть/перебрать все subDB достаточно:
- открыть курсор для MainDB (задать name = NULL);
- перебрать через курсор все записи;
- каждая запись будет либо соответствовать subDB (при этом ключ будет являться именем), либо kv-парами в MainDB (если таковые были созданы).
https://libmdbx.dqdkfa.ru/group__c__crud.html#gadc9d57659242902003bb5459bc063b32
OS: Linux
libmdbx version: 0.12.1.0
 Next messages
Next messages
10 May 2022
РЛ
11:42
Руслан Лайшев
Смотрю в курсоры, по пред. давнему опыту вроде условия какие-то должен выставить для выборки по key-ю, а тут не соображу.
Л(
12:48
Леонид Юрьев (Leonid Yuriev)
Вы слегка путаете key-value и sql.
https://gitflic.ru/project/erthink/libmdbx/blob?file=example%2Fexample-mdbx.c
https://gitflic.ru/project/erthink/libmdbx/blob?file=example%2Fexample-mdbx.c
РЛ
12:51
Руслан Лайшев
Может и путаю, но это не страшно. 😊
Значит никак - так никак. Ладно, будем дальше думать ...
Значит никак - так никак. Ладно, будем дальше думать ...
AS
13:34
Alex Sharov
In reply to this message
Добавляйте в начало ключа timestamp вставки, будете иметь данные отсортированные по нему (по ключу).
РЛ
13:35
Руслан Лайшев
Если так то и секуенс сгодится.
13:40
Но тогда как искать по исходному "без таймстампа" ключу ?
AS
13:40
Alex Sharov
In reply to this message
Либо заводите 2-ю коллекцию как индекс: timestamp -> id
Или если нужно groupBy:
groupByDate(timestamp) -> array_of_ids
Или groupByDate(timestamp) -> roaring_bitmap_of_ids
Если нужен композитный индекс - напихивайте в ключ больше: col1 + col2 -> id
Или если нужно groupBy:
groupByDate(timestamp) -> array_of_ids
Или groupByDate(timestamp) -> roaring_bitmap_of_ids
Если нужен композитный индекс - напихивайте в ключ больше: col1 + col2 -> id
РЛ
13:41
Руслан Лайшев
Да, этот путь ясен.
AS
13:42
Alex Sharov
“prefix compression” здесь называется DupSort.
13:42
Курсор умеет seek на префикс
13:43
GET_RANGE вроде называется
Л(
13:46
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Пардон, но тут достаточно принципиальная "путаница".
Выбирая движок key-value нужно начинать с необходимых возможностей, включая порядок ключей и т.п.
Если "из каробки" нужны разные (вторичные) индексы, курсоры с условиями, то нужно смотреть не на key-value.
Например, есть libfpta на основе libmdbx.
Выбирая движок key-value нужно начинать с необходимых возможностей, включая порядок ключей и т.п.
Если "из каробки" нужны разные (вторичные) индексы, курсоры с условиями, то нужно смотреть не на key-value.
Например, есть libfpta на основе libmdbx.
РЛ
14:00
Руслан Лайшев
table.h - недоступна, 404.
Чесслово, с плюсами заморачиваться не хочу. Буду выкручиваться как-нибудь по другому.
Чесслово, с плюсами заморачиваться не хочу. Буду выкручиваться как-нибудь по другому.
Л(
РЛ
14:06
Руслан Лайшев
Ок. Спсб, изучу.
РЛ
18:16
Руслан Лайшев
Коллеги. опять пардон, в код лезть мозгов не хватает, лучше умных спрошу:
вот эта штука
вот эта штука
mdbx_dbi_sequence() - между открытиями не обнуляется ?
Л(
18:21
Леонид Юрьев (Leonid Yuriev)
А какой смысл было-бы добавлять эту функцию в библиотеку вне семантики ACID?
РЛ
18:24
Руслан Лайшев
Не знаю, вопрос был не в этом. 😊 Так значит могу быть спокоен что де sequence сохраняется "где-то там" и при открытии восстанавливается сохранённое значение.
Мне бы ответ попроще: да, нет. 😊
Мне бы ответ попроще: да, нет. 😊
A
23:59
для такого примера получаю max_maps_reached
11 May 2022
A
00:00
Aleksei🐈
хотя в комментарии к max_maps указано Zero means default value.
00:01
наверно либо комментарий подправить надо либо в какой-то момент собственно подставлять значение дефолтное
Л(
00:07
Леонид Юрьев (Leonid Yuriev)
"... By default only unnamed key-value database could used and appropriate value should set by MDBX_opt_max_db to using any more named subDB(s)..."
https://libmdbx.dqdkfa.ru/group__c__api.html#gga671855605968c3b1f89a72e2d7b71eb3a5501f6899c2a3c82bedcbc079b850247
Но соглашусь что логично добавить в описание C++ API ссылку на описание этого значения по-умолчанию.
merge-request-ы приветствуются ;)
https://libmdbx.dqdkfa.ru/group__c__api.html#gga671855605968c3b1f89a72e2d7b71eb3a5501f6899c2a3c82bedcbc079b850247
Но соглашусь что логично добавить в описание C++ API ссылку на описание этого значения по-умолчанию.
merge-request-ы приветствуются ;)
A
15:50
Aleksei🐈
In reply to this message
Тэкс, немного глупый вопрос, а как форкать проект на GitFlic? 🙂
Л(
16:59
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Пока никак.
Этот функционал сейчас не готов (см https://gitflic.ru/project/gitflic/gitflic/issue/104) и я не уверен, что они его сделают (могут быть действующие в РФ патенты на очевидные вещи, но уже полученные всякими M$).
Технически GitFlic предлагает создавать "команды" для подобного взаимодействия, но пока создание команд только по запросу в техподдержку.
Конечно, у меня нет сложностей направить такой запрос и его удовлетворят, но:
- это неудобная модель разработки для редких/одиночных патчей (требуется больше приседаний для вступления и управления правами).
- маловероятно что функционал "команд" готов/отлажен, а у разработчиков GitFlic сейчас аврал по другим задачам.
Поэтому, пока варианты такие:
- заводите issue и прикдываете патч, либо ссылку на патч.
- выкладываете ссылку на патч сюда или в личном сообщении.
- отправляете патч почтой (можно даже настроить git для отправки почты через yandex, mail.ru/vk, gmail и т.п.).
Этот функционал сейчас не готов (см https://gitflic.ru/project/gitflic/gitflic/issue/104) и я не уверен, что они его сделают (могут быть действующие в РФ патенты на очевидные вещи, но уже полученные всякими M$).
Технически GitFlic предлагает создавать "команды" для подобного взаимодействия, но пока создание команд только по запросу в техподдержку.
Конечно, у меня нет сложностей направить такой запрос и его удовлетворят, но:
- это неудобная модель разработки для редких/одиночных патчей (требуется больше приседаний для вступления и управления правами).
- маловероятно что функционал "команд" готов/отлажен, а у разработчиков GitFlic сейчас аврал по другим задачам.
Поэтому, пока варианты такие:
- заводите issue и прикдываете патч, либо ссылку на патч.
- выкладываете ссылку на патч сюда или в личном сообщении.
- отправляете патч почтой (можно даже настроить git для отправки почты через yandex, mail.ru/vk, gmail и т.п.).
Uncel Duk invited Uncel Duk
12 May 2022
РЛ
11:22
Руслан Лайшев
Hi All!
Коллеги, создаю subDB вызовом :
Коллеги, создаю subDB вызовом :
mdbx_dbi_open( txn, "my_submDB-1" ...)
mdbx_dbi_open( txn, "my_submDB-2" ...)
что-то не соображу , есть ли штатный механизьм получить список этих subDB ?
AS
РЛ
13:13
Руслан Лайшев
Оооот спасибо!
РЛ
13:31
Руслан Лайшев
А как отличить что там строчка subDB - а что обычные записи ?
Л(
15:10
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Без использования внутреннего API никак.
Можно проверять что ключи являются печатными строками и пытаться открывать их как subDB.
API сохранено максимально совместимым с LMDB, а там Говард Чу особо не церемонился.
Плюс это имеет какие-то исторические/традиционные увязки с BDB, NDB и т.п.
Поэтому API позволяет использовать MainDB непосредственно как плоскую key-value, либо создавать именованные subDB, которые являются записями специального типа (со ссылкой на свой b+tree root) и могут соседствовать с обычными key-value записями в MainDB.
Можно проверять что ключи являются печатными строками и пытаться открывать их как subDB.
API сохранено максимально совместимым с LMDB, а там Говард Чу особо не церемонился.
Плюс это имеет какие-то исторические/традиционные увязки с BDB, NDB и т.п.
Поэтому API позволяет использовать MainDB непосредственно как плоскую key-value, либо создавать именованные subDB, которые являются записями специального типа (со ссылкой на свой b+tree root) и могут соседствовать с обычными key-value записями в MainDB.
РЛ
15:10
Руслан Лайшев
Ясно. Спасибо!
AS
A
15:38
Aleksei🐈
Напомните плз, mdbx_cursor_del после удаления текущего элемента на следующий перемещается или на предыдущий, или после удаления все равно двигать нужно?
Л(
15:49
Леонид Юрьев (Leonid Yuriev)
Да, писать нельзя.
Т.е. нельзя обновлять записи соответствующие subDb = именнованная таблица при этом станет недоступной, но страницы составляющие её b+tree не будут освобождены.
Насколько помню так и не добавил защиту от таких действий.
Т.е. нельзя обновлять записи соответствующие subDb = именнованная таблица при этом станет недоступной, но страницы составляющие её b+tree не будут освобождены.
Насколько помню так и не добавил защиту от таких действий.
15:56
In reply to this message
см. внимательно описание функции https://libmdbx.dqdkfa.ru/group__c__crud.html#ga124fee3155425c8d20ca86bfd2d10831
спойлер = работают оба варианта, т.е. курсор перемещается на следующий элемент, но игнорирует одно последующее перемещение "next'".
спойлер = работают оба варианта, т.е. курсор перемещается на следующий элемент, но игнорирует одно последующее перемещение "next'".
A
16:02
Aleksei🐈
In reply to this message
Да, спасибо вижу, хотя явного упоминания что курсор на следующий элемент сдвигается нет, но в принципе понятно
Л(
16:12
Леонид Юрьев (Leonid Yuriev)
In reply to this message
"Both MDBX_NEXT and MDBX_GET_CURRENT will return the same record after this operation."
Эта строчка еще со времен LMDB ;)
Эта строчка еще со времен LMDB ;)
A
13 May 2022
11:40
Deleted Account
I can not build for IOS. Using iOS.toolchain.cmake(https://github.com/leetal/ios-cmake).
Commands:
1. cmake .. -G Xcode -DCMAKE_TOOLCHAIN_FILE=../../ios.toolchain.cmake -DPLATFORM=OS64
2. cmake --build . --config Release
Commands:
1. cmake .. -G Xcode -DCMAKE_TOOLCHAIN_FILE=../../ios.toolchain.cmake -DPLATFORM=OS64
2. cmake --build . --config Release
11:44
The following build commands failed:
CompileC /Users/igors/src/libmdbx/Src/libmdbx-native/build/CMakeFiles/CMakeTmp/CMAKE_TRY_COMPILE.build/Debug-iphoneos/cmTC_709fb.build/Objects-normal/arm64/src.o /Users/igors/src/libmdbx/Src/libmdbx-native/build/CMakeFiles/CMakeTmp/src.cxx normal arm64 c++ com.apple.compilers.llvm.clang.1_0.compiler (in target 'cmTC_709fb' from project 'CMAKE_TRY_COMPILE')
(1 failure)
Source file was:
#if defined(SIZEOF_INT128) && !defined(GLIBCXX_TYPE_INT_N_0) && defined(clang) && clang_major__ < 4
#define __GLIBCXX_BITSIZE_INT_N_0 128
#define GLIBCXX_TYPE_INT_N_0 int128
#endif
#ifndef __has_include
#define __has_include(header) (0)
#endif
#if __has_include(<version>)
#include <version>
#endif
#include <cstdlib>
#include <string>
#if defined(cpp_lib_string_view) && cpp_lib_string_view >= 201606L
#include <string_view>
#endif
#if defined(cpp_lib_filesystem) && cpp_lib_filesystem >= 201703L
#include <filesystem>
#else
#include <experimental/filesystem>
#endif
#if (defined(cpp_lib_filesystem) && cpp_lib_filesystem >= 201703L && (!defined(MAC_OS_X_VERSION_MIN_REQUIRED) MAC_OS_X_VERSION_MIN_REQUIRED >= 101500) && (!defined(IPHONE_OS_VERSION_MIN_REQUIRED) IPHONE_OS_VERSION_MIN_REQUIRED >= 130100))
namespace fs = ::std::filesystem;
#elif defined(cpp_lib_experimental_filesystem) && cpp_lib_experimental_filesystem >= 201406L
namespace fs = ::std::experimental::filesystem;
#endif
int main(int argc, const char*argv[]) {
fs::path probe(argv[0]);
if (argc != 1) throw fs::filesystem_error(std::string("fake"), std::error_code());
return fs::is_directory(probe.relative_path());
}
CompileC /Users/igors/src/libmdbx/Src/libmdbx-native/build/CMakeFiles/CMakeTmp/CMAKE_TRY_COMPILE.build/Debug-iphoneos/cmTC_709fb.build/Objects-normal/arm64/src.o /Users/igors/src/libmdbx/Src/libmdbx-native/build/CMakeFiles/CMakeTmp/src.cxx normal arm64 c++ com.apple.compilers.llvm.clang.1_0.compiler (in target 'cmTC_709fb' from project 'CMAKE_TRY_COMPILE')
(1 failure)
Source file was:
#if defined(SIZEOF_INT128) && !defined(GLIBCXX_TYPE_INT_N_0) && defined(clang) && clang_major__ < 4
#define __GLIBCXX_BITSIZE_INT_N_0 128
#define GLIBCXX_TYPE_INT_N_0 int128
#endif
#ifndef __has_include
#define __has_include(header) (0)
#endif
#if __has_include(<version>)
#include <version>
#endif
#include <cstdlib>
#include <string>
#if defined(cpp_lib_string_view) && cpp_lib_string_view >= 201606L
#include <string_view>
#endif
#if defined(cpp_lib_filesystem) && cpp_lib_filesystem >= 201703L
#include <filesystem>
#else
#include <experimental/filesystem>
#endif
#if (defined(cpp_lib_filesystem) && cpp_lib_filesystem >= 201703L && (!defined(MAC_OS_X_VERSION_MIN_REQUIRED) MAC_OS_X_VERSION_MIN_REQUIRED >= 101500) && (!defined(IPHONE_OS_VERSION_MIN_REQUIRED) IPHONE_OS_VERSION_MIN_REQUIRED >= 130100))
namespace fs = ::std::filesystem;
#elif defined(cpp_lib_experimental_filesystem) && cpp_lib_experimental_filesystem >= 201406L
namespace fs = ::std::experimental::filesystem;
#endif
int main(int argc, const char*argv[]) {
fs::path probe(argv[0]);
if (argc != 1) throw fs::filesystem_error(std::string("fake"), std::error_code());
return fs::is_directory(probe.relative_path());
}
11:45
Using xcode 13.3 and latest Mac os Monterey
11:53
Link to CmakeError.log - https://ctxt.io/2/AADgIJx_Fg
11:54
Link to CmakeOutput.log - https://ctxt.io/2/AADgJK02FA
Л(
12:16
Леонид Юрьев (Leonid Yuriev)
In reply to this message
There only the C++17
So, you should see the "No support for std::filesystem" status message from CMake.
But this is not a problem nor a reason for libmdbx build failure.
std::filesystem support check and the search for the necessary library were failed, since selected iOS/OSX target version don't support it.So, you should see the "No support for std::filesystem" status message from CMake.
But this is not a problem nor a reason for libmdbx build failure.
13:14
Errors screenshot
MN
13:20
Misha Nikanorov
you can try my SwiftPM wrapper, but it’s outdated, but easy to update (you have to change submodule url since libmdbx not on github anymore, switch to latest release version and ‘sh build.sh’)
https://github.com/Foboz/mdbx-ios
https://github.com/Foboz/mdbx-ios
Л(
13:22
Леонид Юрьев (Leonid Yuriev)
In reply to this message
These a minor warnings from latest Apple-hacked CLANG.
Will fix, maybe today.
Will fix, maybe today.
13:30
Deleted Account
No problem, pls let me know
РЛ
13:47
Руслан Лайшев
Привет!
13:48
Где взять набор что бы он не требовал git ?
13:48
В zip или ещё как ?
13:50
Так, пардон, нашёл.
👍
Л(
Л(
14:43
Deleted Account
Will check right now
Artem Bazhanov invited Artem Bazhanov
Л(
15:13
Леонид Юрьев (Leonid Yuriev)
In reply to this message
I will fix these warnings tomorrow, not now.
It would be nice if you get all warnings using
As a temporary workaround just remove from
It would be nice if you get all warnings using
make -k or similar, and then put log file here.As a temporary workaround just remove from
CMakeList.txt files an addition of the -Werror option.
15:21
Deleted Account
Ok
14 May 2022
igors invited igors
16:15
Deleted Account
In reply to this message
ser there are alternatives, i recommend looking at https://www.talos.dev/
16 May 2022
AB
20:59
Artem Bazhanov
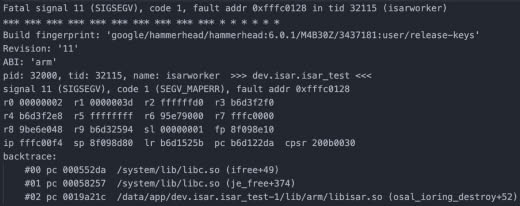
Пытаюсь запустить MDBX под андроид. При вызове mdbx_env_open постоянно получаю EINVAL (22). Значение ANDROID_API проверил, оно корректно. MDBX_DEBUG включен, но в логи ничего не падает. Как можно еще диагностировать проблему? Как правильно интерпретировать лог strace (https://www.dropbox.com/s/p2k1wmsep43rx15/strace.txt?dl=0)?
Л(
21:47
Леонид Юрьев (Leonid Yuriev)
In reply to this message
1.
MDBX_DEBUG > 0 включает ассерты и генерацию более подробных логов.
Но если не установить logger и/или log-level, то вы можете не увидеть желаемого.
см.
2.
Используйте последнюю версию.
До
3.
В логах strace лучше ориентироваться на имя/путь файла БД, а дальше смотреть что происходит следом.
Ваш лог я сильно не исследовал, но (в частности) не увидел там следов открытия
MDBX_DEBUG > 0 включает ассерты и генерацию более подробных логов.
Но если не установить logger и/или log-level, то вы можете не увидеть желаемого.
см.
mdbx_setup_debug() = https://libmdbx.dqdkfa.ru/groupcdebug.html#gae5f003fad215cdd8253ef43b55a02ae02.
Используйте последнюю версию.
До
0.11.7 в коде было определение _FILE_OFFSET_BITS=64 что из-за баго-фичи Android/Bionic приводило к устойчивому EINVAL на 32-битных x86 сборках Андроид (см. https://gitflic.ru/project/erthink/libmdbx/issue/2).3.
В логах strace лучше ориентироваться на имя/путь файла БД, а дальше смотреть что происходит следом.
Ваш лог я сильно не исследовал, но (в частности) не увидел там следов открытия
.lck-файла, т.е. видимо лог совсем не полный.
AB
Л(
22:23
Леонид Юрьев (Leonid Yuriev)
Few fixes for Apple's CLANG 13 is available now in the
master branch.
i
22:24
igors
Я сам проверял все архитектуры поддерживаемые андроидом, и как уже говорил @erthink были только проблемы на x86(воспроизводились на эмуляторе), но все было исправлено. Так что не должно быть никаких проблем на Андроиде.
Л(
i
22:30
igors
I Wii provide later log with all warnings connected with the Apple CLANG, if it make sense yeat. Also, workaround with removing -Werror works.
👍
Л(
17 May 2022
AB
12:54
Artem Bazhanov
In reply to this message
А получилось ли использовать дебаггер в Android Studio в нативном коде? У меня breakpoint-ы упорно игнорируются.
СО
14:02
Станислав Очеретный
Добрый день. Вопрос теоретический для понимания. Большая БД, которая не входит в RAM. Открываем транзакцию на чтения и курсором двигаемся по всей базе, ссылку на первое найденное значение сохраняю в splice (указатель на value), могу ли я рассчитывать, что после прохождения всей базы пока я не закрыл транзакцию splice-ссылка на данные не инвалидируются ?
i
Л(
14:09
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Да, но будет подкачки с диска, в том числе при чтении значений после обхода БД.
i
20:44
igors
https://ctxt.io/2/AABgezRjFg - here is the list of all warning, which we have on a latest master
18 May 2022
Л(
12:58
Леонид Юрьев (Leonid Yuriev)
@AskAlexSharov и @vorot93, обратите внимание.
С конца апреля доступна бета memtest 9.5 с новой фичей: "Added new experimental memory test as Test 14 [DMA test]. This test exercises the disk controller's DMA hardware to perform memory access, bypassing the CPU. The motivation for this test came from discovering a defective RAM module that did not produce errors when accessed via the CPU, but failed when files were read from disk via DMA."
В подробности я не вникал, но если верить написанному, то этот новый тест действительно может выявлять специфические проблемы из-за которых может происходить неожиданное повреждение БД.
Особенно у любителей XMP и поразгонять память.
Поэтому при подозрениях обязательно отравляйте в сторону memtest86 >= v9.5
https://forums.passmark.com/memtest86/52671-memtest86-v9-5-beta-1-release
С конца апреля доступна бета memtest 9.5 с новой фичей: "Added new experimental memory test as Test 14 [DMA test]. This test exercises the disk controller's DMA hardware to perform memory access, bypassing the CPU. The motivation for this test came from discovering a defective RAM module that did not produce errors when accessed via the CPU, but failed when files were read from disk via DMA."
В подробности я не вникал, но если верить написанному, то этот новый тест действительно может выявлять специфические проблемы из-за которых может происходить неожиданное повреждение БД.
Особенно у любителей XMP и поразгонять память.
Поэтому при подозрениях обязательно отравляйте в сторону memtest86 >= v9.5
https://forums.passmark.com/memtest86/52671-memtest86-v9-5-beta-1-release
🔥
AV
AS
12:59
Alex Sharov
спс
SC
13:18
Simon C.
Hey, is there an api to calculate the size of a database in bytes?
AS
13:30
Alex Sharov
There are stat methods for db and for sub-db and for current transaction
SC
13:35
Simon C.
Would
(ms_branch_pages + ms_leaf_pages) * ms_psize be the size of the database?
AS
13:48
Alex Sharov
Oferflow pages also
❤
SC
РЛ
16:15
Руслан Лайшев
Добрый день!
MDBX_MAP_FULL - коллеги, какой алгоритм действий при таком сообщении ?
MDBX_MAP_FULL - коллеги, какой алгоритм действий при таком сообщении ?
16:29
При mdbx_put().
Памяти добавить или что-то ещё? Каковы первоочередные рекомендации ?
Памяти добавить или что-то ещё? Каковы первоочередные рекомендации ?
b
Л(
16:41
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Во-первых вам нужно понять, ожидаемое ли это поведение или нет.
Если "ожидаемое", т.е. вы понимаете что БД действительно мала для ваших данных - то задать больший размер, как вариант геометрию с шагом приращения и некоторым предельным верхним размером.
Иначе, если по вашим оценкам и/или понимаю, заданного размера БД должно хватать для ваших данных, а они не влезают, то разбираться в причинах: смотреть статистку по БД (посредством
Если "ожидаемое", т.е. вы понимаете что БД действительно мала для ваших данных - то задать больший размер, как вариант геометрию с шагом приращения и некоторым предельным верхним размером.
Иначе, если по вашим оценкам и/или понимаю, заданного размера БД должно хватать для ваших данных, а они не влезают, то разбираться в причинах: смотреть статистку по БД (посредством
mdbx_stat), проверять БД (посредством mdbx_chk) и выяснять что пошло не так...
👍
РЛ
РЛ
16:45
Руслан Лайшев
Принял. Спасибо!
19 May 2022
i
11:24
igors
Всем добрый день, есть у меня одна проблема связанная с статичской ибилиотекой.
11:25
1. Собираю статичскую либо используя ios cmake - cmake .. -G Xcode -DCMAKE_TOOLCHAIN_FILE=../ios.toolchain.cmake -DPLATFORM=SIMULATOR64 -DMDBX_INSTALL_STATIC=ON -DMDBX_BUILD_SHARED_LIBRARY=OFF
11:26
2. После этого линкую в проект(сразу скажу что использую xamarin.ios)
11:28
и при вызове функции например - mdbx_default_pagesize, вылетает исключение System.EntryPointNotFoundException
11:32
запустил комманду nm для mdbx.a и нахожу там функцию мою функцию
11:34
0001112c T _mdbx_default_pagesize с буквой T(uppercase)
11:35
потом запускаю nm для исполниемого файла куда либа залинковалась - и там уже эта функция с маленькой буквой t
11:35
0001120a t _mdbx_default_pagesize
11:37
посканил инет и нашел там вот это - https://github.com/xamarin/xamarin-macios/issues/12515
11:38
The dynamic lookup that is used (default for p/invoke and JIT) cannot look it up.
It's (of course) the same for Xcode but since it's not a lookup, but for ObjC it's just a call inside the same binary (no lookup), then it works fine.
It's (of course) the same for Xcode but since it's not a lookup, but for ObjC it's just a call inside the same binary (no lookup), then it works fine.
11:38
It appears you need to rebuild possibly with a new define to get libcurl working here.
11:40
потом ради эксперимента взял пример проект из ios-cmake(https://github.com/leetal/ios-cmake)
11:40
там есть пример с библиотекой
11:41
и с CMakeLists.txt
11:42
собрал там статическую либу, прилинковал - работает
11:43
вот здесь тоже обсуждается проблема неправильной сборки - https://bugzilla.xamarin.com/36/3651/bug.html
11:44
это лог
11:46
@erthink может в CMakeLists.txt есть какие то проблемы при сборке статики для ios?
11:49
P.S. По поводу удаление -WError, мне чтобы собрать пришлось подправить не только CMakeLists.txt. Также поправил compiler.cmake and GNUmakefile
Л(
14:00
In reply to this message
В libmdbx сборка правильная, в том числе абсолютно корректно в статической библиотеки символы (имена функций) определяются как приватные для DSO (не экспортируемые из DLL).
Причина проблемы в том, что для JIT и всех динамических языков/runtime нужны экспортируемые символы.
Т.е. для xamarin по-определению требуется динамическая библиотека, а не статическая.
Причина проблемы в том, что для JIT и всех динамических языков/runtime нужны экспортируемые символы.
Т.е. для xamarin по-определению требуется динамическая библиотека, а не статическая.
Л(
14:18
Леонид Юрьев (Leonid Yuriev)
igors, Собирать статическую библиотеку с видимыми вне DSO/DLL возможно, но не совсем корректно.
Грубо говоря, тут случай "трусы/крестик".
При желании вы можете при сборке libmdbx самостоятельно определить
Технически при этом вы соберете статическую библиотеку, с использованием которой затем где-то соберете DSO с экспортируемыми символами.
Но я НЕ СОВЕТУЮ этого делать по двум причинам:
- вы можете ненамеренно получить несколько копий кода libmdbx в вашем приложении;
- вы можете получить серьезные проблемы из-за Thread Local Storage destructors и вечный https://ru.wikipedia.org/wiki/Гейзенбаг;
- чтобы не наломать дров Вам нужно (как минимум) хорошо разбираться в вопросах видимости символов для DSO, в работе Thread Local Storage и работе TLS-деструкторов, в томи числе при использовании DSO/DLL (загрузки/выгрузки).
- при использовании xamarin с libmdbx в виде динамической библиотеке всё должно просто работать и вы можете рассчитывать на поддержку), а в остальных случаях придется разбираться самостоятельно.
Короче, не ешьте с ножа ;)
Грубо говоря, тут случай "трусы/крестик".
При желании вы можете при сборке libmdbx самостоятельно определить
LIBMDBX_EXPORTS и получить желаемый эффект.Технически при этом вы соберете статическую библиотеку, с использованием которой затем где-то соберете DSO с экспортируемыми символами.
Но я НЕ СОВЕТУЮ этого делать по двум причинам:
- вы можете ненамеренно получить несколько копий кода libmdbx в вашем приложении;
- вы можете получить серьезные проблемы из-за Thread Local Storage destructors и вечный https://ru.wikipedia.org/wiki/Гейзенбаг;
- чтобы не наломать дров Вам нужно (как минимум) хорошо разбираться в вопросах видимости символов для DSO, в работе Thread Local Storage и работе TLS-деструкторов, в томи числе при использовании DSO/DLL (загрузки/выгрузки).
- при использовании xamarin с libmdbx в виде динамической библиотеке всё должно просто работать и вы можете рассчитывать на поддержку), а в остальных случаях придется разбираться самостоятельно.
Короче, не ешьте с ножа ;)
👍
i
FK
i
23:27
igors
Ok, спасибо
21 May 2022
Даниил Терляхин invited Даниил Терляхин
23 May 2022
РЛ
12:40
Руслан Лайшев
Добрый день, коллеги!
Сёдня на убунту 20.04 (если это важно), поймалось вот так:
Сёдня на убунту 20.04 (если это важно), поймалось вот так:
Устанавливаем max_dbs = 1024
mdbx_dbi_open: (-30791) MDBX_DBS_FULL: Too many DBI-handles (maxdbs reached)
Подскажите, плиз, что проверить ?
Л(
12:48
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Так а сколько dbi-хендлов вы открываете?
Или другими словами - сколько разноименных subDb у вас создается за время работы приложения?
Или другими словами - сколько разноименных subDb у вас создается за время работы приложения?
РЛ
12:50
Руслан Лайшев
Открытия ещё не было.
12:51
Но обычно кол-во subDB несколько десятков, но точно даже не сотня.
Л(
12:52
Леонид Юрьев (Leonid Yuriev)
А установка
max_dbs = 1024 выполняется до открытия БД и результат этой операции MDBX_SUCCESS ?
РЛ
13:02
Руслан Лайшев
if ( MDBX_SUCCESS != (l_rc = mdbx_env_create(&s_mdbx_env)) )
return log_it(L_CRITICAL, "mdbx_env_create: (%d) %s", l_rc, mdbx_strerror(l_rc)), -ENOENT;
log_it(L_NOTICE, "Set maximum number of local groups: %d", DAP_DB$K_MAXGROUPS);
assert ( !mdbx_env_set_maxdbs (s_mdbx_env, DAP_DB$K_MAXGROUPS) ); /* Set maximum number of the file-tables (MDBX subDB)
according to number of supported groups */
/* We set "unlim" for all MDBX characteristics at the moment */
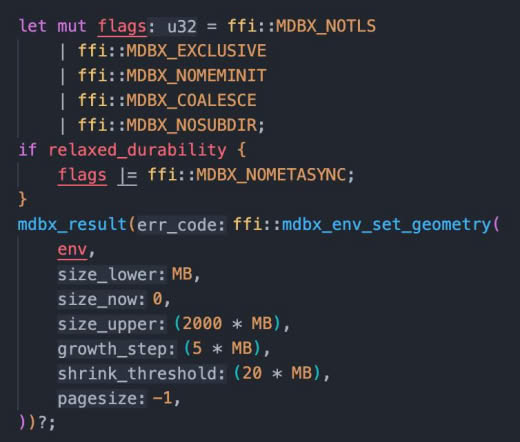
if ( MDBX_SUCCESS != (l_rc = mdbx_env_set_geometry(s_mdbx_env, -1, -1, l_upper_limit_of_db_size, -1, -1, -1)) )
return log_it (L_CRITICAL, "mdbx_env_set_geometry (%s): (%d) %s", s_db_path, l_rc, mdbx_strerror(l_rc)), -EINVAL;
if ( MDBX_SUCCESS != (l_rc = mdbx_env_open(s_mdbx_env, s_db_path, MDBX_CREATE | MDBX_COALESCE | MDBX_LIFORECLAIM, 0664)) )
return log_it (L_CRITICAL, "mdbx_env_open (%s): (%d) %s", s_db_path, l_rc, mdbx_strerror(l_rc)), -EINVAL;
Л(
13:28
Леонид Юрьев (Leonid Yuriev)
Тогда что-то странное, надо смотреть/разбираться.
Варианта примерно три:
0) Добавить явное логирование в
1) Под gdb поставить точку останова внутри кода libmdbx на возврат
2) Дать мне код со сценарием воспроизведения.
Варианта примерно три:
0) Добавить явное логирование в
mdbx_dbi_open() и/или mdbx_dbi_open_ex() чтобы видеть сколько dbi-хендлов открывается и с какими значениями.1) Под gdb поставить точку останова внутри кода libmdbx на возврат
MDBX_DBS_FULL (всего два таких места, оба в функции db_open()), а после поковыряться самостоятельно или показать мне содержание кадров стека и основных объектов (env, txn).2) Дать мне код со сценарием воспроизведения.
РЛ
i
17:38
igors
In reply to this message
к сожалению там появились еще ошибки, я тут сам подправил и проверил чтобы все собралось успешно
17:40
могу сделать ветку и пр
17:40
если так будет проще
Л(
21:06
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Пожалуйста не отправляйте скриншоты, а запустите
При затруднениях установите bash и gmake посредством brew.
make --keep-going &>log.txt, а потом приложите log.txt к сообщению здесь.При затруднениях установите bash и gmake посредством brew.
21:09
In reply to this message
Предположительно там простые предупреждения, из-за слишком бдительного отношения Apple' CLANG к конвертации 64-битных значений в 32-битные.
Если вы в состоянии сделать и предложить правки - welcome, но протокол с ошибками/предупреждениями мне всё равно потребуется (для уверенности что в предупреждениях нет реальных проблем).
Если вы в состоянии сделать и предложить правки - welcome, но протокол с ошибками/предупреждениями мне всё равно потребуется (для уверенности что в предупреждениях нет реальных проблем).
i
22:31
igors
нет прав чтобы файл приложить в группу
22:32
смотрите когда я собираю для macos(make all) - то нет никаких ошибок
22:33
ошибки появлбтся только когда использую cmake with toolchain file длч сборки под ios
22:34
вот содержимое файла log.txt
22:34
// The GNU Make 3.81
// TIP: Use
// TIP: Clone and build the https://github.com/pmwkaa/ioarena.git within a neighbouring directory for availability of benchmarking.
MDBX_BUILD_OPTIONS = -DNDEBUG=1
MDBX_BUILD_TIMESTAMP = 2022-05-23T22:26:05+0300
// TIP: Use
CC =/usr/bin/cc | Apple clang version 13.1.6 (clang-1316.0.21.2)
CFLAGS =-std=gnu11 -O2 -g -Wall -Werror -Wextra -Wpedantic -ffunction-sections -fPIC -fvisibility=hidden -pthread -Wno-error=attributes -fno-semantic-interposition -Wno-unused-command-line-argument -Wno-tautological-compare
CXXFLAGS =-std=gnu++2b -O2 -g -Wall -Werror -Wextra -Wpedantic -ffunction-sections -fPIC -fvisibility=hidden -pthread -Wno-error=attributes -fno-semantic-interposition -Wno-unused-command-line-argument -Wno-tautological-compare
LDFLAGS = -lm -pthread
// TIP: Use
CLEAN for build with specified flags... Ok
MAKE src/version.c
MAKE src/config.h
CC mdbx-static.o
CC mdbx++-static.o
AR libmdbx.a
CC mdbx-dylib.o
CC mdbx++-dylib.o
LD libmdbx.dylib
CC+LD mdbx_stat
CC+LD mdbx_copy
CC+LD mdbx_dump
CC+LD mdbx_load
CC+LD mdbx_chk
CC+LD mdbx_drop
// TIP: Use
make V=1 for verbose.// TIP: Clone and build the https://github.com/pmwkaa/ioarena.git within a neighbouring directory for availability of benchmarking.
MDBX_BUILD_OPTIONS = -DNDEBUG=1
MDBX_BUILD_TIMESTAMP = 2022-05-23T22:26:05+0300
// TIP: Use
make options to listing available build options.CC =/usr/bin/cc | Apple clang version 13.1.6 (clang-1316.0.21.2)
CFLAGS =-std=gnu11 -O2 -g -Wall -Werror -Wextra -Wpedantic -ffunction-sections -fPIC -fvisibility=hidden -pthread -Wno-error=attributes -fno-semantic-interposition -Wno-unused-command-line-argument -Wno-tautological-compare
CXXFLAGS =-std=gnu++2b -O2 -g -Wall -Werror -Wextra -Wpedantic -ffunction-sections -fPIC -fvisibility=hidden -pthread -Wno-error=attributes -fno-semantic-interposition -Wno-unused-command-line-argument -Wno-tautological-compare
LDFLAGS = -lm -pthread
// TIP: Use
make help to listing available targets.CLEAN for build with specified flags... Ok
MAKE src/version.c
MAKE src/config.h
CC mdbx-static.o
CC mdbx++-static.o
AR libmdbx.a
CC mdbx-dylib.o
CC mdbx++-dylib.o
LD libmdbx.dylib
CC+LD mdbx_stat
CC+LD mdbx_copy
CC+LD mdbx_dump
CC+LD mdbx_load
CC+LD mdbx_chk
CC+LD mdbx_drop
i
23:11
igors
в итоге если для генерации makefiles для ios я использую cmake - cmake -G Xcode -DCMAKE_TOOLCHAIN_FILE=ios.toolchain.cmake -DPLATFORM=SIMULATOR64 -DDEPLOYMENT_TARGET=9.0
а потом для билда вызываю
а потом для билда вызываю
make - то нет никаких ошибок.
23:13
если же билд запускать через - cmake --build --config Release, то появляются ошибки
24 May 2022
i
00:29
igors
я просмотрел ios.toolchain.cmake файл и получатся что -G Xcode(генерирует xcode project) нужен только в случае генерации FAT файла, и если без него то все билдится без ошибок
Л(
00:56
In reply to this message
Тогда просьба приложить лог сборки с опцией
Примерно так:
-k из-под cmake.Примерно так:
cmake -build . -- -k &> log.txt
00:58
При использовании ninja лучше так:
ninja -j 1 -k 0 &>log.txt
i
00:58
igors
пробовал так
Л(
01:02
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Имеется в виду, что сначала вы конфигурируете сборку посредством CMake с toolchain-файлом, а затем затем запускаете сборщик (make или ninja) с перенаправлением логов в файл.
i
01:02
igors
да
Л(
01:08
Леонид Юрьев (Leonid Yuriev)
Что-то я совсем ничего не понял, в логе нет ошибок.
Вы перенаправляли вывод посредством
Вы перенаправляли вывод посредством
&>log.txt или как-то иначе?
01:08
На маке по-умолчанию какой-то старый bash, но вроде-бы он понимает
&>.
i
01:08
igors
да нет файла то у меня создался
Л(
01:09
Леонид Юрьев (Leonid Yuriev)
пишите с запятыми, pls
i
01:15
igors
магия в том что я не использовал -G XCode, когда делал мейк файлы - и тогда все собирается без ошибок. Сейчас скину log.txt файл где в cmake использовал -G XCode(создать xcodeproj), и потом запускаю - cmake --build . -- -k &> log.txt(сбилдать xcodeproj). И вот что в логе:
01:20
в варианте с -G XCode мы создаем xcodeproj и потом его билдим, ну такие были примеры в ioc-cmake на гитхабе(https://github.com/leetal/ios-cmake), хотя потом выяснилось что -G XCode нужен только для fat файлов
Л(
01:25
Леонид Юрьев (Leonid Yuriev)
Тут проблема в том, что у XCode нет аналога опции
Поэтому, видимо, самый простой способ = убрать
Так должны остаться все предупреждения, но сборка не должна останавливаться из-за ошибок.
--keep-going при сборке.Поэтому, видимо, самый простой способ = убрать
-Werror из опций (как вы делали раньше) и собрать с перенаправлением в файл.Так должны остаться все предупреждения, но сборка не должна останавливаться из-за ошибок.
i
01:30
igors
ok, завтра кину лог
i
Л(
12:50
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Поправил.
Там было два минорных предупреждения наведенных предыдущей правкой предупреждений...
Но в целом набор флагов/опций компилятора достаточно странный, выключена масса предупреждений, но явно включено
Там было два минорных предупреждения наведенных предыдущей правкой предупреждений...
Но в целом набор флагов/опций компилятора достаточно странный, выключена масса предупреждений, но явно включено
-Wshorten-64-to-32.
12:52
Эти предупреждения останутся, это какие-то проблемы в toolchain с TLS-переменными (aka
__thread).warning: (x86_64) failed to insert symbol '__ZZ13test_strerroriE3buf' in the debug map.
warning: (x86_64) failed to insert symbol '__ZL10prng_state' in the debug map.
i
13:39
igors
ok
13:51
проверил, все работает, спасибо за помощь
👍
Л(
30 May 2022
Aleks Raiden | Fintech R&D invited Aleks Raiden | Fintech R&D
3 June 2022
PJ
17:55
Peter Johnson
Hi all, I have a database file created with MDBX_NOSUBDIR, when trying to read the database on a read-only filesystem I'm getting a runtime error.
Converting the volume to read-write resolves the issue, I believe this is due to MDBX trying to create a
I've tried to disable lock generation using MDBX_EXCLUSIVE but wasn't able to resolve the issue.
Is there any way I can open a database read-only against a read-only volume without getting these lockfile creation errors?
Converting the volume to read-write resolves the issue, I believe this is due to MDBX trying to create a
-lck file on the read-only volume.I've tried to disable lock generation using MDBX_EXCLUSIVE but wasn't able to resolve the issue.
Is there any way I can open a database read-only against a read-only volume without getting these lockfile creation errors?
17:57
I'm using the GO wrapper
github.com/torquem-ch/mdbx-go/mdbx which produces the following error:
fatal error: unexpected signal during runtime execution
[signal SIGSEGV: segmentation violation code=0x1 addr=0x20 pc=0x40d27f]
horizon_osm |
runtime stack:
runtime.throw({0xceb4c8?, 0x7f75d2007a16?})
/usr/lib/go/src/runtime/panic.go:992 +0x71
runtime.sigpanic()
/usr/lib/go/src/runtime/signal_unix.go:802 +0x3a9
horizon_osm |
goroutine 1 [syscall]:
runtime.cgocall(0xa7bc50, 0xc0000f9bb8)
/usr/lib/go/src/runtime/cgocall.go:157 +0x5c fp=0xc0000f9b90 sp=0xc0000f9b58 pc=0x4293fc
github.com/torquem-ch/mdbx-go/mdbx._Cfunc_mdbx_env_open(0x7f75d207e8c0, 0x7f75d207a910, 0x2a24000, 0x124)
_cgo_gotypes.go:708 +0x4c fp=0xc0000f9bb8 sp=0xc0000f9b90 pc=0x5a2bec
github.com/torquem-ch/mdbx-go/mdbx.(*Env).Open.func2(0x7f75d207a910?, 0
x20?, 0x2824000, 0x0?)
/go/pkg/mod/github.com/torquem-ch/mdbx-go@v0.23.2/mdbx/env.go:153 +0x74 fp=0xc0000f9c00 sp=0xc0000f9bb8 pc=0x5a7534
github.com/torquem-ch/mdbx-go/mdbx.(*Env).Open(0x497e46?, {0x7fff6849ae8d?, 0x0?}, 0x0?, 0x80?)
Л(
18:06
Леонид Юрьев (Leonid Yuriev)
In reply to this message
You should used
However, this mode has not been tested for a long time, so I wouldn't be surprised if something doesn't work.
In this case, I will probably be able to make a fix tomorrow.
MDBX_EXCLUSIVE | MDBX_RDONLY to open DB on a read-only media/volume.However, this mode has not been tested for a long time, so I wouldn't be surprised if something doesn't work.
In this case, I will probably be able to make a fix tomorrow.
4 June 2022
Л(
02:33
Леонид Юрьев (Leonid Yuriev)
In reply to this message
I checked the mode of operation when a DB placed in a read-only file system.
There was one simple bug that was added at the end of last year.
It is now fixed in the
In addition:
- the ability to open the database in exclusive readonly mode without write permissions to files has been added;
- and the problem of checking the locality of the file system for CD ROM in Windows has also been solved.
Presumably tomorrow I will test the changes again and merge ones to the master branch.
There was one simple bug that was added at the end of last year.
It is now fixed in the
devel branch = https://gitflic.ru/project/erthink/libmdbx/commit/e795fe7c3ee093e1188095d9006aa707001ff174In addition:
- the ability to open the database in exclusive readonly mode without write permissions to files has been added;
- and the problem of checking the locality of the file system for CD ROM in Windows has also been solved.
Presumably tomorrow I will test the changes again and merge ones to the master branch.
PJ
16:40
Peter Johnson
Awesome thanks 🙏
5 June 2022
Л(
03:31
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Please confirm success or report a problem otherwise.
For now we have a release candidate for v0.11.8.
So I prefer have an ack for every fix or significant change.
For now we have a release candidate for v0.11.8.
So I prefer have an ack for every fix or significant change.
19:59
Deleted Account
What is the extension of the file created by the database?
Л(
6 June 2022
01:08
i.e mdbx.dat
Л(
01:13
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Yes, but with
MDBX_NOSUBDIR option the name of a DB-file is arbitrary (defined by application code).
01:15
Deleted Account
i.e it will be {name}.dat??
Л(
PJ
16:26
Peter Johnson
In reply to this message
Unfortunately I have applied the patch but I am still seeing the error.
Note that I'm using the Go bindings, so it might pay for someone familiar with the C code to write a test in C.
My testing method is:
1. Create a temp directory with read-write permissions
2. Create a new MDBX database at
3. Create a DBI and write something to it
4. Close the environment
5. Chmod the directory to 0444
6. Open the database at
7.
Note that I'm using the Go bindings, so it might pay for someone familiar with the C code to write a test in C.
My testing method is:
1. Create a temp directory with read-write permissions
$TMP_DIR2. Create a new MDBX database at
$TMP_DIR/my.db with the flag NoSubdir3. Create a DBI and write something to it
4. Close the environment
5. Chmod the directory to 0444
6. Open the database at
$TMP_DIR/my.db with the flags NoSubdir|Exclusive|Readonly7.
panic: mdbx_env_open: permission denied
Л(
16:29
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Please firstly make a simple check:
- clone the https://gitflic.ru/project/erthink/libmdbx.git
- chdir inside
- just run
- then run
- clone the https://gitflic.ru/project/erthink/libmdbx.git
- chdir inside
- just run
make- then run
./mdbx_chk -v path-to-your-db.
PJ
16:31
Peter Johnson
/code/mi/play/mdbx-bug/libmdbx devel ❯ ./mdbx_chk /var/folders/5w/xzyyzb490m36my2j2w4094_m0000gn/T/mdbx3164665739/my.db
mdbx_chk v0.11.7-50-g77f56541 (2022-06-04T02:08:24+03:00, T-c1bcf1b3ab87e8b856175c4bb9ad5d2a5778aad7)
Running for /var/folders/5w/xzyyzb490m36my2j2w4094_m0000gn/T/mdbx3164665739/my.db in 'read-only' mode...
! mdbx_env_open() failed, error 13 Permission denied
16:32
/code/mi/play/mdbx-bug/libmdbx devel ❯ chmod 777 /var/folders/5w/xzyyzb490m36my2j2w4094_m0000gn/T/mdbx3164665739/
/code/mi/play/mdbx-bug/libmdbx devel ❯ ./mdbx_chk /var/folders/5w/xzyyzb490m36my2j2w4094_m0000gn/T/mdbx3164665739/my.db
mdbx_chk v0.11.7-50-g77f56541 (2022-06-04T02:08:24+03:00, T-c1bcf1b3ab87e8b856175c4bb9ad5d2a5778aad7)
Running for /var/folders/5w/xzyyzb490m36my2j2w4094_m0000gn/T/mdbx3164665739/my.db in 'read-only' mode...
Traversal b-tree by txn#4...
Iterating DBIs...
No error is detected, elapsed 0.006 seconds
Л(
16:37
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Very strange, I will check again more carefully.
PJ
16:39
Peter Johnson
👍 🙏
Л(
21:55
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Oh, I guess the problem.
There are some limitations of without-LCK mode (aka exclusive read-only).
For now you should manually remove the LCK-file or place both DB files (*.dat and *.lck) to a read-only filesystem.
Technically this limitation conditioned by compatibility with old versions with a guarantee of reading valid data.
I need to think about whether such limitation can be safely removed or relaxed without creating risks.
There are some limitations of without-LCK mode (aka exclusive read-only).
For now you should manually remove the LCK-file or place both DB files (*.dat and *.lck) to a read-only filesystem.
Technically this limitation conditioned by compatibility with old versions with a guarantee of reading valid data.
I need to think about whether such limitation can be safely removed or relaxed without creating risks.
PJ
22:41
Peter Johnson
hmmm.. so I have both files in the directory, after playing with it some more I have discovered that setting the
executable bit for the owner (and only the owner) resolves the issue:
/code/mi/pla/mdbx-bug/libmdbx devel ❯ chmod 444 /var/folders/5w/xzyyzb490m36my2j2w4094_m0000gn/T/mdbx3164665739/
/code/mi/play/mdbx-bug/libmdbx devel ❯ ./mdbx_chk -v /var/folders/5w/xzyyzb490m36my2j2w4094_m0000gn/T/mdbx3164665739/my.db
mdbx_chk v0.11.7-50-g77f56541 (2022-06-04T02:08:24+03:00, T-c1bcf1b3ab87e8b856175c4bb9ad5d2a5778aad7)
Running for /var/folders/5w/xzyyzb490m36my2j2w4094_m0000gn/T/mdbx3164665739/my.db in 'read-only' mode...
! mdbx_env_open() failed, error 13 Permission denied
/code/mi/play/mdbx-bug/libmdbx devel ❯ chmod 544 /var/folders/5w/xzyyzb490m36my2j2w4094_m0000gn/T/mdbx3164665739/
/code/mi/play/mdbx-bug/libmdbx devel ❯ ./mdbx_chk -v /var/folders/5w/xzyyzb490m36my2j2w4094_m0000gn/T/mdbx3164665739/my.db
mdbx_chk v0.11.7-50-g77f56541 (2022-06-04T02:08:24+03:00, T-c1bcf1b3ab87e8b856175c4bb9ad5d2a5778aad7)
Running for /var/folders/5w/xzyyzb490m36my2j2w4094_m0000gn/T/mdbx3164665739/my.db in 'read-only' mode...
- monopolistic mode
- current boot-id b914b4228e6fc859-3142ec2a5ee24d50
- pagesize 4096 (4096 system), max keysize 1980..2022, max readers 116
- mapsize 1073741824 (1.00 Gb)
- dynamic datafile: 12288 (12.00 Kb) .. 1073741824 (1.00 Gb), +536870912 (512.00 Mb), -1073741824 (1.00 Gb)
- current datafile: 536870912 (512.00 Mb), 131072 pages
- meta-0: steady txn#4, head
- meta-1: steady txn#2, tail
- meta-2: steady txn#3, stay
- transactions: recent 4, latter reader 4, lag 0
Traversal b-tree by txn#4...
- found 'example' area
- pages: walked 5, left/unused 0
- summary: average fill 4.0%, 0 problems
Processing '@MAIN'...
- key-value kind: usual-key => single-value
- last modification txn#4
- summary: 1 records, 0 dups, 7 key's bytes, 48 data's bytes, 0 problems
Processing '@GC'...
- key-value kind: ordinal-key => single-value
- summary: 0 records, 0 dups, 0 key's bytes, 0 data's bytes, 0 problems
- space: 262144 total pages, backed 131072 (50.0%), allocated 5 (0.0%), available 262139 (100.0%)
Processing 'example'...
- key-value kind: usual-key => single-value
- last modification txn#4
- summary: 1 records, 0 dups, 5 key's bytes, 5 data's bytes, 0 problems
No error is detected, elapsed 0.004 seconds
22:42
Note tthat
454 and 445 don't work but 544 does 🤷
22:45
deleteing the lock file manually and using
444 doesn't work:
/code/mi/play/mdbx-bug/libmdbx devel ❯ chmod 444 /var/folders/5w/xzyyzb490m36my2j2w4094_m0000gn/T/mdbx3164665739/
/code/mi/play/mdbx-bug/libmdbx devel ❯ sudo rm /var/folders/5w/xzyyzb490m36my2j2w4094_m0000gn/T/mdbx3164665739/my.db-lck
/code/mi/play/mdbx-bug/libmdbx devel ❯ ./mdbx_chk -v /var/folders/5w/xzyyzb490m36my2j2w4094_m0000gn/T/mdbx3164665739/my.db
mdbx_chk v0.11.7-50-g77f56541 (2022-06-04T02:08:24+03:00, T-c1bcf1b3ab87e8b856175c4bb9ad5d2a5778aad7)
Running for /var/folders/5w/xzyyzb490m36my2j2w4094_m0000gn/T/mdbx3164665739/my.db in 'read-only' mode...
! mdbx_env_open() failed, error 13 Permission denied
22:53
note, I'm on MacOS, and I noticed something odd I haven't seen in *nix environments, which may or may not be related:
mkdir -p /tmp/example
touch /tmp/example/file
ls -lah /tmp/example/
total 0
drwxr-xr-x 3 peter wheel 96 Jun 6 21:51 .
drwxrwxrwt 53 root wheel 1.7K Jun 6 21:51 ..
-rw-r--r-- 1 peter wheel 0 Jun 6 21:51 file
chmod 444 /tmp/example
ls -lah /tmp/example/
ls: cannot access '/tmp/example/.': Permission denied
ls: cannot access '/tmp/example/..': Permission denied
ls: cannot access '/tmp/example/file': Permission denied
total 0
d????????? ? ? ? ? ? .
d????????? ? ? ? ? ? ..
-????????? ? ? ? ? ? file
22:54
I assume this is unrelated because I first notcied this MDBX issue on an Ubuntu machine
23:00
agh no, sorry, this is the same behaviour on Ubuntu, sorry for the noise:
ubuntu@hetzner:~$ mkdir -p /tmp/example
ubuntu@hetzner:~$ touch /tmp/example/file
ubuntu@hetzner:~$ ls -lah /tmp/example/
total 20K
drwxrwxr-x 2 ubuntu ubuntu 4.0K Jun 6 21:59 .
drwxrwxrwt 17 root root 16K Jun 6 21:59 ..
-rw-rw-r-- 1 ubuntu ubuntu 0 Jun 6 21:59 file
ubuntu@hetzner:~$ chmod 444 /tmp/example
ubuntu@hetzner:~$ ls -lah /tmp/example/
ls: cannot access '/tmp/example/..': Permission denied
ls: cannot access '/tmp/example/.': Permission denied
ls: cannot access '/tmp/example/file': Permission denied
total 0
d????????? ? ? ? ? ? .
d????????? ? ? ? ? ? ..
-????????? ? ? ? ? ? file
7 June 2022
Л(
13:18
Леонид Юрьев (Leonid Yuriev)
In reply to this message
The LCK-file is created automatically when actual permissions to the directory are allows this.
The permissions for created LCK-file are:
- owner: read+write (the uid of current process);
- group: inherited read of DATA-file and enable write if such read is allowed;
- others: inherited read of DATA-file and enable write if such read is allowed.
So a very large number of behavior scenarios are possible, depending on the access rights to the directory, the DAT-file, their owners, the uid/gid of the current process and the presence of the LCK-file.
---
It is important what you want in the end: just to solve your problem, or to understand what MDBX does and/or what is happening.
The permissions for created LCK-file are:
- owner: read+write (the uid of current process);
- group: inherited read of DATA-file and enable write if such read is allowed;
- others: inherited read of DATA-file and enable write if such read is allowed.
So a very large number of behavior scenarios are possible, depending on the access rights to the directory, the DAT-file, their owners, the uid/gid of the current process and the presence of the LCK-file.
---
It is important what you want in the end: just to solve your problem, or to understand what MDBX does and/or what is happening.
Л(
14:50
Леонид Юрьев (Leonid Yuriev)
Call for testing v0.11.8
RU: В ветке
EN: The release candidate for now is ready in the
https://gitflic.ru/project/erthink/libmdbx/blob?file=ChangeLog.md
RU: В ветке
master подготовлен кандидат в релизы, который намечен на 12 число. Просьба по-возможности по-тестировать.EN: The release candidate for now is ready in the
master branch. Please test it. https://gitflic.ru/project/erthink/libmdbx/blob?file=ChangeLog.md
8 June 2022
СО
20:32
Станислав Очеретный
@erthink Добрый вечер. Я использую версию 0.10.2.0 под Windows. У меня есть рабочий дамп базы 2Гб в которой несколько sudb, одна из subdb занимает 90% базы. В сценарии удаление все информации subdb, добавление информации в subdb удалось положить базу с ошибкой MDBX_CORRUPTED в функции
static int mdbx_update_gc(MDBX_txn *txn) {
if (unlikely(rc != MDBX_SUCCESS ||
key.iov_len != sizeof(mdbx_tid_t))) {
>> rc = MDBX_CORRUPTED;
goto bailout;
}
Теперь при любой записи в эту базу возвращается ошибка MDBX_CORRUPTED
static int mdbx_update_gc(MDBX_txn *txn) {
if (unlikely(rc != MDBX_SUCCESS ||
key.iov_len != sizeof(mdbx_tid_t))) {
>> rc = MDBX_CORRUPTED;
goto bailout;
}
Теперь при любой записи в эту базу возвращается ошибка MDBX_CORRUPTED
20:33
Для меня это не критично, хотелось бы понять:
Почему утилиты командной строки mdbx_chk.exe не видят ошибки
Почему утилиты командной строки mdbx_chk.exe не видят ошибки
20:37
Завтра если успею попробую на последней версии воспроизвести, ошибку. К сожалению, буду в отъезде на неделю
Л(
20:40
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Внезапно вы нашли опечатку в коде, которая "ломает" БД в крайне редко выполняющейся ветке кода и только когда размер внутреннего типа идентификации тредов не равен 8.
База целая, опечатку я сейчас исправлю.
База целая, опечатку я сейчас исправлю.
20:41
Сообщение с логом проверки я удалил за не надобностью.
СО
20:42
Станислав Очеретный
Тогда второй вопрос теоретический. Какой алгоритм восстановления
20:43
битой базы, прогонять через утилиту dump/load?
Л(
20:43
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Я же сразу написал, что БД целая восстанавливать ничего не надо.
Однако, потребуется перейти на новую версию, либо вручную применить патч к вашей локальной версии.
Однако, потребуется перейти на новую версию, либо вручную применить патч к вашей локальной версии.
СО
20:44
Станислав Очеретный
Про базу я понял, что она целая. Если "вдруг" база будет битая по каким либо другим причинам. Какой правильный алгоритм ее восстановления
Л(
20:47
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Это принципиально зависит от причин повреждения, и (соответственно) от того что именно поломалось.
В худшем случае восстановление примерно не возможно.
В лучшем случае dump + restore с опциями.
В худшем случае восстановление примерно не возможно.
В лучшем случае dump + restore с опциями.
СО
20:49
Станислав Очеретный
ок. Спасибо за информацию.
Л(
21:05
Леонид Юрьев (Leonid Yuriev)
СО
21:07
Станислав Очеретный
Сейчас проверю на таком же сценарии
👍
Л(
21:18
Все работает, база не ломается. Спасибо!
😁
Л(
11 June 2022
AV
05:10
Artem Vorotnikov
хм
VERIFY amalgamated sources...In file included from mdbx.c:1060:
В функции «atomic_store64»,
включённом из «mdbx_find_oldest.isra» в mdbx.c:9227:12:
mdbx.c:4320:3: ошибка: «__atomic_store_8» writing 8 bytes into a region of size 0 overflows the destination [-Werror=stringop-overflow=]
Л(
05:58
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Исправлено 12 мая.
Возьмите текущую ветку
Возьмите текущую ветку
master из https://gitflic.ru/project/erthink/libmdbx, либо подождите пару дней релиз v0.11.8
AV
Л(
15:33
Леонид Юрьев (Leonid Yuriev)
Обнаружена существенная/критическая проблема (write-after-free) при работе на последних релизах MacOS/OSX/iOS.
Суть проблемы = запись в уже освобожденный регион памяти при завершении каждого потока читавшего из БД.
Причины:
- в dyld изменился механизм вызова деструкторов и освобождения ресурсов TLS (Thread Local Storage).
- ранее, память выделенная под переменные декларированные как
- теперь же, выделенные под
Проблема возникла только на MacOS по трем причинам:
- кроме MacOS, нет систем где ресурсы и деструкторы освобождаются/вызываются в прямом порядке (телега впереди лошади), а не в обратном.
- libmdbx переходит на использование
- эппловская
Сегодня будет исправление, из двух частей:
- в резервный rthc-механизм в libmdbx будет добавлен контроль сигнатур, с очисткой посредством atomic-compare-and-swap, что гарантирует отсутствие write-after-free, вне зависимости от поведения системных библиотек (в худшем случае будет несущественная течь ресурсов).
- добавление использование
Суть проблемы = запись в уже освобожденный регион памяти при завершении каждого потока читавшего из БД.
Причины:
- в dyld изменился механизм вызова деструкторов и освобождения ресурсов TLS (Thread Local Storage).
- ранее, память выделенная под переменные декларированные как
__thread, освобождалась после вызова зарегистрированных TLS-деструкторов, что соответствовало обычному/ожидаемому порядку освобождения/разрушения, обратному при выделении/создании.- теперь же, выделенные под
__thread-переменные блоки памяти освобождается до вызова зарегистрированных деструкторов, из-за чего такой деструктор в libmdbx писал в уже освобожденный регион.Проблема возникла только на MacOS по трем причинам:
- кроме MacOS, нет систем где ресурсы и деструкторы освобождаются/вызываются в прямом порядке (телега впереди лошади), а не в обратном.
- libmdbx переходит на использование
__thread-переменных только при отсутствии __cxa_thread_atexit().- эппловская
_tlv_atexit() не использовалась, ибо: (1) не имеет якоря привязки к DSO из-за чего приводит к падениям при выгрузке dso/dll, (2) отлично работал резервный механизм в libmdbx.Сегодня будет исправление, из двух частей:
- в резервный rthc-механизм в libmdbx будет добавлен контроль сигнатур, с очисткой посредством atomic-compare-and-swap, что гарантирует отсутствие write-after-free, вне зависимости от поведения системных библиотек (в худшем случае будет несущественная течь ресурсов).
- добавление использование
_tlv_atexit() на Darwin.
❤
AV
i
SC
Л(
AV
17:16
Artem Vorotnikov
In reply to this message
Спасибо! Если что, как гошные, так и растовые привязки включают
MDBX_NOTLS
13 June 2022
Л(
00:07
Леонид Юрьев (Leonid Yuriev)
libmdbx 0.11.8 (Baked Apple)
The stable release with an important fixes and workaround for the critical macOS thread-local-storage issue.
https://gitflic.ru/project/erthink/libmdbx/release/06268038-39ff-4270-9be8-9f26d5543015
The stable release with an important fixes and workaround for the critical macOS thread-local-storage issue.
https://gitflic.ru/project/erthink/libmdbx/release/06268038-39ff-4270-9be8-9f26d5543015
🎉
AA
ED
AV
14 June 2022
AA
08:33
Alexey Akhunov
good morning! Long time ago, I found a way to increase the effectiveness of freelist organisation during commits in LMDB to reduce commit times and made a patch that we used. Yesterday I tried to apply the same patch to MDBX and tested it today, and it seems to work too! 🙂 here is the patch: https://github.com/torquem-ch/mdbx-go/pull/72
🔥
SC
08:34
the reason it worked described here: https://github.com/ledgerwatch/erigon/wiki/LMDB-freelist-illustrated-guide
08:35
search for ",The fix was to not allocate transaction IDs lower than
1000001 to the new writeable transactions. How does this help?"
08:37
after 1 hours of running DB with this patch, my commit times went from 1-2 seconds to sub 200ms, with the same workload. I will test it on other databases
Л(
10:12
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Unfortunately, this approach does not work and will fail gives only a short-term positive effect and does not work at all for a long time.
I will give explanations in Russian, and then translate if necessary.
I will give explanations in Russian, and then translate if necessary.
Л(
11:05
Леонид Юрьев (Leonid Yuriev)
Значение (величина) номера транзакции имеет значение, только когда при фиксации транзакции требуется вернуть в GC остаток списка свободных страниц и этот список очень большой.
Если нумерация транзакций начинается с больших чисел, то в начале пространстве ключей GC всегда будет интервал, который можно использовать для набора коротких записей со списками страниц вместо единого большого куска.
Смысл избегать очень длинных записей в GC в том, что такие записи (при текущем формате БД) требует последовательных страниц для хранения, т.е. при их создании нужно искать такие последовательности среди свободных страниц.
В свою очередь, природа btree такова, что в большинстве сценариев использования страницы изменяются более-менеее случайно.
Поэтому при CoW в GC распределение номеров страниц примерно случайно/стохастическое, а распределение длин последовательностей обратно-экспоненциальное.
Соответственно, помещение длинных записей в GC требует поиска по всей GC, с загрузкой в память в список свободных страниц, а сам список затем придется снова записать в GC.
libmdbx автоматически производит нарезку больших записей на более мелкие когда это возможно и если в пространстве ключей есть запас, то сделать это действительно проще, однако нужно учитывать остальные факторы:
- при текущем формате БД retired-страницы должны помещятcя в GC одной записью, именно это порождает потребность в последовательностях свободных страниц и загрузку всей GC в память;
- если возникла ситуация когда требуются ID для записи списка свободных страниц по частям, то значит уже были транзакции с большим retired-списком.
Поэтому нумерация транзакций с
Но чем больше транзакций будет закоммичено, тем меньше будет разница.
Если нумерация транзакций начинается с больших чисел, то в начале пространстве ключей GC всегда будет интервал, который можно использовать для набора коротких записей со списками страниц вместо единого большого куска.
Смысл избегать очень длинных записей в GC в том, что такие записи (при текущем формате БД) требует последовательных страниц для хранения, т.е. при их создании нужно искать такие последовательности среди свободных страниц.
В свою очередь, природа btree такова, что в большинстве сценариев использования страницы изменяются более-менеее случайно.
Поэтому при CoW в GC распределение номеров страниц примерно случайно/стохастическое, а распределение длин последовательностей обратно-экспоненциальное.
Соответственно, помещение длинных записей в GC требует поиска по всей GC, с загрузкой в память в список свободных страниц, а сам список затем придется снова записать в GC.
libmdbx автоматически производит нарезку больших записей на более мелкие когда это возможно и если в пространстве ключей есть запас, то сделать это действительно проще, однако нужно учитывать остальные факторы:
- при текущем формате БД retired-страницы должны помещятcя в GC одной записью, именно это порождает потребность в последовательностях свободных страниц и загрузку всей GC в память;
- если возникла ситуация когда требуются ID для записи списка свободных страниц по частям, то значит уже были транзакции с большим retired-списком.
Поэтому нумерация транзакций с
1_000_000 даёт эффект только в достаточно искусственной/редкой ситуации, когда в нескольких первых транзакциях большая БД наполняется и существенно меняется (удаляется и/или обновляется большое кол-во записей).Но чем больше транзакций будет закоммичено, тем меньше будет разница.
Л(
11:22
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Перефразировано/выжато из переписки с @AskAlexSharov:
В целом причинно-следственная цепочка такая:
- У Erigon случаются транзакции с огромным retired объемом (сотни тысяч страниц);
- Эти огромные списки retired-страниц нужно сохранять в GC для чего (в текущем дизайне/формате) требуются длинные последовательности пустых страниц;
- В btree изменения по страницам достаточно случайны, и размер пустых цепочек имеет обратно-экспоненциальное распределение (длинные цепочки очень маловероятны).
- Поэтому большие retired-списки сначала требуют приращения БД (сначала в GC нет длинных цепочек), а затем поиска этих цепочек во всей GC.
- Через несколько итераций GC становится очень большой, а поиск занимает много времени, хотя в целом всё работает.
Кардинально решить проблему можно только устранив причину:
- добавить "потоковый" формат хранения больших данных, чтобы для больших BLOB-ов и списков не требовались последовательности страниц;
- хранить последовательности страниц в сжатом виде (RLE, roaring bitmaps, etc);
= требуется смена формата БД.
Это всё будет в MithrilDB, но пока у меня нет времени довести его до готовности (
Последние же данные профилирования от @AskAlexSharov показали, что существенная часть времени тратится не на загрузку записей GC в память, а только на просмотр списка пустых страниц уже в ОЗУ.
Сейчас вторичную проблему можно обрисовать так:
- изначально длинные retired-списки помещаются в GC "как есть": в одну запись с номером транзакции в качестве ключа, ибо так требуется для отслеживания.
- затем, при случае, длинные записи в GC нарезаются более мелкими кусками, чтобы высвободить длинные последовательности пустых страниц (в результате, в целом, со временем, такие последовательности всегда есть и БД перестает расти);
- однако, затем, при поиске длинных последовательностей, все эти мелкие слайсы нужно загрузить и объединить в один список в ОЗУ;
- проблема в том, что сейчас поиск в объединенном списке в ОЗУ повторяется после загрузки каждого слайса;
= соответственно, всплески latency случаются когда для очередного большого retited-списка последовательность свободных страниц не обнаруживается на "поверхности" GC и происходит поиск "в глубину" (отказываться от него нельзя, ибо тогда БД будет постоянно расти).
Поэтому я подумаю как ускорить именно это место:
- попробовать сделать простейший/минимальный вариант более эффективного списка пустых страниц в памяти (с RLE для цепочек);
- отделить поиск коротких цепочек (fast path) от поиска длинных (rare slow path);
- как минимум избежать ненужных циклов сканирования списка при загрузке слайсов при поиске длинных последовательностей (предположительно это сэкономит ~80% времени).
В целом причинно-следственная цепочка такая:
- У Erigon случаются транзакции с огромным retired объемом (сотни тысяч страниц);
- Эти огромные списки retired-страниц нужно сохранять в GC для чего (в текущем дизайне/формате) требуются длинные последовательности пустых страниц;
- В btree изменения по страницам достаточно случайны, и размер пустых цепочек имеет обратно-экспоненциальное распределение (длинные цепочки очень маловероятны).
- Поэтому большие retired-списки сначала требуют приращения БД (сначала в GC нет длинных цепочек), а затем поиска этих цепочек во всей GC.
- Через несколько итераций GC становится очень большой, а поиск занимает много времени, хотя в целом всё работает.
Кардинально решить проблему можно только устранив причину:
- добавить "потоковый" формат хранения больших данных, чтобы для больших BLOB-ов и списков не требовались последовательности страниц;
- хранить последовательности страниц в сжатом виде (RLE, roaring bitmaps, etc);
= требуется смена формата БД.
Это всё будет в MithrilDB, но пока у меня нет времени довести его до готовности (
Последние же данные профилирования от @AskAlexSharov показали, что существенная часть времени тратится не на загрузку записей GC в память, а только на просмотр списка пустых страниц уже в ОЗУ.
Сейчас вторичную проблему можно обрисовать так:
- изначально длинные retired-списки помещаются в GC "как есть": в одну запись с номером транзакции в качестве ключа, ибо так требуется для отслеживания.
- затем, при случае, длинные записи в GC нарезаются более мелкими кусками, чтобы высвободить длинные последовательности пустых страниц (в результате, в целом, со временем, такие последовательности всегда есть и БД перестает расти);
- однако, затем, при поиске длинных последовательностей, все эти мелкие слайсы нужно загрузить и объединить в один список в ОЗУ;
- проблема в том, что сейчас поиск в объединенном списке в ОЗУ повторяется после загрузки каждого слайса;
= соответственно, всплески latency случаются когда для очередного большого retited-списка последовательность свободных страниц не обнаруживается на "поверхности" GC и происходит поиск "в глубину" (отказываться от него нельзя, ибо тогда БД будет постоянно расти).
Поэтому я подумаю как ускорить именно это место:
- попробовать сделать простейший/минимальный вариант более эффективного списка пустых страниц в памяти (с RLE для цепочек);
- отделить поиск коротких цепочек (fast path) от поиска длинных (rare slow path);
- как минимум избежать ненужных циклов сканирования списка при загрузке слайсов при поиске длинных последовательностей (предположительно это сэкономит ~80% времени).
11:33
@AskAlexSharov, @ledgerwatch, еще я подумаю чтобы при фиксации транзакции с большим retired-списком автоматически увеличивать
Это позволит сразу разрезать большие списки и по-сути будет примитивным суррогатным подобием формата хранения MithrilDB.
Проблемы тут две:
- доработка требует переделки
- может быть неожиданно для софта, когда при коммите номер транзакции скачет вперед на произвольное значение.
Но бонус в том, что это должно полностью вылечить наблюдаемые проблемы.
txnid.Это позволит сразу разрезать большие списки и по-сути будет примитивным суррогатным подобием формата хранения MithrilDB.
Проблемы тут две:
- доработка требует переделки
mdbx_update_gc(), т.е. требует времени и тестирования.- может быть неожиданно для софта, когда при коммите номер транзакции скачет вперед на произвольное значение.
Но бонус в том, что это должно полностью вылечить наблюдаемые проблемы.
11:36
But a bonus is that this should completely solve the observed problems.
AA
12:07
Alexey Akhunov
Cпасибо! Проблему которую мы решали (и решаем) с помощью увеличения номера транзакции это как раз медленный коммит на базах данных которые только только были созданы. Со временем, когда они "стареют", всё само собой разрешается, но установка номера транцакции в 1000000 просто ускоряет этот процесс скажем на полгода
12:12
В прошлом, этот патч очень хорошо сработал с LMDB и прекратил поток жалоб пользователей на медленные коммиты. Сейчас этот поток жалоб начинает возрастать для MDBX, и я попробую включить это в след. релиз Эригона и посмотрю решило ли это проблемы пользователей. Думаю, что решит
Л(
12:58
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Этот костыль безобидный, поэтому можно включать.
Однако, если верить данным профилирования от @AskAlexSharov, то проблема совсем в другом (как написал выше).
Поэтому, с одной стороны, я всё-равно попробую реализовать "Bigfoot feature" (автоматическое приращение
С другой стороны, стоит несколько раз сделать профилирование (на разных системах, с разной длительностью), чтобы не иметь сомнений относительно затрат при формировании и фиксации транзакций.
+ Для понимания: bigfoot "выполнит" ваш патч до возникновения проблемы, а не для частичного обхода последствий на начальных транзакциях.
Однако, если верить данным профилирования от @AskAlexSharov, то проблема совсем в другом (как написал выше).
Поэтому, с одной стороны, я всё-равно попробую реализовать "Bigfoot feature" (автоматическое приращение
txnid для дробления retired pages list), ибо это должно решить все проблемы.С другой стороны, стоит несколько раз сделать профилирование (на разных системах, с разной длительностью), чтобы не иметь сомнений относительно затрат при формировании и фиксации транзакций.
+ Для понимания: bigfoot "выполнит" ваш патч до возникновения проблемы, а не для частичного обхода последствий на начальных транзакциях.
Л(
13:31
Леонид Юрьев (Leonid Yuriev)
Честно говоря, "bigfoot" - великолепная идея, странно что не пришла в голову раньше (или я уже забыл про какие-то подводные камни).
AA
14:17
Alexey Akhunov
Я сейчас перечитаю обьяснение, потому что с утра был в спешке
👍
Л(
EI
21:10
Eugene Istomin
In reply to this message
Обратная связь по проблеме: появляется только при работе malloc-модулями:
LD_PRELOAD=/usr/lib64/libjemalloc.so.2
LD_PRELOAD=/usr/lib64/libtcmalloc.so.4
LD_PRELOAD=/usr/lib64/libjemalloc.so.2
LD_PRELOAD=/usr/lib64/libtcmalloc.so.4
Л(
22:34
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Подумаю-посмотрю, но через пару дней.
Пока советую попробовать актуальную версию и задействовать максимум контроля и диагностики на стороне je/tc-malloc.
Пока советую попробовать актуальную версию и задействовать максимум контроля и диагностики на стороне je/tc-malloc.
15 June 2022
p
10:22
pavel
Вопрос про реализацию лайков.
Есть правильная кастомная хранилка key=set<uint64>, где key - идентификатор лайкаемого обьекта, uint64 = userid. Хранилка быстро возвращает len(set), даже если внутри миллиард интов и мы быстро видим число лайков у обьекта. Быстро - это b-tree, максимум 1 поход на диск. Медленнее, чем hyperloglog, но ведь нельзя лайенуть одно и то же дважды да и список лайкеров хочется запросить, так что хранить честный set лайкнувших - надо так или иначе.
Вопрос в том, как бы мне не делать 80 запросов в лайкохранилку при попытке показать страницу с 40 комментами. Ведь про каждый коммент надо спросить len(его set) и set.find(userid) дабы понимать лайкало это тело обьект или нет.
От set.find(uid) непонятно как избавиться - вещь нужная, а вот len(set) можно кешировать в uint32-поле (колонке "likes") самой сообщенечки. То есть, в коде "бизнес-логики", отправив запрос на добавление лайка в set, проапдейтить колонку likes новым значением len(set). Профит: число лайков лежит прямо в сообщеньке и показать 40 мессаг с лайками - скан рядом лежащих данных.
Проблема в нагрузке на update(message) при большом потоке лайков на него и в расссинхроне - когда сервис set-ов с лайками жив, а messages прилег на 5 минут. Ясно, что следующий лайк синхронизирует все как надо, но его может не быть. Хотя не банковские данные, потерять в счетчике лайков временно - не беда. Ну или можно такое правило: раз в N запросов ходить за len(set) - уточнять. Остался вопрос про прореживание - как делать update(message) не на каждый лайк, когда их валится стопицот тыщ. Хотя, этот update вроде не дорогой, да и даже самый популярный коммент на ютубе получает лайков порядка 5K, что не в одну секунду. Да и непонятно как прореживать - завести sizeclass как в аллокаторах? Ну типа до 100 лайков - апдейтить на каждый, до 1000 - на каждый 5-й и т.п.
в общем, прочьба поделиться мыслями про кеширование числа лайков внутри мессаги, про прореживание апдейтов и прочее.
Есть правильная кастомная хранилка key=set<uint64>, где key - идентификатор лайкаемого обьекта, uint64 = userid. Хранилка быстро возвращает len(set), даже если внутри миллиард интов и мы быстро видим число лайков у обьекта. Быстро - это b-tree, максимум 1 поход на диск. Медленнее, чем hyperloglog, но ведь нельзя лайенуть одно и то же дважды да и список лайкеров хочется запросить, так что хранить честный set лайкнувших - надо так или иначе.
Вопрос в том, как бы мне не делать 80 запросов в лайкохранилку при попытке показать страницу с 40 комментами. Ведь про каждый коммент надо спросить len(его set) и set.find(userid) дабы понимать лайкало это тело обьект или нет.
От set.find(uid) непонятно как избавиться - вещь нужная, а вот len(set) можно кешировать в uint32-поле (колонке "likes") самой сообщенечки. То есть, в коде "бизнес-логики", отправив запрос на добавление лайка в set, проапдейтить колонку likes новым значением len(set). Профит: число лайков лежит прямо в сообщеньке и показать 40 мессаг с лайками - скан рядом лежащих данных.
Проблема в нагрузке на update(message) при большом потоке лайков на него и в расссинхроне - когда сервис set-ов с лайками жив, а messages прилег на 5 минут. Ясно, что следующий лайк синхронизирует все как надо, но его может не быть. Хотя не банковские данные, потерять в счетчике лайков временно - не беда. Ну или можно такое правило: раз в N запросов ходить за len(set) - уточнять. Остался вопрос про прореживание - как делать update(message) не на каждый лайк, когда их валится стопицот тыщ. Хотя, этот update вроде не дорогой, да и даже самый популярный коммент на ютубе получает лайков порядка 5K, что не в одну секунду. Да и непонятно как прореживать - завести sizeclass как в аллокаторах? Ну типа до 100 лайков - апдейтить на каждый, до 1000 - на каждый 5-й и т.п.
в общем, прочьба поделиться мыслями про кеширование числа лайков внутри мессаги, про прореживание апдейтов и прочее.
Л(
12:16
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Наверное я дам вам не тот ответ, что вы бы хотели, но (как считаю) верный по сути:
1) Берите "совсем правильную" хранилку, а именно Tarantool.
Мне жаль что Константин Осипов покинул проект, но в тарантуле многое сделано очень хорошо, с остальное достаточно хорошо.
В частности, и что не всего легко увидеть сквозь слои маркетинга: таратнул коммитит на диск "за раз" все прилетевшие аптейты, хоть это 100 роликов по 1 лайку, хоть 100К по 1К лайков.
Хранимки на Lua с JIT, кастомные модули и хранимки на C, шартинг и репликация из каробки, продуманная миграция и управление кластером - при всём уважении к "правильной кастомной" хралилке, скорее всего следует отдать предпочтение тарантулу.
2) Если смотреть на задачу с учетом возможностей тарантула, то у вас появляется определенная гибкость и пространство для экспериментов:
- можно экспериментировать с индексами в памяти (не хранимыми), да холодный старт будет дольше, но в пределах разумного (не считая возможности использовать горячие реплики).
- все запросы, даже с запутанной бизнес-логикой "говно и палки" можно делать локально (как in-process, так и рядом).
- и т.д. и т.п.
3) Какие-либо более конкретные дельные советы для rutube-подобных проектов требует глубокого вникания в задачу и учета возможностей "хранилки".
В том числе, например, подсчет комментариев/лайков, пагинация и т.п. может эффективно решаться использованием btree-подобного индекса обеспечивающего подсчет количество записей для узла (соответственно моментальный подсчет точного количества записей в диапазоне между ключами).
1) Берите "совсем правильную" хранилку, а именно Tarantool.
Мне жаль что Константин Осипов покинул проект, но в тарантуле многое сделано очень хорошо, с остальное достаточно хорошо.
В частности, и что не всего легко увидеть сквозь слои маркетинга: таратнул коммитит на диск "за раз" все прилетевшие аптейты, хоть это 100 роликов по 1 лайку, хоть 100К по 1К лайков.
Хранимки на Lua с JIT, кастомные модули и хранимки на C, шартинг и репликация из каробки, продуманная миграция и управление кластером - при всём уважении к "правильной кастомной" хралилке, скорее всего следует отдать предпочтение тарантулу.
2) Если смотреть на задачу с учетом возможностей тарантула, то у вас появляется определенная гибкость и пространство для экспериментов:
- можно экспериментировать с индексами в памяти (не хранимыми), да холодный старт будет дольше, но в пределах разумного (не считая возможности использовать горячие реплики).
- все запросы, даже с запутанной бизнес-логикой "говно и палки" можно делать локально (как in-process, так и рядом).
- и т.д. и т.п.
3) Какие-либо более конкретные дельные советы для rutube-подобных проектов требует глубокого вникания в задачу и учета возможностей "хранилки".
В том числе, например, подсчет комментариев/лайков, пагинация и т.п. может эффективно решаться использованием btree-подобного индекса обеспечивающего подсчет количество записей для узла (соответственно моментальный подсчет точного количества записей в диапазоне между ключами).
17 June 2022
Л(
09:50
Леонид Юрьев (Leonid Yuriev)
В ветке
Заинтересованным предлагается попробовать, у меня (пока) за 12+ часов тесты проблем не выявили.
Но тот код не для production и будет доработан.
erigon доступен черновик фичи " bigfoot" для решения замедления транзакций в Ethereum с очень-большими транзакциями.Заинтересованным предлагается попробовать, у меня (пока) за 12+ часов тесты проблем не выявили.
Но тот код не для production и будет доработан.
👍
РЛ
18 June 2022
Filip invited Filip
Виктор invited Виктор
В
05:43
Виктор
Здравствуйте! Очень хочется попробовать libmdbx в своем проекте, но, к большому сожалению, в интернете большинство ссылок на статьи по применению заблокированы. Большая просьба дать ссылки на примеры использования libmdbx в разрезе c++
Л(
08:11
Леонид Юрьев (Leonid Yuriev)
In reply to this message
https://libmdbx.dqdkfa.ru/group__cxx__api.html
Что-то еще появиться когда кто-то напишет.
Что-то еще появиться когда кто-то напишет.
В
11:34
Виктор
Это первое что посмотрел) Но из этого непонятно с чего начать. Может есть простенький main.cpp для старта?
РЛ
11:41
Делал аксетичный пример для себя на период погружения.
В
11:53
Виктор
Проект на с++. Си вариант не собирается.
ddadybayo invited ddadybayo
vvv invited vvv
Л(
20:28
Леонид Юрьев (Leonid Yuriev)
Хочу посоветоваться, если кто-то занимался и/или занимается CI для проектов с C++.
Вопросов примерно два:
1) Есть ли смысл заморачиваться с проверкой старыми компиляторами, либо рациональнее и/или достаточно ограничиться актуальными версиями gcc/clang с явным выбором стандарта С++ 11/14/17/20/23 ?
2) Если все-таки делать итерации со старыми компиляторами, то какой максимально готовый набор doker-образов посоветуете ?
Вопросов примерно два:
1) Есть ли смысл заморачиваться с проверкой старыми компиляторами, либо рациональнее и/или достаточно ограничиться актуальными версиями gcc/clang с явным выбором стандарта С++ 11/14/17/20/23 ?
2) Если все-таки делать итерации со старыми компиляторами, то какой максимально готовый набор doker-образов посоветуете ?
EI
b
20:31
basiliscos
In reply to this message
я бы сказал, что имеет смысл поддерживать "самое старое поддерживаемое" (например, приняли, что поддерживаем с++11, то его и тестим) + тестать последний релиз (с++20). Посередине, я бы сказал, особого смысла тестать нет.
19 June 2022
Л(
14:56
Леонид Юрьев (Leonid Yuriev)
Спасибо за ответы/мнения.
Думал/пробовал, смотрел и т.п.
В сухом остатке всё достаточно очевидно/ожидаемо.
1. Откажусь от CI на всех устаревших не-поддерживаемых платформах.
Тут требуется больше всего как костылей, так и усилий для поддержки самого CI, при этом их мало кто использует эти платформы.
Сюда попадают как старые версии компиляторов lcc < 1.25, gcc 4.x, clang, msvc 2015), так и устаревшие версии стандартной библиотеки С++.
Критерий похоже будет очень прост: окончание поддержки LTS у Ubuntu, окончание поддержки MSVC и т.д.
2. Поддержка стандарта C++ сохраниться на 10+ лет.
Сейчас требуется минимум C++11, а в 2024 могут потребовать как минимум C++14.
Однако, не будет обеспечиваться совместимость/поддержка с устаревшими версиями компиляторов и libstdc++ (как обозначено в первом пункте).
CI-сборки будут для каждого стандарта 11/14/17/20/23, иначе нет покрытия.
Думал/пробовал, смотрел и т.п.
В сухом остатке всё достаточно очевидно/ожидаемо.
1. Откажусь от CI на всех устаревших не-поддерживаемых платформах.
Тут требуется больше всего как костылей, так и усилий для поддержки самого CI, при этом их мало кто использует эти платформы.
Сюда попадают как старые версии компиляторов lcc < 1.25, gcc 4.x, clang, msvc 2015), так и устаревшие версии стандартной библиотеки С++.
Критерий похоже будет очень прост: окончание поддержки LTS у Ubuntu, окончание поддержки MSVC и т.д.
2. Поддержка стандарта C++ сохраниться на 10+ лет.
Сейчас требуется минимум C++11, а в 2024 могут потребовать как минимум C++14.
Однако, не будет обеспечиваться совместимость/поддержка с устаревшими версиями компиляторов и libstdc++ (как обозначено в первом пункте).
CI-сборки будут для каждого стандарта 11/14/17/20/23, иначе нет покрытия.
25 June 2022
SC
11:25
Simon C.
Would it be possible to add
#ifndef to MDBX_LOCK_SUFFIX to allow customization?
Л(
Л(
22:19
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Please use the
https://gitflic.ru/project/erthink/libmdbx/commit/7b735c272d384b2d9adc27c8ce0f16cd76ce6409
master branch, since devel contain experimantal features and will be rewritten.https://gitflic.ru/project/erthink/libmdbx/commit/7b735c272d384b2d9adc27c8ce0f16cd76ce6409
SC
22:20
Simon C.
Will do, thanks!
27 June 2022
Levi Aul invited Levi Aul
LA
07:49
Levi Aul
Hi, I tried to use
after a bit more tracing, it's seemingly triggered by this line in
mdbx_load to load data into an mdbx DB created by Erigon with non-default pagesize (16kb), but it refuses to work, quitting with MDBX_INCOMPATIBLE; after enabling debugging + copying over the relevant console-logger into that utility, I get this more-specific error:
! could not apply preconfigured db-geometry: err 22
after a bit more tracing, it's seemingly triggered by this line in
mdbx_env_set_geometry:
if ((uint64_t)size_lower / pagesize < MIN_PAGENO) {
rc = MDBX_EINVAL;
goto bailout;
}
LA
08:06
Levi Aul
a bit of printf-debugging says:
-
-
-
size_lower is 12288-
pagesize is 16384
Л(
Л(
28 June 2022
Yevhenii Skrebtsov invited Yevhenii Skrebtsov
29 June 2022
Klen Santakheza invited Klen Santakheza
KS
14:44
Klen Santakheza
здравствуйте! хочу вступить в ряды бынды. посмотрел исходники, подсобрал поднял - очень итересно. родилась мысль: сделать железяку - аппаратную бд. вижу это так : проц 500мгц 1мб быстрого озу, 64мб sdram, кучка микросхем флеша + SD накопитель. наружу езернет для класического применения и промышленные интерфейсы для "некласического" применения.
размер двух паралленно работающих баз 256мб и вторая определяемая SD картой в сокете. поверх кода mdbx интерфейс redis-like для доступа по сети.
никаких больших линуксов, никакого жира и индуского кода. сбоеустойчивая фс. размер с пачку сигарет, потреблние 2.5 вата под нагрузкой, скорость обмена порядка 133мб/c
если хотя бы морально поддержите то возьмусь. заодно поподтягиваю Ваш код к С++23. увидел много резервов для compile/linking- time оптимизации
размер двух паралленно работающих баз 256мб и вторая определяемая SD картой в сокете. поверх кода mdbx интерфейс redis-like для доступа по сети.
никаких больших линуксов, никакого жира и индуского кода. сбоеустойчивая фс. размер с пачку сигарет, потреблние 2.5 вата под нагрузкой, скорость обмена порядка 133мб/c
если хотя бы морально поддержите то возьмусь. заодно поподтягиваю Ваш код к С++23. увидел много резервов для compile/linking- time оптимизации
EI
17:31
Eugene Istomin
In reply to this message
Добрый!
Для меня звучит немного запутанно - особенно в месте "никакого больше линукса" - в смысле asm-загрузчик + C-обвязка над mdbx?
Для меня звучит немного запутанно - особенно в месте "никакого больше линукса" - в смысле asm-загрузчик + C-обвязка над mdbx?
KS
17:32
Klen Santakheza
почти так
17:33
операционная система тут не нужна. это лишнее
17:34
достаточно шедуллера реального времени
EI

{kind=link}
{kind=link}
{kind=link}
KS
17:35
Klen Santakheza
я :) у меня своя быстрая libc написанная на с++ , с сосками враперами с99
EI
KS
17:37
Klen Santakheza
стандрартные реализации очень медленные. посмотлите к примеру memcpy в glibc которую скорее всего используетее не задаваясь вопросом как оно работает. прослезитесь
EI
17:38
Eugene Istomin
In reply to this message
Грамотный embedded уровня "нечему ломаться" - это будет скоро нужно, буду следить за новостями
KS
17:38
Klen Santakheza
это мой хлеб
👍
EI
Павел Кораблёв invited Павел Кораблёв
KS
17:41
Klen Santakheza
в данный момент глядя на исходники понятно как к libdbmx прикрутить функционал потоков их синхронизации, стек тср, низ к микросхемам памяти - то есть портануть , отделить верх от системы ... но что мне делать с напихаными С++ эксепшинамт... беда
17:42
я ставлю задачу так: код хотя бы стремится к проходу тестов MISRA должен... С++ исключения это из другой вселенной
17:44
это должена быть в полном смысле embedded db. иначе смысла нет.
ПК
KS
17:45
Klen Santakheza
я вижу необходимомть в промышленом оборудовании, комплексы и системы. тук критически важна скорость реакции
ПК
17:45
Павел Кораблёв
In reply to this message
Какие требования к прототипу по железу? Производители, производство, локализация
KS
17:49
Klen Santakheza
предскпзуемое время обрабртки запроса и дубовая надежность и устойчиврсть к воздействиям на железяку. абсалютная скорость не так важна
17:50
я думаю что буду пробывать макетик собрать. понадобится Ваша помощь. чтоб меньше ковырятся и быстрее портануть код.
EI
17:50
Eugene Istomin
In reply to this message
@erthink, что думаете?
Тема реально хорошая, не вся же пром.интеграция будет в ближайшие годы красивая (на шинах итд) - думаю, что быстрые KV-боксы имеют реальную нишу.
Т.е. в разные исполнения закатать (для пищеблоков, для пыльных производств, ...) - и можно использовать как аггрегатор локальных данных: персональный (для аудита) или при смене тех.процесса, как временное решение
Тема реально хорошая, не вся же пром.интеграция будет в ближайшие годы красивая (на шинах итд) - думаю, что быстрые KV-боксы имеют реальную нишу.
Т.е. в разные исполнения закатать (для пищеблоков, для пыльных производств, ...) - и можно использовать как аггрегатор локальных данных: персональный (для аудита) или при смене тех.процесса, как временное решение
KS
17:51
Klen Santakheza
да. именно так. железку я сам разрабатываю и изготавливаю. покупаю только микросхемы.
🔥
EI
17:53
пищеблоки....это интересно..я про более про бортовый комплексы мыслю.
17:54
я думаю даже если идея не взлетит, все равно хорошо потренеруемся. гигабайтов в сек не поличить но можно подкупит надежностью и потреблением
EI
17:55
Eugene Istomin
In reply to this message
\\ тут две же развёртки "с лёту" - ОПК и смена владельцев у производств. В ОПК был, ЭМС занимался, стараюсь аккуратно с военной приёмкой иметь дело )
Производства (для меня) интереснее
Производства (для меня) интереснее
KS
17:56
Klen Santakheza
подумайте сами - отделить от кода низ, означает описать обстрактно базу с ее алгоритмами, и низ - абстракция аппаратуры.
17:58
task, synchronization, open, read, write, close, sync.
17:59
в эмбеддед уже давно есть негласный стандарты на интерфейс. на писи все пилят каждый свой велосипед.
ПК
18:06
Павел Кораблёв
In reply to this message
Чугунно-простая операционка как расширение функции хранилища и архива?
EI
18:07
Eugene Istomin
In reply to this message
Там даже не операционка, там libc, которое напрямую (через asm, конечно) в железо смотрит
ПК
18:09
Павел Кораблёв
РБ
Рубикон Безумный 29.06.2022 17:58:32
https://gitflic.ru/project/erthink/libmdbx
там народ на столько преисполнися, что неудосужился линк в заголовке группы поправить, а репу на гитхабе снес
там народ на столько преисполнися, что неудосужился линк в заголовке группы поправить, а репу на гитхабе снес
KS
18:14
Klen Santakheza
когда лет двадцать назад был oracle кторый без SunOS непосредственно на spark машину насаживался. бысто. красиво никаких индийских танцев по пол часа между переноской угля в топку паровоза
18:15
хочу также :) но чтоб доступно для всех
🔥
ПК
18:23
все таки хотелось бы хотя бы в общем виде понять перспективы выпилить с++ исключения. или все переписывать....?
Л(
18:24
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Упоминание github поправлено.
Оставалось по недосмотру, спасибо за наводку.
По поводу "а репу на гитхабе снес" см https://t.me/libmdbx/2814, https://t.me/libmdbx/2905, ChangeLog и Release Notes для v0.11.7 (https://gitflic.ru/project/erthink/libmdbx/release/90ec9985-cd60-4d9a-8c98-8417506fd26d)
Оставалось по недосмотру, спасибо за наводку.
По поводу "а репу на гитхабе снес" см https://t.me/libmdbx/2814, https://t.me/libmdbx/2905, ChangeLog и Release Notes для v0.11.7 (https://gitflic.ru/project/erthink/libmdbx/release/90ec9985-cd60-4d9a-8c98-8417506fd26d)
18:25
In reply to this message
Ох, я думаю... или сова порвётся, или глобус сломается ;)
Если серьёзно, то всё определяется решаемой задачей, условиями/ограничениями/требованиями и финансированием.
Если серьёзно, то всё определяется решаемой задачей, условиями/ограничениями/требованиями и финансированием.
KS
18:26
Klen Santakheza
это вообще про все или только про эксепшены?
18:27
глобус надуем. сову тоже. мы кого хочешь надуем
Л(
18:31
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Исключения используются только в C++ API, фактически это легковестная обертка над C API с добавлением сервиса (управление буферами, RAII и т.п.).
Поэтому избавиться от исключений можно тремя способами:
- использовать C API, https://libmdbx.dqdkfa.ru/group__c__api.html
- сделать свои биндинги для С++ без использования исключений
- предложить какое-то работающее решение, без нарушения совместимости с текущим кодом.
Поэтому избавиться от исключений можно тремя способами:
- использовать C API, https://libmdbx.dqdkfa.ru/group__c__api.html
- сделать свои биндинги для С++ без использования исключений
- предложить какое-то работающее решение, без нарушения совместимости с текущим кодом.
KS
18:34
Klen Santakheza
второй и первый звучит обнадеживающе
18:35
в принципе тупика пока нет. начну делать. посмотрим где упрусь лбом.
Л(
19:39
Леонид Юрьев (Leonid Yuriev)
По поводу кастомных libc, встраиваемых платформ, специализированных применений и т.п.
1. libmdbx является развитием LMDB, которая в свою очередь сконструирована под определенные сценарии использования.
Чем дальше реальное применение от этих сценариев, тем меньше у libmdbx преимуществ.
2. Все специализированные применения выстраиваются под решаемую задачу, как правило с формированием специфических требований к ОС, подсистеме хранения и/или аппаратуре.
Примерами могут быть:
- использование персистентной памяти (NVDIMM и т.п.) и/или более-менее аппаратный кэш обратной записи с "батарейкой";
- требования оптимизировать один-два эксплуатационных параметра (потребление ОЗУ, такты ЦПУ, минимум операций записи, максимальная производительность, постоянство задержки и т.п.).
Суть же в том, что чем более специализированно применение, тем меньше вероятность того что использованные в libmdbx трюки/подходы будут полезны, а затраты оправданы.
Например, использование специализированного варианта
3. У libmdbx есть несколько унаследованных недостатков, которые нельзя исправить без смены API и формата БД.
Поэтому "в принципе" я стараюсь минимизировать затраты времени на поддержку и/или развитие libmdbx, чтобы когда-нибудь закончить MithrilDB.
4. Если-же всё-таки сохраняется потребность и желание запустить libmdbx на какой-то новой/кастомной/неподдерживаемой платформе, то начинать следует с вопросов:
- есть ли сущность "процесса" и нужно ли поддерживать работы с БД для нескольких процессов, какой механизм блокировок использовать;
- будут ли потоки/threads, что с TLS (Thread Local Storage) и TSD (Thread Storage Destructors), как это работает в контексте DSO (если они есть);
- нужно ли поддерживать БД больше размера ОЗУ, как дела с
- каковы возможности файловой системы, есть ли
- есть ли
1. libmdbx является развитием LMDB, которая в свою очередь сконструирована под определенные сценарии использования.
Чем дальше реальное применение от этих сценариев, тем меньше у libmdbx преимуществ.
2. Все специализированные применения выстраиваются под решаемую задачу, как правило с формированием специфических требований к ОС, подсистеме хранения и/или аппаратуре.
Примерами могут быть:
- использование персистентной памяти (NVDIMM и т.п.) и/или более-менее аппаратный кэш обратной записи с "батарейкой";
- требования оптимизировать один-два эксплуатационных параметра (потребление ОЗУ, такты ЦПУ, минимум операций записи, максимальная производительность, постоянство задержки и т.п.).
Суть же в том, что чем более специализированно применение, тем меньше вероятность того что использованные в libmdbx трюки/подходы будут полезны, а затраты оправданы.
Например, использование специализированного варианта
std::map<> с NVDIMM может быть рациональнее чем подключение libmdbx.3. У libmdbx есть несколько унаследованных недостатков, которые нельзя исправить без смены API и формата БД.
Поэтому "в принципе" я стараюсь минимизировать затраты времени на поддержку и/или развитие libmdbx, чтобы когда-нибудь закончить MithrilDB.
4. Если-же всё-таки сохраняется потребность и желание запустить libmdbx на какой-то новой/кастомной/неподдерживаемой платформе, то начинать следует с вопросов:
- есть ли сущность "процесса" и нужно ли поддерживать работы с БД для нескольких процессов, какой механизм блокировок использовать;
- будут ли потоки/threads, что с TLS (Thread Local Storage) и TSD (Thread Storage Destructors), как это работает в контексте DSO (если они есть);
- нужно ли поддерживать БД больше размера ОЗУ, как дела с
madvise();- каковы возможности файловой системы, есть ли
msync(), fdatasync();- есть ли
/proc/sys/kernel/random/boot_id, есть ли CLOCK_BOOTTIME или CLOCK_MONOTONIC...
SC
19:42
Simon C.
In reply to this message
Very reasonable. Are you able to share a bit more about Mithril? Maybe an API sneak peak or some new / improved features 😉
KS
20:18
Klen Santakheza
In reply to this message
все очевидно, мы реалисты. желание осталось. по поводу вопросов пункта 6 - все эти вещи есть или я написал, или допишу в систему. давайте смотреть на процесс "насадить mdbx на железяку из говна и палок" как на путь развития. если заработает, то пока я это прокручу, навернякак как обычно вылезут интересные местечковые особенности, которые позволят Вам по новому посмотреть на философию и на реализацию. это будет полезно для улучшения MithrilDB. как то так :)
👍
YS
Л(
ПК
4
EI
20:52
Deleted Account
is MithrilDB a new project you are thinking about or??
Л(
21:11
Леонид Юрьев (Leonid Yuriev)
In reply to this message
This is a new code base from scratch, using both some old ideas from LMDB and many new ones.
Unfortunately, I have to take long breaks in development due to lack of time...
Unfortunately, I have to take long breaks in development due to lack of time...
❤
KS
21:23
Klen Santakheza
какой язык для общения в группе принят как предпочтительный?
Л(
21:24
Леонид Юрьев (Leonid Yuriev)
Билингво, но мой родной - русский.
ПК
21:24
Павел Кораблёв
In reply to this message
think no matter главное, чтобы понимали и уважали)
👍
Л(
30 June 2022
SC
02:27
Simon C.
I got the following config but I can never get the shrink feature to work. Even if I put 1 GB of data into mdbx and clear the database the file won't shrink. Tried macOS and iOS 😕
Is there something I have to do before it works?
Is there something I have to do before it works?
AV
SC
Л(
10:27
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Seemingly you don't have a complete understanding of how and when compactification and shrinking work.
A quote from README:
4. Automatic continuous zero-overhead database compactification.
| During each commit libmdbx merges a freeing pages which adjacent with the unallocated area at the end of file, and then truncates unused space when a lot enough of.
Thus compactification is zero-cost, but without warranty to ability to be performed.
The compactification will be sure done in case the whole database will be entirely updated several times in small record-by-record transactions.
Because a such use case warranties that each DB page will be updated/retired/reused and whole GC will be reclaimed.
So all pages adjacent with the end of DB will be pushed/merged the unallocated area of DB-file, and then could be truncated.
However, it is just one page is enough to stop compactification - a page adjacent to the end of DB and remain non-free (have filled by non-updated data or leaves in non-reclaimed portion of GC).
A quote from README:
4. Automatic continuous zero-overhead database compactification.
| During each commit libmdbx merges a freeing pages which adjacent with the unallocated area at the end of file, and then truncates unused space when a lot enough of.
Thus compactification is zero-cost, but without warranty to ability to be performed.
The compactification will be sure done in case the whole database will be entirely updated several times in small record-by-record transactions.
Because a such use case warranties that each DB page will be updated/retired/reused and whole GC will be reclaimed.
So all pages adjacent with the end of DB will be pushed/merged the unallocated area of DB-file, and then could be truncated.
However, it is just one page is enough to stop compactification - a page adjacent to the end of DB and remain non-free (have filled by non-updated data or leaves in non-reclaimed portion of GC).
SC
10:35
Simon C.
In reply to this message
Thanks for the explanation, makes sense! If I understand correctly, pages need to be updated to be elightable for truncation and that's not the case if I just clear the entire db.
Would it be a possibility / make sense to introduce a manual, non-zero cost compaction that is more powerful?
The reason is: disk space and virtual memory are scarce resources on mobile devices 😕
Would it be a possibility / make sense to introduce a manual, non-zero cost compaction that is more powerful?
The reason is: disk space and virtual memory are scarce resources on mobile devices 😕
AS
13:04
Alex Sharov
Maybe you don't really need "be as compact as possible", but enough "don't growth uncontrollable over some threshold". Can change way you using db to achieve 2-nd goal (for example do deletes and inserts in different write txs).
❤
SC
3 July 2022
SC
14:46
Simon C.
Will Mithril support page based encryption like mdb.master3? I'm getting so many requests for encryption support 🤯
Л(
5 July 2022
Ben TradeForMe invited Ben TradeForMe
6 July 2022
i
17:14
igors
In documentation we have "Do not have open an database twice in the same process at the same time, MDBX will track and prevent this. Instead, share the MDBX environment that has opened the file across all threads" - as i understand MDBX prevent it only in "Exclusive = true". Am i right @erthink ?
Л(
17:22
Леонид Юрьев (Leonid Yuriev)
In reply to this message
No.
Double-open is prohibited and prevented regardless of
Double-open is prohibited and prevented regardless of
MDBX_EXCLUSIVE flag, but when the MDBX_DBG_LEGACY_MULTIOPEN is not set by mdbx_setup_debug().
17:22
Historically "multi-open" used inside
libfpta tests, so the MDBX_DBG_LEGACY_MULTIOPEN was provided for ones.
i
17:52
igors
i think also we have typo in "Do not have open an database twice...", maybe should to be "environment" instead of "database". Because if i understand correctly, mdbx_dbi_open() - it's database open, and we can run mdbx_dbi_open in parallel, in diffent threads for the same process, but only should share environment. For example we have two parallel read transactions in different threads.
i
18:36
igors
на русском))) мне кажется нужен совет, касательно MDBX_EXCLUSIVE(почитав документацию). Я в принципе буду использовать бд локально, и скорее всего в одном процессе, но много потоков. И вот у меня дилема))) Если использовать MDBX_EXCLUSIVE - то надо шарить энв между потоками ну и правильно настроить синхронизация потоков. Если не использовать - то все задачи по синхронизации на себя забирает libmdbx? @erthink - можно больше деталей по MDBX_EXCLUSIVE?
18:41
тоже самое поповоду флага MDBX_NOTLS - я так понимаю использовать его имеет смысл только если для одного потока у нас есть параллельные транзакции для чтения(что реально странно)?
Л(
20:01
Леонид Юрьев (Leonid Yuriev)
In reply to this message
MDBX_EXCLUSIVE предназначен для случаев когда нужен явный монопольный доступ к БД, либо из-за ограничений, либо из-за производимых операций:
- работа с БД на сетевом ресурсе/диске;
- чтение БД на read-only носителе (CD-ROM);
- полной проверки и/или восстановления;
- изменении БД с гарантией отсутствия посторонних долгих чтений.
Проще говоря, в обычных случаях он не нужен.
- работа с БД на сетевом ресурсе/диске;
- чтение БД на read-only носителе (CD-ROM);
- полной проверки и/или восстановления;
- изменении БД с гарантией отсутствия посторонних долгих чтений.
Проще говоря, в обычных случаях он не нужен.
СО
20:03
Станислав Очеретный
@igor есть задачи когда удобно использовать параллельные транзакции для чтения. В моем приложении по таймеру разные компоненты системы в одном треде запрашивают нужные им данные. Т.о. нагрузка «размазывается».
Л(
20:05
Леонид Юрьев (Leonid Yuriev)
In reply to this message
MDBX_NOTLS позволяет отойти от базового правила "один поток == одна транзакция".
Типичные варианты использования:
- пул потоков обслуживающий множество очередей запросов;
- использование co-routines, fibers или "легковесных потоков" внутри среды (Rust, Java).
Типичные варианты использования:
- пул потоков обслуживающий множество очередей запросов;
- использование co-routines, fibers или "легковесных потоков" внутри среды (Rust, Java).
20:13
В свою очередь, в обычном режиме без MDBX_NOTLS, есть возможность решать определенные проблемы:
- автоматически прерывать/ликвидировать читающие транзакции при завершении/аварии потоков;
- явно отстреливать зависшие потоки с долгими транзакциями чтения;
- автоматически прерывать/ликвидировать читающие транзакции при завершении/аварии потоков;
- явно отстреливать зависшие потоки с долгими транзакциями чтения;
i
KS
23:42
Klen Santakheza
здравсвуйте. к вопросу о портировании на "железо". кроме всего прочего вызывает сомнения в возможности обойти механизм отображения в память mmap. в файле osal.c есть вызов mdbx_mmap/mdbx_munmap - для чего филосовски базе нужно это. у меня все напрямую в железке - в случае успеха. отрезать файловый io и замениить его на непосредственно запись и чтение страниц , а вот с протянутым через все mmap не понятно как быть - реализовать эмуляцию чтоб все не ломать? что это по смыслу должyо быть?
Л(
23:47
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Приветствую.
У меня устойчивое впечатление что у вас чешутся руки что-то сделать, но при этом вы не совсем понимаете что именно и зачем.
У меня устойчивое впечатление что у вас чешутся руки что-то сделать, но при этом вы не совсем понимаете что именно и зачем.
23:49
libmdbx исторически происходит от LMDB, которая прежде всего "memory mapped database".
Т.е. memory mapped заложено в ДНК дизайна, из чего растёт как много плюсов, так и ряд минусов.
Т.е. memory mapped заложено в ДНК дизайна, из чего растёт как много плюсов, так и ряд минусов.
23:51
Так вот, достаточно нерационально пытаться сразу куда-то тащить движок хранения (которым и является libmdbx) не поняв для чего, зачем и как он сделан.
23:57
От libmdbx можно отрезать mmap или как-то залепить заглушками, при этом потеряется возможность работать с БД размером больше чем ОЗУ.
Подобным образом можно отрезать поддержку конкурентного доступа из нескольких процессов и/или тредов, и т.д.
Вопрос же в том что после этого останется, и чем оно будет лучше чем специализированный
Подобным образом можно отрезать поддержку конкурентного доступа из нескольких процессов и/или тредов, и т.д.
Вопрос же в том что после этого останется, и чем оно будет лучше чем специализированный
std::map<>.
👍
РЛ
YS
7 July 2022
KS
00:24
Klen Santakheza
в общем вы правы.
Л(
00:26
Леонид Юрьев (Leonid Yuriev)
In reply to this message
К слову, по аналогичному набору причин я не стал реализовывать поддержку https://vk.com/embox - не понятно для чего это нужно и кому.
С другой стороны, если будет нужно, т.е. когда будет задача - станет понятно как именно делать (что добавлять, а что отрезать).
С другой стороны, если будет нужно, т.е. когда будет задача - станет понятно как именно делать (что добавлять, а что отрезать).
KS
00:30
Klen Santakheza
в данный момент нет сценария использования. однако известно что подсистемы бортовых комплексов имеют свои локальные вычислители и нуждаются в хранилищах данных. при взаимодействии подсистем все это напоминает зоопарк. если бы на общей шине был бы девайс(узел или как хочешь его назови) с унифицированным api хранения доступа то это могло бы исключить кучу велосипелов. база данных как раз на мой взгляд могла бы выполнить эту роль
00:38
идея использовать unordered_map<> с обвязкой сверху в виде потоков с синхронизацией, буфером памяти с боку и блочной сериализацией/десертализацией внизу в страницы флеш микросхем тоже есть в голове. но я думал что в mdbx эту обвязка реализует и сделано это специалистами. мне только перепортить файловый ввод вывод и потоки. а тут еще это...
Л(
00:44
Леонид Юрьев (Leonid Yuriev)
Если вы будете действовать подобным образом, то просто добавите еще один велосипед к существующему зоопарку.
Примерно единственный путь = достаточно детально формализовать желаемый результат (цель), со всеми сопутствующими хотелками и ограничениями.
Называется это примерно "Управление требованиями", хотя есть еще масса вариантов.
Примерно единственный путь = достаточно детально формализовать желаемый результат (цель), со всеми сопутствующими хотелками и ограничениями.
Называется это примерно "Управление требованиями", хотя есть еще масса вариантов.
00:56
Суть же в том, что специалист (или группа) более-менее владеющий знаниями как в "прикладной" области (БВК, ВЭВМ, авионика, АСУ и т.п.) так и в "предметной" (базы данных) формирует описание "что надо".
После чего можно либо подбирать готовые решения (оценивать насколько они подходят), либо думать о разработке.
В реальной жизни это конечно отягощается массой факторов, в том числе сугубо социально-психологическими.
После чего можно либо подбирать готовые решения (оценивать насколько они подходят), либо думать о разработке.
В реальной жизни это конечно отягощается массой факторов, в том числе сугубо социально-психологическими.
KS
01:01
Klen Santakheza
это все да... но есть нюанс. формализовать желаемый результат не так то просто в реальной обстановке - акторов много и они зачастую хотят противоположного. поэтому я почему то пришел к следующей мысли - не спрашивать кто хочет какую игрушку и что она есть такое, а зная "акторов" создать нечто на мой взгляд рациональное, всунуть в песочницу и посмотреть кто захочет с этим поиграть. мы же все знаем что такое согласование ТЗ и прочие этапы "формализации желаемого результата", жизни не хватит, к томуже в моей сфере требования изменяются жизнью быстрее чем их согласовывают :). я рискую своим временем и своими ресурсами на создание железа - это мой выбор. для меня это все равно развитие.. обычно мое железо и код к нему покрывает много практических задач.
РЛ
11:49
Руслан Лайшев
Пардон коллега, но не очень понятный разговор, извиняюсь.
Л(
12:32
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Делать или нет = всё-таки ваше решение.
Со своей стороны я могу/буду давать советы и оказывать минимально-разумную помощь.
При необходимости вы можете сделать форк библиотеки и в дальнейшем его поддерживать.
А чтобы я принял ваши изменения необходимо следовать паре советов/принципов:
1. Изменение не должны затрагивать привязку/стыковку с уже поддерживаемыми ОС (Linux, *BSD, Solaris, Windows, MacOS, etc), в частности не требовать повторной проверки (сборки и прогона тестов).
2. Поддержка вашей платформы должны сводиться примерно к трем вещам:
- собственный скрипт сборки, Makefile и/или target, возможна опция CMake.
- подключение одного заголовочного файла посредством конструкции
Вам же я советую начать с исследования/наблюдения за работой libmdbx на linux посредством strace.
Т.е. сделать небольшую программу по мотивам предполагаемых сценариев использования и смотреть какие системные вызовы происходят во время её работы.
Со своей стороны я могу/буду давать советы и оказывать минимально-разумную помощь.
При необходимости вы можете сделать форк библиотеки и в дальнейшем его поддерживать.
А чтобы я принял ваши изменения необходимо следовать паре советов/принципов:
1. Изменение не должны затрагивать привязку/стыковку с уже поддерживаемыми ОС (Linux, *BSD, Solaris, Windows, MacOS, etc), в частности не требовать повторной проверки (сборки и прогона тестов).
2. Поддержка вашей платформы должны сводиться примерно к трем вещам:
- собственный скрипт сборки, Makefile и/или target, возможна опция CMake.
- подключение одного заголовочного файла посредством конструкции
#ifdef CUSTOM_OSAL_H \n #include CUSTOM_OSAL_H \n #endif
- опциональное определение заглушек для ненужных/замещаемых/переопределяемых функций, например #define mdbx_mapresize(x, y, z) (ENOSYS)
Соответственно, со своей стороны я обеспечу интеграцию эти изменений, в том числе обрамление ненужных/замещаемых/переопределяемых функций гардами #ifndef mdbx_foobar / #endif.Вам же я советую начать с исследования/наблюдения за работой libmdbx на linux посредством strace.
Т.е. сделать небольшую программу по мотивам предполагаемых сценариев использования и смотреть какие системные вызовы происходят во время её работы.
KS
13:22
Klen Santakheza
большое спасибо! все разумно. именно с обычного сценария я и начну - вчера появилась практическая задача, заказали написать прослойку между апи libmdbx и верхним кодом который генерит SQL ( в деталях я еще не разобрался ). по скольку я не специалист по БД мне будут помогать. в процессе как раз и получу знания о которых вы сказали. мои колеги по работе требуют внедрять libmdbx, это политический вопрос. еще раз спасибо!
Л(
13:26
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Ох, SQL тут похоже чтобы убедить вас отказаться от затеи ;)
Нем не менее, в этом контексте вам стоит посмотреть на https://gitflic.ru/project/erthink/libfpta.
Хотя-бы знать что такое есть и какие там возможности.
Нем не менее, в этом контексте вам стоит посмотреть на https://gitflic.ru/project/erthink/libfpta.
Хотя-бы знать что такое есть и какие там возможности.
Fynn invited Fynn
KS
17:28
Klen Santakheza
спасибо. это... fpta поинтереснее выглядит чтоб посмотреть "как оно". прекрасно, каждый день дает новые ощущения от нового увиденного. с железкой так просто не получится. но польза все равно будет!
9 July 2022
SC
00:57
Simon C.
When I iterate a cursor and update the current entry using
When iterating the cursor again (in the same or a later txn) about every third key is different than before. Is it not allowed to update the current entry with a different size?
I tried using the
The keys are different but still in the same order as before.
mdbx_cursor_put with differently sized data, I see very weird behavior.When iterating the cursor again (in the same or a later txn) about every third key is different than before. Is it not allowed to update the current entry with a different size?
I tried using the
MDBX_CURRENT flag but it makes no difference.The keys are different but still in the same order as before.
Л(
01:06
Леонид Юрьев (Leonid Yuriev)
In reply to this message
It looks strange, should work without such problems. Please prepare а minimalistic testcase, then tomorrow I will dig for.
👍
SC
SC
02:03
Simon C.
I can reproduce this issue 100% of the time in a real app but fail to recreate a simple example. Here is one of the resulting databases. It does not pass mdbx_chk. https://fromsmash.com/RwQgc8yrMM-dt
Л(
09:56
Леонид Юрьев (Leonid Yuriev)
In reply to this message
This DB is completely correct, considering that you use custom comparators.
So the
I assume that you have problems because of one or both of the bugs:
1. You messed up DBI handles while putting data.
2. The custom comparators used cannot provide ordering for all data (for instance, compares:
So the
-i options is required for mdbx_chk.I assume that you have problems because of one or both of the bugs:
1. You messed up DBI handles while putting data.
2. The custom comparators used cannot provide ordering for all data (for instance, compares:
1 < 2, 2 < 3, but 3 < 1).
SC
10:13
Simon C.
In reply to this message
I do NOT use custom comparators and never have.
I use the builtin comparator and 64-bit numbers as keys. But for some reason putting while iteraring the cursor screws up the keys. I noticed that the broken keys contain data of nearby entries
I use the builtin comparator and 64-bit numbers as keys. But for some reason putting while iteraring the cursor screws up the keys. I noticed that the broken keys contain data of nearby entries
Л(
10:46
Леонид Юрьев (Leonid Yuriev)
In reply to this message
The database has mixed keys like
As far as I understand from your words, you have not done such tricks.
So it could be the results of about two problems:
1. Corruption due to an libmdbx's bug.
2. Corruption due use/write of invalid pointers.
03;00;00;00;00;00;00;80 (8-byte sequence) and "attention" (string) with wrong order for builtin comparator.As far as I understand from your words, you have not done such tricks.
So it could be the results of about two problems:
1. Corruption due to an libmdbx's bug.
2. Corruption due use/write of invalid pointers.
SC
10:51
Simon C.
In reply to this message
Exactly! "attention" was part of previous data.
Shouldn't the db be protected from invalid pointers?
The issue only happens if a new key-value pair has a smaller size than the to-be-overridden one.
I'm still working on finding a reproducible example.
Shouldn't the db be protected from invalid pointers?
The issue only happens if a new key-value pair has a smaller size than the to-be-overridden one.
I'm still working on finding a reproducible example.
Л(
10:59
Леонид Юрьев (Leonid Yuriev)
To find out the reason I need a reproduction testcase.
Alternatively, I can recommend two options:
1. Try don't use the
Thus you can (likely) catch an invalid write to DB pages via bad pointers.
+ However, this does not allow detect an incorrect write to a temporary copies of the modified DB pages (aka dirty pages) in RAM.
2. Build libmdbx from actual
This enforces a lot of extra checking/verification and should reveal any corruption during DB updating.
Alternatively, I can recommend two options:
1. Try don't use the
MDBX_WRITEMAP mode and put at exactly one data item per transaction.Thus you can (likely) catch an invalid write to DB pages via bad pointers.
+ However, this does not allow detect an incorrect write to a temporary copies of the modified DB pages (aka dirty pages) in RAM.
2. Build libmdbx from actual
devel branch with -DMDBX_DEBUG=2 and don't alter debug flags by mdbx_setup_debug().This enforces a lot of extra checking/verification and should reveal any corruption during DB updating.
❤
SC
SC
11:01
Simon C.
In reply to this message
I don't use writemap but I'll try to find the issue! Thanks for your help.
Л(
SC
22:04
Simon C.
In reply to this message
Not yet. Didn't have a lot of time today. Doing more investigation now
10 July 2022
SC
00:34
Simon C.
Found the issue. Really stupid mistake on my end: I passed a key from a dirty page to
put(). Sorry!
👍
Л(
SC
01:47
Simon C.
In which cases can key/value returned by
mdbx_cursor_get be in a dirty page? Do I always have to check it in write txns using mdbx_is_dirty or are there some cases where a check is obsolete?
12 July 2022
Л(
13:47
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Sorry for the delay in responding.
For robustness you should expect any data accessible by retrieved pointers inside a read-write transactions could be invalidated by any subsequent call of a function changes data.
Actually any pointers retrieved from some sub-DB prior to its first modification during the current transaction will still be valid until the end of this transaction.
This is guaranteed/ensured by the fact that before the first modification, only pointers to data located in an already formed constant MVCC-snapshot can be returned, which is also available to read-transactions in other threads/processes.
But in all other cases, the retrieved pointers can points to data in modified pages (aka dirty pages), which can be overwritten during subsequent modifying operations.
For robustness you should expect any data accessible by retrieved pointers inside a read-write transactions could be invalidated by any subsequent call of a function changes data.
Actually any pointers retrieved from some sub-DB prior to its first modification during the current transaction will still be valid until the end of this transaction.
This is guaranteed/ensured by the fact that before the first modification, only pointers to data located in an already formed constant MVCC-snapshot can be returned, which is also available to read-transactions in other threads/processes.
But in all other cases, the retrieved pointers can points to data in modified pages (aka dirty pages), which can be overwritten during subsequent modifying operations.
SC
14:44
Simon C.
In reply to this message
Thanks a lot for this detailed explanation 🙏.
Can pointers from one sub db be invalidated by a put or delete operation to another sub db? Naively I would say no because a page cannot contain data of multiple dbs. Is this assumption correct?
Can pointers from one sub db be invalidated by a put or delete operation to another sub db? Naively I would say no because a page cannot contain data of multiple dbs. Is this assumption correct?
Л(
13 July 2022
AS
03:47
Alex Sharov
What can do if get MDBX_PAGE_FULL? (Probably just change size of our values, but do you need some debug info - it looks as some edge-case)
AS
04:05
Alex Sharov
Our app working on 4kb pagesize, but on 64kb pagesize some user got this error (we didn’t test much 64kb pagesize ourself).
Л(
10:57
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Ok, I got this.
I will run a long-stochastic test with 64K page size.
If this does not reveal the problem, then I will give you a modified version that will provide core-dump with additional logging in case of that error.
Nonetheless, you can just now add the
I will run a long-stochastic test with 64K page size.
If this does not reveal the problem, then I will give you a modified version that will provide core-dump with additional logging in case of that error.
Nonetheless, you can just now add the
abort() before the each of three return MDBX_PAGE_FULL .
Л(
23:39
Леонид Юрьев (Leonid Yuriev)
Просьба к обладателям последних AMD Zen3 и Apple M1 - мне нужна простая помощь в оценке нового алгоритма двоичного поиска для libmdbx:
Полученный вывод прислать ответом или в личное сообщение.
git clone https://gitflic.ru/project/erthink/bsearch-try.gitcd bsearch-trymakeПолученный вывод прислать ответом или в личное сообщение.
👍
AV
YS
MN
4
23:53
In reply to this message
Для Apple M1 данные получены и подтверждены - новый код примерно вдвое быстрее.
Всем спасибо!
Осталось добыть результаты для Zen3.
Всем спасибо!
Осталось добыть результаты для Zen3.
👍
A
AV
YS
SC
14 July 2022
KS
01:57
Klen Santakheza
gcc версия 13.0.0 20220712 (experimental) (Klen's GNU package (KGP) for target::x86_64-kgp-linux-gnu-znver3-avx2 @ host::x86_64-kgp-linux-gnu << TARAXACUM >>)
01:58
./bsearch-probe
Verify stdlib's bsearch() ...Done
Verify std::lower_bound<> ...Done
Verify bsearch_libmdbx() ...Done
Verify ly_bsearch_mini1() ...Done
Verify ly_bsearch_mini2() ...Done
Verify ly_bsearch_mini3() ...Done
Verify ly_bsearch_switch1() ...Done
Verify ly_bsearch_switch2() ...Done
Verify ly_bsearch_goto1() ...Done
Verify ly_bsearch_goto2() ...Done
Use 256 Fibonacci-like sizes 0..65536, average 25849.9
Benching null ...Done 0.016621 (9 loops, 3 stable, last diff 0.054%)
Benching stdlib's bsearch() ...Done 0.011833 (9 loops, 3 stable, last diff 0.007%)
Benching std::lower_bound<> ...Done 0.007168 (42 loops, 2 stable, last diff 0.134%)
Benching bsearch_libmdbx() ...Done 0.006590 (10 loops, 3 stable, last diff 0.039%)
Benching ly_bsearch_mini1() ...Done 0.016761 (10 loops, 3 stable, last diff 0.024%)
Benching ly_bsearch_mini2() ...Done 0.014380 (8 loops, 3 stable, last diff 0.008%)
Benching ly_bsearch_mini3() ...Done 0.014795 (6 loops, 3 stable, last diff 0.070%)
Benching ly_bsearch_switch1() ...Done 0.017393 (6 loops, 3 stable, last diff 0.087%)
Benching ly_bsearch_switch2() ...Done 0.017443 (8 loops, 3 stable, last diff 0.063%)
Benching ly_bsearch_goto1() ...Done 0.017430 (7 loops, 3 stable, last diff 0.004%)
Benching ly_bsearch_goto2() ...Done 0.018980 (6 loops, 3 stable, last diff 0.020%)
Verify stdlib's bsearch() ...Done
Verify std::lower_bound<> ...Done
Verify bsearch_libmdbx() ...Done
Verify ly_bsearch_mini1() ...Done
Verify ly_bsearch_mini2() ...Done
Verify ly_bsearch_mini3() ...Done
Verify ly_bsearch_switch1() ...Done
Verify ly_bsearch_switch2() ...Done
Verify ly_bsearch_goto1() ...Done
Verify ly_bsearch_goto2() ...Done
Use 256 Fibonacci-like sizes 0..65536, average 25849.9
Benching null ...Done 0.016621 (9 loops, 3 stable, last diff 0.054%)
Benching stdlib's bsearch() ...Done 0.011833 (9 loops, 3 stable, last diff 0.007%)
Benching std::lower_bound<> ...Done 0.007168 (42 loops, 2 stable, last diff 0.134%)
Benching bsearch_libmdbx() ...Done 0.006590 (10 loops, 3 stable, last diff 0.039%)
Benching ly_bsearch_mini1() ...Done 0.016761 (10 loops, 3 stable, last diff 0.024%)
Benching ly_bsearch_mini2() ...Done 0.014380 (8 loops, 3 stable, last diff 0.008%)
Benching ly_bsearch_mini3() ...Done 0.014795 (6 loops, 3 stable, last diff 0.070%)
Benching ly_bsearch_switch1() ...Done 0.017393 (6 loops, 3 stable, last diff 0.087%)
Benching ly_bsearch_switch2() ...Done 0.017443 (8 loops, 3 stable, last diff 0.063%)
Benching ly_bsearch_goto1() ...Done 0.017430 (7 loops, 3 stable, last diff 0.004%)
Benching ly_bsearch_goto2() ...Done 0.018980 (6 loops, 3 stable, last diff 0.020%)
02:01
на эльбрусе нужно?
Alisher Ashyrov invited Alisher Ashyrov
Л(
08:52
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Спасибо.
Но несколько неожиданные результаты для Zen3.
Предполагалось что cmov у AMD работает лучше чем у штеуда, и поэтому новый код будет существенно быстрее.
Оказалось наоборот.
Но несколько неожиданные результаты для Zen3.
Предполагалось что cmov у AMD работает лучше чем у штеуда, и поэтому новый код будет существенно быстрее.
Оказалось наоборот.
KS
09:51
Klen Santakheza
речь идет примерно про это? https://stackoverflow.com/questions/27136961/what-is-it-about-cmov-which-improves-cpu-pipeline-performance
👍
b
09:53
в каком кусочке кода Вы ожидали cmovxx, я посмотрю выходной асм. нужно разобратся. возможно что то не сработало и необходимо дать пинка компиллеру.
Л(
10:50
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Да, речь примерно про это, с поправкой ситуации на прошедшие 5-8 лет.
10:54
In reply to this message
Это всё многократно проверялось и подкручивалось. Код доведен до состояния когда его не портит ни один из более-менее актуальных компиляторов.
Отдельные странности есть только у lcc, но для него для проверки был сделан вариант через &&label и computed goto.
Отдельные странности есть только у lcc, но для него для проверки был сделан вариант через &&label и computed goto.
11:04
В целом получается так:
- новый single-branch bsearch быстрее на Эльбрус, Apple M1, новых штеудах, предположительно на всех не дохлых arm и risc-v с cmov, всех процессорах с длинным конвейером и без срекулятивного выполнения.
- старый код быстрее на новых AMD (что странно) и старых штеудах.
- новый single-branch bsearch быстрее на Эльбрус, Apple M1, новых штеудах, предположительно на всех не дохлых arm и risc-v с cmov, всех процессорах с длинным конвейером и без срекулятивного выполнения.
- старый код быстрее на новых AMD (что странно) и старых штеудах.
Deleted invited Deleted Account
Л(
16:45
Леонид Юрьев (Leonid Yuriev)
Ох, в бенчмарке был баг.
При перебазировании корректирующих коммитов я поломал соответствие между наполнением массива и значениями, которые потом в нём ищутся.
В результате почти все искомые значения были за его концом, а предсказатель переходов почти всегда угадывал.
Скорее всего это объясняет странные результаты на AMD Zen3.
При перебазировании корректирующих коммитов я поломал соответствие между наполнением массива и значениями, которые потом в нём ищутся.
В результате почти все искомые значения были за его концом, а предсказатель переходов почти всегда угадывал.
Скорее всего это объясняет странные результаты на AMD Zen3.
SC
Л(
16:48
Леонид Юрьев (Leonid Yuriev)
Поправленный бенчмарк показывает превосходство нового кода на всех платформах где есть cmov.
Точнее говоря, там где раньше был быстрее старый вариант (из-за угадывания переходов) теперь он медленнее.
Точнее говоря, там где раньше был быстрее старый вариант (из-за угадывания переходов) теперь он медленнее.
16:52
In reply to this message
It will be better to do this later, after I double-check everything and completely finish the benchmark.
Now this can be done out of curiosity.
However, the current (new) results are too good, which makes me suspect about some other bug.
Now this can be done out of curiosity.
However, the current (new) results are too good, which makes me suspect about some other bug.
👍
YS
SC
VS
17:30
Vladislav Shchapov
Леонид, у меня есть M1 Max, если надо, я могу провести на нем тесты.
Л(
17:31
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Будет замечательно, но чуть позже. Как только я до конца разберусь сбенчмарком.
Л(
23:02
Леонид Юрьев (Leonid Yuriev)
$ git clone https://gitflic.ru/project/erthink/bsearch-try.git
$ cd bsearch-try
$ make bench
На Xeon 5317, gcc 11.3:| Function | Time | Diff | Ratio |Т.е. ускорение чуть больше чем в 4 раза, и пока я не нашел причин не верить этим цифрам ;)
|:-------------------------|----------:|---------:|------:|
| ly_bsearch_mini1() | 0.014409 | -75.23% | 4.04 |
| ly_bsearch_goto2() | 0.014736 | -74.67% | 3.95 |
| ly_bsearch_mini3() | 0.014840 | -74.49% | 3.92 |
| ly_bsearch_goto1() | 0.015054 | -74.12% | 3.86 |
| ly_bsearch_mini2() | 0.015115 | -74.01% | 3.85 |
| ly_bsearch_switch2() | 0.020880 | -64.10% | 2.79 |
| ly_bsearch_switch1() | 0.024750 | -57.45% | 2.35 |
| bsearch_libmdbx() | 0.057715 | -0.78% | 1.01 |
| bsearch_linux() | 0.058085 | -0.14% | 1.00 |
| std::lower_bound<> | 0.058167 | +0.00% | 1.00 |
| bsearch_stdlib() | 0.059757 | +2.73% | 0.97 |
🔥
SC
VS
23:13
Vladislav Shchapov
In reply to this message
Apple clang version 13.1.6 (clang-1316.0.21.2.5)
Target: arm64-apple-darwin21.5.0
phprus@mbp bsearch-try % make bench
c++ -g -std=c++11 -Ofast -save-temps main.c++ -o bsearch-bench
./bsearch-bench
Verify bsearch_stdlib() ...Done
Verify bsearch_linux() ...Done
Verify std::lower_bound<> ...Done
Verify bsearch_libmdbx() ...Done
Verify ly_bsearch_mini1() ...Done
Verify ly_bsearch_mini2() ...Done
Verify ly_bsearch_mini3() ...Done
Verify ly_bsearch_switch1() ...Done
Verify ly_bsearch_switch2() ...Done
Verify ly_bsearch_goto1() ...Done
Verify ly_bsearch_goto2() ...Done
Parameters:
min size 0
max size 65536
size steps 111
step repetitions 9
number of probes 1000000
prng seed 42
Use 69 Fibonacci-like sizes 1..60697 of whole 111 steps: average 16024.6, root mean square 26127.4
Benching null ... 0.002648, 20 loops with 5 last stable, last diff 0.094%
Benching std::lower_bound<> ... 0.026678, 11 loops with 5 last stable, last diff 0.019%, position: avg 49.557%, min 0.0%, max 100.0%
Benching bsearch_libmdbx() ... 0.034313, 17 loops with 5 last stable, last diff 0.047%, position: avg 49.557%, min 0.0%, max 100.0%
Benching ly_bsearch_mini1() ... 0.011893, 42 loops with 0 last stable, last diff 0.220%, position: avg 49.557%, min 0.0%, max 100.0%
Benching ly_bsearch_mini2() ... 0.011563, 13 loops with 5 last stable, last diff 0.032%, position: avg 49.557%, min 0.0%, max 100.0%
Benching ly_bsearch_mini3() ... 0.011642, 9 loops with 5 last stable, last diff 0.070%, position: avg 49.557%, min 0.0%, max 100.0%
Benching ly_bsearch_switch1() ... 0.011389, 32 loops with 5 last stable, last diff 0.025%, position: avg 49.557%, min 0.0%, max 100.0%
Benching ly_bsearch_switch2() ... 0.011449, 24 loops with 5 last stable, last diff 0.014%, position: avg 49.557%, min 0.0%, max 100.0%
Benching ly_bsearch_goto1() ... 0.011080, 42 loops with 0 last stable, last diff 0.410%, position: avg 49.557%, min 0.0%, max 100.0%
Benching ly_bsearch_goto2() ... 0.011185, 12 loops with 5 last stable, last diff 0.036%, position: avg 49.557%, min 0.0%, max 100.0%
Benching bsearch_stdlib() ... 0.050448, 7 loops with 5 last stable, last diff 0.049%
Benching bsearch_linux() ... 0.031111, 7 loops with 5 last stable, last diff 0.013%
| Function | Time | Diff | Ratio |
|:-------------------------|----------:|---------:|------:|
| ly_bsearch_goto1() | 0.011080 | -58.47% | 2.41 |
| ly_bsearch_goto2() | 0.011185 | -58.07% | 2.39 |
| ly_bsearch_switch1() | 0.011389 | -57.31% | 2.34 |
| ly_bsearch_switch2() | 0.011449 | -57.08% | 2.33 |
| ly_bsearch_mini2() | 0.011563 | -56.66% | 2.31 |
| ly_bsearch_mini3() | 0.011642 | -56.36% | 2.29 |
| ly_bsearch_mini1() | 0.011893 | -55.42% | 2.24 |
| std::lower_bound<> | 0.026678 | +0.00% | 1.00 |
| bsearch_linux() | 0.031111 | +16.62% | 0.86 |
| bsearch_libmdbx() | 0.034313 | +28.62% | 0.78 |
| bsearch_stdlib() | 0.050448 | +89.10% | 0.53 |
phprus@mbp bsearch-try %
Target: arm64-apple-darwin21.5.0
phprus@mbp bsearch-try % make bench
c++ -g -std=c++11 -Ofast -save-temps main.c++ -o bsearch-bench
./bsearch-bench
Verify bsearch_stdlib() ...Done
Verify bsearch_linux() ...Done
Verify std::lower_bound<> ...Done
Verify bsearch_libmdbx() ...Done
Verify ly_bsearch_mini1() ...Done
Verify ly_bsearch_mini2() ...Done
Verify ly_bsearch_mini3() ...Done
Verify ly_bsearch_switch1() ...Done
Verify ly_bsearch_switch2() ...Done
Verify ly_bsearch_goto1() ...Done
Verify ly_bsearch_goto2() ...Done
Parameters:
min size 0
max size 65536
size steps 111
step repetitions 9
number of probes 1000000
prng seed 42
Use 69 Fibonacci-like sizes 1..60697 of whole 111 steps: average 16024.6, root mean square 26127.4
Benching null ... 0.002648, 20 loops with 5 last stable, last diff 0.094%
Benching std::lower_bound<> ... 0.026678, 11 loops with 5 last stable, last diff 0.019%, position: avg 49.557%, min 0.0%, max 100.0%
Benching bsearch_libmdbx() ... 0.034313, 17 loops with 5 last stable, last diff 0.047%, position: avg 49.557%, min 0.0%, max 100.0%
Benching ly_bsearch_mini1() ... 0.011893, 42 loops with 0 last stable, last diff 0.220%, position: avg 49.557%, min 0.0%, max 100.0%
Benching ly_bsearch_mini2() ... 0.011563, 13 loops with 5 last stable, last diff 0.032%, position: avg 49.557%, min 0.0%, max 100.0%
Benching ly_bsearch_mini3() ... 0.011642, 9 loops with 5 last stable, last diff 0.070%, position: avg 49.557%, min 0.0%, max 100.0%
Benching ly_bsearch_switch1() ... 0.011389, 32 loops with 5 last stable, last diff 0.025%, position: avg 49.557%, min 0.0%, max 100.0%
Benching ly_bsearch_switch2() ... 0.011449, 24 loops with 5 last stable, last diff 0.014%, position: avg 49.557%, min 0.0%, max 100.0%
Benching ly_bsearch_goto1() ... 0.011080, 42 loops with 0 last stable, last diff 0.410%, position: avg 49.557%, min 0.0%, max 100.0%
Benching ly_bsearch_goto2() ... 0.011185, 12 loops with 5 last stable, last diff 0.036%, position: avg 49.557%, min 0.0%, max 100.0%
Benching bsearch_stdlib() ... 0.050448, 7 loops with 5 last stable, last diff 0.049%
Benching bsearch_linux() ... 0.031111, 7 loops with 5 last stable, last diff 0.013%
| Function | Time | Diff | Ratio |
|:-------------------------|----------:|---------:|------:|
| ly_bsearch_goto1() | 0.011080 | -58.47% | 2.41 |
| ly_bsearch_goto2() | 0.011185 | -58.07% | 2.39 |
| ly_bsearch_switch1() | 0.011389 | -57.31% | 2.34 |
| ly_bsearch_switch2() | 0.011449 | -57.08% | 2.33 |
| ly_bsearch_mini2() | 0.011563 | -56.66% | 2.31 |
| ly_bsearch_mini3() | 0.011642 | -56.36% | 2.29 |
| ly_bsearch_mini1() | 0.011893 | -55.42% | 2.24 |
| std::lower_bound<> | 0.026678 | +0.00% | 1.00 |
| bsearch_linux() | 0.031111 | +16.62% | 0.86 |
| bsearch_libmdbx() | 0.034313 | +28.62% | 0.78 |
| bsearch_stdlib() | 0.050448 | +89.10% | 0.53 |
phprus@mbp bsearch-try %
23:15
Это на M1 Max. Ноутбук работает от сети.
Л(
15 July 2022
KS
01:35
Klen Santakheza
| Function | Time | Diff | Ratio |
|:-------------------------|----------:|---------:|------:|
| ly_bsearch_mini2() | 0.010240 | -74.16% | 3.87 |
| ly_bsearch_mini3() | 0.010485 | -73.55% | 3.78 |
| ly_bsearch_mini1() | 0.011075 | -72.06% | 3.58 |
| ly_bsearch_goto1() | 0.011185 | -71.78% | 3.54 |
| ly_bsearch_goto2() | 0.011935 | -69.89% | 3.32 |
| ly_bsearch_switch2() | 0.014809 | -62.64% | 2.68 |
| ly_bsearch_switch1() | 0.017753 | -55.21% | 2.23 |
| bsearch_linux() | 0.039478 | -0.39% | 1.00 |
| std::lower_bound<> | 0.039634 | +0.00% | 1.00 |
| bsearch_stdlib() | 0.040672 | +2.62% | 0.97 |
| bsearch_libmdbx() | 0.041325 | +4.27% | 0.96 |
|:-------------------------|----------:|---------:|------:|
| ly_bsearch_mini2() | 0.010240 | -74.16% | 3.87 |
| ly_bsearch_mini3() | 0.010485 | -73.55% | 3.78 |
| ly_bsearch_mini1() | 0.011075 | -72.06% | 3.58 |
| ly_bsearch_goto1() | 0.011185 | -71.78% | 3.54 |
| ly_bsearch_goto2() | 0.011935 | -69.89% | 3.32 |
| ly_bsearch_switch2() | 0.014809 | -62.64% | 2.68 |
| ly_bsearch_switch1() | 0.017753 | -55.21% | 2.23 |
| bsearch_linux() | 0.039478 | -0.39% | 1.00 |
| std::lower_bound<> | 0.039634 | +0.00% | 1.00 |
| bsearch_stdlib() | 0.040672 | +2.62% | 0.97 |
| bsearch_libmdbx() | 0.041325 | +4.27% | 0.96 |
01:36
gcc версия 13.0.0 20220712 (experimental) (Klen's GNU package (KGP) for target::x86_64-kgp-linux-gnu-znver3-avx2 @ host::x86_64-kgp-linux-gnu << TARAXACUM >>)
01:37
amd ryzen 7 5700g ( zen3 )
MN
01:40
Misha Nikanorov
для полноты картины - iMac M1:
Apple clang version 13.1.6 (clang-1316.0.21.2)
Target: arm64-apple-darwin21.3.0
c++ -g -std=c++11 -Ofast -save-temps main.c++ -o bsearch-bench
./bsearch-bench
Verify bsearch_stdlib() ...Done
Verify bsearch_linux() ...Done
Verify std::lower_bound<> ...Done
Verify bsearch_libmdbx() ...Done
Verify ly_bsearch_mini1() ...Done
Verify ly_bsearch_mini2() ...Done
Verify ly_bsearch_mini3() ...Done
Verify ly_bsearch_switch1() ...Done
Verify ly_bsearch_switch2() ...Done
Verify ly_bsearch_goto1() ...Done
Verify ly_bsearch_goto2() ...Done
Parameters:
min size 0
max size 65536
size steps 111
step repetitions 9
number of probes 1000000
prng seed 42
Use 69 Fibonacci-like sizes 1..60697 of whole 111 steps: average 16024.6, root mean square 26127.4
Benching null ... 0.002667, 42 loops with 3 last stable, last diff 0.800%
Benching std::lower_bound<> ... 0.026867, 15 loops with 5 last stable, last diff 0.027%, position: avg 49.557%, min 0.0%, max 100.0%
Benching bsearch_libmdbx() ... 0.034570, 9 loops with 5 last stable, last diff 0.028%, position: avg 49.557%, min 0.0%, max 100.0%
Benching ly_bsearch_mini1() ... 0.011992, 42 loops with 3 last stable, last diff 0.979%, position: avg 49.557%, min 0.0%, max 100.0%
Benching ly_bsearch_mini2() ... 0.011874, 8 loops with 5 last stable, last diff 0.034%, position: avg 49.557%, min 0.0%, max 100.0%
Benching ly_bsearch_mini3() ... 0.011906, 7 loops with 5 last stable, last diff 0.027%, position: avg 49.557%, min 0.0%, max 100.0%
Benching ly_bsearch_switch1() ... 0.011750, 9 loops with 5 last stable, last diff 0.007%, position: avg 49.557%, min 0.0%, max 100.0%
Benching ly_bsearch_switch2() ... 0.011649, 42 loops with 0 last stable, last diff 0.769%, position: avg 49.557%, min 0.0%, max 100.0%
Benching ly_bsearch_goto1() ... 0.011550, 8 loops with 5 last stable, last diff 0.007%, position: avg 49.557%, min 0.0%, max 100.0%
Benching ly_bsearch_goto2() ... 0.011236, 10 loops with 5 last stable, last diff 0.093%, position: avg 49.557%, min 0.0%, max 100.0%
Benching bsearch_stdlib() ... 0.050266, 12 loops with 5 last stable, last diff 0.063%
Benching bsearch_linux() ... 0.031230, 8 loops with 5 last stable, last diff 0.003%
| Function | Time | Diff | Ratio |
|:-------------------------|----------:|---------:|------:|
| ly_bsearch_goto2() | 0.011236 | -58.18% | 2.39 |
| ly_bsearch_goto1() | 0.011550 | -57.01% | 2.33 |
| ly_bsearch_switch2() | 0.011649 | -56.64% | 2.31 |
| ly_bsearch_switch1() | 0.011750 | -56.27% | 2.29 |
| ly_bsearch_mini2() | 0.011874 | -55.80% | 2.26 |
| ly_bsearch_mini3() | 0.011906 | -55.69% | 2.26 |
| ly_bsearch_mini1() | 0.011992 | -55.37% | 2.24 |
| std::lower_bound<> | 0.026867 | +0.00% | 1.00 |
| bsearch_linux() | 0.031230 | +16.24% | 0.86 |
| bsearch_libmdbx() | 0.034570 | +28.67% | 0.78 |
| bsearch_stdlib() | 0.050266 | +87.09% | 0.53 |
Apple clang version 13.1.6 (clang-1316.0.21.2)
Target: arm64-apple-darwin21.3.0
c++ -g -std=c++11 -Ofast -save-temps main.c++ -o bsearch-bench
./bsearch-bench
Verify bsearch_stdlib() ...Done
Verify bsearch_linux() ...Done
Verify std::lower_bound<> ...Done
Verify bsearch_libmdbx() ...Done
Verify ly_bsearch_mini1() ...Done
Verify ly_bsearch_mini2() ...Done
Verify ly_bsearch_mini3() ...Done
Verify ly_bsearch_switch1() ...Done
Verify ly_bsearch_switch2() ...Done
Verify ly_bsearch_goto1() ...Done
Verify ly_bsearch_goto2() ...Done
Parameters:
min size 0
max size 65536
size steps 111
step repetitions 9
number of probes 1000000
prng seed 42
Use 69 Fibonacci-like sizes 1..60697 of whole 111 steps: average 16024.6, root mean square 26127.4
Benching null ... 0.002667, 42 loops with 3 last stable, last diff 0.800%
Benching std::lower_bound<> ... 0.026867, 15 loops with 5 last stable, last diff 0.027%, position: avg 49.557%, min 0.0%, max 100.0%
Benching bsearch_libmdbx() ... 0.034570, 9 loops with 5 last stable, last diff 0.028%, position: avg 49.557%, min 0.0%, max 100.0%
Benching ly_bsearch_mini1() ... 0.011992, 42 loops with 3 last stable, last diff 0.979%, position: avg 49.557%, min 0.0%, max 100.0%
Benching ly_bsearch_mini2() ... 0.011874, 8 loops with 5 last stable, last diff 0.034%, position: avg 49.557%, min 0.0%, max 100.0%
Benching ly_bsearch_mini3() ... 0.011906, 7 loops with 5 last stable, last diff 0.027%, position: avg 49.557%, min 0.0%, max 100.0%
Benching ly_bsearch_switch1() ... 0.011750, 9 loops with 5 last stable, last diff 0.007%, position: avg 49.557%, min 0.0%, max 100.0%
Benching ly_bsearch_switch2() ... 0.011649, 42 loops with 0 last stable, last diff 0.769%, position: avg 49.557%, min 0.0%, max 100.0%
Benching ly_bsearch_goto1() ... 0.011550, 8 loops with 5 last stable, last diff 0.007%, position: avg 49.557%, min 0.0%, max 100.0%
Benching ly_bsearch_goto2() ... 0.011236, 10 loops with 5 last stable, last diff 0.093%, position: avg 49.557%, min 0.0%, max 100.0%
Benching bsearch_stdlib() ... 0.050266, 12 loops with 5 last stable, last diff 0.063%
Benching bsearch_linux() ... 0.031230, 8 loops with 5 last stable, last diff 0.003%
| Function | Time | Diff | Ratio |
|:-------------------------|----------:|---------:|------:|
| ly_bsearch_goto2() | 0.011236 | -58.18% | 2.39 |
| ly_bsearch_goto1() | 0.011550 | -57.01% | 2.33 |
| ly_bsearch_switch2() | 0.011649 | -56.64% | 2.31 |
| ly_bsearch_switch1() | 0.011750 | -56.27% | 2.29 |
| ly_bsearch_mini2() | 0.011874 | -55.80% | 2.26 |
| ly_bsearch_mini3() | 0.011906 | -55.69% | 2.26 |
| ly_bsearch_mini1() | 0.011992 | -55.37% | 2.24 |
| std::lower_bound<> | 0.026867 | +0.00% | 1.00 |
| bsearch_linux() | 0.031230 | +16.24% | 0.86 |
| bsearch_libmdbx() | 0.034570 | +28.67% | 0.78 |
| bsearch_stdlib() | 0.050266 | +87.09% | 0.53 |
Л(
11:26
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Спасибо.
Если есть возможность, то попробуйте посредством clang.
Примерно так
На штеудах clang до 5.0 геренирует быстрый код, а начиная с 5.0 внезапно отказывается от cmov внутри циклов.
Хочу попробовать выяснить почему...
Если есть возможность, то попробуйте посредством clang.
Примерно так
make clean && CXX=clang++ make bench.На штеудах clang до 5.0 геренирует быстрый код, а начиная с 5.0 внезапно отказывается от cmov внутри циклов.
Хочу попробовать выяснить почему...
MN
11:33
Misha Nikanorov
In reply to this message
clang++ -g -std=c++11 -Ofast -save-temps main.c++ -o bsearch-bench
./bsearch-bench
Verify bsearch_stdlib() ...Done
Verify bsearch_linux() ...Done
Verify std::lower_bound<> ...Done
Verify bsearch_libmdbx() ...Done
Verify ly_bsearch_mini1() ...Done
Verify ly_bsearch_mini2() ...Done
Verify ly_bsearch_mini3() ...Done
Verify ly_bsearch_switch1() ...Done
Verify ly_bsearch_switch2() ...Done
Verify ly_bsearch_goto1() ...Done
Verify ly_bsearch_goto2() ...Done
Parameters:
min size 0
max size 65536
size steps 111
step repetitions 9
number of probes 1000000
prng seed 42
Use 69 Fibonacci-like sizes 1..60697 of whole 111 steps: average 16024.6, root mean square 26127.4
Benching null ... 0.002665, 18 loops with 5 last stable, last diff 0.019%
Benching std::lower_bound<> ... 0.026964, 7 loops with 5 last stable, last diff 0.040%, position: avg 49.557%, min 0.0%, max 100.0%
Benching bsearch_libmdbx() ... 0.034423, 11 loops with 5 last stable, last diff 0.067%, position: avg 49.557%, min 0.0%, max 100.0%
Benching ly_bsearch_mini1() ... 0.011953, 13 loops with 5 last stable, last diff 0.017%, position: avg 49.557%, min 0.0%, max 100.0%
Benching ly_bsearch_mini2() ... 0.011572, 42 loops with 0 last stable, last diff 0.263%, position: avg 49.557%, min 0.0%, max 100.0%
Benching ly_bsearch_mini3() ... 0.011619, 8 loops with 5 last stable, last diff 0.091%, position: avg 49.557%, min 0.0%, max 100.0%
Benching ly_bsearch_switch1() ... 0.011450, 9 loops with 5 last stable, last diff 0.064%, position: avg 49.557%, min 0.0%, max 100.0%
Benching ly_bsearch_switch2() ... 0.011531, 9 loops with 5 last stable, last diff 0.067%, position: avg 49.557%, min 0.0%, max 100.0%
Benching ly_bsearch_goto1() ... 0.011173, 15 loops with 5 last stable, last diff 0.072%, position: avg 49.557%, min 0.0%, max 100.0%
Benching ly_bsearch_goto2() ... 0.011233, 11 loops with 5 last stable, last diff 0.011%, position: avg 49.557%, min 0.0%, max 100.0%
Benching bsearch_stdlib() ... 0.050114, 26 loops with 5 last stable, last diff 0.059%
Benching bsearch_linux() ... 0.031199, 11 loops with 5 last stable, last diff 0.081%
| Function | Time | Diff | Ratio |
|:-------------------------|----------:|---------:|------:|
| ly_bsearch_goto1() | 0.011173 | -58.56% | 2.41 |
| ly_bsearch_goto2() | 0.011233 | -58.34% | 2.40 |
| ly_bsearch_switch1() | 0.011450 | -57.54% | 2.35 |
| ly_bsearch_switch2() | 0.011531 | -57.24% | 2.34 |
| ly_bsearch_mini2() | 0.011572 | -57.08% | 2.33 |
| ly_bsearch_mini3() | 0.011619 | -56.91% | 2.32 |
| ly_bsearch_mini1() | 0.011953 | -55.67% | 2.26 |
| std::lower_bound<> | 0.026964 | +0.00% | 1.00 |
| bsearch_linux() | 0.031199 | +15.71% | 0.86 |
| bsearch_libmdbx() | 0.034423 | +27.66% | 0.78 |
| bsearch_stdlib() | 0.050114 | +85.86% | 0.54 |
./bsearch-bench
Verify bsearch_stdlib() ...Done
Verify bsearch_linux() ...Done
Verify std::lower_bound<> ...Done
Verify bsearch_libmdbx() ...Done
Verify ly_bsearch_mini1() ...Done
Verify ly_bsearch_mini2() ...Done
Verify ly_bsearch_mini3() ...Done
Verify ly_bsearch_switch1() ...Done
Verify ly_bsearch_switch2() ...Done
Verify ly_bsearch_goto1() ...Done
Verify ly_bsearch_goto2() ...Done
Parameters:
min size 0
max size 65536
size steps 111
step repetitions 9
number of probes 1000000
prng seed 42
Use 69 Fibonacci-like sizes 1..60697 of whole 111 steps: average 16024.6, root mean square 26127.4
Benching null ... 0.002665, 18 loops with 5 last stable, last diff 0.019%
Benching std::lower_bound<> ... 0.026964, 7 loops with 5 last stable, last diff 0.040%, position: avg 49.557%, min 0.0%, max 100.0%
Benching bsearch_libmdbx() ... 0.034423, 11 loops with 5 last stable, last diff 0.067%, position: avg 49.557%, min 0.0%, max 100.0%
Benching ly_bsearch_mini1() ... 0.011953, 13 loops with 5 last stable, last diff 0.017%, position: avg 49.557%, min 0.0%, max 100.0%
Benching ly_bsearch_mini2() ... 0.011572, 42 loops with 0 last stable, last diff 0.263%, position: avg 49.557%, min 0.0%, max 100.0%
Benching ly_bsearch_mini3() ... 0.011619, 8 loops with 5 last stable, last diff 0.091%, position: avg 49.557%, min 0.0%, max 100.0%
Benching ly_bsearch_switch1() ... 0.011450, 9 loops with 5 last stable, last diff 0.064%, position: avg 49.557%, min 0.0%, max 100.0%
Benching ly_bsearch_switch2() ... 0.011531, 9 loops with 5 last stable, last diff 0.067%, position: avg 49.557%, min 0.0%, max 100.0%
Benching ly_bsearch_goto1() ... 0.011173, 15 loops with 5 last stable, last diff 0.072%, position: avg 49.557%, min 0.0%, max 100.0%
Benching ly_bsearch_goto2() ... 0.011233, 11 loops with 5 last stable, last diff 0.011%, position: avg 49.557%, min 0.0%, max 100.0%
Benching bsearch_stdlib() ... 0.050114, 26 loops with 5 last stable, last diff 0.059%
Benching bsearch_linux() ... 0.031199, 11 loops with 5 last stable, last diff 0.081%
| Function | Time | Diff | Ratio |
|:-------------------------|----------:|---------:|------:|
| ly_bsearch_goto1() | 0.011173 | -58.56% | 2.41 |
| ly_bsearch_goto2() | 0.011233 | -58.34% | 2.40 |
| ly_bsearch_switch1() | 0.011450 | -57.54% | 2.35 |
| ly_bsearch_switch2() | 0.011531 | -57.24% | 2.34 |
| ly_bsearch_mini2() | 0.011572 | -57.08% | 2.33 |
| ly_bsearch_mini3() | 0.011619 | -56.91% | 2.32 |
| ly_bsearch_mini1() | 0.011953 | -55.67% | 2.26 |
| std::lower_bound<> | 0.026964 | +0.00% | 1.00 |
| bsearch_linux() | 0.031199 | +15.71% | 0.86 |
| bsearch_libmdbx() | 0.034423 | +27.66% | 0.78 |
| bsearch_stdlib() | 0.050114 | +85.86% | 0.54 |
Л(
11:40
Леонид Юрьев (Leonid Yuriev)
In reply to this message
С M1 (и вроде-бы всеми aarch64) проблем нет - clang генерирует нормальный код, и gcc (но перепроверю).
Странности на x86_64, где последние версии clang внезапно отказываются от cmov.
Причем даже с опцией
Поэтому хочется понять как ведет себя код из-под clang на последних ядрах AMD.
Странности на x86_64, где последние версии clang внезапно отказываются от cmov.
Причем даже с опцией
-march=native на последних ядрах интел, где более-менее починили тормознутость cmov.Поэтому хочется понять как ведет себя код из-под clang на последних ядрах AMD.
MN
11:44
Misha Nikanorov
In reply to this message
а, ясно…тут помочь не смогу, живу в мире без амд, к сожалению…пачка машин на интеле, m1 и полумёртвый i9 на макбуке (решение взять - самый мой большой провал)
KS
12:02
Klen Santakheza
щас.. подсоберу llvm и попробую. посмотрим в асм что там будет. результаты с m1 еще раз подтверждают что x86 унылая печаль по сравнению с другими. у меня есть машинка на 64 битном risc-v. нитересно на нем будет запустить и проверить основные алгоритмы.
Л(
12:23
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Ну на всякий, для объективности Xeon 5317 и i7-11700T показывают те же цифры что и M1, т.е. проблема в clang как компиляторе.
А на riscv64 было-бы любопытно посмотреть, но неопределенностей еще больше:
- cmov есть только в
- если cmov есть, то не понятно с какими latency и throughput;
- если компилятор знает о наличии
- не проглючит ли clang с cmov также как на x86, даже имея точные данные о latency и throughput.
но любопытно...
А на riscv64 было-бы любопытно посмотреть, но неопределенностей еще больше:
- cmov есть только в
B-extensions;- если cmov есть, то не понятно с какими latency и throughput;
- если компилятор знает о наличии
B-extensions, то что он знает о latency и throughput...- не проглючит ли clang с cmov также как на x86, даже имея точные данные о latency и throughput.
но любопытно...
👍
YS
KS
15:32
Klen Santakheza
clang++ -g -std=c++11 -march=znver2 -mtune=znver2 -Ofast -save-temps main.c++ -o bsearch-bench
15:34
| Function | Time | Diff | Ratio |
|:-------------------------|----------:|---------:|------:|
| bsearch_libmdbx() | 0.025047 | -36.72% | 1.58 |
| bsearch_linux() | 0.031008 | -21.66% | 1.28 |
| ly_bsearch_goto1() | 0.033406 | -15.60% | 1.18 |
| ly_bsearch_goto2() | 0.034593 | -12.60% | 1.14 |
| ly_bsearch_switch1() | 0.036891 | -6.80% | 1.07 |
| ly_bsearch_switch2() | 0.038642 | -2.37% | 1.02 |
| ly_bsearch_mini1() | 0.039108 | -1.20% | 1.01 |
| bsearch_stdlib() | 0.039384 | -0.50% | 1.01 |
| std::lower_bound<> | 0.039582 | +0.00% | 1.00 |
| ly_bsearch_mini2() | 0.039645 | +0.16% | 1.00 |
| ly_bsearch_mini3() | 0.040073 | +1.24% | 0.99 |
|:-------------------------|----------:|---------:|------:|
| bsearch_libmdbx() | 0.025047 | -36.72% | 1.58 |
| bsearch_linux() | 0.031008 | -21.66% | 1.28 |
| ly_bsearch_goto1() | 0.033406 | -15.60% | 1.18 |
| ly_bsearch_goto2() | 0.034593 | -12.60% | 1.14 |
| ly_bsearch_switch1() | 0.036891 | -6.80% | 1.07 |
| ly_bsearch_switch2() | 0.038642 | -2.37% | 1.02 |
| ly_bsearch_mini1() | 0.039108 | -1.20% | 1.01 |
| bsearch_stdlib() | 0.039384 | -0.50% | 1.01 |
| std::lower_bound<> | 0.039582 | +0.00% | 1.00 |
| ly_bsearch_mini2() | 0.039645 | +0.16% | 1.00 |
| ly_bsearch_mini3() | 0.040073 | +1.24% | 0.99 |
15:36
какието очень странные результаты. я бы не стал им сразу доверять. llvm( не собраный мной а был в бинарях ) не сильно новый и почему то не знает zen3, поэтому собрано с ключами zver2.
15:37
clang version 11.1.0
Л(
15:58
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Спасибо.
Результаты соответствуют наблюдаемому на штеудах.
Я по-быстрому проверил поведение старых версий и заметил что замедление начинается 5.0.
При этом мельком глянул генерируемый код = clang внезапно и необъяснимо отказывается от cmov в пользу переходов в самом удобном для cmov месте.
Почему пока не выяснял (некогда) и в compiler explorer подобного не видел, насколько помню.
Результаты соответствуют наблюдаемому на штеудах.
Я по-быстрому проверил поведение старых версий и заметил что замедление начинается 5.0.
При этом мельком глянул генерируемый код = clang внезапно и необъяснимо отказывается от cmov в пользу переходов в самом удобном для cmov месте.
Почему пока не выяснял (некогда) и в compiler explorer подобного не видел, насколько помню.
Л(
21:12
Леонид Юрьев (Leonid Yuriev)
С lang разобрался.
Собственно (мне) было не понятно как я пропустил проблему, ибо с самого начала метился в cmov.
Короче, в clang явно какой-то глупый баг, наподобие пропущенного
Упрощенно:
- если внутри цикла две зависимости от результата сравнения. то clang использует две CMOV-инструкции.
- если же зависимость одна, то вместо одной CMOV используются переходы.
Т.е. логика ровно обратная, ибо если одна CMOV дороже переходов, то две точно еще дороже.
А если CMOV не дороже переходов, то вообще тут незачем использовать переходы (ибо загрязнение кэша предсказателя).
Соответственно, я пропустил проблему, ибо считал что после упрощения кода (уменьшения зависимостей) у компилятора не будет причины заметить CMOV переходами.
С gcc была именно эта обратная проблема - если больше одной зависимости он задействует условные переходы вместо двух (или более) CMOV, что полностью логично.
Сейчас для clang добавлен workaround = добавление второй зависимости, но так чтобы это приносило хоть какую-то пользу.
Собственно (мне) было не понятно как я пропустил проблему, ибо с самого начала метился в cmov.
Короче, в clang явно какой-то глупый баг, наподобие пропущенного
! в условии.Упрощенно:
- если внутри цикла две зависимости от результата сравнения. то clang использует две CMOV-инструкции.
- если же зависимость одна, то вместо одной CMOV используются переходы.
Т.е. логика ровно обратная, ибо если одна CMOV дороже переходов, то две точно еще дороже.
А если CMOV не дороже переходов, то вообще тут незачем использовать переходы (ибо загрязнение кэша предсказателя).
Соответственно, я пропустил проблему, ибо считал что после упрощения кода (уменьшения зависимостей) у компилятора не будет причины заметить CMOV переходами.
С gcc была именно эта обратная проблема - если больше одной зависимости он задействует условные переходы вместо двух (или более) CMOV, что полностью логично.
Сейчас для clang добавлен workaround = добавление второй зависимости, но так чтобы это приносило хоть какую-то пользу.
👍
АМ
VS
4
👏
AV
2
16 July 2022
KS
19:20
Klen Santakheza
х86 он такой. инструкций много а толку мало.
17 July 2022
KS
17:11
Klen Santakheza
подсобрал крайний llvm из транка. заставить генерить условное копирование да... никак не удается. скорее всего есть траблы (по мнению кодогенератора) с конвейером и при втыкании zver3 эта инструкция прописана с высокой стоймостью. поведение одинаково для gcc13 и clang15, налицо какая то система или заговор!. есть особенность. бинарь из под clang15 выполняет тест bsearch_libmdbx быстрее чем из под gcc ( 0.026056 против 0.043302 ), однако тест ly_bl_mini1 наглухо отвисает несмотря на удачный проход верификации. асм код в обоих вариантах практически идентичен. откуда разница в два раза я не понимаю.
17:12
что то живущее снаружи в Вашем коде еще промеряется. разные libc/libstdc++ ?
Л(
18:14
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Минут 10-15 назад я пролил в бенчмарк примерно итоговый workaround для clang.
В нагрузку там только одна лишняя инструкция, которая зависит от сравнения, но не генерирует зависимостей по данным.
Поэтому pipeline должен её проглатывать без дополнительных задержек.
Этот workaround отрабатывает на всех "плохих" версиях clang (от 5.0 до trunk).
gcc 13 еще не существует. Если говорить про trunk, то судя по compiler explorer никаких проблем там нет.
__asm __volatile("" : "+r"(foo bar for dependency) : "r"(comparison result));В нагрузку там только одна лишняя инструкция, которая зависит от сравнения, но не генерирует зависимостей по данным.
Поэтому pipeline должен её проглатывать без дополнительных задержек.
Этот workaround отрабатывает на всех "плохих" версиях clang (от 5.0 до trunk).
gcc 13 еще не существует. Если говорить про trunk, то судя по compiler explorer никаких проблем там нет.
18:16
In reply to this message
Для сравнения замеряются
Какие именно зависит исключительно от системы, на которой выполняется сборка.
bsearch() и std::lower_bound<> (собственно см исходники).Какие именно зависит исключительно от системы, на которой выполняется сборка.
Л(
19:37
Леонид Юрьев (Leonid Yuriev)
Но c clang всё равно какие-то странности, если не сказать что непотребство.
clang-14 с
clang-14 с
-march=native| Function | Time | Diff | Ratio |clang-14 без
|:-----------------|----------:|---------:|------:|
| ly_bl_switch1 | 0.013019 | -72.12% | 3.59 |
| ly_bl_goto1 | 0.013075 | -72.00% | 3.57 |
| ly_bl_mini2 | 0.013100 | -71.95% | 3.56 |
| ly_bl_switch2 | 0.013126 | -71.89% | 3.56 |
| ly_bl_goto2 | 0.013165 | -71.81% | 3.55 |
| ly_bl_mini0 | 0.013223 | -71.68% | 3.53 |
| ly_bl_mini1 | 0.013248 | -71.63% | 3.52 |
| ly_bl_clz_switch | 0.013365 | -71.38% | 3.49 |
| ly_bl_mini3 | 0.013588 | -70.90% | 3.44 |
| ly_bl_clz_goto | 0.013668 | -70.73% | 3.42 |
| bsearch_libmdbx | 0.028976 | -37.94% | 1.61 |
| bsearch_linux | 0.030456 | -34.78% | 1.53 |
| std::lower_bound | 0.046694 | +0.00% | 1.00 |
| bsearch_stdlib | 0.047566 | +1.87% | 0.98 |
-march=native| Function | Time | Diff | Ratio |gcc-12 без
|:-----------------|----------:|---------:|------:|
| ly_bl_mini0 | 0.023544 | -23.57% | 1.31 |
| ly_bl_mini1 | 0.025137 | -18.40% | 1.23 |
| ly_bl_mini2 | 0.025902 | -15.91% | 1.19 |
| ly_bl_mini3 | 0.026880 | -12.74% | 1.15 |
| ly_bl_goto1 | 0.028402 | -7.80% | 1.08 |
| ly_bl_switch2 | 0.028410 | -7.77% | 1.08 |
| ly_bl_switch1 | 0.028461 | -7.61% | 1.08 |
| ly_bl_goto2 | 0.028463 | -7.60% | 1.08 |
| ly_bl_clz_goto | 0.028486 | -7.53% | 1.08 |
| ly_bl_clz_switch | 0.029184 | -5.26% | 1.06 |
| std::lower_bound | 0.030805 | +0.00% | 1.00 |
| bsearch_libmdbx | 0.034632 | +12.43% | 0.89 |
| bsearch_linux | 0.036243 | +17.66% | 0.85 |
| bsearch_stdlib | 0.048673 | +58.01% | 0.63 |
-march=native| Function | Time | Diff | Ratio |
|:-----------------|----------:|---------:|------:|
| ly_bl_goto1 | 0.012665 | -75.52% | 4.08 |
| ly_bl_mini1 | 0.012697 | -75.45% | 4.07 |
| ly_bl_mini2 | 0.012832 | -75.19% | 4.03 |
| ly_bl_goto2 | 0.012840 | -75.18% | 4.03 |
| ly_bl_mini0 | 0.012950 | -74.96% | 3.99 |
| ly_bl_mini3 | 0.013380 | -74.13% | 3.87 |
| ly_bl_clz_goto | 0.013479 | -73.94% | 3.84 |
| ly_bl_switch2 | 0.018024 | -65.16% | 2.87 |
| ly_bl_switch1 | 0.020905 | -59.59% | 2.47 |
| ly_bl_clz_switch | 0.021961 | -57.54% | 2.36 |
| bsearch_linux | 0.048620 | -6.01% | 1.06 |
| bsearch_libmdbx | 0.049127 | -5.03% | 1.05 |
| bsearch_stdlib | 0.050831 | -1.73% | 1.02 |
| std::lower_bound | 0.051727 | +0.00% | 1.00 |
19:43
Т.е. без
С добавлением же
-march=native clang генерирует чуть-ли не вдвое более медленный код, причем для функций где сложно что-либо испортить.С добавлением же
-march=native и костылем __asm __volatile приближается к GCC, но при этом в полтора раза замедляет штатную реализацию std::lower_bound<>.
18 July 2022
Giulio invited Giulio
G
15:48
Giulio
Hello there, i am not russian speaking so I will post in English
👍
Л(
15:49
What does mdbx_cursor_get: no data avaiable means?
Л(
16:11
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Basically, it is a soft error, means you doing some extra useless get/move action.
For instance,
For instance,
mdbx_cursor_get(MDBX_CURRENT) for non-positioned cursor, i.e. for a cursor which not positioned to the any entry.
G
16:23
Giulio
In reply to this message
are there any other possibilities of it happening outside of that?
Л(
16:30
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Then it will look like some kind of bug in libmdbx.
G
16:38
Giulio
mmh okay
i
17:31
igors
у меня есть вопросик: на x86 пытаюсь из 4 потоков параллельно читать данные(данных не много - 100 пар ключ значение типа string), в каждом потоке примерно следующее - 1. mdbx_env_open("C:\test\mdbx-test.db"....); 2. mdbx_txn_begin(MDBX_RDONLY); 3. mdbx_dbi_open("Test"); 4. mdbx_get_ex. То есть по сути не шарю одну и ту же "env" переменную между разными потоками, а в каждом потоку вызываю "mdbx_env_open". И у меня на третьем параллельном вызове mdbx_env_open кидается системная ошибка - ERROR_NOT_ENOUGH_MEMORY(0x8). на x64 пробовал - 10, 20 потоков - всё работает без проблем. @erthink - это ожидаемое поведение для x86?
Л(
17:51
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Хм, странно что библиотека дала вам открыть БД из одного процесса несколько раз.
Можно по-подробнее что именно вы делаете.
Можно по-подробнее что именно вы делаете.
i
18:46
igors
извините немного запутал - так же в каждом потоке перед mdbx_env_open делаю mdbx_env_create
Л(
18:58
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Это тоже понятно.
Но всё равно вы должны получить ошибку 11, либо
Но всё равно вы должны получить ошибку 11, либо
MDBX_BUSY.
i
18:58
igors
Щл
Л(
19:10
Леонид Юрьев (Leonid Yuriev)
Ладно давайте разделим проблему на три:
1. По умолчанию (без использования
Если тот предохранитель не сработал в вашем случае (на всякий случая я его только-что проверил), то это либо какой-то скрытый баг, либо еще какие-то серьезные проблемы.
2. Если вы всё-таки используете
3. Открывая одну БД несколько раз вы несколько раз отображаете её файл в адресное пространство одного процесса, т.е. расходуете как PTE, так и само адресное пространство.
Вполне вероятно что на 32-битной системе у вас просто не хватает адресного пространства, чтобы несколько раз отобразить файл в память.
В том числе ядро может не разрешить одному процессу использовать слишком много PTE.
1. По умолчанию (без использования
MDBX_DBG_LEGACY_MULTIOPEN) библиотека не должна позволить вам открыть одну БД (один и тот-же файл) дважды в одном процессе.Если тот предохранитель не сработал в вашем случае (на всякий случая я его только-что проверил), то это либо какой-то скрытый баг, либо еще какие-то серьезные проблемы.
2. Если вы всё-таки используете
MDBX_DBG_LEGACY_MULTIOPEN, то толжны полностью представлять последствия (розетка + пальцы = ...).3. Открывая одну БД несколько раз вы несколько раз отображаете её файл в адресное пространство одного процесса, т.е. расходуете как PTE, так и само адресное пространство.
Вполне вероятно что на 32-битной системе у вас просто не хватает адресного пространства, чтобы несколько раз отобразить файл в память.
В том числе ядро может не разрешить одному процессу использовать слишком много PTE.
i
19:17
igors
MDBX_DB_LEGACY_MULTIOPEN я его явно не сетал, ща ещё раз проверю
Л(
20:03
Леонид Юрьев (Leonid Yuriev)
In reply to this message
А какая у вас версия, какой коммит или что в mdbx_version ?
i
20:22
igors
0.11.8
i
20:43
igors
на маке я получаю PANIC
Л(
20:44
Леонид Юрьев (Leonid Yuriev)
MDBX_PANIC ?
i
20:47
igors
да
20:49
а вот на винде не наблюдается такое поведение, сейчас попробую ещё раз собрать
i
22:24
igors
на винде мне позволяет открыть одну БД (один и тот-же файл) дважды в одном процессе.
22:26
я так понимаю что
MDBX_DB_LEGACY_MULTIOPEN можно только явно засетать через mdbx_setup_debug?
Л(
22:26
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Похоже есть баг в контроле двойного открытия - как минимум на винде, и похоже что-то не так на маке.
Буду смотреть...
В остальном же ваша проблема (скорее всего) объясняется третьим пунктом (см выше).
Буду смотреть...
В остальном же ваша проблема (скорее всего) объясняется третьим пунктом (см выше).
i
22:34
igors
я сразу уточню что для винды я использовал visula studio 2022, хотя в инструкции у вас написано 2019. Но мне кажется что это ни на что не влияет.
Л(
19 July 2022
SC
16:01
Simon C.
I don't quite understand
MDBX_CP_FORCE_DYNAMIC_SIZE. What does "resisable" mean in this context? If the copied database is not resizable can I not write to it?
Л(
16:23
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Just forces "resizeable" (min_size < max_size) for the geometry of a copy.
❤
SC
i
17:45
igors
на андроиде - MDBX_PANIC при повторном открытии, как на маке.
Л(
17:46
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Принято.
Спасибо за информацию.
Буду смотреть, но не сегодня.
Спасибо за информацию.
Буду смотреть, но не сегодня.
M
19:38
Mark
Hey gitflic.ru is asking for a username/password to do a git pull now. Has something changed? Is that the current place to pull the repo since the GitHub fiasco?
Л(
19:56
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Seems this is a bug in the fresh (today) release of Gitflic engine.
Try https://abf.io/erthink/libmdbx.git as a backup.
Try https://abf.io/erthink/libmdbx.git as a backup.
M
19:57
Mark
I've tried that one in the past. Had issues getting to it from my network. Does gitflic plan to fix do you know?
Л(
19:59
Леонид Юрьев (Leonid Yuriev)
In reply to this message
I am got a similar problem and wrote to support 5 minutes ago.
Aлексей invited Aлексей
Nekto invited Nekto
20 July 2022
Л(
10:43
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Gitflic's support confirmed that is a bug which affected only a few repos, and scheduled it to fix.
👍
SC
Aleksandr Borgardt invited Aleksandr Borgardt
Л(
M
17:19
Mark
Works for me
👍
Л(
23 July 2022
Tim invited Tim
28 July 2022
i
13:51
igors
вопросик. Чистый env(создал его только что), первая транзакция - это Read транзакция, в таком случае mdbx_dbi_open(c параметром MDBX_CREATE) - возвращает MDBX_EACCESS(Permission denied). Если же первая транзакция - это Write транзакция то всё работает без ошибок. @erthink - это ожидаемое поведение?
Л(
13:54
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Так вроде-бы логично что в read-only транзакции вы получаете EACCESS при попытке создать таблицу.
i
13:54
igors
согласен
AA
15:00
Alexey Akhunov
Получили первые сигналы о применении BigFoot - пока положительные
15:02
Релиз был в воскресенье, время коммитов сократилось у пользователей, которые это очень просили
Л(
15:03
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Это хорошо, но не спешите - там были баги снижающие производительность.
Надеюсь к понедельнику выкачу новый devel (как раздам долги, в том числе @k0tb9g9m0t).
Надеюсь к понедельнику выкачу новый devel (как раздам долги, в том числе @k0tb9g9m0t).
AS
15:44
Alex Sharov
In reply to this message
Спс. Мы тестили долго перф этой ветки - нас все устроило.
Л(
15:50
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Да, да. Это я к тому, что кроме Bigfoot затеял ещё несколько откладываем допеределок, включая поиск последовательностей (на котором у вас раньше тормозило).
Но пришлось приостановить всё это из-за продуктового бага...
Но пришлось приостановить всё это из-за продуктового бага...
16:00
In reply to this message
Как закончу нужно будет проверить насколько оправдан у вас "накопитель" в std::map - вполне может оказаться что теперь одна большая транзакция будет выгоднее, в частности из-за LRU-спиллинга (очень хорош с прошлого года) и ускоренного на днях поиска.
@ledgerwatch, FYI.
@ledgerwatch, FYI.
AS
16:08
Alex Sharov
Кстати может быть, последние эксперименты были с «полу-полными» транзакциями чтобы на гарантированный unspill не попадать.
Л(
16:53
Леонид Юрьев (Leonid Yuriev)
In reply to this message
По-хорошему нужно делать фитнес/шейпинг под задаваемый объем памяти (по-умолчанию = размер_ОЗУ*3/4 - 4Гб).
На бумаге решать сколько-куда пойдет, затем реализовывать это в политиках и вочдогах, в том числе задавать лимиты для libmdbx и/или переходить на WRITEMAP.
На бумаге решать сколько-куда пойдет, затем реализовывать это в политиках и вочдогах, в том числе задавать лимиты для libmdbx и/или переходить на WRITEMAP.
G
19:18
Giulio
hello, I will write in English, what happens if we call mdbx_reset but not mdbx_renew after?
Л(
19:26
Леонид Юрьев (Leonid Yuriev)
In reply to this message
nothing;
but later you should call
but later you should call
mdbx_txn_abort() to avoid memory leak(s).
👍
G
G
20:10
Giulio
what is the main difference beetwen Reset and Renew
20:13
I am using Reset but it does seem to reset anything
20:15
Not sure if it is a problem with the go interfaces or what else
Л(
20:20
Леонид Юрьев (Leonid Yuriev)
These are historical API names from LMDB.
Did you read the docs at https://libmdbx.dqdkfa.ru?
Please do it and help me clarify API descriptions where you are doubt.
Did you read the docs at https://libmdbx.dqdkfa.ru?
Please do it and help me clarify API descriptions where you are doubt.
G
20:35
Giulio
mdbx_tx_renew is historical? i did not know that
Л(
2 August 2022
Л(
13:36
Леонид Юрьев (Leonid Yuriev)
libmdbx 0.11.9 (Чирчик-1992)
https://gitflic.ru/project/erthink/libmdbx/release/4742671e-a691-45a5-88de-c6341f762d0b
https://gitflic.ru/project/erthink/libmdbx/release/4742671e-a691-45a5-88de-c6341f762d0b
8 August 2022
SC
11:26
Simon C.
When I upgrade from 0.11.8 to 0.11.9 I get the following error during iOS release builds (debug builds work fine)
Any idea what could cause this?
Undefined symbols for architecture arm64:
"___cxa_thread_atexit", referenced from:
_thread_rthc_set in libisar.a(mdbx.o)
ld: symbol(s) not found for architecture arm64
clang: error: linker command failed with exit code 1 (use -v to see invocation)Any idea what could cause this?
Л(
12:01
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Hmm.
No anything changes around
Also known a few success builds on macOS with Xcode 13.2.1 and AppleClang (13.0.0.13000029).
So seem this is Apple's compatibility issue.
Nonetheless I will check this when got a time.
No anything changes around
__cxa_thread_atexit since v0.11.8 (you can check this by git blame src/core.c and search for cxa_thread_atexit).Also known a few success builds on macOS with Xcode 13.2.1 and AppleClang (13.0.0.13000029).
So seem this is Apple's compatibility issue.
Nonetheless I will check this when got a time.
❤
SC
Л(
12:19
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Check your definition of
MAC_OS_X_VERSION_MIN_REQUIRED.
SC
12:20
Simon C.
It's an iOS build. I don't think this exists
Л(
SC
12:26
Simon C.
They're similar but not the same. Do you mean this:
-miphoneos-version-min=10.0
Л(
12:43
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Oh, there are a lot of Apple's marketing bullshit that lead confusion.
Briefly:
- libmdbx needs to use "Thread Local Storage Destructors";
- the
- but since
Briefly:
- libmdbx needs to use "Thread Local Storage Destructors";
- the
__cxa_thread_atexit() should be preferred when available, because it accepts a DSO-anchor to avoid unload DSO/DLL before all destructors are complete;- but since
MAC_OS_X_VERSION_MIN_REQUIRED >= MAC_OS_X_VERSION_10_7 only the _tlv_atexit() is available on macOS.
12:44
In reply to this message
So without
MAC_OS_X_VERSION_MIN_REQUIRED you will get error "The <AvailabilityMacros.h> should be included and MAC_OS_X_VERSION_MIN_REQUIRED must be defined" during libmdbx build.
SC
12:46
Simon C.
I can define
MAC_OS_X_VERSION_MIN_REQUIRED 🙂 what should I set it to?
12:51
Another issue a user brought up: https://github.com/isar/isar/issues/527#issuecomment-1200366022
Do you think the proposed fix here makes sense?
Do you think the proposed fix here makes sense?
Л(
Л(
9 August 2022
Л(
10:17
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Please check out the
devel branch for mdbx_env_openW().
10 August 2022
SC
00:28
Simon C.
Awesome thanks so much for these fixes they work great!!
11 August 2022
SC
01:28
Simon C.
Do you plan to implement a special
scan4seq implementation for arm processors? Is that even possible?
M
18:12
Mark
Hey guys. Is there a clever way to do composite keys in libmdbx?
18:13
I can concatenate them into a single buffer before putting them in a MDBX_val. But I was wondering if there is a more elegant solution.
Л(
20:42
Леонид Юрьев (Leonid Yuriev)
In reply to this message
There are some good and bad news:
- good: it is simple for now because libmdbx contains boilerplate and
- bad: ARM NEON required 16-byte aligned data, but
So such implementation is possible in general but requires copy data or handling 16 combinations (4*4) of alignment and sequence length, i.e. a lot of code with low profit.
I have no desire to spend time on this yet.
- good: it is simple for now because libmdbx contains boilerplate and
scan4seq_sse2() as a template;- bad: ARM NEON required 16-byte aligned data, but
scan4seq() required operation with 4-byte aligned numbers.So such implementation is possible in general but requires copy data or handling 16 combinations (4*4) of alignment and sequence length, i.e. a lot of code with low profit.
I have no desire to spend time on this yet.
12 August 2022
SC
01:32
Simon C.
In reply to this message
Yeah this effort is pretty cool! I'm a little sad that arm processors get no speed improvements but maybe in the future 😇
Л(
13:33
Леонид Юрьев (Leonid Yuriev)
In reply to this message
One of my friends corrected me.
Actually ARM NEON has
However, ARM NEON don't provide any "move mask" for comparison results.
Actually ARM NEON has
vld1 instructions family that can read partially-aligned data.However, ARM NEON don't provide any "move mask" for comparison results.
👍
SC
15 August 2022
Deleted invited Deleted Account
16 August 2022
08:07
Deleted Account
build with https://github.com/mstorsjo/llvm-mingw ubuntu -tools chain. get this error:
mdbx/src/core.c:15254:10: error: use of undeclared identifier 'EINVAL'
rc = EINVAL;
^
1 error generated.
any tips how to fix this ?
mdbx/src/core.c:15254:10: error: use of undeclared identifier 'EINVAL'
rc = EINVAL;
^
1 error generated.
any tips how to fix this ?
👍
Л(
10:45
Deleted Account
For multimaps, if I only use 8byte KEY, the max value size for 4K page still is 2022 ?
Л(
10:52
Леонид Юрьев (Leonid Yuriev)
In reply to this message
mingw has a lot of oddities, so such problems arise.
however, this is a minor typo-like bug.
Change
I will fix this today in the
however, this is a minor typo-like bug.
Change
EINVAL to the MDBX_EINVAL.I will fix this today in the
master branch.
10:54
Deleted Account
Thanks, after change it to
MDBX_EINVAL . build pass with mingw X86 and X64.
Л(
11:00
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Yes.
Multimaps values (i.e. sets of values) are stored as keys inside a nested b-trees.
This allows store each multimap key only once, but imposes restrictions on the size of values similar to restrictions on b-tree's keys (at least two keys should fit to a single page).
Multimaps values (i.e. sets of values) are stored as keys inside a nested b-trees.
This allows store each multimap key only once, but imposes restrictions on the size of values similar to restrictions on b-tree's keys (at least two keys should fit to a single page).
13:40
Deleted Account
Thanks for explain and the great work.
17 August 2022
09:14
Deleted Account
https://libmdbx.dqdkfa.ru/img/perf-slide-4.png
If I understood correct, this mean lazy commit throughput around 100K transactions per sec in the test ?
{kind=link}
If I understood correct, this mean lazy commit throughput around 100K transactions per sec in the test ?
10:13
Deleted Account
With MDBX_UTTERLY_NOSYNC, app crash and restart will not corrupt the database ?
Л(
10:35
In reply to this message
disk failure = you lose the entire db anyway;
system crash (power failure, BSOD) = you lose all not saved to the disk: maybe the entire db with MDBX_UTTERLY_SYNC, some last txns with MDBX_NOSYNC;
app crash = you lose uncommited transaction(s).
Nonetheless, with MDBX_WRITE MAP app could corrupt a db during a crashing, because whole db image accessible for read-write in app's address space.
system crash (power failure, BSOD) = you lose all not saved to the disk: maybe the entire db with MDBX_UTTERLY_SYNC, some last txns with MDBX_NOSYNC;
app crash = you lose uncommited transaction(s).
Nonetheless, with MDBX_WRITE MAP app could corrupt a db during a crashing, because whole db image accessible for read-write in app's address space.
10:41
Deleted Account
Thanks again for the explain. I only use one process open the database (MDBX_EXCLUSIVE).
in this case, which mode can prevent a disk sector write error corrupt the database ?(un recoverable)
in this case, which mode can prevent a disk sector write error corrupt the database ?(un recoverable)
Л(
10:50
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Only the
MDBX_SYNC_DURABLE, because only synchronous write allows us to see the problem before overwriting the previous (not corrupted) snapshot of data.
11:11
Deleted Account
OK, thanks again for the great project
14:03
Deleted Account
If I use
because there is a IOPS limit from VPS, i want to know the rough number.
switch from diff sync mode, the IOPS will remain same or change a lot (like more than 10 or 100 times) ?
MDBX_SYNC_DURABLE, if every transactions commit around 1024 pages, how many IOPS it will trigger ? because there is a IOPS limit from VPS, i want to know the rough number.
switch from diff sync mode, the IOPS will remain same or change a lot (like more than 10 or 100 times) ?
Л(
14:18
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Simplify, "sync mode" means libmdbx will call
However, the
To reduce IOPS you should try WRITEMAP mode with some kind of NOSYNC option.
As a result, all changes will be performed only in memory, and the OS kernel will write ones to disk asynchronously at own discretion, or at a kick from libmdbx in accordance with the corresponding no-sync mode (yeah, you need to read the documentation carefully, please).
msync(), fdatasync() or similar to flush written data to the HDD/SSD/NVMe.However, the
write() will be used/called regardless to "sync" or "no-sync".To reduce IOPS you should try WRITEMAP mode with some kind of NOSYNC option.
As a result, all changes will be performed only in memory, and the OS kernel will write ones to disk asynchronously at own discretion, or at a kick from libmdbx in accordance with the corresponding no-sync mode (yeah, you need to read the documentation carefully, please).
14:21
Deleted Account
Thanks for the explain. I will read the document more carefully.
👍
Л(
18 August 2022
Л(
08:39
Леонид Юрьев (Leonid Yuriev)
In reply to this message
https://gitflic.ru/project/erthink/libmdbx/commit/08a8f844dc0bf6a048066c21a21ecbb573e06841
Where's my beer?
;)
Where's my beer?
;)
👏
SC
AS
08:54
Deleted Account
If I like to get best speed for non-dup-map, with
I said 4044 because libmdbx seems use 52 byte for internal each page ?
MDBX_SYNC_DURABLE. for default 4K page size, is there a best value size for it (like 4044 ) ? I always commit at batch ( like commit 1024 (or more pages) values at once). key size is fixed 8 byte. I said 4044 because libmdbx seems use 52 byte for internal each page ?
AS
09:53
Alex Sharov
In reply to this message
can see mount of overflow pages (if no overflow pages, then you are fine) in DBI by:
mdbx_stat -a
mdbx_stat -a
09:54
Deleted Account
thanks
09:56
I also need a in-memory fast store by use MDBX_UTTERLY_NOSYNC, if app not crashed then disk io error will not corrupt the in-process database ? (I will recreate it at app restart, dont need old data). (use it like in-memory KV store)
10:05
A DISK-less in-memory libmdbx will be best suit for this case.
YS
10:09
Deleted Account
I need the txn function, hashmap will not able to do it.
AS
10:37
Alex Sharov
In reply to this message
mdbx has no disk-less mode. but it's not a big dial - just set correct geometry and remove db files on startup. in this case can use MDBX_UTTERLY_NOSYNC with
You anyway will have 1 write txn at a time.
"I need the txn function" - btree libs are usually comming with COW-txn support. Consider them.
MDBX_NOMETASYNC - if you don't care about files after machine power-off then any syncmode is good for you. maybe you will need set some sync_period - i don't remember defaults.You anyway will have 1 write txn at a time.
"I need the txn function" - btree libs are usually comming with COW-txn support. Consider them.
👍
YS
10:39
Deleted Account
Thanks for explain. with MDBX_UTTERLY_NOSYNC |
MDBX_NOMETASYNC | MDBX_EXCLUSIVE , disk io error will corrupt the in-memory-one-process database ?
SC
11:11
Simon C.
In reply to this message
You are crazy! I have no idea how you implement all of this stuff so quickly. Thanks so much 🙏💜
Л(
12:10
Леонид Юрьев (Leonid Yuriev)
In reply to this message
On Linux (and most of POSIX systems) the
/dev/shm (or similar) coud be used for disk-less cases.
12:31
Deleted Account
In reply to this message
thanks for this tips, I guess use shm will make sure no disk related corrupt.
Л(
12:43
Леонид Юрьев (Leonid Yuriev)
In reply to this message
This is depends on a system and much complex.
1. DB file is mapped to RAM. So on read I/O error reader process(es) will receive SIGBUS or observe a corrupted (zeroed) page.
This could be fixed/resolved.
However, the system caches pages, so after a single read, everything can work even a disk will dead.
2. Without
Usually the process only gets an error from
Depend on system this may invalidate or do nothing for unified page cache content.
So reader process(es) could receive SIGBUS while accessing such pages, or not to see any problems at all.
3. With
Depend on system this may invalidate whole mapped region (and kill all processes uses DB) or contrary not affect the DB content until the system comes to out-of-memory condition.
Nonetheless, readers will not see a new snapshot (and can't be affected) if transaction will not be committed successfully due I/O error.
1. DB file is mapped to RAM. So on read I/O error reader process(es) will receive SIGBUS or observe a corrupted (zeroed) page.
This could be fixed/resolved.
However, the system caches pages, so after a single read, everything can work even a disk will dead.
2. Without
MDBX_WRITEMAP updates using file descriptor going to the system/kernel's unified page cache and then the to a disk.Usually the process only gets an error from
fdatasync(), which can happen much later than the I/O error actually occurred.Depend on system this may invalidate or do nothing for unified page cache content.
So reader process(es) could receive SIGBUS while accessing such pages, or not to see any problems at all.
3. With
MDBX_WRITEMAP updates are performed only in RAM, and then written to disk asynchronously or forced at transaction committing.Depend on system this may invalidate whole mapped region (and kill all processes uses DB) or contrary not affect the DB content until the system comes to out-of-memory condition.
Nonetheless, readers will not see a new snapshot (and can't be affected) if transaction will not be committed successfully due I/O error.
12:51
Deleted Account
So even in one-process multi thread mode(I deploy app at linux only), a read thread cloud read error if there is no OS cache pages. I guess SHM is the solution for this case.
Л(
13:11
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Two points:
1. If disk fails Linux system becomes unusable mostly immediately or soon.
Therefore, I do not see the rationality in ensuring the operation of your application in such situations. It's just very likely that no user will ever notice that your application is ok when the entire system has died.
2. For single process in-memory cases you can find more suitable solution like
1. If disk fails Linux system becomes unusable mostly immediately or soon.
Therefore, I do not see the rationality in ensuring the operation of your application in such situations. It's just very likely that no user will ever notice that your application is ok when the entire system has died.
2. For single process in-memory cases you can find more suitable solution like
std::map<> or std::unordered_map<> under a mutex (for multithread cases) or some lockless solution.
13:28
Deleted Account
thanks for explain. I ask for
Today I ask for MDBX_UTTERLY_NOSYNC |
After a RAFT command apply, there is time delay before it apply to state machine. I will create a read TNX after send the apply command, and release the TXN if no read task during the apply process.
The point is state machine can continue without wait every command apply, in the same time, if one readonly request arrived, it will use latested apply TXN to execute the task. (A sqlite run on top state machie, so the readonly request will execute in other thread)
One new machine will recreate after app restart from snapshot, so I dont need MDBX_UTTERLY_NOSYNC |
The total size is small, since it only need keep the changed SQLITE-page since last RAFT snapshot. (in this case a new thread will use
The system write only in main-thread, and main-thread can not be blocked(block will made RAFT loss leadership and start re-election). and all write is FAST.
There also a lot read-request, need take a read-snapshot of the sqlite-in-memory-WAL pages(I plan use libmdbx TXN), all run in worker-thread.
The target is keep a high write speed in-memory SQL system, also support high speed query without block write. (a task start apply, after it done, there cloud be 1 RTT from disk IO, read-worker start without wait IO return, USE commited TXN)
I can not use std:map, because in this case every time I response a read-only request, need copy it into worker thread.
MDBX_SYNC_DURABLE yesterday is use it for the RAFT snapshot state machine.Today I ask for MDBX_UTTERLY_NOSYNC |
MDBX_NOMETASYNC | MDBX_EXCLUSIVE , Is use to store the RAFT statue mache before the snapshot.After a RAFT command apply, there is time delay before it apply to state machine. I will create a read TNX after send the apply command, and release the TXN if no read task during the apply process.
The point is state machine can continue without wait every command apply, in the same time, if one readonly request arrived, it will use latested apply TXN to execute the task. (A sqlite run on top state machie, so the readonly request will execute in other thread)
One new machine will recreate after app restart from snapshot, so I dont need MDBX_UTTERLY_NOSYNC |
MDBX_NOMETASYNC | MDBX_EXCLUSIVE to be persistent. But it must always be right, so the result read from it can safe distribute to other node.The total size is small, since it only need keep the changed SQLITE-page since last RAFT snapshot. (in this case a new thread will use
MDBX_SYNC_DURABLE commit into other store).The system write only in main-thread, and main-thread can not be blocked(block will made RAFT loss leadership and start re-election). and all write is FAST.
There also a lot read-request, need take a read-snapshot of the sqlite-in-memory-WAL pages(I plan use libmdbx TXN), all run in worker-thread.
The target is keep a high write speed in-memory SQL system, also support high speed query without block write. (a task start apply, after it done, there cloud be 1 RTT from disk IO, read-worker start without wait IO return, USE commited TXN)
I can not use std:map, because in this case every time I response a read-only request, need copy it into worker thread.
13:30
The raft snapshot process is also execute in worker thread, a TXN take from FAST-memory MDBX-instance, and copy the changed page into DISK-based-DURABLE MDBX-instance. the page-index info also persistent into RAFT-snapshot in this step .
13:34
The RAFT log store & snapshot is not related to DBMX, and is async IO in a event loop.
13:46
@erthink > 1. If disk fails Linux system becomes unusable mostly immediately or soon.
I need avoid replicated wrong results into other node before system crash, so the RAFT group can continue without error.
I need avoid replicated wrong results into other node before system crash, so the RAFT group can continue without error.
👍
Л(
13:53
map with lock will not fix the problem, because I need Serializable Snapshot Isolation for every read request. (I has to copy full map for every read-request)
👍
Л(
Л(
13:59
Леонид Юрьев (Leonid Yuriev)
In reply to this message
However, I should warn you about RAM errors.
Unfortunately libmdbx didn't provide/use any checksums (MithrilDB will use Merkle tree).
So RAM bit errors will affect you, and we have a few confirmed such incidents.
Unfortunately libmdbx didn't provide/use any checksums (MithrilDB will use Merkle tree).
So RAM bit errors will affect you, and we have a few confirmed such incidents.
14:01
Deleted Account
The app will deploy only at server, so ECC memory is expected in this case. (I will also keep a hash to verify for every SQLITE-page in raft-snapshot)
🔥
Л(
AS
14:06
Alex Sharov
In reply to this message
Etcd - RAFT replicated db - using “boltdb” under the hood. And boltdb is the mdbx re-written in golang (With some features loss). Etcd seems fine and popular (recent outage rootcause was about bottleneck which mdbx doesn’t have - copy whole FreeList on each commit: https://hn.svelte.dev/item/30013919 ).
👍
Л(
14:14
Deleted Account
In reply to this message
I am very look forward the MithrilDB. please also check https://github.com/chjj/liburkel
16:39
Deleted Account
to start read only txn from main loop and dispatch it execute inside worker thread, I need decide create read-only TXN from event loop or worker thread.
to create from event loop, I need use MDBX_NOTLS to make sure the txn pass to worker will be useable. in this case Can I shared one read-only txn for multi worker without lock ? (I read from document "And a read-only transaction may span threads if you synchronizes its use.", I guess this mean NO even there is no write )
If I create txn from worker thread, I can not use a parent TXN from event loop (mark the step of state machine, in case node loss leader-ship and un-distributed command).
to create from event loop, I need use MDBX_NOTLS to make sure the txn pass to worker will be useable. in this case Can I shared one read-only txn for multi worker without lock ? (I read from document "And a read-only transaction may span threads if you synchronizes its use.", I guess this mean NO even there is no write )
If I create txn from worker thread, I can not use a parent TXN from event loop (mark the step of state machine, in case node loss leader-ship and un-distributed command).
Л(
16:44
Леонид Юрьев (Leonid Yuriev)
With MDBX_NOTLS you can use txn from any thread but NOT simultaneously.
For instance, txn internally contains a linked list of cursors, so it can't be used from more than a single thread.
For instance, txn internally contains a linked list of cursors, so it can't be used from more than a single thread.
16:52
Deleted Account
Thanks for the explain. so if I am right, I need use MDBX_NOTLS and create txn with parent txn for every time I need dispatch a task into a worker, and release that txn when job is finished.
The other choice is open read-only txn without parent txn inside worker thread, release txn when finished. in this case I need wait the raft command is apply into cluster, then send the response to client. if leader-ship lossed then I need ask client to resend request.
with TLS, there is no need keep a TXN mark for every raft comand log (AS parent TXN late create child TXN pass to worker), I guess in this case it use less-memory and run faster ? (I will try this first, late if also be able to implement no-tls will try some benchmark comapre)
The other choice is open read-only txn without parent txn inside worker thread, release txn when finished. in this case I need wait the raft command is apply into cluster, then send the response to client. if leader-ship lossed then I need ask client to resend request.
with TLS, there is no need keep a TXN mark for every raft comand log (AS parent TXN late create child TXN pass to worker), I guess in this case it use less-memory and run faster ? (I will try this first, late if also be able to implement no-tls will try some benchmark comapre)
20 August 2022
Л(
16:06
Леонид Юрьев (Leonid Yuriev)
In reply to this message
0) I strongly advise you to read the documentation in full at least once, specially the "Restrictions & Caveats" chapter.
https://libmdbx.dqdkfa.ru/intro.html#restrictions
1) MDBX supports nested read-write transactions, but not read-only.
In addition to the obvious, there are a lot of other differences between read-only and read-write transactions:
- the single writer rule: there can be running only one read-write transaction;
- MDBX_NOTLS is for read-only transaction only, but you may decide to use the
- etc...
2) The use of nested transactions is justified only if the logic of the application assumes ones cancellation in some cases of external data and/or events.
3) The long-lived read transactions should be avoided, especially in the scenarios with a high rate of write transactions.
Follow the given link for more details...
https://libmdbx.dqdkfa.ru/intro.html#restrictions
1) MDBX supports nested read-write transactions, but not read-only.
In addition to the obvious, there are a lot of other differences between read-only and read-write transactions:
- the single writer rule: there can be running only one read-write transaction;
- MDBX_NOTLS is for read-only transaction only, but you may decide to use the
MDBX_TXN_CHECKOWNER=0 build option;- etc...
2) The use of nested transactions is justified only if the logic of the application assumes ones cancellation in some cases of external data and/or events.
3) The long-lived read transactions should be avoided, especially in the scenarios with a high rate of write transactions.
Follow the given link for more details...
Л(
16:38
Леонид Юрьев (Leonid Yuriev)
@AskAlexSharov, вам бы стоит попробовать текущую ветку
BigFoot там (вроде-бы) такой-же как вы уже пользуете, но есть три существенных доработки:
0) Добавлен осторожный/безопасный режим работы с потенциально поврежденными БД.
Это первый шаг для переезда функционала mdbx_chk внутрь библиотеки.
1) Уменьшены накладные расходы на контроль страниц.
Это не полный контроль из предыдущего пункта, но страховка от большинства проблем (и багов).
В текущем понимании, теперь эта часть libmdbx c контролем работает быстрее чем LMDB без контроля.
2) Примерно к теоретическому минимум сведены накладные расходы на анализ/выбор мета-страниц.
Минимум чтений, сравнений/ветвлений и барьеров памяти.
В текущем понимании, теперь эта часть libmdbx по скорости примерно как в LMDB, хотя в MDBX есть контроль/защита от частичного обновления и три мета-страницы вместо двух.
3) Ускорение поиска последовательностей страниц в 4/8/16 раз посредством SSE/AVX2/AVX512/Neon.
Даже на тупом RISCV работает вдвое быстрее чем раньше.
---
Дальше я продолжу закрывать TODO, в частности перенесу внутрь функционал mdbx_chk и асинхронную запись для Windows, может быть io_ring для Linux.
Но пока не решил откладывать выпуск v0.12 до реализации запланированного или выпускать то что готово сейчас.
devel.BigFoot там (вроде-бы) такой-же как вы уже пользуете, но есть три существенных доработки:
0) Добавлен осторожный/безопасный режим работы с потенциально поврежденными БД.
Это первый шаг для переезда функционала mdbx_chk внутрь библиотеки.
1) Уменьшены накладные расходы на контроль страниц.
Это не полный контроль из предыдущего пункта, но страховка от большинства проблем (и багов).
В текущем понимании, теперь эта часть libmdbx c контролем работает быстрее чем LMDB без контроля.
2) Примерно к теоретическому минимум сведены накладные расходы на анализ/выбор мета-страниц.
Минимум чтений, сравнений/ветвлений и барьеров памяти.
В текущем понимании, теперь эта часть libmdbx по скорости примерно как в LMDB, хотя в MDBX есть контроль/защита от частичного обновления и три мета-страницы вместо двух.
3) Ускорение поиска последовательностей страниц в 4/8/16 раз посредством SSE/AVX2/AVX512/Neon.
Даже на тупом RISCV работает вдвое быстрее чем раньше.
---
Дальше я продолжу закрывать TODO, в частности перенесу внутрь функционал mdbx_chk и асинхронную запись для Windows, может быть io_ring для Linux.
Но пока не решил откладывать выпуск v0.12 до реализации запланированного или выпускать то что готово сейчас.
🔥
AS
A
АМ
4
16:53
Deleted Account
In reply to this message
Thanks for the tips and advice. I will read it all.
1) I am not aware nested is support for read-only. (I am look for a solution like a marker for a position to start read-only late, late start read if there is request, or remove it if no request before RAFT LOG saved[ 1ms ~ 3ms SSD disk IO delay ] ) . In this case I need think of some new solution. (there is no long time read-only, because it will be release ASAP when worker finished)
2) I am aware the singlo-write limit, the RAFT write in main-loop and alway run one by one.
Thanks again the tips, now I am test it for SQLITE VFS.
1) I am not aware nested is support for read-only. (I am look for a solution like a marker for a position to start read-only late, late start read if there is request, or remove it if no request before RAFT LOG saved[ 1ms ~ 3ms SSD disk IO delay ] ) . In this case I need think of some new solution. (there is no long time read-only, because it will be release ASAP when worker finished)
2) I am aware the singlo-write limit, the RAFT write in main-loop and alway run one by one.
Thanks again the tips, now I am test it for SQLITE VFS.
16:58
What will be use-full is: clone a read-only txn, so there can be multi read-only work from multi thread at same time. no need nested.
(I can not open one from NULL, because in this case maybe read a un-commit RAFT log state machine)
(I also can not delay the write txn commit until raft-log saved, this will block the pipeline) (raft-log commit take much more time, if pipeline blocked the QPS will drop to 200 ~ 300)
(I can not open one from NULL, because in this case maybe read a un-commit RAFT log state machine)
(I also can not delay the write txn commit until raft-log saved, this will block the pipeline) (raft-log commit take much more time, if pipeline blocked the QPS will drop to 200 ~ 300)
SC
20:41
Simon C.
In reply to this message
If v0.12 takes a little longer would you mind releasing an v0.11.x version with the fixes in master?
👍
AB
21 August 2022
SC
11:19
Simon C.
How can
EAGAIN be caused/avoided when trying to open an environment? 🧐
Л(
23:53
Леонид Юрьев (Leonid Yuriev)
In reply to this message
0.
So you should try to use the
1. When opening a environment, libmdbx can get this error from the system during locking, but should not return it to the user in such cases.
If the database is used by another process (for instance in exclusive mode), the
2. However, if
For instance, kernel would return AGAIN from
- if DB file is used/locked by another process directly (no by libmdbx);
- corresponding rlimit is reached (see
- system has too low free memory (other process use a lot of).
There may also be rare situations when
EAGAIN is returned by the kernel, and to find out the reason, you need to know which system call returned this error.So you should try to use the
strace or similar tool. 1. When opening a environment, libmdbx can get this error from the system during locking, but should not return it to the user in such cases.
If the database is used by another process (for instance in exclusive mode), the
MDBX_BUSY error should be returned.2. However, if
EAGAIN occurs outside the context of the locking mechanism used (depends on the platform), then the error is returned to the user as is.For instance, kernel would return AGAIN from
mmap()- if DB file is used/locked by another process directly (no by libmdbx);
- corresponding rlimit is reached (see
man setrlimit());- system has too low free memory (other process use a lot of).
There may also be rare situations when
EAGAIN occurs in the most unexpected places, if the system lacks some resources, or some kernel subsystem is overloaded.
22 August 2022
SC
00:22
Simon C.
Thanks that helps a lot!! 💜
Л(
14:00
Леонид Юрьев (Leonid Yuriev)
libmdbx 0.11.10 (the TriColor)
The stable bugfix release.
It is planned that this will be the last release of the v0.11 branch.
- The C++ API has been refined to simplify support for
- Added explicit error message for Buildroot's Microblaze toolchain maintainers.
Fixes:
- Never use modern
- Use
- Don't check owner for finished transactions.
- Fixed typo in
Minors:
- Fixed variable name typo.
- Using
- Added
- Use current transaction geometry for untouched parameters when
- Minor clarified
https://gitflic.ru/project/erthink/libmdbx/release/2886daeb-f583-4c30-bede-b8e60965c834
The stable bugfix release.
It is planned that this will be the last release of the v0.11 branch.
14 files changed, 263 insertions(+), 252 deletions(-)
New:- The C++ API has been refined to simplify support for
wchar_t in path names.- Added explicit error message for Buildroot's Microblaze toolchain maintainers.
Fixes:
- Never use modern
__cxa_thread_atexit() on Apple's OSes.- Use
MultiByteToWideChar(CP_THREAD_ACP) instead of mbstowcs().- Don't check owner for finished transactions.
- Fixed typo in
MDBX_EINVAL which breaks MingGW builds with CLANG.Minors:
- Fixed variable name typo.
- Using
ldd to check used dso.- Added
MDBX_WEAK_IMPORT_ATTRIBUTE macro.- Use current transaction geometry for untouched parameters when
env_set_geometry() called within a write transaction.- Minor clarified
iov_page() failure case.https://gitflic.ru/project/erthink/libmdbx/release/2886daeb-f583-4c30-bede-b8e60965c834
🔥
SC
16:49
I have one more question about readony-txn, if they are create and released with a lock, can I use it form diff thread at same time? (env created wihout TLS)
AS
17:11
Deleted Account
In reply to this message
not pretect by mutex when read dbi, just create and release txn protected by mutex. in this case is it multi thread safe ?
AS
17:24
Alex Sharov
In reply to this message
Everything is not-thread-safe in mdbx. Need take care on app side.
17:26
Deleted Account
If so, a method to clone readonly txn is required. (not as parent txn), the new cloned-txn is not related into parent like nested txn.
without clone readonly-txn, it is not able to be useful in many case. like RAFT log async snapshot.
without clone readonly-txn, it is not able to be useful in many case. like RAFT log async snapshot.
AS
17:29
Deleted Account
last weekend I just try use libmdbx as sqlite VFS sqlite with a RAFT log, I can not find workaround to bypass the clone read-only txn.
The async raft require sqlite checkpoint in worker-thread (not the main thread, which run event loop), after worker-thread done there is a time window before merge the checkpoint into last committed raft-log state machine.
I try read the document, not able to find a solution.
need a method to clone a old-readonly-txn (not the last comimtted write txn).
The async raft require sqlite checkpoint in worker-thread (not the main thread, which run event loop), after worker-thread done there is a time window before merge the checkpoint into last committed raft-log state machine.
I try read the document, not able to find a solution.
need a method to clone a old-readonly-txn (not the last comimtted write txn).
17:30
create new one will not work, because the lateste work is not committed into raft cluster yet.
AS
17:30
Alex Sharov
You wan’t to read non-committed data?
17:31
Deleted Account
no. read the earlly commited data. (confirmed by the raft cluster), not the recent txn.
AS
17:32
Alex Sharov
Open read txn - 10 commits in the past? Just don’t close that old read transaction?
17:33
Deleted Account
this will not work. because when you start open the txn, you dont know how many read request will arrive late. it could be big, or zero.
AS
17:34
Alex Sharov
In reply to this message
Keep stack of last 10 read txs, add there new read tx after every commit.
17:37
Deleted Account
this is is not a solution. there could be 1000 log wait raft group to confirm, at same time the request is unknow.
there is high traffic time, far more than 10 request arrive at same time. (like 100)
there is high traffic time, far more than 10 request arrive at same time. (like 100)
AS
17:39
Alex Sharov
I think there is some api in mdbx - where you can pass snapshotId: somewhere in renew/reset funcs. But i don’t remember where is it exactly now, try search in mdbx.h - but in my head technically it will be same as holding stack of last 10K read transactions.
17:40
Deleted Account
thanks for the tips. I will read mdbx.h again.
AS
17:40
Alex Sharov
Or change your data structure in db from mutable to immutable - and store history in db - read it any time you want without holding read transactions
17:41
Deleted Account
That cloud work. but a public api, to clone read-txn is useful for many case. I am not sure this is doable for mdbx.
Л(
17:41
Леонид Юрьев (Leonid Yuriev)
A lot of misses above.
Read-only txns are mostly lock-free in mostly cases. However there are some points where some locking is required:
- when thread acquiring or releasing slot in the readers table;
- when txn opens new or import fresh dbi handle;
- shared lock to avoid temporary unmap() during resize dB region.
Read-only txns are mostly lock-free in mostly cases. However there are some points where some locking is required:
- when thread acquiring or releasing slot in the readers table;
- when txn opens new or import fresh dbi handle;
- shared lock to avoid temporary unmap() during resize dB region.
17:41
Я сейчас в дороге до завтра. Поэтому мне сложно читать и отвечать.
AS
17:44
Alex Sharov
In reply to this message
Doable - but no magic - mdbx will need to store all versions of your data - to provide you consistent view on them. It means you will need manually say to mdbx - “ok, nobody will need that old views of db anymore” or your db size will grow to hold all versions.
17:46
Deleted Account
It will be released very soon. I expect read-only txn finished less than 10ms
17:50
Most of them Finnish less than 2ms, so the read-only txn qps expect to be high. (Aound 60k qps), because it finished very fast, so the number of version is limited
AS
17:52
Alex Sharov
In reply to this message
No magic - if you wanna read data 10 commits old - mdbx need hold them - same way as it holds when long read txn is open. There is some api for this (like mdbx_txn_reset func).
17:56
Deleted Account
Reset can not allowed one txn to be used at diff worker thread same time
23 August 2022
SC
01:19
Simon C.
I have big problems with Android builds for NDK versions >= 23. I always get the error __emutls_get_address symbol not found. Does anyone have an idea how this can be solved?
Л(
01:41
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Please just google this and read first answer at stackoverflow, etc
10:56
Deleted Account
in the docs: If the filesystem preserves write order (which is rare and never provided unless explicitly noted)
Is ext4 preserves write order ? f2fs ? any linux filesystem support this ?
Is ext4 preserves write order ? f2fs ? any linux filesystem support this ?
Л(
13:40
Леонид Юрьев (Leonid Yuriev)
In reply to this message
You will found a lot of oddities due digging answer.
Basically, No.
However it is very platform-specific.
For instance, on Linux the reordering is an explicit task of the io-scheduler.
Basically, No.
However it is very platform-specific.
For instance, on Linux the reordering is an explicit task of the io-scheduler.
SC
21:23
Simon C.
What can cause EOVERFLOW? Am I providing an invalid value somewhere or is it another problem? A user reported this error happens while opening an environment.
At first I thought it was a database > 2GB on a 32-bit system but the user says it happens for a new environment.
At first I thought it was a database > 2GB on a 32-bit system but the user says it happens for a new environment.
24 August 2022
Л(
13:03
Леонид Юрьев (Leonid Yuriev)
In reply to this message
The
So please use
EOVERFLOW hasn't used/returned in libmdbx, i.e. this error comes form the sysme/kernel.So please use
strace or similar tool.
👍
SC
Л(
14:08
Леонид Юрьев (Leonid Yuriev)
libmdbx 0.12.1 (Positive Proxima)
https://gitflic.ru/project/erthink/libmdbx/release/0d23187f-2215-4153-bb82-6afda7da7c7c
(link was update due gflic glitches).
https://gitflic.ru/project/erthink/libmdbx/release/0d23187f-2215-4153-bb82-6afda7da7c7c
(link was update due gflic glitches).
🔥
MN
SC
14:18
Deleted Account
MDBX_VALIDATION is run once at start, or verify at every read ?
Л(
14:19
Леонид Юрьев (Leonid Yuriev)
For every page read for now. Later will be more flexibility.
14:21
Deleted Account
thanks for explain.
Л(
14:24
Леонид Юрьев (Leonid Yuriev)
Positive Technologies 20 anniversary.
Л(
14:24
Леонид Юрьев (Leonid Yuriev)
Л(
Леонид Юрьев (Leonid Yuriev) 24.08.2022 14:18:29

🎉
AV
4
SC
14:56
Simon C.
I'm getting the following error when trying to build for an x64 mac. Building for arm64 mac works fine.
note: Undefined symbols for architecture x86_64:
"___cpu_indicator_init", referenced from:
_scan4seq_resolver in libmdbx_sys-97b230ccc8c8d06a.rlib(mdbx.o)
"___cpu_model", referenced from:
_scan4seq_resolver in libmdbx_sys-97b230ccc8c8d06a.rlib(mdbx.o)
ld: symbol(s) not found for architecture x86_64
clang: error: linker command failed with exit code 1 (use -v to see invocation)
Л(
15:15
Леонид Юрьев (Leonid Yuriev)
In reply to this message
This is consequence of 🍎's clang incompatibility.
Will be fixed later by disable runtime dispatching when building for apple's platforms or by an apple's toolchain.
Will be fixed later by disable runtime dispatching when building for apple's platforms or by an apple's toolchain.
SC
15:16
Simon C.
Thanks a lot! It's funny how apple built clang and is incompatible
25 August 2022
SC
01:50
Simon C.
On Android x64 (and x86) I get the following error:
Do I have to use -fPIC from now on?
error: relocation R_X86_64_PC32 cannot be used against symbol '__cpu_model'; recompile with -fPICDo I have to use -fPIC from now on?
Л(
16:50
Леонид Юрьев (Leonid Yuriev)
In reply to this message
The
However you should check you build(s).
Nonetheless, this seems like a bug/mistake during build toolchain (that u r using) for Android, i.e. the
-fPIC or -fpic is used by default by CMake and inside GNUMakefile.However you should check you build(s).
Nonetheless, this seems like a bug/mistake during build toolchain (that u r using) for Android, i.e. the
-fpic has been missed for libgcc.
🤔
SC
Леонид Юрьев (Leonid Yuriev) invited Gitflic
Л(
17:33
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Another reasons:
- your build uses a static libgcc, which was built without
- a compilation driver selects the wrong libgcc for linking due to a complex and/or conflicting set of options.
- your build uses a static libgcc, which was built without
-fpic;- a compilation driver selects the wrong libgcc for linking due to a complex and/or conflicting set of options.
17:44
@leisim,
Nonetheless, I didn't seen any probles for CMake-builds libmdbx with NDK r24 and r23c on Ubuntu 20.04 (LTS) for x86, amd64, arm32-7a and arm64-8a.
Also I didn't seen any problems building for macOS 10.15.7 and 11.6.8.
I can send you the logs of these builds, perhaps this will help you understand the causes of your problems.
Nonetheless, I didn't seen any probles for CMake-builds libmdbx with NDK r24 and r23c on Ubuntu 20.04 (LTS) for x86, amd64, arm32-7a and arm64-8a.
Also I didn't seen any problems building for macOS 10.15.7 and 11.6.8.
I can send you the logs of these builds, perhaps this will help you understand the causes of your problems.
❤
SC
SC
18:30
Simon C.
I'll have to look into all of these suggestions. Right now my workaround is to use the previous version. Since I use Rust to build the app it is not always clear how the compiler gets called
27 August 2022
AL
12:43
Andrea Lanfranchi
@erthink
Willing to find the best value size to fit in a page without causing overflow: do you have a rule of thumb ?
Willing to find the best value size to fit in a page without causing overflow: do you have a rule of thumb ?
Л(
13:27
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Briefly, a leaf-page for a non-dupsort DB should contain at least one kv-pair.
So summary length of key and value must fit to a single page.
However, this is a wrong question.
It is no problem to place a value to the separate (i.e. large/overflow) page, or a pair of ones. Then a leaf-page will contain a key and a reference (4 byte) to the page(s) where value within.
This maybe more profitable, because separated value(s) will not be readers during search and will not be COWed during updates of neighbors.
So summary length of key and value must fit to a single page.
However, this is a wrong question.
It is no problem to place a value to the separate (i.e. large/overflow) page, or a pair of ones. Then a leaf-page will contain a key and a reference (4 byte) to the page(s) where value within.
This maybe more profitable, because separated value(s) will not be readers during search and will not be COWed during updates of neighbors.
AL
13:33
Andrea Lanfranchi
In reply to this message
Ok that's a good insight.
But my (maybe wrong) understanding is that OF pages are contiguous to leaves they're linked to ... doesn't this cause troubles on heavily upserted sub-dbs which "records" get heavily upserted (COW of 2+ pages instead of 1) ?
But my (maybe wrong) understanding is that OF pages are contiguous to leaves they're linked to ... doesn't this cause troubles on heavily upserted sub-dbs which "records" get heavily upserted (COW of 2+ pages instead of 1) ?
Л(
13:35
Леонид Юрьев (Leonid Yuriev)
The main disadvantage of storing a large/long values is that requires a sequence of free pages. So if value(s) is long (requires a consequence of several pages) the engine will search in over whole GC.
13:40
In reply to this message
OF pages are contiguous only for itself and only to place a long value in contiguous/linear address range, I.e the "contiguous property" is not related to leaf pages, but only to the length of value(s).
AL
13:41
Andrea Lanfranchi
> So summary length of key and value must fit to a single page.
Yes but I also understand a page stores metadata and length of key and value at minimum. So "available space" in a single page is less than nominal page size (e.g. 4/8/16K)
Yes but I also understand a page stores metadata and length of key and value at minimum. So "available space" in a single page is less than nominal page size (e.g. 4/8/16K)
Л(
AL
13:42
Andrea Lanfranchi
> OF pages are contiguous only for itself and only to place a long value in contiguous/linear address range, I.e the "contiguous property" is not related to leaf pages, but only to the length of value(s).
Hmmm does this mean that if "value" does not fit in a leaf page is then entirely stored in a contiguous sequence of OF pages ?
Hmmm does this mean that if "value" does not fit in a leaf page is then entirely stored in a contiguous sequence of OF pages ?
Л(
AL
13:46
Andrea Lanfranchi
In reply to this message
And about this (sorry for the stubborn repetition) given a page size of 4K which is the maximum "payload" size fitting in one page only ?
Assuming I know key len but have to determine an "optimal" value length and I'm NOT in dupsorted sub-db
Assuming I know key len but have to determine an "optimal" value length and I'm NOT in dupsorted sub-db
Л(
13:53
Леонид Юрьев (Leonid Yuriev)
The overhead is page header + node size + 2 bytes for offset from one-page index-entry, ~32 bytes.
But please refer to source code, since I can confuse the details of the public and experimental versions of the library.
But please refer to source code, since I can confuse the details of the public and experimental versions of the library.
AL
Л(
SC
15:11
Simon C.
In reply to this message
That's such a big help thank you!! Now I just got to figure out what causes this weird
EOVERFLOW https://github.com/isar/isar/issues/589
👍
Л(
AL
15:13
Andrea Lanfranchi
In reply to this message
Just found this which explicates a lot to me.
Would be extremely nice-to-have if it could be exposed in C++ bindings (just a suggestion)
Thank you. Keep up with the great job
#define LEAF_NODE_MAX(pagesize) \
(EVEN_FLOOR(PAGEROOM(pagesize) / 2) - sizeof(indx_t))
Would be extremely nice-to-have if it could be exposed in C++ bindings (just a suggestion)
Thank you. Keep up with the great job
#define LEAF_NODE_MAX(pagesize) \
(EVEN_FLOOR(PAGEROOM(pagesize) / 2) - sizeof(indx_t))
👍
Л(
30 August 2022
СО
15:17
Станислав Очеретный
@erthink . Можно ли как-то получить список sub-dbs , через публичный С/C++ интерфейс. Насколько я понимаю, он хранится в MDBX_db *mt_dbxs, который наружу не виден?
15:19
Я в одной БД создаю несколько subdb, с уникальными именами. Хочется получить список имён эти subdb
15:28
У меня сценарий для реализации отката/наката такой: при накате - предыдущее состояние (subdb) копируется в новую subdb, затем текущая subdb модифицируется, при откате - копируется ранее сохраненная subdb в текущую subdb. Пока я не вышел из своего приложения я знаю имена subdb, т.к. я их сам и создаю.
При перезапуске моего приложения, хочется увидеть все коррекции, т.е. загрузить список всех ранее созданных subbs
При перезапуске моего приложения, хочется увидеть все коррекции, т.е. загрузить список всех ранее созданных subbs
Л(
16:14
Леонид Юрьев (Leonid Yuriev)
In reply to this message
mt_dbxs - это внутреннее поле транзакции указывающее на массив вспомогательных структур для открытых DBI-хендлов, т.е. пока вы не откроете subDB там ничего не появиться.Исторически такой возможности в явном виде нет.
Причина в том, что для совместимости/схожести с LMDB (а у LMDB с более ранними движками) поддерживает работа без именованных subDB, когда DBI-хендл открывается с name==NULL.
В этом режиме key-value пары хранятся в основном b-tree (aka MainDB), вместе с вложенными b-tree именованных subDB.
Соответственно, чтобы увидеть/перебрать все subDB достаточно:
- открыть курсор для MainDB (задать name = NULL);
- перебрать через курсор все записи;
- каждая запись будет либо соответствовать subDB (при этом ключ будет являться именем), либо kv-парами в MainDB (если таковые были созданы).
16:17
Проще говоря, вам следует пройтись курсором по MainDB и пробовать открыть каждый ключ как subDB с опцией
Всё что успешно откроется - будут subDB.
Остальные подробности см описание API.
MDBX_DB_ACCEDE.Всё что успешно откроется - будут subDB.
Остальные подробности см описание API.
СО
16:17
Станислав Очеретный
ок, спасибо
31 August 2022
Л(
03:34
Леонид Юрьев (Leonid Yuriev)
I'm thinking of speaking or not at the HighLoad++ conference.
You are welcome to note a subject or be a co-speaker.
You are welcome to note a subject or be a co-speaker.
yi huang invited yi huang
СО
17:32
Функция mdbx_del возвращает MDBX_INCOMPATIBLE, при вызове mdbx_cursor_del(MDBX_cursor *mc, MDBX_put_flags_t flags)
>> if (unlikely((node_flags(node) ^ flags) & F_SUBDATA))
return MDBX_INCOMPATIBLE;
>> if (unlikely((node_flags(node) ^ flags) & F_SUBDATA))
return MDBX_INCOMPATIBLE;
17:35
При вызове mdbx_del(MDBX_txn *txn, MDBX_dbi dbi, const MDBX_val *key, const MDBX_val *data)
dbi - ставлю ссылку на MainDB, в key - cтроку с именем subDB, data=nullptr
dbi - ставлю ссылку на MainDB, в key - cтроку с именем subDB, data=nullptr
AV
18:49
Artem Vorotnikov
In reply to this message
mdbx_drop с третьим аргументом truehttps://libmdbx.dqdkfa.ru/group__c__crud.html#gadc9d57659242902003bb5459bc063b32
👍
Л(
1 September 2022
СО
6 September 2022
08:08
Deleted Account
I get this error when build libmdbx for linux aarch64:
mdbx/src/core.c:7378:46: error: no member named 'troika' in 'struct MDBX_txn'
last = meta_recent(env, &env->me_txn0->troika).ptr_v->mm_geo.next;
~~~~~~~~~~~~ ^
1 error generated.
mdbx/src/core.c:7378:46: error: no member named 'troika' in 'struct MDBX_txn'
last = meta_recent(env, &env->me_txn0->troika).ptr_v->mm_geo.next;
~~~~~~~~~~~~ ^
1 error generated.
Л(
13:17
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Fixed for now in the
Thank you for reporting.
devel branch.Thank you for reporting.
13:38
Deleted Account
It's my pleasure
12 September 2022
A Telegram User invited A Telegram User
SC
17:16
Simon C.
What does it mean if this assertion fails? I got a user reporting that on "lower end Android devices".
Л(
18:21
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Very strange...
So far I can only assume three possible reasons:
- a DB corruption due hardware failure;
- a bug in the library that manifests itself due to the features of the platform;
- a bug in the library that manifests itself due to the specific scenario.
At a minimum, a full stack dump is required to get closer to understanding.
So far I can only assume three possible reasons:
- a DB corruption due hardware failure;
- a bug in the library that manifests itself due to the features of the platform;
- a bug in the library that manifests itself due to the specific scenario.
At a minimum, a full stack dump is required to get closer to understanding.
Л(
18:50
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Besides above, just an one bug working with pointers in the application code or the libraries used is enougb to corrupt some libmdbx data in the RAM.
SC
18:50
Simon C.
Okay thanks! 🙏
13 September 2022
Fat Solko invited Fat Solko
FS
10:59
Fat Solko
При билде проекта на windows с использованием mingw64 gcc g++, make, cmake, оявляется такая ошибка и крашится с ошибками на втором скрине.
Этот же проект на другом компе собирается, но доступа к нему нет, чтобы сравнить окружения. В чём может быть проблема?
Этот же проект на другом компе собирается, но доступа к нему нет, чтобы сравнить окружения. В чём может быть проблема?
10:59
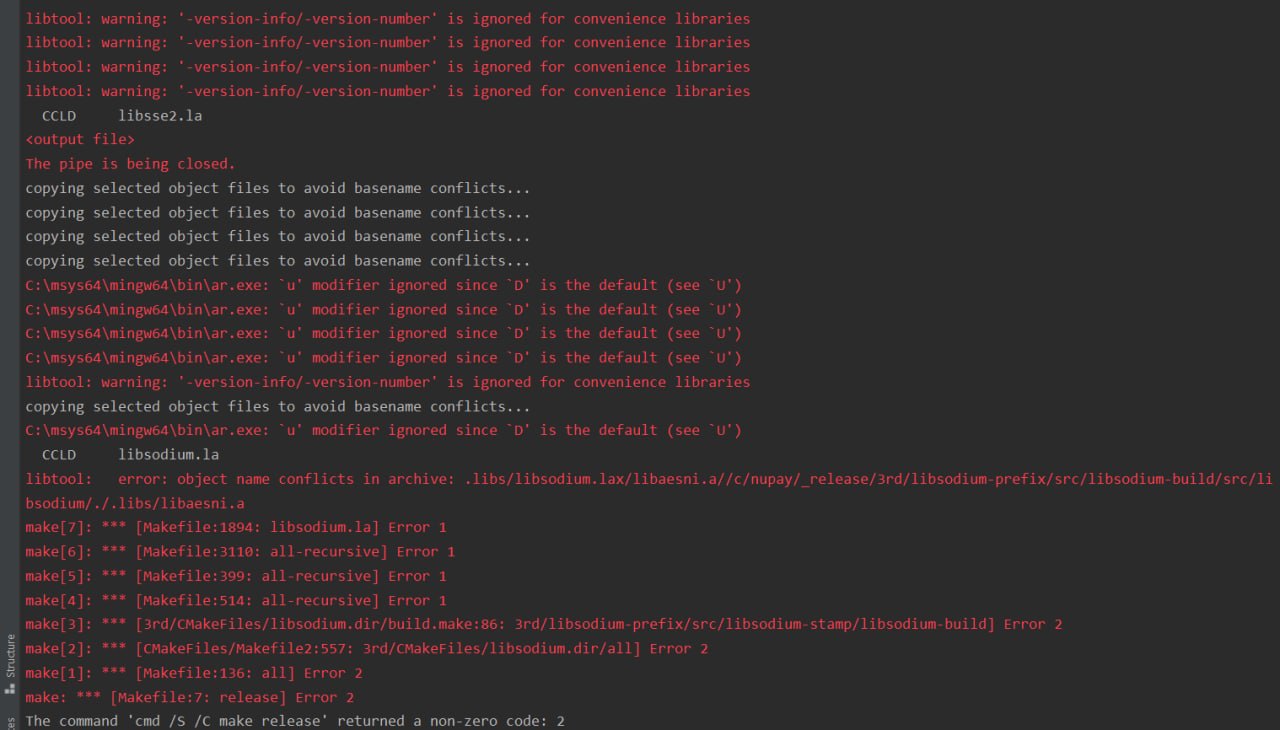
Л(
11:14
Леонид Юрьев (Leonid Yuriev)
In reply to this message
В mingw точно были какие-то глупые подобные проблемы, которые устранены в последних актуальных версиях.
Поэтому совет только один - используйте последние версии тулчейна и актуальные версии libmdbx.
Достоверно известно что на прошлой неделе всё успешно собиралось и тестировалось посредством mingw доступной через https://chocolatey.org/.
Как лучше устанавливать и обновлять mingw мне советовать сложно, так как последние лет 10 почти не пользуюсь.
Пока пришел к выводу что проще использовать choco, но там тоже бывают ошибки/проблемы как в самой утилите, так и в пакете.
Поэтому может потребоваться ручная чистка и/или переустановка.
Поэтому совет только один - используйте последние версии тулчейна и актуальные версии libmdbx.
Достоверно известно что на прошлой неделе всё успешно собиралось и тестировалось посредством mingw доступной через https://chocolatey.org/.
Как лучше устанавливать и обновлять mingw мне советовать сложно, так как последние лет 10 почти не пользуюсь.
Пока пришел к выводу что проще использовать choco, но там тоже бывают ошибки/проблемы как в самой утилите, так и в пакете.
Поэтому может потребоваться ручная чистка и/или переустановка.
FS
11:20
Fat Solko
Собираю всё в докере. Использую набор тулов из скрина.
Libmdbx подтягивается отсюда https://gitflic.ru/project/erthink/libmdbx.git коммит b36a07a5(но он по сути не должен влиять, потому что на другой машине собирается нормально с тем же коммитом). Со слов разработчика у которого всё билдится, там тоже mingw64
Libmdbx подтягивается отсюда https://gitflic.ru/project/erthink/libmdbx.git коммит b36a07a5(но он по сути не должен влиять, потому что на другой машине собирается нормально с тем же коммитом). Со слов разработчика у которого всё билдится, там тоже mingw64
Л(
11:25
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Ищите различия в системах и/или окружении.
Если придете к выводу, что в libmdbx что-то не верно, то я готов принять патч.
Но предоставить более существенную поддержку винды я не могу.
Если придете к выводу, что в libmdbx что-то не верно, то я готов принять патч.
Но предоставить более существенную поддержку винды я не могу.
FS
11:27
Fat Solko
In reply to this message
как и писал выше, нет доступа к компу, сравнить окружения нет возможности.
Всё верно, я думаю проблема не в библиотеке, просто вдруг кто-то уже сталкивался с подобным.
Всё верно, я думаю проблема не в библиотеке, просто вдруг кто-то уже сталкивался с подобным.
Л(
11:36
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Прошу прощенья, присмотрелся - это всё таки мой мелкий баг.
У вас проявляется из-за различия в тулченах, но не суть.
Сейчас поправлю.
У вас проявляется из-за различия в тулченах, но не суть.
Сейчас поправлю.
FS
11:37
Fat Solko
In reply to this message
буду очень рад если это поправит ситуацию, уже неделю голову ломаю)
boolean invited boolean
Л(
b
12:40
boolean
In reply to this message
Hi, has this issue been solved? I got the same compile issue on my x64 device(MacBook and a AWS x64 instance), BTW I use the latest v0.12.1.
Л(
12:45
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Yes, it is fixed, but in the
master branch after the 0.12.1 release.
b
12:49
boolean
that is great, I will have a try, thx.
12:50
Could give it a tag or release? so we can update our repo.
13:03
Just tried with
master branch, it works for me.
👍
Л(
b
13:28
boolean
Sorry, it works on my MacBook, but still fail on my AWS x64, same error:
`/root/larry/akula/target/debug/deps/libmdbx_sys-c7193f857e49b563.rlib(mdbx.o): In function `scan4seq_resolver':
/root/.cargo/registry/src/github.com-1ecc6299db9ec823/mdbx-sys-0.12.1-0/libmdbx/mdbx.c:9863: undefined reference to `__cpu_indicator_init'
/root/.cargo/registry/src/github.com-1ecc6299db9ec823/mdbx-sys-0.12.1-0/libmdbx/mdbx.c:9866: undefined reference to `__cpu_model'
/root/.cargo/registry/src/github.com-1ecc6299db9ec823/mdbx-sys-0.12.1-0/libmdbx/mdbx.c:9870: undefined reference to `__cpu_model'
/root/.cargo/registry/src/github.com-1ecc6299db9ec823/mdbx-sys-0.12.1-0/libmdbx/mdbx.c:9874: undefined reference to `__cpu_model'
collect2: error: ld returned 1 exit status`
`/root/larry/akula/target/debug/deps/libmdbx_sys-c7193f857e49b563.rlib(mdbx.o): In function `scan4seq_resolver':
/root/.cargo/registry/src/github.com-1ecc6299db9ec823/mdbx-sys-0.12.1-0/libmdbx/mdbx.c:9863: undefined reference to `__cpu_indicator_init'
/root/.cargo/registry/src/github.com-1ecc6299db9ec823/mdbx-sys-0.12.1-0/libmdbx/mdbx.c:9866: undefined reference to `__cpu_model'
/root/.cargo/registry/src/github.com-1ecc6299db9ec823/mdbx-sys-0.12.1-0/libmdbx/mdbx.c:9870: undefined reference to `__cpu_model'
/root/.cargo/registry/src/github.com-1ecc6299db9ec823/mdbx-sys-0.12.1-0/libmdbx/mdbx.c:9874: undefined reference to `__cpu_model'
collect2: error: ld returned 1 exit status`
Л(
13:30
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Seems this is toolchain's bug.
However, you could use
However, you could use
MDBX_HAVE_BUILTIN_CPU_SUPPORTS=0 build option as a workaround.
b
13:54
boolean
MDBX_HAVE_BUILTIN_CPU_SUPPORTS=0 works, will it have any side effect?
AV
13:57
Artem Vorotnikov
what is your AWS environment?
Л(
13:57
Леонид Юрьев (Leonid Yuriev)
In reply to this message
It disables choosing implementation of scan-function at runtime depending on the available CPU features.
For x86_64 this means that SSE2-based acceleration (i.e. ×4) will be used always, but never AVX2 (×8) nor AVX512 (×16).
For x86_64 this means that SSE2-based acceleration (i.e. ×4) will be used always, but never AVX2 (×8) nor AVX512 (×16).
b
14:03
My MacBook use Clang v14.0.0, maybe the Clang version matters. But I failed to upgrade AWS's clang to v14.0.0, it has lots of dependencies... failed to upgrade glibc to v2.7 in my case.
AV
Л(
14:04
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Apple's clang is broken, i.e. for OSX/Apple cases the
MDBX_HAVE_BUILTIN_CPU_SUPPORTS=0 is just forced by default.
b
14:05
boolean
😢
14:07
Artem, should we upgrade to use the latest libmdbx, i.e. the current master branch and disbale the macro?
MDBX_HAVE_BUILTIN_CPU_SUPPORTS=0
AV
14:09
if AWS provides only ancient environment, forget AWS, use any other cloud provider for there are hundreds of them
👍
b
Л(
b
14:09
boolean
yes, agree, we should upgrade the toolchain
q invited q
15 September 2022
Victor invited Victor
16 September 2022
b
06:03
boolean
In reply to this message
Just some updates of the previous compile error of
- MacBook: x86_64 clang v14.0.0 ==> compile failed with
- AWS: x86_64 clang v12.0.1, Glibc v2.26. ==> compile failed with
- GCP: x86_64 clang v12.0.0, Glibc v.2.31 ==> compile succeed with
** Summary: glibc version matters.
libmdbx:- MacBook: x86_64 clang v14.0.0 ==> compile failed with
v0.12.1, but succeed with master- AWS: x86_64 clang v12.0.1, Glibc v2.26. ==> compile failed with
v0.12.1 and master- GCP: x86_64 clang v12.0.0, Glibc v.2.31 ==> compile succeed with
v0.12.1** Summary: glibc version matters.
👍
AV
Л(
Л(
19:31
Леонид Юрьев (Leonid Yuriev)
В программу конференции HighLoad++ заявлен доклад о libmdbx.
https://highload.ru/moscow/2022/abstracts/9342
В текущем понимании тема слишком специфична и не интересна большинству участников/посетителей.
Просьба проголосовать (тут https://t.me/HighLoadTalks/42714), если есть мнение по этому вопросу.
https://highload.ru/moscow/2022/abstracts/9342
В текущем понимании тема слишком специфична и не интересна большинству участников/посетителей.
Просьба проголосовать (тут https://t.me/HighLoadTalks/42714), если есть мнение по этому вопросу.
KS
20:17
Klen Santakheza
добавил голос за.
AV
20:24
Artem Vorotnikov
Поставил лайк в чате
Л(
20:25
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Со-докладчиком никто случайно не желает?
РЛ
21:14
Руслан Лайшев
CellFrame байда тоже переведена на LibMDBX, правда это совсем не эфир, крипта хуторского масштаба, но всё же.
Лайк!
Лайк!
Л(
17 September 2022
AS
12:23
Alex Sharov
In reply to this message
Записи предыдущих докладов автора на highload (на youtube) мне были сильно полезны по разным причинам. Поэтому я очень плюсую.
23 September 2022
SC
16:37
Simon C.
Does the min linux version also apply to Android devices? There is a ton of Android devices out there < linux 4.0.0
Л(
SC
17:06
Simon C.
About 10-12% of all active (connected to Google Play at least once per month) Android phones run 3.x Linux versions 🙁
Is there an advantage in dropping support for 3.x?
Is there an advantage in dropping support for 3.x?
Л(
17:29
Леонид Юрьев (Leonid Yuriev)
In reply to this message
The longest-lived version of the 3.x branch was 3.16.85
Its EOL and support ended more than two years ago.
So, about 10-12% of Android devices should have received an update more than two years ago, otherwise it's time to throw them away.
on the my side: I have neither the need, nor the desire, nor the resources to ensure (and test) compatibility with such outdated kernels.
Its EOL and support ended more than two years ago.
So, about 10-12% of Android devices should have received an update more than two years ago, otherwise it's time to throw them away.
on the my side: I have neither the need, nor the desire, nor the resources to ensure (and test) compatibility with such outdated kernels.
AV
17:34
Artem Vorotnikov
In reply to this message
for context, Akula does NOT support Linux stack older than what's in the latest mainstream distro LTS releases
@erthink is being very generous here
@erthink is being very generous here
SC
18:05
Simon C.
In reply to this message
Most of those devices are owned by people who just don't have the money to buy a new one so I'm not sure that is a solid argument.
I respect this decision however and will take care of the support of those devices in a fork 🙂
I don't know what Akula is 😅
I respect this decision however and will take care of the support of those devices in a fork 🙂
I don't know what Akula is 😅
Л(
20:57
Леонид Юрьев (Leonid Yuriev)
In reply to this message
I think it is much more appropriate to ask the manufacturers of these devices about why they do not provide support nor updates for the money paid to them, etc.
However, the libmdbx v0.11.11 is still available, and should run on 2.6.32.
But for new/modern v0.12.x, (I assume) is unreasonable to provide compatibility with obsolete platforms, any maintenance for which ended more than two years ago.
// Akula = Ethereum + Rust + libmdbx
However, the libmdbx v0.11.11 is still available, and should run on 2.6.32.
But for new/modern v0.12.x, (I assume) is unreasonable to provide compatibility with obsolete platforms, any maintenance for which ended more than two years ago.
// Akula = Ethereum + Rust + libmdbx
4 October 2022
Сергей Мирянов invited Сергей Мирянов
5 October 2022
СМ
09:19
Сергей Мирянов
Коллеги, добрый день.
Помогите, пожалуйста, разобраться с работой gc в libmdbx.
у меня маленькая БД:
Current mapsize: 5767168 bytes, 1408 pages
Current datafile: 5767168 bytes, 1408 pages
В БД хранится "дерево", с каждым узлом дерева связан словарь атрибутов (msgpack).
на одном из вырожденных сценариев (вряд ли он будет в production, но я его использую для тестирования
производительности) - удаление поочередно всех атрибутов у всех узлов.
Удаление пробовал делать как с удалением атрибутов так и с пометкой флага удаления (в надежде что в этом случае
размер value не будет меняться).
На этом сценарии libmdbx очень много (на мой взгляд) времени проводит в gc - для 5300 операций общее время
более 3 секунд.
При этом если смотреть во времени - то для первой тысячи операций gc выше 1 мс происходит почти постоянно,
от второй тысячи до третьей - реже, после третьей совсем реже.
Хотелось бы понять - это ожидаемое поведение или можно его как то "затюнить"? У меня получается "затюнить" это поведение
оставив размер MDBX_opt_sync_bytes по умолчанию, но в этом случае у меня вырастает время выполнения mdbx_put, что меня
не очень устраивает. Но при этом поведение gc остается примерно таким же.
Документацию прочитал уже несколько раз, тикеты на гитхабе тоже - может у меня замылился глаз и я чего то пропускаю?
Помогите, пожалуйста, разобраться с работой gc в libmdbx.
у меня маленькая БД:
Current mapsize: 5767168 bytes, 1408 pages
Current datafile: 5767168 bytes, 1408 pages
В БД хранится "дерево", с каждым узлом дерева связан словарь атрибутов (msgpack).
на одном из вырожденных сценариев (вряд ли он будет в production, но я его использую для тестирования
производительности) - удаление поочередно всех атрибутов у всех узлов.
Удаление пробовал делать как с удалением атрибутов так и с пометкой флага удаления (в надежде что в этом случае
размер value не будет меняться).
На этом сценарии libmdbx очень много (на мой взгляд) времени проводит в gc - для 5300 операций общее время
более 3 секунд.
При этом если смотреть во времени - то для первой тысячи операций gc выше 1 мс происходит почти постоянно,
от второй тысячи до третьей - реже, после третьей совсем реже.
Хотелось бы понять - это ожидаемое поведение или можно его как то "затюнить"? У меня получается "затюнить" это поведение
оставив размер MDBX_opt_sync_bytes по умолчанию, но в этом случае у меня вырастает время выполнения mdbx_put, что меня
не очень устраивает. Но при этом поведение gc остается примерно таким же.
Документацию прочитал уже несколько раз, тикеты на гитхабе тоже - может у меня замылился глаз и я чего то пропускаю?
{kind=link}
{kind=link}
09:21
версия вчерашний мастер
Л(
10:35
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Есть подозрение, что вы используете отладочную сборку без
-DNDEBUG.
СМ
10:38
Сергей Мирянов
да, у меня были такие подозрения вчера. но насколько я понимаю VS в релизе устанавливает этот флаг.
вот список из студии:
/ifcOutput "mdbx.dir\Release\" /GS- /GL /W4 /Gy /Zc:wchar_t /I"D:\Sources\thirdparty\libmdbx\src" /Gm- /Ox /Ob2 /Fd"mdbx.dir\Release\vc142.pdb" /Zc:inline /fp:precise /D "_WINDLL" /D "_MBCS" /D "WIN32" /D "_WINDOWS" /D "NDEBUG" /D "LIBMDBX_EXPORTS" /D "MDBX_BUILD_SHARED_LIBRARY=1" /D "__STDC_FORMAT_MACROS=1" /D "__STDC_LIMIT_MACROS=1" /D "__STDC_CONSTANT_MACROS=1" /D "_HAS_EXCEPTIONS=1" /D "MDBX_BUILD_FLAGS_CONFIG=\"/Ox /Ob2 /DNDEBUG /GS- \"" /D "MDBX_BUILD_TYPE=\"Release\"" /D "MDBX_CONFIG_H=\"D:/Sources/thirdparty/libmdbx/build/config.h\"" /D "CMAKE_INTDIR=\"Release\"" /D "mdbx_EXPORTS" /errorReport:prompt /WX /Zc:forScope /Gd /MD /Fa"mdbx.dir\Release\" /EHsc /nologo /Fo"mdbx.dir\Release\" /Fp"mdbx.dir\Release\mdbx.pch" /diagnostics:column
вот список из студии:
/ifcOutput "mdbx.dir\Release\" /GS- /GL /W4 /Gy /Zc:wchar_t /I"D:\Sources\thirdparty\libmdbx\src" /Gm- /Ox /Ob2 /Fd"mdbx.dir\Release\vc142.pdb" /Zc:inline /fp:precise /D "_WINDLL" /D "_MBCS" /D "WIN32" /D "_WINDOWS" /D "NDEBUG" /D "LIBMDBX_EXPORTS" /D "MDBX_BUILD_SHARED_LIBRARY=1" /D "__STDC_FORMAT_MACROS=1" /D "__STDC_LIMIT_MACROS=1" /D "__STDC_CONSTANT_MACROS=1" /D "_HAS_EXCEPTIONS=1" /D "MDBX_BUILD_FLAGS_CONFIG=\"/Ox /Ob2 /DNDEBUG /GS- \"" /D "MDBX_BUILD_TYPE=\"Release\"" /D "MDBX_CONFIG_H=\"D:/Sources/thirdparty/libmdbx/build/config.h\"" /D "CMAKE_INTDIR=\"Release\"" /D "mdbx_EXPORTS" /errorReport:prompt /WX /Zc:forScope /Gd /MD /Fa"mdbx.dir\Release\" /EHsc /nologo /Fo"mdbx.dir\Release\" /Fp"mdbx.dir\Release\mdbx.pch" /diagnostics:column
Л(
13:33
Леонид Юрьев (Leonid Yuriev)
In reply to this message
MDBX реализует MVCC посредством COW.
Это значит, что при любых изменениях предыдущая версия/снимок данных сохраняется, а изменения производятся в копии.
Далее новая копия становится доступной при успешной фиксации транзакции.
Поэтому ваш вариант с пометкой флагом вместо удаления ничем не лучше.
Далее, не совсем понятно как именно вы выполняете 5300 изменений.
Грубо говоря - а сколько именно транзакций?
Если у вас 5300 отдельных транзакций, то на Windows это может быть близко к возможностям ОС:
- на Windows в libmdbx используются файловые блокировки (чтобы подстраховаться от неверных действий пользователя и другого софта), эти блокировки исторически довольно медленные (ибо 640К хватит всем и т.п.).
- на Windows кошмарно медленная файловая система и управление виртуальной памятью, особенно
- на Windows на работу memory-mapped БД оказывают влияния антивирусы (включая встроенный defender), это влияние не всегда прогнозируемо и иногда катастрофично.
Далее, есть две метрики по GC:
Если я правильно понимаю, то вы смотрите на второе.
Эта стадия (обновление GC) алгоритмически кошмарна сложна/запутанна, так как требуется сохранить внутри БД данные, которые зависят от состояние этой БД.
Из-за этой логической рекурсии обновление GC предполагает повторы (когда при обновлении GC меняется состояние, которое нужно сохранить).
Поэтому в пространстве состояний БД на момент фиксации транзакции, есть критические точки/домены, которые требуют больше итераций/повторов.
В целом сейчас ситуация оценивается на "хорошо с плюсом", но:
- были жалобы на всплески latency в сценариях Erigon (ethereum);
- могут быть упущения в эвристиках после реализации auto-coalesce;
- всегда могут быть какие-то специфические состояния/сценарии, которые не воспроизводятся в тестах.
Соответственно, если ваша проблема (медленное обновление GC) проявляется не только в Windows, то будет разбираться/чинить.
Это значит, что при любых изменениях предыдущая версия/снимок данных сохраняется, а изменения производятся в копии.
Далее новая копия становится доступной при успешной фиксации транзакции.
Поэтому ваш вариант с пометкой флагом вместо удаления ничем не лучше.
Далее, не совсем понятно как именно вы выполняете 5300 изменений.
Грубо говоря - а сколько именно транзакций?
Если у вас 5300 отдельных транзакций, то на Windows это может быть близко к возможностям ОС:
- на Windows в libmdbx используются файловые блокировки (чтобы подстраховаться от неверных действий пользователя и другого софта), эти блокировки исторически довольно медленные (ибо 640К хватит всем и т.п.).
- на Windows кошмарно медленная файловая система и управление виртуальной памятью, особенно
FlushViewOfFile() и FlushFileBuffers() (в процессе починки, но есть затруднения с самой ОС).- на Windows на работу memory-mapped БД оказывают влияния антивирусы (включая встроенный defender), это влияние не всегда прогнозируемо и иногда катастрофично.
Далее, есть две метрики по GC:
gcrtime_seconds16dot16 из MDBX_envinfo и gc из MDBX_commit_latency.Если я правильно понимаю, то вы смотрите на второе.
Эта стадия (обновление GC) алгоритмически кошмарна сложна/запутанна, так как требуется сохранить внутри БД данные, которые зависят от состояние этой БД.
Из-за этой логической рекурсии обновление GC предполагает повторы (когда при обновлении GC меняется состояние, которое нужно сохранить).
Поэтому в пространстве состояний БД на момент фиксации транзакции, есть критические точки/домены, которые требуют больше итераций/повторов.
В целом сейчас ситуация оценивается на "хорошо с плюсом", но:
- были жалобы на всплески latency в сценариях Erigon (ethereum);
- могут быть упущения в эвристиках после реализации auto-coalesce;
- всегда могут быть какие-то специфические состояния/сценарии, которые не воспроизводятся в тестах.
Соответственно, если ваша проблема (медленное обновление GC) проявляется не только в Windows, то будет разбираться/чинить.
SC
13:36
Simon C.
Oh that's interesting! My app also got flagged by some anti virus softwares on Windows. Is there anything I can do to make it less likely to be flagged?
СМ
13:45
Сергей Мирянов
Спасибо за подробный ответ!
1. Каждое изменение в отдельной транзакции (т.е. из 5300). У меня есть отдельный тестовый сценарий, где операции над одним узлом сгруппированы в транзакцию - там ситуация лучше.
2. По поводу файловых блокировок согласен - мы с этим столкнулись и в другом месте отказались от них (с потерей кросс-платформенности - но чинить ее будем потом). Возможно ли также в libmdbx заменить файловые блокировки на mutex например?
3. Антивирус тормозит - с этим тоже согласен. Но в пределе у нас будет end-user решение и жить с антивирусом все равно придется. Но есть эталонное легаси хранилище - и его получилось догнать только в части сценариев, хотелось бы понять в остальных мы сможем еще приблизиться или это ужу максимум.
4. Смотрю на gc из latency, код в стадии обновления GC тоже смотрел - честно, говоря стало страшно - снимаю шляпу за то что заставили его работать :)
5. Про Erigon что было видел в гитхабе (хотя понимаю что это только часть). Оттуда были идеи попробовать скомпилировать с частью отключенных флагов, но не сильно помогло.
6. Принципиально мы должны поддерживать работу на Linux - но в той части с которой я экспериментирую мы пока еще не готовы перейти, к сожалению.
Из сказанного вами получается - что остается мне только страдать :)
1. Каждое изменение в отдельной транзакции (т.е. из 5300). У меня есть отдельный тестовый сценарий, где операции над одним узлом сгруппированы в транзакцию - там ситуация лучше.
2. По поводу файловых блокировок согласен - мы с этим столкнулись и в другом месте отказались от них (с потерей кросс-платформенности - но чинить ее будем потом). Возможно ли также в libmdbx заменить файловые блокировки на mutex например?
3. Антивирус тормозит - с этим тоже согласен. Но в пределе у нас будет end-user решение и жить с антивирусом все равно придется. Но есть эталонное легаси хранилище - и его получилось догнать только в части сценариев, хотелось бы понять в остальных мы сможем еще приблизиться или это ужу максимум.
4. Смотрю на gc из latency, код в стадии обновления GC тоже смотрел - честно, говоря стало страшно - снимаю шляпу за то что заставили его работать :)
5. Про Erigon что было видел в гитхабе (хотя понимаю что это только часть). Оттуда были идеи попробовать скомпилировать с частью отключенных флагов, но не сильно помогло.
6. Принципиально мы должны поддерживать работу на Linux - но в той части с которой я экспериментирую мы пока еще не готовы перейти, к сожалению.
Из сказанного вами получается - что остается мне только страдать :)
AS
16:22
Если нужно обрабатывать много параллельных мелких апдейтов (типа вебсервера), можно сделать абстракцию которая соберет параллельные апдейты в одну пишущую транзакцию. И не будет отвечать клиенту пока коммит не пройдет - для клиента это будет выглядеть просто как «любой вызов апдейта занимает 50ms, но если он завершился то данные можно читать (read after write гарантия не нарушится). Смотрите для примера bbolt.Batch реализацию https://github.com/etcd-io/bbolt#batch-read-write-transactions
СМ
16:35
Сергей Мирянов
In reply to this message
спасибо! у меня примерно такой вариант уже реализован (в пункте 1 выше я его упоминал) и я планирую его использовать. но в существующей кодовой базе очень много старого кода, который работает не батчами, а одиночными записями. и хотелось бы чтобы с новым хранилищем существующий код не сильно просел в производительности.
можно наверное сделать батчи неявными, но этого хотелось бы избежать до последнего.
можно наверное сделать батчи неявными, но этого хотелось бы избежать до последнего.
Л(
17:23
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Если считаете что проблема всё-таки с обновлением GC, то по-возможности постарайтесь подготовить минимальный сценарий воспроизводящий проблему.
Тогда я займусь проблемой как будет время.
Кроме всего прочего, можно достаточно хорошо понять что происходит.
В отладочных сборках очень много логирования.
Поэтому достаточно установить логгер (см
Тогда я займусь проблемой как будет время.
Кроме всего прочего, можно достаточно хорошо понять что происходит.
В отладочных сборках очень много логирования.
Поэтому достаточно установить логгер (см
mdbx_setup_debug()) и посмотреть что происходит при коммите.
AS
17:25
Alex Sharov
Еще можно уменьшить влияние GC увеличив размер страницы. Меньше страниц - меньше работы GC.
Л(
17:29
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Не поможет.
Судя по сценарию там совсем не ваш случай (всего 1408 страниц в БД).
Соответственно, вся GC помещается в несколько страниц, а причина проблем (если они не из-за винды) в каком-то "резонансе" с auto-coalesce при обновлении GC.
Судя по сценарию там совсем не ваш случай (всего 1408 страниц в БД).
Соответственно, вся GC помещается в несколько страниц, а причина проблем (если они не из-за винды) в каком-то "резонансе" с auto-coalesce при обновлении GC.
СМ
18:35
Сергей Мирянов
In reply to this message
да, я сейчас занимаюсь этим. осложняет ситуацию то что у меня это все проброшено в питон и основная логика на питоне - просто так собрать в дебаге не получится. поэтому сейчас собрать минимальный пример попробую.
размер страницы увеличивал - это действительно в моем случае не помогает. думаю что в основном потому что у меня маленькая БД.
размер страницы увеличивал - это действительно в моем случае не помогает. думаю что в основном потому что у меня маленькая БД.
6 October 2022
AV
10:48
Artem Vorotnikov
Какие минусы от установки большого максимального количества читателей?
Л(
10:56
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Если реальных читателей будет мало, то разницы примерно нет.
Только LCK-файл будет больше, ну и можно не заметить появления лишних читателей из-за ошибок (не завершения транзакций).
Если же читателей действительно становиться большое, но линейно увеличивается стоимость сканирования таблицы читателей.
см
Только LCK-файл будет больше, ну и можно не заметить появления лишних читателей из-за ошибок (не завершения транзакций).
Если же читателей действительно становиться большое, но линейно увеличивается стоимость сканирования таблицы читателей.
см
git grep oldest_reader
AV
Л(
11:11
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Максимум 32767 читателей, на каждого уходит по одной кэш-линии, плюс общий заголовок LCK-файла.
СМ
20:08
Сергей Мирянов
In reply to this message
@erthink у меня получилось повторить это на минимальном пример - выложил пример сюда - https://github.com/sergey-miryanov/xx_mdbx
👍
Л(
20:11
в интерфейс на с++ пришлось добавить одну функцию
void txn_managed::commit(MDBX_commit_latency* latency) {
const error err = static_cast<MDBX_error_t>(::mdbx_txn_commit_ex(handle_, latency));
if (MDBX_LIKELY(err.code() != MDBX_THREAD_MISMATCH))
MDBX_CXX20_LIKELY handle_ = nullptr;
if (MDBX_UNLIKELY(err.code() != MDBX_SUCCESS))
MDBX_CXX20_UNLIKELY err.throw_exception();
}
void txn_managed::commit(MDBX_commit_latency* latency) {
const error err = static_cast<MDBX_error_t>(::mdbx_txn_commit_ex(handle_, latency));
if (MDBX_LIKELY(err.code() != MDBX_THREAD_MISMATCH))
MDBX_CXX20_LIKELY handle_ = nullptr;
if (MDBX_UNLIKELY(err.code() != MDBX_SUCCESS))
MDBX_CXX20_UNLIKELY err.throw_exception();
}
👍
Л(
Л(
20:15
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Добавлю в API.
Исторически сбор информация о задержках был добавлен в экспериментальную ветку для Erigon, когда C++ API уже был.
Поэтому до сих пор в C++ API этого не было.
Исторически сбор информация о задержках был добавлен в экспериментальную ветку для Erigon, когда C++ API уже был.
Поэтому до сих пор в C++ API этого не было.
👍
СМ
Л(
22:32
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Буду смотреть, может быть даже сегодня.
Кроме этого, в devel-ветку на gitflic только-что пролиты (вроде-бы) рабочие правки с поддержкой overlapped и gather-write для Windows.
Этим закрывается одна из давних недоделок и причина отставания MDBX от LMDB в некоторых сценариях на Windows (из-за жуткой тормознутости
Просьба по-возможности попробовать/потестировать (все доработки всё равно будут от этой ветки).
Кроме этого, в devel-ветку на gitflic только-что пролиты (вроде-бы) рабочие правки с поддержкой overlapped и gather-write для Windows.
Этим закрывается одна из давних недоделок и причина отставания MDBX от LMDB в некоторых сценариях на Windows (из-за жуткой тормознутости
FlushViewOfFile() и FlushFileBuffers()).Просьба по-возможности попробовать/потестировать (все доработки всё равно будут от этой ветки).
СМ
7 October 2022
Л(
02:11
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Попробовал ваш сценарий, ни сразу, но разобрался.
Выявился дефект/упущение в логике/эвристиках, который при пустой GC в режиме
При исправлении "костылем" суммарная задержка падает с 3-4 секунд до сотен миллисекунд.
Завтра подумаю как исправить по-хорошему.
Выявился дефект/упущение в логике/эвристиках, который при пустой GC в режиме
MDBX_SAFE_NOSYNC приводит к принудительному сбросу данных на диск при подготовке задела страниц и слотов перед обновлением GC.При исправлении "костылем" суммарная задержка падает с 3-4 секунд до сотен миллисекунд.
Завтра подумаю как исправить по-хорошему.
👍
СМ
Л(
17:12
Леонид Юрьев (Leonid Yuriev)
@miryanovsn, в ветке devel на gitflic доступно исправление.
Оно прошло CI и дополнительные тесты, т.е. можно брать в разработку и дальнейшее тестирование.
Оно прошло CI и дополнительные тесты, т.е. можно брать в разработку и дальнейшее тестирование.
👍
СМ
СМ
22:22
Сергей Мирянов
In reply to this message
стало сильно лучше, спасибо!
теперь gc занимает менее 10мс в отличии от 3сек. но выросли write и sync - что наверное и должно быть. в текущей реализации смущает только то что для первого коммита уже есть синхронизация - понятно что она занимает пару милисекунд, но я не ожидал ее там увидеть.
отдельное спасибо за то что починил latency для замеров менее 1/65536.
теперь gc занимает менее 10мс в отличии от 3сек. но выросли write и sync - что наверное и должно быть. в текущей реализации смущает только то что для первого коммита уже есть синхронизация - понятно что она занимает пару милисекунд, но я не ожидал ее там увидеть.
отдельное спасибо за то что починил latency для замеров менее 1/65536.
22:23
In reply to this message
вот это тоже посмотрел - но судя по всему на моих объемах оно не заметно. в планах собрать тест для более крупной базы - но там еще с моей стороны есть работы - как сделаю - сообщу о результатах.
10 October 2022
Mikl invited Mikl
Л(
17:35
Леонид Юрьев (Leonid Yuriev)
Не релиз, но существенное обновление, см https://libmdbx.dqdkfa.ru/md__change_log.html
@AskAlexSharov, скоро (может быть даже сегодня) займусь всплесками задержки при обновлении GC в ваших сценариях.
@AskAlexSharov, скоро (может быть даже сегодня) займусь всплесками задержки при обновлении GC в ваших сценариях.
👍
СМ
🔥
SC
G
Л(
17:38
Леонид Юрьев (Leonid Yuriev)
In reply to this message
А теперь всё по-русски.
Переход был анансирован еще весной.
Переход был анансирован еще весной.
😢
SC
G
Л(
17:39
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Потому-что нет смысла переводить только "чтобы перевести".
SC
17:40
Simon C.
I think for international projects it would be awesome to keep the project bilingual. I thought the previous mix was quite a good solution
RS
17:40
Roman Sergeev
overlapped для windows - хорошая новость
G
18:45
G
под riscv64 кросскомпиляцией нормально собирается и вроде работает mdbx_example, почему в Gnumakefile нет компилятора riscv64-linux-gnu-gcc ?
Л(
20:09
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Я не против если кто-то будет переводить материалы и/или облагораживать документацию.
При желании можете сами создать аккаунт на gitflc и добавлять подобные изменение посредством pull-requests.
При желании можете сами создать аккаунт на gitflc и добавлять подобные изменение посредством pull-requests.
20:11
In reply to this message
Рома, на всякий случай - пока асинхронная запись только в при синхронном коммите, т.е. с полным ожиданием.
Т.е. речь сугубо о преодолении внутренних проблем/недостатков ядра винды.
Т.е. речь сугубо о преодолении внутренних проблем/недостатков ядра винды.
20:16
In reply to this message
Исторически были проблемы с кросс-компиляцией для R5.
Не было готовых пакетов для alt/astra/fedora/ubuntu, а в самом компиляторе были проблемы с C11 атомиками.
Собственно и сейчас нет нормальной поддержки в QEMU (не понимает часть системных вызовов и т.п.).
Тем не менее, добавил.
Не было готовых пакетов для alt/astra/fedora/ubuntu, а в самом компиляторе были проблемы с C11 атомиками.
Собственно и сейчас нет нормальной поддержки в QEMU (не понимает часть системных вызовов и т.п.).
Тем не менее, добавил.
SC
G
20:28
G
In reply to this message
сегодня кросскопилировал libmdbx под riscv64 успешно и запускал mdbx_example в qemu ubuntu 22.04 riscv64 вроде успешно
Л(
20:34
Леонид Юрьев (Leonid Yuriev)
In reply to this message
На всякий - я имел в виду запуск через qemu-riscv64-static.
Сегодня в
В qemu подобных проблем много.
Сегодня в
qemu-riscv64 version 6.2.0 (Debian 1:6.2+dfsg-2ubuntu6.4) не заработало, если не ошибаюсь то проблема в отсутствии поддержки OFD-блокировок для fcntl().В qemu подобных проблем много.
G
20:55
G
In reply to this message
./mdbx_test basic
RESULT: Successful
CPU: user 3.422619, system 9.815496
IOPs: read 48, write 0
RAM: 10188 Kb
Paging: reclaims 3249, faults 40, swaps 0
RESULT: Successful
CPU: user 3.422619, system 9.815496
IOPs: read 48, write 0
RAM: 10188 Kb
Paging: reclaims 3249, faults 40, swaps 0
Л(
23:39
Леонид Юрьев (Leonid Yuriev)
@AskAlexSharov, в ветке 4erigon на gitflic подготовил отладку для всплесков задержки в ваших сценариях.
Там по-сути две правки:
1. Добавлены три накопительных счетчика в pgos (gc_rloops, gc_wloops, gc_xpages).
2. Добавлено повышение уровня логирования изнутри update_gc() начиная со второго цикла.
Соответственно добавленные счетчики хотелось-бы увидеть на дашборе и получить лог после воспроизведения проблемы (пишите в личку по готовности).
Там по-сути две правки:
1. Добавлены три накопительных счетчика в pgos (gc_rloops, gc_wloops, gc_xpages).
2. Добавлено повышение уровня логирования изнутри update_gc() начиная со второго цикла.
Соответственно добавленные счетчики хотелось-бы увидеть на дашборе и получить лог после воспроизведения проблемы (пишите в личку по готовности).
11 October 2022
AS
03:21
Alex Sharov
Спасибо
Л(
21:09
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Пока не за что )
Когда можно ждать результатов?
Когда можно ждать результатов?
12 October 2022
AS
14:38
Alex Sharov
на следующей неделе возьмусь, но думаю займет долго
Л(
23:40
Леонид Юрьев (Leonid Yuriev)
libmdbx 0.11.12 (Эребуни)
The stable bugfix release:
- Fixed static assertion failure on platforms where the
- Fixed assertion check inside
- Fixed
- Removed needless
https://gitflic.ru/project/erthink/libmdbx/release/f7a1dc42-f85f-406e-bd8f-f038fe53864d
The stable bugfix release:
- Fixed static assertion failure on platforms where the
off_t type is wider than corresponding fields of struct flock used for file locking. Now libmdbx will use fcntl64(F_GETLK64/F_SETLK64/F_SETLKW64) if available.- Fixed assertion check inside
page_retire_ex().- Fixed
-Wint-to-pointer-cast warnings while casting to mdbx_tid_t.- Removed needless
LockFileEx() inside mdbx_env_copy().https://gitflic.ru/project/erthink/libmdbx/release/f7a1dc42-f85f-406e-bd8f-f038fe53864d
👍
СМ
🔥
SC
13 October 2022
YS
16:48
Yevhenii Skrebtsov
2022-10-13T13:20:15.570403Z INFO { 12/12 Finish }: DONE @ 15739453 in 00:00:00.000
2022-10-13T13:20:15.570425Z INFO Staged sync complete. Headers=00:00:04.700 TotalGasIndex=00:00:00.000 BlockHashes=00:00:00.000 Bodies=00:00:04.193 TotalTxIndex=00:00:00.008 SenderRecovery=00:00:00.020 Execution=00:00:02.269 AccountHistoryIndex=00:00:00.935 StorageHistoryIndex=00:00:01.474 TxLookup=00:00:01.058 CallTraces=00:00:02.688 Finish=00:00:00.000
akula: mdbx:9268: map_resize: Assertion `size_bytes == env->me_dxb_mmap.current' failed.
[1] 1111536 IOT instruction (core dumped)OS: Linux
libmdbx version: 0.12.1.0
Л(
21:17
Леонид Юрьев (Leonid Yuriev)
In reply to this message
В текущем понимании это лишняя и/или слишком строгая проверка в какой-то странной ситуации, которая не воспроизводится в тестах (в том числе в стохастическом).
Чтобы понять в чем именно дело и поправить - нужна дополнительная информация, чем больше тем лучше:
- в читающей или пишущей транзакции это произошло?
- была ли БД открыта в режиме только-чтения или чтения-записи?
- что делали с БД другие потоки и/или процессы?
- если ли возможность получить трассировку стека, информацию о локальных переменных, сам дамп?
- есть ли сценарий воспроизведения (без загрузки всех терабайтов БД)?
@vorot93, может что-то подскажешь?
Чтобы понять в чем именно дело и поправить - нужна дополнительная информация, чем больше тем лучше:
- в читающей или пишущей транзакции это произошло?
- была ли БД открыта в режиме только-чтения или чтения-записи?
- что делали с БД другие потоки и/или процессы?
- если ли возможность получить трассировку стека, информацию о локальных переменных, сам дамп?
- есть ли сценарий воспроизведения (без загрузки всех терабайтов БД)?
@vorot93, может что-то подскажешь?
YS
21:29
Yevhenii Skrebtsov
In reply to this message
1. без понятия, так как были активны как и read, так и одна write транзакция.
2. чтение-запись.
3. В одном потоке была активна write транзакция, в нескольких других - read.
2. чтение-запись.
3. В одном потоке была активна write транзакция, в нескольких других - read.
Л(
22:02
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Тогда примерно так:
Чтобы проблема вас не беспокоила можно просто закомментировать эту проверку.
В худшем случае, будет падение (без повреждения БД), но скорее всего вы ничего не заметите.
Как вариант, можно просто вообще отключить assert-проверки при сборке.
Если же хотите помочь разобраться с проблемой, то мне нужны ответы на вопросы выше.
Как максимальный вариант: попробуйте воспроизвести проблему под gdb и дать мне доступ по ssh.
Со своей стороны я попробую покурить код...
Чтобы проблема вас не беспокоила можно просто закомментировать эту проверку.
В худшем случае, будет падение (без повреждения БД), но скорее всего вы ничего не заметите.
Как вариант, можно просто вообще отключить assert-проверки при сборке.
Если же хотите помочь разобраться с проблемой, то мне нужны ответы на вопросы выше.
Как максимальный вариант: попробуйте воспроизвести проблему под gdb и дать мне доступ по ssh.
Со своей стороны я попробую покурить код...
YS
22:03
Yevhenii Skrebtsov
In reply to this message
проблемы нет после перезапуска, просто единоразово упало на проверке
14 October 2022
Л(
00:44
Ошибок я не нашел. Но в этом коммите больше контроля (ассертов) и добавлена защита от дефекта mremap.
Л(
13:46
Леонид Юрьев (Leonid Yuriev)
@Eugeen01, @vorot93, для продолжения исследования обозначенной проблемы просьба обновиться сегодняшнего master-а (39c6387d).
@AskAlexSharov, ветку 4erigon с отладкой всплесков задержки также обновил.
@AskAlexSharov, ветку 4erigon с отладкой всплесков задержки также обновил.
👍
AV
YS
AS
YS
15 October 2022
Максим Крюков invited Максим Крюков
Л(
13:22
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Links to machine translation was added to the ChangeLog,
https://gitflic.ru/project/erthink/libmdbx/blob?file=ChangeLog.md
https://gitflic.ru/project/erthink/libmdbx/blob?file=ChangeLog.md
SC
14:02
Simon C.
Thank you 🙏
20 October 2022
FS
16:16
Fat Solko
Почему может всплывать эта ошибка?
CMake Error at 3rd/libmdbx/cmake/utils.cmake:148 (message):
Please fetch tags (no any tags for 141 commits)
Call Stack (most recent call first):
3rd/libmdbx/CMakeLists.txt:553 (fetch_version)
-- Configuring incomplete, errors occurred!
16:17
при этом она появляется только при билде из под shell гитлаб раннера, если билдить через shell ручками вводя те же команды, билд проходит без ошибок
Л(
FS
16:19
Fat Solko
получается нужно
git fetch --tags из папки с либой запустить?
Л(
16:21
Леонид Юрьев (Leonid Yuriev)
In reply to this message
RTFM.
Для сборки не-амальгамированной версии нужны теги git, а как именно это обеспечить зависит как от версии git, так и от того как именно был клонирован репозиторий для сборки.
Короче, RTFM.
Для сборки не-амальгамированной версии нужны теги git, а как именно это обеспечить зависит как от версии git, так и от того как именно был клонирован репозиторий для сборки.
Короче, RTFM.
FS
16:23
Fat Solko
репозиторий клонирован через сабмодуль
25 October 2022
Л(
22:33
Леонид Юрьев (Leonid Yuriev)
В libmdbx API добавлена функция
https://libmdbx.dqdkfa.ru/group__c__settings.html#ga3f45781963bf17c72b25422547a1fd7b
mdbx_env_warmup().https://libmdbx.dqdkfa.ru/group__c__settings.html#ga3f45781963bf17c72b25422547a1fd7b
Л(
23:10
Леонид Юрьев (Leonid Yuriev)
В текущем понимании ветка
Поэтому по-возможности просьба попробовать на полигонах и отписать от результатах.
Если не будет замечено проблем, то я постараюсь сделать релизы по-быстрее.
master сейчас готова для релиза.Поэтому по-возможности просьба попробовать на полигонах и отписать от результатах.
Если не будет замечено проблем, то я постараюсь сделать релизы по-быстрее.
🎉
SC
i
YS
4
1 November 2022
Л(
19:04
Леонид Юрьев (Leonid Yuriev)
В сентябре я писал (https://t.me/libmdbx/3762) что подал заявку выступление на конференции Highload++.
А сегодня поучаствовал во "встрече программного комитета HighLoad++ с IT-сообществом".
Нах-нах-нах... Испанский стыд, что я собирался участвовать в этой "тусовке".
А сегодня поучаствовал во "встрече программного комитета HighLoad++ с IT-сообществом".
Нах-нах-нах... Испанский стыд, что я собирался участвовать в этой "тусовке".
i
19:06
igors
А если не секрет что там такое было))))
AA
19:16
Alexey Akhunov
In reply to this message
Я как раз проверял несколько дней назад программу чтобы посмотреть, включили ли они доклад или нет. И не нашёл его там
Л(
19:17
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Не хочу показаться фарисеем, но для меня достаточно важны как профессиональные, так и личностные качества.
А сейчас эти качества там в большом дефиците, при переизбытке позерства и т.д., даже с поправкой что любая конференция - это шоу.
А сейчас эти качества там в большом дефиците, при переизбытке позерства и т.д., даже с поправкой что любая конференция - это шоу.
РЛ
19:39
Руслан Лайшев
О причинах не было сказано ?
AV
20:26
Artem Vorotnikov
In reply to this message
соевые куколды не добежавшие до Верхнего Ларса? )
👍
АМ
Л(
Л(
20:26
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Отвечу подробно, чтобы снять максимум вопросов.
Кратко:
- Доклад забуксовал на стадии обсуждения с ПК.
- У меня возникли сомнения, из-за нехватки времени включил тормоза, в результате доклад тихо не взяли.
- При этом какой-либо предвзятости или вины ПК (программного комитета) в этом случае точно нет.
Для понимания истории, логика процесса была такая:
0. Посещение хайлода платное, вход порядка 25-50 тысяч рублей ($500-750).
Поэтому посетители вправе ожидать подготовленное шоу, т.е. программу которая им будет интересна.
1. Давно известно "в среднем" большинство посетителей хайлоада не хочет просто докладов, а идет на "замануху" где уровень заявляется "круче вареных яиц".
Применительно к libmdbx это означает, что тема просто о "key-value storage" не интересна, в том числе приелась и изъезжена.
2. Для обозначение "крутизны" предполагалось зайти со стороны Ethereum, как специфичного нагруженного кейса, где экономия "на спичках" даёт ощутимый результат.
На это со стороны ПК последовало предостережение, что тема крипты у публики малопопулярна.
Соответственно, ПК предложил подготовить план доклада для оценки.
3. Со своей стороны я пытался оценить интерес публики, как к key-value, так и к ethereum.
В сухом остатке оказалось что ПК прав - большинство посетителей HL реально не представляют как внутри работает ни key-value storage, ни узел ethereum.
Поэтому у публики (в среднем) не было-бы понимания ни проблематики (откуда задачи и почему они важны), ни результатов (насколько круто или не круто, что-то там сделано внутри).
Итого:
Получилось что посетителям HL (в среднем) не интересно что там сделано за последние 2-3 года в какой-то libmdbx или каких-то Erigon/Akula/Silkworm.
А если не говорить про новое, то получится примерно повтор одного из докладов, которые я уже делал (в том числе на HL) 5-7 лет назад (как о libmdbx, так и о её применении в libfpta).
Конечно, всё-равно можно было "поучаствовать в шоу" и сделать хороший осмысленный доклад, но:
- на хайлод примерно перестали ходить реальные грамотные разработчики (не знаю ни одного кто был больше одного раза за последние 5 лет).
- пошел сильный крен от разработки в эксплуатацию, под "как сделать" подразумевается "как настроить разработанное кем-то".
- посматривая на программу я сильно растерял желание участвовать, тем более с учетом нехватки времени.
Кратко:
- Доклад забуксовал на стадии обсуждения с ПК.
- У меня возникли сомнения, из-за нехватки времени включил тормоза, в результате доклад тихо не взяли.
- При этом какой-либо предвзятости или вины ПК (программного комитета) в этом случае точно нет.
Для понимания истории, логика процесса была такая:
0. Посещение хайлода платное, вход порядка 25-50 тысяч рублей ($500-750).
Поэтому посетители вправе ожидать подготовленное шоу, т.е. программу которая им будет интересна.
1. Давно известно "в среднем" большинство посетителей хайлоада не хочет просто докладов, а идет на "замануху" где уровень заявляется "круче вареных яиц".
Применительно к libmdbx это означает, что тема просто о "key-value storage" не интересна, в том числе приелась и изъезжена.
2. Для обозначение "крутизны" предполагалось зайти со стороны Ethereum, как специфичного нагруженного кейса, где экономия "на спичках" даёт ощутимый результат.
На это со стороны ПК последовало предостережение, что тема крипты у публики малопопулярна.
Соответственно, ПК предложил подготовить план доклада для оценки.
3. Со своей стороны я пытался оценить интерес публики, как к key-value, так и к ethereum.
В сухом остатке оказалось что ПК прав - большинство посетителей HL реально не представляют как внутри работает ни key-value storage, ни узел ethereum.
Поэтому у публики (в среднем) не было-бы понимания ни проблематики (откуда задачи и почему они важны), ни результатов (насколько круто или не круто, что-то там сделано внутри).
Итого:
Получилось что посетителям HL (в среднем) не интересно что там сделано за последние 2-3 года в какой-то libmdbx или каких-то Erigon/Akula/Silkworm.
А если не говорить про новое, то получится примерно повтор одного из докладов, которые я уже делал (в том числе на HL) 5-7 лет назад (как о libmdbx, так и о её применении в libfpta).
Конечно, всё-равно можно было "поучаствовать в шоу" и сделать хороший осмысленный доклад, но:
- на хайлод примерно перестали ходить реальные грамотные разработчики (не знаю ни одного кто был больше одного раза за последние 5 лет).
- пошел сильный крен от разработки в эксплуатацию, под "как сделать" подразумевается "как настроить разработанное кем-то".
- посматривая на программу я сильно растерял желание участвовать, тем более с учетом нехватки времени.
20:27
In reply to this message
В том числе.
Но если-бы что-то круто умели или соображали, а то основные навыки = поболтать + полизать + прогнуться...
Но если-бы что-то круто умели или соображали, а то основные навыки = поболтать + полизать + прогнуться...
i
A
20:30
Aleks Raiden | Fintech R&D
Эх а я именно этот доклад ждал ( пока пересматривая предыдущие
Л(
21:26
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Краткий план несостоявшегося доклада:
1. Пересказ "в красках" https://github.com/ledgerwatch/erigon/wiki/Criteria-for-transitioning-from-Alpha-to-Beta#switch-from-lmdb-to-mdbx и абзаца о MDBX из https://medium.com/ankr-network/ankr-contributing-to-bsc-and-implementing-erigon-performance-upgrade-178e63168a09
2. Пересказ в "в красках" содержимого https://gitflic.ru/project/erthink/libmdbx/blob?file=ChangeLog.md
3. Ответы на вопросы из зала.
Поэтому вы особо ничего не потеряли.
1. Пересказ "в красках" https://github.com/ledgerwatch/erigon/wiki/Criteria-for-transitioning-from-Alpha-to-Beta#switch-from-lmdb-to-mdbx и абзаца о MDBX из https://medium.com/ankr-network/ankr-contributing-to-bsc-and-implementing-erigon-performance-upgrade-178e63168a09
2. Пересказ в "в красках" содержимого https://gitflic.ru/project/erthink/libmdbx/blob?file=ChangeLog.md
3. Ответы на вопросы из зала.
Поэтому вы особо ничего не потеряли.
2 November 2022
Л(
12:49
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Релиз задерживается.
Багов приводящих к сбоям или потери данных не замечено, со стабильностью и надежностью всё хорошо.
Однако, обнаружено излишнее (пока не объясненное) потребление ЦПУ при поиске внутри GC и обновлении GC, всё это в сценариях Erigon (больших транзакциях, на терабайтной БД с огромным размером GC).
Скорее всего эта деградация не затрагивает другие "обычные" сценарии, но релиза не будет как минимум до понимания причин.
Дальше одно из двух:
1) Если станет понятно что изъян безобидный, но требует изменений с высоким уровнем регресса, то текущий master будет выпущен как 0.12.2 со статусом pre-release.
2) Релиз после устранения замеченного изъяна.
Кроме этого, если исследование замеченной проблемы потребует больше пары дней, то постараюсь выпустить релиз 0.11.13 из
Багов приводящих к сбоям или потери данных не замечено, со стабильностью и надежностью всё хорошо.
Однако, обнаружено излишнее (пока не объясненное) потребление ЦПУ при поиске внутри GC и обновлении GC, всё это в сценариях Erigon (больших транзакциях, на терабайтной БД с огромным размером GC).
Скорее всего эта деградация не затрагивает другие "обычные" сценарии, но релиза не будет как минимум до понимания причин.
Дальше одно из двух:
1) Если станет понятно что изъян безобидный, но требует изменений с высоким уровнем регресса, то текущий master будет выпущен как 0.12.2 со статусом pre-release.
2) Релиз после устранения замеченного изъяна.
Кроме этого, если исследование замеченной проблемы потребует больше пары дней, то постараюсь выпустить релиз 0.11.13 из
stable-ветки: workaround для encryptfs, исправления сборки для устаревших систем и экзотических конфигураций buildroot.
Л(
17:51
Леонид Юрьев (Leonid Yuriev)
Ugh, it seems it's time to recator
page_alloc_slowpath().
Matteo invited Matteo
СМ
20:49
Сергей Мирянов
@erthink Леонид, добрый день. у меня есть подозрение, что после этого коммита (https://gitflic.ru/project/erthink/libmdbx/commit/e5fc056035f194d682acd1a7bc9ba3a37459aebc) вызов mdbx_env_set_syncbytes стал возвращать MDBX_BUSY при вызове из второго и более процесса, который одновременно открывает БД.
так и задумано или это регрессия? БД открывается не в эксклюзивном режиме
так и задумано или это регрессия? БД открывается не в эксклюзивном режиме
Л(
22:29
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Нет, так не задуманно.
Это может быть регрессом, но указанный коммит не виноват.
Картина более сложная:
1.
2. в свою очередь
3.
4.
5. При сбросе данных на диск выполняется блокировка, так как потребуется обновиться мета-страницу (пометить как steady).
Эта блокировка производится только если текущий тред уже не выполняет пишущую транзакцию (и тогда владеет блокировкой).
6. В рассматриваемом случае имеем
т.е. если БД занята, то сразу будет возврат
7. На Windows я использую файловые блокировки, так как только это дает гарантию от шальных рук пользователей (были любители скопировать файл БД на ходу, а потом ругать libmdbx за поломанную БД).
8. У Windows файловые блокировки без ожидания (делались балбесами чтобы "назло бабушке уши отморозить" разблокировка регионов выполняется асинхронно внутри ядра отдельным потоком.
Это может быть регрессом, но указанный коммит не виноват.
Картина более сложная:
1.
mdbx_env_set_syncbytes() это shortcut для mdbx_env_set_option(MDBX_opt_sync_bytes);2. в свою очередь
mdbx_env_set_option(env, MDBX_opt_sync_bytes) вызывает mdbx_env_sync_poll() если БД уже открыта;3.
mdbx_env_sync_poll() это shortcut для mdbx_env_sync_ex(env, force=false, nonblock=true);4.
mdbx_env_sync_ex(env, force=false, nonblock=true) смотрит на состояние БД и заданные sync_bytes c sync_period, а если требуется сброс данных на диск, то пытается его выполнить.5. При сбросе данных на диск выполняется блокировка, так как потребуется обновиться мета-страницу (пометить как steady).
Эта блокировка производится только если текущий тред уже не выполняет пишущую транзакцию (и тогда владеет блокировкой).
6. В рассматриваемом случае имеем
mdbx_env_sync_ex(env, force=false, nonblock=true),т.е. если БД занята, то сразу будет возврат
MDBX_BUSY.7. На Windows я использую файловые блокировки, так как только это дает гарантию от шальных рук пользователей (были любители скопировать файл БД на ходу, а потом ругать libmdbx за поломанную БД).
8. У Windows файловые блокировки без ожидания (
LockFileEx(..., LOCKFILE_FAIL_IMMEDIATELY, ...) могут возвращать ложно-положительный конфликт, ибо
👍
СМ
22:38
9. Далее, Windows не умеет downgrade/upgrade для файловых блокировок.
Поэтому внутри libmdbx реализована их двух-ступенчатая эмуляция (похоже на две фазы 2PC).
Всё это хорошо отлажено/проверенно, но имеется упомянутая проблема ложно-положительного конфликта, которая проявляется только при открытии БД (когда выполняется процедура захвата блокировок).
Поэтому внутри libmdbx реализована их двух-ступенчатая эмуляция (похоже на две фазы 2PC).
Всё это хорошо отлажено/проверенно, но имеется упомянутая проблема ложно-положительного конфликта, которая проявляется только при открытии БД (когда выполняется процедура захвата блокировок).
👍
СМ
22:40
Можно подумать как это обойти/подкастылить.
Например, самый простой вариант - на Windows задавать
Например, самый простой вариант - на Windows задавать
nonblock=false при вызове mdbx_env_sync_ex() изнутри mdbx_env_set_option().
👍
СМ
M
23:14
Mark
Hey guys. What's the fastest way to determine if there are any tuples in a database at all? If I know a DB is completely empty then my code can take a more optimal path in one case. So I would like to have the most optimal way to test if a database is empty.
Л(
23:18
Леонид Юрьев (Leonid Yuriev)
In reply to this message
bool mdbx::env::is_empty() const;
bool mdbx::env::is_pristine() const;
For
bool mdbx::env::is_pristine() const;
For
C just see the implementations of these methods inside the mdbx.c++
M
23:19
Mark
Thanks. I'll take a look. I don't do any c++, so I didn't even think to look in those files.
23:20
Actually that won't work. That's for the environment. I have lots of databases in this environment
23:21
I only care if it's one particular database that is empty. There are many others with varying data
23:22
Is it quicker to call mdbx_8
23:23
Which do you think is faster: mdbx_dbi_stat or to make a cursor and stop if I can fetch one row?
Л(
23:24
Леонид Юрьев (Leonid Yuriev)
Call the
mdbx_dbi_stat(txn, dbi, &stat) and then checks stat.ms_entries.
M
23:24
Mark
Thanks!!
3 November 2022
СМ
07:07
Сергей Мирянов
In reply to this message
Спасибо за столь развернутый ответ! Постарюсь это осознать и прикинуть к своей реальности.
Л(
13:34
Леонид Юрьев (Leonid Yuriev)
In reply to this message
В качестве эксперимента попробуйте https://gitflic.ru/project/erthink/libmdbx/commit/91a6e84caba43733ad2af15e98501bdf10b07368
👍
СМ
СМ
13:35
Сергей Мирянов
спасибо, попробую - отпишусь
4 November 2022
AV
00:37
Artem Vorotnikov
In reply to this message
Не знаю насколько актуально для Вас или притянуто за уши
https://www.basealt.ru/conference/ezhegodnaja-konferencija-spo-v-vysshei-shkole
https://www.basealt.ru/conference/ezhegodnaja-konferencija-spo-v-vysshei-shkole
Л(
00:45
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Сильно принятуно.
Но буду на https://www.basealt.ru/conference/ezhegodnaja-konferencija-razrabotchikov-svobodnykh-programm
Только это следующим летом или осенью (через год).
Но буду на https://www.basealt.ru/conference/ezhegodnaja-konferencija-razrabotchikov-svobodnykh-programm
Только это следующим летом или осенью (через год).
👍
СМ
AV
5 November 2022
AS
07:10
Alex Sharov
If mv_size == 0, it means value is Nil or EmptyBytesArray?
Л(
08:02
Леонид Юрьев (Leonid Yuriev)
In reply to this message
0) Not a
1) Many KV-storages engines unable to store
2) In a native DB, just a sequence of bytes of a certain length is stored, no other abstractions.
So, in order to distinguish
With libmdbx you should do such yourself.
3) To distinguish
mv_size but the iov_len of struct iovec.1) Many KV-storages engines unable to store
EmptyBytesArray (including LMDB), but libmdbx can.2) In a native DB, just a sequence of bytes of a certain length is stored, no other abstractions.
So, in order to distinguish
Nil from EmptyBytesArray, an additional flag-prefix is placed at the beginning of the value and/or key, etc.With libmdbx you should do such yourself.
3) To distinguish
Nil from EmptyBytesArray in an instances of struct iovec the iov_base is useful, i.e. {nullptr, 0} means Nil and {"" /* any non-null pointer */, 0} means EmptyBytesArray.
AS
Л(
08:11
Леонид Юрьев (Leonid Yuriev)
In reply to this message
libmdbx (not C++ bindings) returns
Otherwise an error code, but never a
{address_inside_a_DB_page, 0} for zero-length keys and/or values (i.e. non-nullptr iov_base).Otherwise an error code, but never a
NIL.
AS
08:11
Alex Sharov
Good
Л(
12:51
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Поступила жалоба на аналогичную проблему https://gitflic.ru/project/erthink/libmdbx/issue/7
Пока мне не удалось воспроизвести её локально, ни получить какую-либо информацию для анализа (стек, локальные переменные, содержимое
Вырисовывается отдельная проблема:
К пользователям попадают отладочные сборки с включенными ассертами, а результат их страданий не доступен для использования/анализа.
Причем пользователи не в курсе включенных ассертов (неизбежным замедлением, в некоторых случаях в сотни раз), и не в состоянии предоставить информацию для анализа/отладки.
@Eugeen01, @vorot93
Пока мне не удалось воспроизвести её локально, ни получить какую-либо информацию для анализа (стек, локальные переменные, содержимое
env->me_dxb_mmap).Вырисовывается отдельная проблема:
К пользователям попадают отладочные сборки с включенными ассертами, а результат их страданий не доступен для использования/анализа.
Причем пользователи не в курсе включенных ассертов (неизбежным замедлением, в некоторых случаях в сотни раз), и не в состоянии предоставить информацию для анализа/отладки.
@Eugeen01, @vorot93
СМ
18:46
Сергей Мирянов
In reply to this message
да, этот фикс помог. по крайней мере на многопроцессных тестах ошибка перестала появляться. спасибо!
👍
Л(
Л(
18:47
Леонид Юрьев (Leonid Yuriev)
In reply to this message
На всякий - в ветке
devel следующим коммитом проблема устранена полностью.
👍
СМ
СМ
18:49
Сергей Мирянов
здорово, еще раз спасибо и за оперативные исправления и за проделанную работу!
6 November 2022
AV
Л(
14:37
Леонид Юрьев (Leonid Yuriev)
In reply to this message
1.
Просьба скопипастить на гитхаб мой ответ из https://gitflic.ru/project/erthink/libmdbx/issue/7, или хотя-бы уведомить что я ответил (gitflic не уведомляет об ответах почтой, пока не знаю почему).
В том числе, наверное стоит открыть https://github.com/vorot93/libmdbx-rs/issues/16, так как эффективность workaround не проверена и сам он не попал в версию используемую для сборки биндингов.
Оказывается у пользователей уже два месяца подгорает из-за этого
2.
Да, можно сказать есть "ошибка при сборке".
Исторически в C/C++ принято оставлять ассерты если при сборке НЕ определен макрос NDEBUG, т.е. по-умолчанию в коде остаются проверки реализованные через библиотечный макрос
Соответственно, если просто собрать, то часть ассертов остаётся, но ни сами собирающие, ни тем более пользователи не в курсе.
Буду думать и менять:
- по-умолчанию оставлю только минимум проверок, которые дешевы и страхуют от тихой потери данных.
- допишу в readme что-нибудь об этом, включая рекомендации по формированию информации необходимой для анализа подобных сбоев.
- как вариант, адаптирую/реанимирую вызов gdb как когда-то было в ReOpenLDAP (там что-то перестало работать из-за изменений в gdb > 6).
Просьба скопипастить на гитхаб мой ответ из https://gitflic.ru/project/erthink/libmdbx/issue/7, или хотя-бы уведомить что я ответил (gitflic не уведомляет об ответах почтой, пока не знаю почему).
В том числе, наверное стоит открыть https://github.com/vorot93/libmdbx-rs/issues/16, так как эффективность workaround не проверена и сам он не попал в версию используемую для сборки биндингов.
Оказывается у пользователей уже два месяца подгорает из-за этого
mdbx:9268: map_resize: Assertion `size_bytes == env->me_dxb_mmap.current' failed. и уже пошли рассуждения о плохом коде и низкой надежности libmdbx, хотя в текущем понимании баг в glibc или в докере.2.
Да, можно сказать есть "ошибка при сборке".
Исторически в C/C++ принято оставлять ассерты если при сборке НЕ определен макрос NDEBUG, т.е. по-умолчанию в коде остаются проверки реализованные через библиотечный макрос
assert().Соответственно, если просто собрать, то часть ассертов остаётся, но ни сами собирающие, ни тем более пользователи не в курсе.
Буду думать и менять:
- по-умолчанию оставлю только минимум проверок, которые дешевы и страхуют от тихой потери данных.
- допишу в readme что-нибудь об этом, включая рекомендации по формированию информации необходимой для анализа подобных сбоев.
- как вариант, адаптирую/реанимирую вызов gdb как когда-то было в ReOpenLDAP (там что-то перестало работать из-за изменений в gdb > 6).
YS
15:59
Yevhenii Skrebtsov
In reply to this message
Могу сказать, что использовал ветку с workaround на протяжении 3-х недель и пока подобной проблемы выявлено не было.
👍
Л(
Л(
21:47
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Начал тестирование к подготовке
В ближайшее время обновлю changelog в ветке
Критерий релиза: есть несколько важных исправлений и there is no suspicion of regressions after
v0.12.2 в статусе pre-release.В ближайшее время обновлю changelog в ветке
devel и волью в master.Критерий релиза: есть несколько важных исправлений и there is no suspicion of regressions after
v0.12.1.
7 November 2022
Hecate2 invited Hecate2
H
07:29
Hecate2
Hello😆, but I wrote https://github.com/ledgerwatch/erigon/issues/2507#issuecomment-1305043174 😝 and I was asked to report the problem to mdbx. I am really having a hard time reading Russian now.😵💫
Л(
08:27
Леонид Юрьев (Leonid Yuriev)
In reply to this message
It takes a bit of black magic to work on Windows ;)
The easiest and most reliable way is to build and use _libmdbx_ as a shared library.
In this way, initialization and deinitialization (including destructors of thread local storage objects), will be performed by the operating system by calling
Otherwise, when using a static library, the same thing needs to be done with the means of the used compiler/toolchain, like the
Such tricks are compiler-dependent and libmdbx uses it already.
However, if something doesn't work, then I'll should to repeat:
- build and use dll, but not a static library;
- use one of the proven compilers (MSVC or MinGW);
- for other cases: study documentation for used compiler, check the source code and the build, and if bugs are found, I will gladly accept fixes.
The easiest and most reliable way is to build and use _libmdbx_ as a shared library.
In this way, initialization and deinitialization (including destructors of thread local storage objects), will be performed by the operating system by calling
DllMain().Otherwise, when using a static library, the same thing needs to be done with the means of the used compiler/toolchain, like the
__declspec(allocate(".CRT$XLB")) or __attribute__((__section__(".CRT$XLB"), used)).Such tricks are compiler-dependent and libmdbx uses it already.
However, if something doesn't work, then I'll should to repeat:
- build and use dll, but not a static library;
- use one of the proven compilers (MSVC or MinGW);
- for other cases: study documentation for used compiler, check the source code and the build, and if bugs are found, I will gladly accept fixes.
❤
H
H
08:29
Hecate2
Many thanks!
8 November 2022
Li Fu invited Li Fu
9 November 2022
Л(
17:11
Леонид Юрьев (Leonid Yuriev)
Call for Testing
~~~~~~~~~~~~~
Please check ones now.
~~~~~~~~~~~~~
v0.11.13 (stable bugfix) scheduled at 2022-11-10, the stable branch at https://gitflic.ru/project/erthink/libmdbxv0.12.2 (frontward) scheduled at 2022-11-11, the master branch at https://gitflic.ru/project/erthink/libmdbxPlease check ones now.
🎉
СМ
SC
СМ
17:14
Сергей Мирянов
На последнем devel все мои тесты проходятся
❤
Л(
10 November 2022
SC
03:14
Simon C.
I'm getting the following on master for Windows builds. Any idea what might cause it?
LINK : warning LNK4098: defaultlib 'MSVCRTD' conflicts with use of other libs; use /NODEFAULTLIB:library
mdbx.lib(mdbx.obj) : error LNK2001: unresolved external symbol __imp__CrtDbgReport
Л(
11:46
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Seem your build is intentionally broken.
https://stackoverflow.com/questions/3007312/resolving-lnk4098-defaultlib-msvcrt-conflicts-with
As I already answered, building libmdbx via MSVC involves using CMake and everything necessary is provided for this way, i.e. the
This script is regularly tested in more than 100 configurations under Windows.
If for some reason you go the other way, then you will have to solve such problems yourself.
I think the easiest way is to compare all the options in your build with how CMake poked ones on the right way.
https://stackoverflow.com/questions/3007312/resolving-lnk4098-defaultlib-msvcrt-conflicts-with
As I already answered, building libmdbx via MSVC involves using CMake and everything necessary is provided for this way, i.e. the
CMakeLists.txt is provided which is smart enough to solve such problems.This script is regularly tested in more than 100 configurations under Windows.
If for some reason you go the other way, then you will have to solve such problems yourself.
I think the easiest way is to compare all the options in your build with how CMake poked ones on the right way.
👍
SC
Л(
13:57
Леонид Юрьев (Leonid Yuriev)
libmdbx v0.11.13 "Swashplate"
The stable bugfix release in Family Glory and in memory of Boris Yuriev (the inventor of Helicopter and Swashplate in 1911) on his 133rd birthday.
The stable bugfix release in Family Glory and in memory of Boris Yuriev (the inventor of Helicopter and Swashplate in 1911) on his 133rd birthday.
30 files changed, 405 insertions(+), 136 deletions(-)https://gitflic.ru/project/erthink/libmdbx/release/82bf302a-81fe-4b9c-8309-4bd39e9233d6
🎉
ED
СМ
AV
AV
15:33
Artem Vorotnikov
а я правильно понимаю, что BigFoot включён по умолчанию для 64-битных систем?
Л(
Л(
17:57
Леонид Юрьев (Leonid Yuriev)
Возник не-праздный вопрос по такому сценарию:
- есть машина в #GoogleComputeEngine;
- предположим на ней возникают корректируемые ошибки DDR4 или перегрев ЦПУ;
- соответствующие прерывания будет обрабатывать гипервизор и не факт что гостевое ядро будет как-то уведомлено об этом;
- с точки зрения гостевого ядра, возникающие пенальти будут засчитаны в user-mode cpu-time, если только гипервизор не вычтет их при виртуализации;
- а вычитать подобные затраты гипервизор не будет, ибо редкий случай и незачем.
Соответственно, если подобные (корректируемы) сбои происходят и конфигурация VM не предполагает миграцию, либо сильно толстая для миграции, то с точки зрения VM будут происходить необъяснимые всплески потребления ЦПУ.
В чем я не прав?
- есть машина в #GoogleComputeEngine;
- предположим на ней возникают корректируемые ошибки DDR4 или перегрев ЦПУ;
- соответствующие прерывания будет обрабатывать гипервизор и не факт что гостевое ядро будет как-то уведомлено об этом;
- с точки зрения гостевого ядра, возникающие пенальти будут засчитаны в user-mode cpu-time, если только гипервизор не вычтет их при виртуализации;
- а вычитать подобные затраты гипервизор не будет, ибо редкий случай и незачем.
Соответственно, если подобные (корректируемы) сбои происходят и конфигурация VM не предполагает миграцию, либо сильно толстая для миграции, то с точки зрения VM будут происходить необъяснимые всплески потребления ЦПУ.
В чем я не прав?
11 November 2022
yh
06:57
yi huang
Hi, I have a use case that we always insert into the db in the same order as the keys, it's great that lmdb/mdbx has the APPEND mode and will have minimal free pages.
My question is mainly on db size, what can be done to minimize db size, other than dupsort and compressions on the indivial values, and I might want to share the compression dictionary for a batch of items.
My question is mainly on db size, what can be done to minimize db size, other than dupsort and compressions on the indivial values, and I might want to share the compression dictionary for a batch of items.
yh
07:14
yi huang
maybe zfs compression?
AS
08:33
Alex Sharov
"what can be done to minimize db size?" - as usually first find what exactly eating most of space then fix it somehow:
- increase normal-form: https://en.wikipedia.org/wiki/Database_normalization
- use
- if you doing much deletes - can try increase
- group data to bigger shards manually or by
- If need store tons of digits - like DupSort inverted index "key -> some_id". Can try switch it to something like Non-DupSort "key -> RoaringBitamp_of_some_ids". Or "key + shard_id -> shard_encoded_as_RoaringBitmap"
- reduce %GC: mdbx_state -ef | grep GC
- increase PageSize - to reduce amount of overhead-per-page
- increase normal-form: https://en.wikipedia.org/wiki/Database_normalization
- use
MDBX_INTEGERKEY, MDBX_INTEGERDUP (I'm not 100% sure, but probably it saving 8-bytes per key, because don't need store key length)- if you doing much deletes - can try increase
MDBX_opt_merge_threshold_16dot16_percent- group data to bigger shards manually or by
MDBX_MULTIPLE (to reduce amount of keys/values - it saving 8-bytes per key, because don't need store key length). To navigate in shards can use next trick: switch table format from "key_id -> value" to "shard_id -> list_of_values" - where "shard_id = max_key_id_inside_given_shard | MaxUint64_for_the_last_shard". Then request like MDBX_SET_RANGE(key_id) will return correct "shard_id -> list_of_values" pair - and you will manually search your value inside list_of_values. - If need store tons of digits - like DupSort inverted index "key -> some_id". Can try switch it to something like Non-DupSort "key -> RoaringBitamp_of_some_ids". Or "key + shard_id -> shard_encoded_as_RoaringBitmap"
- reduce %GC: mdbx_state -ef | grep GC
- increase PageSize - to reduce amount of overhead-per-page
👍
yh
yh
08:56
yi huang
I use it to store a merkle tree, the data structure is just like the shards you described:
the length of node is variable, so to do manual search in the
version -> [ node, ...], and the nodes can be accessed by (version, index). and we may or may not need to prune the tree, if not prune the tree, we don't need to delete anything ever, I think I can optimize for both cases separately.the length of node is variable, so to do manual search in the
list_of_values you mentioned, we also need to prepend a list of offsets (the whole version is written out in a batch, so that's possible), right?
08:57
or better to simply:
version(dupsort) -> [(index(int key), node)]
AS
09:07
Alex Sharov
In reply to this message
Probably list of offsets can compress better - by roaring or elias-fano.
Node - contains full key? Likely it’s biggest space-waste?
Node - contains full key? Likely it’s biggest space-waste?
yh
09:10
yi huang
yeah, the actual keys, values, and hashes, should occupy most space, but hard to optimize there, I want to see if an optimal format in mdbx can match the counterparts like leveldb/rocksdb in terms of db size
09:10
I can do certain compression on the node itself
09:17
version -> (offsets, list of compressed nodes), I guess this should be most space efficient format
Rüdiger Klaehn invited Rüdiger Klaehn
Л(
18:00
Леонид Юрьев (Leonid Yuriev)
libmdbx 0.12.2 (Иван Ярыгин)
The frontward release with significant improvements and new functionality in memory of Russian wrestler Ivan Sergeyevich Yarygin.
At the Olympic Games in Munich in 1972, Ivan Yarygin defeated all his rivals, spending a total of less than 9 minutes.
This record so far in force.
https://gitflic.ru/project/erthink/libmdbx/release/0440894b-d418-474d-bae8-f7a89a7712f0
The frontward release with significant improvements and new functionality in memory of Russian wrestler Ivan Sergeyevich Yarygin.
At the Olympic Games in Munich in 1972, Ivan Yarygin defeated all his rivals, spending a total of less than 9 minutes.
This record so far in force.
https://gitflic.ru/project/erthink/libmdbx/release/0440894b-d418-474d-bae8-f7a89a7712f0
👍
RS
i
AV
4
12 November 2022
SC
11:36
Simon C.
Are database files between 0.12.x versions and 0.11.x versions incompatible? Can I downgrade without loosing data?
And could you maybe give me a hint what code is incompatible with Linux kernels <4.0.0? I'm getting crashes on a device farm (hard to debug) with version 0.12.2 on a slighly older armv7 Android phone
And could you maybe give me a hint what code is incompatible with Linux kernels <4.0.0? I'm getting crashes on a device farm (hard to debug) with version 0.12.2 on a slighly older armv7 Android phone
Л(
12:50
Леонид Юрьев (Leonid Yuriev)
In reply to this message
1. Yes, 0.11.x and 0.12.x are compatible, so you can do.
2. Running on linux kernels < 4 the
So any
2. Running on linux kernels < 4 the
mdbx_env_create() will return MDBX_INCOMPATIBLE.So any
SIGSEGV is unexpected unless you ignore a returning code(s) and/or dereference invalid/uninitialized pointer(s).
❤
SC
SC
12:51
Simon C.
In reply to this message
Thanks!!
Yes because of the kernel version check. But apart from the check is there any actual problem?
Yes because of the kernel version check. But apart from the check is there any actual problem?
Л(
13:16
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Old kernels didn't support some API.
You can check libmdbx source code for an assertions like
To be sure (and not to lie to users), a full-fledged check is required - at least a week of the stochastic test (see
If changes are made to the source code for API compatibility with older kernels, then there will be a chance that such a test run will be successful.
And if such checks will be performed regularly (at least with each release and/or major code change), then you can hope that users will not have problems on older devices.
You can check libmdbx source code for an assertions like
linux_kernel_version < xxx
i.e. git grep linux_kernel_version | grep -i assert
However, it would be a deception to say that everything will work on old kernels.To be sure (and not to lie to users), a full-fledged check is required - at least a week of the stochastic test (see
test/long_stochastic.sh inside libmdbx repo) on the target system with old kernel.If changes are made to the source code for API compatibility with older kernels, then there will be a chance that such a test run will be successful.
And if such checks will be performed regularly (at least with each release and/or major code change), then you can hope that users will not have problems on older devices.
SC
13:16
Simon C.
Awesome thanks so much!
SC
22:33
Simon C.
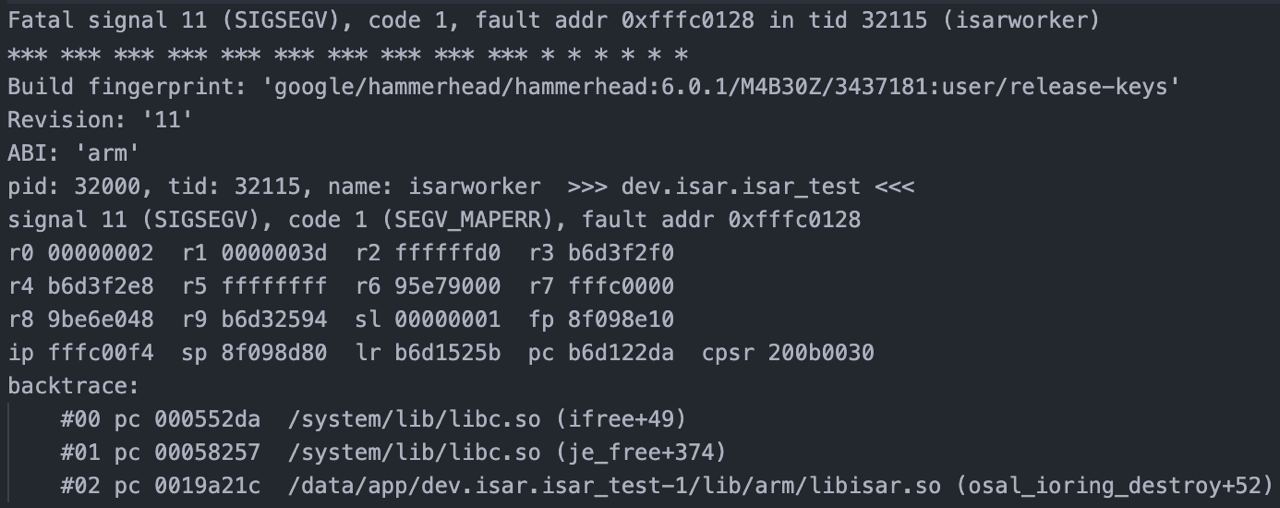
I get the following error on a lot of 32bit arm devices on 0.12.2.
Any idea how to debug this further?
osal_free(ior->pool); in osal_ioring_destroy()Any idea how to debug this further?
Л(
23:05
Леонид Юрьев (Leonid Yuriev)
In reply to this message
1) Seems bionic'
Try to add
2) Describe your use case so that I can reproduce the problem.
3) Try to replace
free() don't accepts NULL.Try to add
if (ior->pool) before osal_free(ior->pool).2) Describe your use case so that I can reproduce the problem.
3) Try to replace
-1 with 0 in the next line memset(ior, -1, sizeof(osal_ioring_t)) after the osal_free() call.
❤
SC
13 November 2022
SC
01:15
Simon C.
Replacing -1 with 0 did the trick 🤯 thanks!!
Л(
14:42
Леонид Юрьев (Leonid Yuriev)
In reply to this message
If this helps, then consequently there are some strange problems when closing the environment and releasing resources.
For instance you have call
For instance you have call
mdbx_env_close() simultaneously from multiple threads, i.e. not from a single.
🥴
SC
SC
14:43
Simon C.
The crash happened in a single threaded environment
Л(
20:12
Леонид Юрьев (Leonid Yuriev)
In reply to this message
The
But the
The
Thus the
Hence we have some unexpected execution path in your case.
memset(ior, 0, sizeof(osal_ioring_t)); may help if only the osal_ioring_destroy() is called twice.But the
osal_ioring_destroy() is called only from the env_close() and if the MDBX_ENV_ACTIVE bit is set.The
MDBX_ENV_ACTIVE is cleared (by the env->me_flags &= ~ENV_INTERNAL_FLAGS) before calling the osal_ioring_destroy().Thus the
osal_ioring_destroy() will be called once, and only after the mdbx_env_open().Hence we have some unexpected execution path in your case.
🤔
SC
20:21
There are two ways to understand what's going on:
1) Reproduce case under a debugger, then get a stack backtrace, seen the value of variables, etc.
2) Try to build and run libmdbx' test.
1) Reproduce case under a debugger, then get a stack backtrace, seen the value of variables, etc.
2) Try to build and run libmdbx' test.
SC
22:14
Simon C.
Will do, thanks. Both is not easy because this is a device on a device farm and Android is super annoying to debug but I'll try 👌
15 November 2022
G
15:41
Giulio
panic: fail to open mdbx: bucket: Clique, mdbx_dbi_open: MDBX_DBS_FULL: Too many DBI-handles (maxdbs reached) [recovered]
panic: fail to open mdbx: bucket: Clique, mdbx_dbi_open: MDBX_DBS_FULL: Too many DBI-handles (maxdbs reached)
panic: fail to open mdbx: bucket: Clique, mdbx_dbi_open: MDBX_DBS_FULL: Too many DBI-handles (maxdbs reached)
15:41
I get this in erigon-lib
15:42
is there any way to increase it, will also report to erigon discord
15:48
okay you can bump it up, can increasing it lead to db corruption?
Л(
15:50
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Please RTFM and just use API properly.
https://libmdbx.dqdkfa.ru/group__c__settings.html#ga39ab74bb9bbfaab1cc586642fec4559a
https://libmdbx.dqdkfa.ru/group__c__settings.html#ga39ab74bb9bbfaab1cc586642fec4559a
G
SC
16:09
Simon C.
Increasing number of dbs (before opening env) is not a problem 👍
G
18 November 2022
SC
14:02
Simon C.
Has anyone tried compiling mdbx to wasm?
i
16:27
igors
Wasm doesn't support mmap
SC
16:28
Simon C.
Emscripten does afaik
i
16:30
igors
But what about runtime for wasm?
16:31
Support for an MVP of mmap · Issue #304 · WebAssembly/WASI · GitHub
https://github.com/WebAssembly/WASI/issues/304
https://github.com/WebAssembly/WASI/issues/304
😢
SC
19 November 2022
Л(
23:40
Леонид Юрьев (Leonid Yuriev)
Скоро будет выпущен 0.12.3 со срочным исправлением (уже доступно в ветке master).
https://gitflic.ru/project/erthink/libmdbx/blob?file=ChangeLog.md
https://gitflic.ru/project/erthink/libmdbx/blob?file=ChangeLog.md
👌
СМ
SC
22 November 2022
SC
19:17
Simon C.
I have a couple of users reporting a new issue on iOS devices in version 0.12.2
I'm still working on symbolicate the crash (never done that before 😅) and reproducing it myself. I looked at the
I'm still working on symbolicate the crash (never done that before 😅) and reproducing it myself. I looked at the
env_close() code and don't really understand how this error can even happen since all the frees are checked 0x20524 abort + 168
3 libsystem_malloc.dylib 0x1ca04 _malloc_put + 550
4 libsystem_malloc.dylib 0x1cbdc malloc_report + 64
5 libsystem_malloc.dylib 0x1e38 free + 300
6 isar_flutter_libs 0xca588 env_close + 136
7 isar_flutter_libs 0xc8284 mdbx_env_open + 1644
8 isar_flutter_libs 0x4d470 isar_core::instance::IsarInstance::open_internal::h5dfcafd44edbc112 + 736
Л(
23 November 2022
Л(
01:22
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Hope to fixed by
Please checkout the
a1333fc827bba3fb0a2c5d9c718177d27cc2cf5f.Please checkout the
devel branch.
SC
01:28
Simon C.
Wow that was quick!! Thank you 💜
Л(
01:30
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Oh, I don't sure it fixed, but hope to.
So, please check.
So, please check.
👍
SC
24 November 2022
AV
AA
22:17
Alexey Akhunov
well, now go tell this to paradigm 🙂 they are going to be using MDBX in their soon-to-be-opensourced product
👍
Л(
22:17
and I will have a good laugh
22:19
for the context, you can watch the latest video on my channel - about winding down support for Akula project (using MDBX): https://t.me/monoblunt
Л(
23:24
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Хм, не знал что у вас "там" такие баталии и угоны.
🔥
AA
23:28
In reply to this message
Вот так и начинаешь видеть/понимать причины, например, по которым Говард Чу пишет ребусы в коде.
🔥
AA
AA
23:31
Alexey Akhunov
всё только начинается, у этой истории обязательно будет продолжение 🙂
A
23:32
Aleksei🐈
Шо там, объясните в двух словах?
AA
23:33
Alexey Akhunov
В общем, есть такой венчурный фонд в области крипты, называется Pardigm. Куча бабла, инвестировали во все возможные и невозможные крипто-проекты
SC
23:34
Simon C.
I don't quite understand their reasoning. What does a GitHub ban have to do with code quality/security? They don't ban bad code lol
AA
23:35
Alexey Akhunov
И вот они захотели написать на Расте ноду для Эфириума. Так как сначала начинать очень трудно, решили позаимствовать какой-то код из Акулы, включая кстати интеграцию MDBX, ну и прийти к нам в различные публичные чаты и поспрашивать о том, как мы это сделали, и то, и зачем, и что еще пробовали. На вопросы, а зачем вам всё это надо, молчок
23:37
Мы начали подозревать что-то. В конце концов мне удалось с ними поговорить и узнать всё что надо, и заодно они показали весь код. Пока закрытый, но будут открывать очень скоро. Та же функциональность что и Акула, с кусками кода оттуда, и с большими амбициями
23:38
Ну и стало нам понятно, что соревноваться с ними за один и тот продукт - это медленная смерть при этом истекая не кровью, а деньгами и временем. Ну еще демотивация. И решили "закрыть" наш проект. Они победили. Но теперь я с ними говорю, чтобы они нам хотя бы денег дали за бесплатные консультации
👍
Л(
23:39
думаю, что дадут
Л(
23:44
In reply to this message
Надеюсь что Erigon не думаете закрывать?
А то вы у меня лучшие бета-тестеры ;)
А то вы у меня лучшие бета-тестеры ;)
23:50
Завтрашний релиз 0.12.3 назову "Акулой".
❤
ED
i
AV
4
🔥
1
AA
23:51
Alexey Akhunov
Нет, пока не собираемся, ситуация с Го немного другая. Самая используемая реализация эфириума - это go-ethereum, а Erigon на втором месте. Поэтому если появится третья разработка на Го, то они не только с нами должны будут соревноваться, но и go-ethereum. К тому же мы теперь будем самые свои новые наработки держать во внутренних чатах, а также создавать программу обучения, чтобы можно было нанимать разработчков и их обучать, вместо того, чтобы "расплескивать" дезайн и надеятся, что заинтересованные люди придут извне сами собой
👍
Л(
23:51
а наработки у нас есть, мне кажется очень обещающие
🔥
Л(
25 November 2022
ED
07:34
Evgenii Danilenko
In reply to this message
Подтверждаю. Мы в Polygon запустили Erigon как эксперимент, а в итоге часть клиентов стала его требовать. Под это даже время разработчиков удалось выбить с изначально "не более 2х недель в квартал" до двух полноценных разработчиков.
07:34
Спрос есть, как и потребность в Erigon.
СМ
20:06
Сергей Мирянов
@erthink добрый вечер.
подскажите, пожалуйста, я правильно понимаю, что в 32-битном процессе под Windows получить БД более 2Гб не получится?
подскажите, пожалуйста, я правильно понимаю, что в 32-битном процессе под Windows получить БД более 2Гб не получится?
Л(
СМ
20:07
Сергей Мирянов
ясно, спасибо за ответ
20:09
и еще вопрос - у нас было обсуждние и я не смог уверенно ответить на вопрос - как хранятся данные в b+tree в mdbx. в документации не уверен что это было - но если да - то буду рад если укажете где смотреть
Л(
20:14
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Такую документацию я не готовил, ибо (1) это сугубо внутреннее дело и (2) любой желающий может изучить исходный код.
Кроме этого, так как mdbx происходит от LMDB, то формат БД почти идентичен.
В свою очередь, по LMDB в Сети были какие-то презентации, статьи и т.п. - но ссылок не подскажу.
Кроме этого, так как mdbx происходит от LMDB, то формат БД почти идентичен.
В свою очередь, по LMDB в Сети были какие-то презентации, статьи и т.п. - но ссылок не подскажу.
СМ
20:14
Сергей Мирянов
ага, я видел ваше обсуждение под одной из статей на хабре, начну от туда
i
20:16
вот достаточно неплохой доклад, ну а по b+ tree информации предостаточно
СМ
20:17
Сергей Мирянов
да, я его имел в виду
AA
21:19
Alexey Akhunov
@miryanovsn это было написано про LMDB, но в MDBX очень похожее расположение. У нас еще до сих пор валяется код, с помощью которого можно такие картинки делать уже для MDBX: https://github.com/ledgerwatch/erigon/wiki/LMDB-freelist-illustrated-guide
21:20
я просто давно не возился с этим, надо бы переписать
СМ
21:21
Сергей Мирянов
спасибо, эту тоже ранее видел - посмотрю внимательнее еще раз
AA
21:24
Alexey Akhunov
сейчас проверил - генерация картинок работает. У нас тут фактически парсер файлов MDBX написанный на го: https://github.com/ledgerwatch/erigon/blob/devel/cmd/hack/db/lmdb.go если есть желание поиграться, можно склонировать репу, менять примерчики (заполнять базу разными данными), и перегерерировать картинки, как описано в начале документа
21:25
и если есть желание, сделать PR чтобы всё переименовать с LMDB 🙂
СМ
21:29
Сергей Мирянов
придется наконец-то познакомится с го поближе :)
Л(
21:36
Леонид Юрьев (Leonid Yuriev)
In reply to this message
А какая у вас цель?
Если просто посмотреть что внутри конкретной БД, то еще можно использовать утилиту
Если просто посмотреть что внутри конкретной БД, то еще можно использовать утилиту
mdbx_chk несколько раз задав опцию -v, т.е. например mdbx_chk -vvvvv path-todb
СМ
21:37
Сергей Мирянов
ого, я пробовал только с -v
цель чисто удовлетворить свой интерес
цель чисто удовлетворить свой интерес
AA
21:38
Alexey Akhunov
все они так говорят "удовлетворить интерес", а потом выкатывают целые проекты из под полы (шутка на злобу нашего дня) 🙂
СМ
21:38
Сергей Мирянов
про интерес - это про внутреннюю структуру
21:39
не про интерес - да я делаю прототип но это не блокчейн
Л(
22:19
Леонид Юрьев (Leonid Yuriev)
In reply to this message
На всякий, есть инструменты позволяющие описать формат на DSL.
Затем как сгенерировать код для парсинга/чтения данных, так и для визуализации.
https://github.com/dloss/binary-parsing
Затем как сгенерировать код для парсинга/чтения данных, так и для визуализации.
https://github.com/dloss/binary-parsing
👍
СМ
22:29
Чуть более конкретно - там прям по списку можно идти и выбирать подходящее.
Грубо говоря, вооружившись http://kaitai.io/ вы можете за выходные сделать формально точнее описание, которое позволит визуализировать структуру.
Грубо говоря, вооружившись http://kaitai.io/ вы можете за выходные сделать формально точнее описание, которое позволит визуализировать структуру.
СМ
Л(
СМ
22:41
Сергей Мирянов
я имел опыт только с spirit из буста
Л(
23:38
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Решил отложить релиз на пару дней.
Хочу еще по-тестировать последние доработки, а также получить подтверждение от @AskAlexSharov что стало лучше (или хотя-бы не хуже).
Хочу еще по-тестировать последние доработки, а также получить подтверждение от @AskAlexSharov что стало лучше (или хотя-бы не хуже).
Tеngiz Shаrаfiev invited Tеngiz Shаrаfiev
26 November 2022
Л(
17:41
Леонид Юрьев (Leonid Yuriev)
Windows must will die!
О поддержке Windows, точнее о предстоящем её прекращении с очисткой кода.
Суть:
В одном из следующих мажорных релизов поддержка ОС Windows будет прекращена.
Причины:
1. В API Windows имеется ряд проблем для эффективной работы libmdbx.
2. Positive Technologies прекратит выпуск и поддержку своих продуктов на платформе Windows.
3. Классическая ОС Windows является умирающей системой.
4. Microsoft предоставляет полноценную поддержку WSL, с блекджеком (графическим стеком) и куртизанками (systemd).
5. Поддержка Windows захламляет код и требует трудозатрат, в том числе покупку Windows (что официально не возможно в России).
Когда:
- в одном из следующих мажорных релизов, но точной даты пока нет.
- практически невероятно, что поддержка Windows сохранится в новых релизах в 24 году.
- все предыдущие релизы останутся "как есть", а их поддержка (устранение проблем) будет до 25 года, а дальше - время покажет.
+++
However, existing versions of libmdbx, including
Therefore, to not be left in a dust, it is good enough for anybody to check the current releases and report an issues noticed in a timely manner.
О поддержке Windows, точнее о предстоящем её прекращении с очисткой кода.
Суть:
В одном из следующих мажорных релизов поддержка ОС Windows будет прекращена.
Причины:
1. В API Windows имеется ряд проблем для эффективной работы libmdbx.
2. Positive Technologies прекратит выпуск и поддержку своих продуктов на платформе Windows.
3. Классическая ОС Windows является умирающей системой.
4. Microsoft предоставляет полноценную поддержку WSL, с блекджеком (графическим стеком) и куртизанками (systemd).
5. Поддержка Windows захламляет код и требует трудозатрат, в том числе покупку Windows (что официально не возможно в России).
Когда:
- в одном из следующих мажорных релизов, но точной даты пока нет.
- практически невероятно, что поддержка Windows сохранится в новых релизах в 24 году.
- все предыдущие релизы останутся "как есть", а их поддержка (устранение проблем) будет до 25 года, а дальше - время покажет.
+++
However, existing versions of libmdbx, including
0.12.x and most likely 0.13.x will support Windows.Therefore, to not be left in a dust, it is good enough for anybody to check the current releases and report an issues noticed in a timely manner.
🎉
VS
ED
AV
👎
1
СМ
17:42
Сергей Мирянов
эх, тоска
SC
17:44
Simon C.
In reply to this message
Is windows the only platform you'll discontinue? Or will others follow?
This puts downstream projects that can't give up on Windows into a lot of trouble ☹️
This puts downstream projects that can't give up on Windows into a lot of trouble ☹️
Л(
17:48
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Support for all POSIX systems will remain.
👍
SC
Л(
18:12
Леонид Юрьев (Leonid Yuriev)
In reply to this message
M$ understands that classic Window's API and Windows kernel are mad, so dying off.
Therefore, M$ provides WSL, so as not to disappear with Windows.
The sooner you switch to WSL, the more successful you will be.
Therefore, M$ provides WSL, so as not to disappear with Windows.
The sooner you switch to WSL, the more successful you will be.
SC
18:16
Simon C.
In reply to this message
I don't use Windows for obvious reasons. I think it sucks. But just not supporting it is not the solution. Let me give you a bit of context.
My open source projects depending on libmdbx are being used by ~20k apps and other project with a combined user number of 50-100M. A not insignificant number of those (end-users) use Windows.
Just loosing those is not an option. And I also can't tell them to use WSL. Many of those don't even know what it is
My open source projects depending on libmdbx are being used by ~20k apps and other project with a combined user number of 50-100M. A not insignificant number of those (end-users) use Windows.
Just loosing those is not an option. And I also can't tell them to use WSL. Many of those don't even know what it is
👍
СМ
Л(
18:23
Леонид Юрьев (Leonid Yuriev)
I wouldn't be surprised if Windows 12 will be based on WSL, with an obsolete Windows subsystem as an option.
However, existing versions of libmdbx, including 0.12.x and most likely 0.13.x will support Windows.
Therefore, to not be left in a dust, it is good enough for you to check the current releases and report an issues noticed in a timely manner.
However, existing versions of libmdbx, including 0.12.x and most likely 0.13.x will support Windows.
Therefore, to not be left in a dust, it is good enough for you to check the current releases and report an issues noticed in a timely manner.
❤
SC
SC
18:24
Simon C.
In reply to this message
Yes that's my plan. Lets hope Microsoft finally understands that they and all of humanity is better off without NT 😂
👍
Л(
27 November 2022
Л(
02:23
Леонид Юрьев (Leonid Yuriev)
На всякий стоит проинформировать о статусе устаревшего/протухшего репозитория на github:
1. Изначально при "блокировке" гитхаб удалил данные, но продолжал выдавать http-мета-информацию поисковым роботам.
Поэтому пользователи получали 404, но поисковые системы продолжали считать ресурсы существующими и доступными.
2. Когда-то летом гитхаб восстановил какие-то НЕПОЛНЫЕ мусорные архивы, которые сейчас доступны в режиме только для чтения.
Исходный код устарел, а сопутствующие ресурсы (issues с комментариями, релизы и т.п.) не полные и являются не снимком на некоторую дату, а мешаниной из разных старых версий.
Например, последним помечен релиз двухлетней давности.
Тем не менее, issues в таком виде попали в web.archive и доступны через https://libmdbx.dqdkfa.ru/dead-github/issues/.
3. Единственная создаваемая гихабом проблема в том, что покалеченные устаревшие репозитории засоряют поисковую выдачу и мешают заинтересованным находить актуальные проекты.
Попробую написать в гихаб, чтобы добиться удаления этого хлама.
1. Изначально при "блокировке" гитхаб удалил данные, но продолжал выдавать http-мета-информацию поисковым роботам.
Поэтому пользователи получали 404, но поисковые системы продолжали считать ресурсы существующими и доступными.
2. Когда-то летом гитхаб восстановил какие-то НЕПОЛНЫЕ мусорные архивы, которые сейчас доступны в режиме только для чтения.
Исходный код устарел, а сопутствующие ресурсы (issues с комментариями, релизы и т.п.) не полные и являются не снимком на некоторую дату, а мешаниной из разных старых версий.
Например, последним помечен релиз двухлетней давности.
Тем не менее, issues в таком виде попали в web.archive и доступны через https://libmdbx.dqdkfa.ru/dead-github/issues/.
3. Единственная создаваемая гихабом проблема в том, что покалеченные устаревшие репозитории засоряют поисковую выдачу и мешают заинтересованным находить актуальные проекты.
Попробую написать в гихаб, чтобы добиться удаления этого хлама.
👍
AV
AL
12:26
Andrea Lanfranchi
@erthink about the announced future drop of Windows support will it be also something affecting Mithrildb (if/when) available?
Also ... As I understand from your statements here the issue with windows compatibility is mainly related to extra work needed: just asking would contribution (work/funds) be sufficient to keep compatibility or there are also ideological reasons? Thank you
Also ... As I understand from your statements here the issue with windows compatibility is mainly related to extra work needed: just asking would contribution (work/funds) be sufficient to keep compatibility or there are also ideological reasons? Thank you
AS
12:36
Alex Sharov
Random idea: if your product need Win, maybe you can contribute somehow. For example: pay for Win CI, setup “devel” branch there, by gitflick webhooks, if it’s red - create bug-report.
AL
12:51
Andrea Lanfranchi
Yes that could be a route but in the end does imply an official support by the repo (even if mostly user contributed). My question is more about whether @erthink is keen to such behavior (or any variant) or in the long term does want to drop windows anyway
AS
13:21
Alex Sharov
In reply to this message
I mean “contribute somehow”. Some “community-driven-feature”, etc…
AL
13:34
Andrea Lanfranchi
Yep but there must be some agreement in the meaning of ceased support. If in next major release the windows code is dropped entirely there is no choice but to create a sort of LIBMDX-CE (Community Edition) to keep it.
If nstead is to be meant as "we do not guarantee it works as expected on windows nor we tested on it" then there's the door open to contribution to keep windows support.
I'm not sure which of the two
If nstead is to be meant as "we do not guarantee it works as expected on windows nor we tested on it" then there's the door open to contribution to keep windows support.
I'm not sure which of the two
👍
SC
AV
13:42
Artem Vorotnikov
I'm pretty sure code cleanup means active removal of Windows crutches
AL
13:49
Andrea Lanfranchi
In reply to this message
That would make clarity around the "drop of support" and of course help many devs to properly plan their future work
SC
Л(
15:56
Леонид Юрьев (Leonid Yuriev)
More about dropping the support of Windows.
1. Classic Windows’ API is non-POSIX and lack many of features required for libmdbx, i.e. mremap(), madvise() and flexibility of resizing mmaped-regions. So libmdbx has a lot of workarounds and crutches which are looks ugly, complex to understanding and support, requires more testing, etc. Any sane programmer would prefer to remove all such rubbish if possible.
2. The system design of many things in Windows was initially experimental. Unfortunately, many design decisions were made not for engineering perfection, but for the sake of intentional incompatibility with POSIX and the formation of a peculiar API. This is a fatal cause sufficient for the death of Windows. Microsoft understands the inevitability of the outcome, so it is making efforts and already offers WSL as a lifebuoy. It is extremely unwise to abandon it.
3. The support of Windows will be dropped in some next major release, this means that in the worst case:
- there is still about a year to test releases of the 0.12.x branch thoroughly as possible;
- anyone can always send me a patch even for unsupported/obsolete branches (which supports Windows) or make a project fork for a «community edition»;
- the present code and the 0.12.x branch will never disappear, i.e. ones will be available and will work no worse than now.
If someone needs additional promises, then we need to discuss paid support.
For instance, I wouldn't mind getting
1. Classic Windows’ API is non-POSIX and lack many of features required for libmdbx, i.e. mremap(), madvise() and flexibility of resizing mmaped-regions. So libmdbx has a lot of workarounds and crutches which are looks ugly, complex to understanding and support, requires more testing, etc. Any sane programmer would prefer to remove all such rubbish if possible.
2. The system design of many things in Windows was initially experimental. Unfortunately, many design decisions were made not for engineering perfection, but for the sake of intentional incompatibility with POSIX and the formation of a peculiar API. This is a fatal cause sufficient for the death of Windows. Microsoft understands the inevitability of the outcome, so it is making efforts and already offers WSL as a lifebuoy. It is extremely unwise to abandon it.
3. The support of Windows will be dropped in some next major release, this means that in the worst case:
- there is still about a year to test releases of the 0.12.x branch thoroughly as possible;
- anyone can always send me a patch even for unsupported/obsolete branches (which supports Windows) or make a project fork for a «community edition»;
- the present code and the 0.12.x branch will never disappear, i.e. ones will be available and will work no worse than now.
If someone needs additional promises, then we need to discuss paid support.
For instance, I wouldn't mind getting
M386AAG40MMB-CVF×12 or M386AAG40MMB-CWE×16 to complete the upgrade of my equipment and provide it with uniform memory.
👍
MI
SC
YS
5
AL
22:28
Andrea Lanfranchi
In reply to this message
Thanks for clarifying.
About paid support I'm glad to know there's at least the option.
I'd personally wouldn't kick start a CE fork (nor embrace one) if, as you said, earlier versions shall not disappear. Eventually should be evaluated whether the benefits brought by new major release are worth the effort/money required to port those on windows too.
About paid support I'm glad to know there's at least the option.
I'd personally wouldn't kick start a CE fork (nor embrace one) if, as you said, earlier versions shall not disappear. Eventually should be evaluated whether the benefits brought by new major release are worth the effort/money required to port those on windows too.
28 November 2022
Andrew K invited Andrew K
29 November 2022
Sergey P invited Sergey P
1 December 2022
Tom C. | Will Never DM invited Tom C. | Will Never DM
2 December 2022
Jaanek Oja invited Jaanek Oja
5 December 2022
Л(
15:26
Леонид Юрьев (Leonid Yuriev)
В ветке devel доступны доработки требующие квалифицированного тестирования.
---
1. Реализована prefault-запись для read-write отображений.
В режиме
Это является следствием работы подсистемы виртуальной памяти, а штатный способ лечения через
Последними доработками в libmdbx реализована "упреждающая запись" таких страниц, которая на системах с unified page cache приводит к "вталкиванию" данных, устраняя необходимость чтения с диска при обращении к такой странице памяти.
Этот функционал работает автоматически, в согласованности с автоматическим управлением read-ahead и кэшем статуса присутствия страниц в ОЗУ (посредством mincore()).
По предварительной информации это приводит к кратному повышению производительности (кратному снижению системных издержек) в соответствующих сценариях использования:
- размер БД и объем данных существенно больше ОЗУ;
- используется режим MDBX_WRITEMAP;
- не-мелкие транзакции (по ходу транзакции выделяется многие сотни или тысячи страниц).
---
2. Реализован динамический выбор между сквозной записью на диск и обычной записью с последующим fdatasync(), добавлена опция
В долговечных (durable) режимах данные на диск могут быть сброшены двумя способами:
- сквозной записью через файловый дескриптор с
- обычной записью с последующим вызовом
Если нужно записать мало страниц и/или канал взаимодействия с диском/носителем имеет близкую к нулю задержку, то выгоднее первый способ.
А если же требуется записать много страниц и/или канал взаимодействия имеет весомую задержку (датацентры, облака), то выгоднее второй способ.
Добавленная опция
См описание опции в mdbx.h в ветке devel.
---
3. Запись страниц на Windows была доработана ранее, включая использование overlapped и write-gather.
Однако, данных о реальной производительности мало, а сделанные доработки создают необходимость повторной оценки/проверки.
При этом есть несколько разных режимов, которые следует оценивать независимо:
- MDBX_SYNC_DURABLE = будет задействована сквозная запись через overlapped-io;
- MDBX_SYNC_DURABLE + MDBX_WRITEMAP = будет задействована сквозная запись посредством WriteFileGather();
- MDBX_SYNC_DURABLE + MDBX_NOMETASYNC = будет задействована обычная запись с последующим FlushFileBuffers();
- MDBX_SYNC_DURABLE + MDBX_WRITEMAP c
Тем кто ратовал за сохранение поддержки Windows, самое время убедить меня на деле, что она востребована и её не стоит выбрасывать.
---
1. Реализована prefault-запись для read-write отображений.
В режиме
MDBX_WRITEMAP выделение/переиспользование страниц приводит к page-fault и чтению страницы с диска, даже если содержимое страницы не нужно (будет перезаписано).Это является следствием работы подсистемы виртуальной памяти, а штатный способ лечения через
MADV_REMOVE работает не на всех ФС и обычно дороже получаемой экономии.Последними доработками в libmdbx реализована "упреждающая запись" таких страниц, которая на системах с unified page cache приводит к "вталкиванию" данных, устраняя необходимость чтения с диска при обращении к такой странице памяти.
Этот функционал работает автоматически, в согласованности с автоматическим управлением read-ahead и кэшем статуса присутствия страниц в ОЗУ (посредством mincore()).
По предварительной информации это приводит к кратному повышению производительности (кратному снижению системных издержек) в соответствующих сценариях использования:
- размер БД и объем данных существенно больше ОЗУ;
- используется режим MDBX_WRITEMAP;
- не-мелкие транзакции (по ходу транзакции выделяется многие сотни или тысячи страниц).
---
2. Реализован динамический выбор между сквозной записью на диск и обычной записью с последующим fdatasync(), добавлена опция
MDBX_opt_writethrough_threshold.В долговечных (durable) режимах данные на диск могут быть сброшены двумя способами:
- сквозной записью через файловый дескриптор с
O_DSYNC;- обычной записью с последующим вызовом
fdatasync().Если нужно записать мало страниц и/или канал взаимодействия с диском/носителем имеет близкую к нулю задержку, то выгоднее первый способ.
А если же требуется записать много страниц и/или канал взаимодействия имеет весомую задержку (датацентры, облака), то выгоднее второй способ.
Добавленная опция
MDBX_opt_writethrough_threshold позволяет во время выполнения задать порог для динамического выбора способа записи.См описание опции в mdbx.h в ветке devel.
---
3. Запись страниц на Windows была доработана ранее, включая использование overlapped и write-gather.
Однако, данных о реальной производительности мало, а сделанные доработки создают необходимость повторной оценки/проверки.
При этом есть несколько разных режимов, которые следует оценивать независимо:
- MDBX_SYNC_DURABLE = будет задействована сквозная запись через overlapped-io;
- MDBX_SYNC_DURABLE + MDBX_WRITEMAP = будет задействована сквозная запись посредством WriteFileGather();
- MDBX_SYNC_DURABLE + MDBX_NOMETASYNC = будет задействована обычная запись с последующим FlushFileBuffers();
- MDBX_SYNC_DURABLE + MDBX_WRITEMAP c
MDBX_AVOID_MSYNC=0 при сборке = будет использоваться FlushViewOfFile() и FlushFileBuffers().Тем кто ратовал за сохранение поддержки Windows, самое время убедить меня на деле, что она востребована и её не стоит выбрасывать.
👍
N
АМ
СМ
❤
1
Л(
20:52
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Fixed for now, sure.
Thank you for reporting.
https://gitflic.ru/project/erthink/libmdbx/commit/48eeb93628ea045ef78b02579153eeb988851da7
Thank you for reporting.
https://gitflic.ru/project/erthink/libmdbx/commit/48eeb93628ea045ef78b02579153eeb988851da7
❤
SC
7 December 2022
AS
06:56
Alex Sharov
I think on next pattern - do you see anything bad - on MDBX_DURABLE:
begin(TxNoSync)
do insert+update work
commit() // no fsync here
send notifications about new data arrival to other apps, they may start reading new data at this time (by new read transactions)
begin()
delete portion of old data
commit() // fsync here
(our APP can afford to loose some recent transactions on power-off. we want to stay on MDBX_DURABLE by default for simplicity. we want to send notifications earlier - and make new data available faster for readers).
begin(TxNoSync)
do insert+update work
commit() // no fsync here
send notifications about new data arrival to other apps, they may start reading new data at this time (by new read transactions)
begin()
delete portion of old data
commit() // fsync here
(our APP can afford to loose some recent transactions on power-off. we want to stay on MDBX_DURABLE by default for simplicity. we want to send notifications earlier - and make new data available faster for readers).
👍
AV
ED
Л(
11:17
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Either I didn't understand you, or you're wrong.
For
For
MDBX_SYNC_DURABLE at the end of commit() all data are on a disk, but the option is a way to do this: write() to file descriptor opened with O_DSYNC either write() + fdatasync().
AS
11:26
Alex Sharov
I mean, now we doing:
commit // may take 1sec
send notifications
We can't send notifications before commit, because readers will not see data.
But we can change logic to (in my head - it's possible to open db with MDBX_DURABLE, and use
- commit(
- send notifications
- another transaction without
commit // may take 1sec
send notifications
We can't send notifications before commit, because readers will not see data.
But we can change logic to (in my head - it's possible to open db with MDBX_DURABLE, and use
MDBX_TXN_NOSYNC for some transactions):- commit(
MDBX_TXN_NOSYNC)- send notifications
- another transaction without
MDBX_TXN_NOSYNC ( we must do this transaction anyway )
Л(
11:46
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Yes, you can
mdbx_txn_begin() with MDBX_TXN_NOSYNC either MDBX_TXN_NOMETASYNC to do such.
11:50
And for MDBX_SYNC_DURABLE the next transaction will sync all data to disk or stay unsynced corresponds to it's own MDBX_TXN_NOSYNC option.
11:54
Thus you already have everything you need to do what you described, as well as the ability not to do it.
So I don't see what can be improved here, much less to fixed anything ;)
So I don't see what can be improved here, much less to fixed anything ;)
👍
b
AS
12:05
Alex Sharov
great
8 December 2022
mars marshal invited mars marshal
9 December 2022
AS
07:10
Alex Sharov
In reply to this message
1. Put to DupFixed - also can be implemented by pre-fault? Or PutReserve.
Л(
08:02
Леонид Юрьев (Leonid Yuriev)
In reply to this message
prefault-writes work on page-allocation basis, i.e. for all these (and other) cases.
AS
08:16
Alex Sharov
Very nice. It’s likely is a mental model shift. In the past DupFixed tables was only about “small space saving”, now it will guarantee absence of disk-reads on upsert/delete.
Л(
08:21
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Just for clarity:
- libmdbx uses Cow (Copy on Write);
- prefault-write avoid page-fault for the destination page of CoW, but not for a source;
- so prefault-write just avoids extra reading-from-disk during page-fault in MDBX_WRITEMAP mode.
- libmdbx uses Cow (Copy on Write);
- prefault-write avoid page-fault for the destination page of CoW, but not for a source;
- so prefault-write just avoids extra reading-from-disk during page-fault in MDBX_WRITEMAP mode.
12 December 2022
Polo Lacoste invited Polo Lacoste
Willll G invited Willll G
14 December 2022
Л(
11:59
Леонид Юрьев (Leonid Yuriev)
Mini-benchmark for the current
master branch.$ make -C libmdbx bench-couple
make: вход в каталог «/home/xyz/libmdbx»
// The GNU Make 4.3
// TIP: Use `make V=1` for verbose.
MDBX_BUILD_OPTIONS = -DNDEBUG=1
MDBX_BUILD_CXX = YES
MDBX_BUILD_TIMESTAMP = 2022-12-14T11:07:33+0300
// TIP: Use `make options` to listing available build options.
CXX =/usr/bin/g++ | g++ (Ubuntu 11.3.0-1ubuntu1) 11.3.0
CXXFLAGS =-std=gnu++23 -O2 -g -Wall -Werror -Wextra -Wpedantic -ffunction-sections -fPIC -fvisibility=hidden -pthread -Wno-error=attributes -fno-semantic-interposition -Wno-unused-command-line-argument -Wno-tautological-compare
LDFLAGS =-Wl,--gc-sections,-z,relro,-O1 -Wl,--allow-multiple-definition -lstdc++fs -lm -lrt -pthread
// TIP: Use `make help` to listing available targets.
CLEAN for build with specified flags... Ok
MAKE src/version.c
MAKE src/config.h
CC mdbx-static.o
CC mdbx++-static.o
AR libmdbx.a
CC mdbx-dylib.o
CC mdbx++-dylib.o
LD libmdbx.so
CC+LD mdbx_stat
CC+LD mdbx_copy
CC+LD mdbx_dump
CC+LD mdbx_load
CC+LD mdbx_chk
CC+LD mdbx_drop
RUNNING ioarena for mdbx/25000000...
linux-vdso.so.1 (0x00007ffe2b3c1000)
liblmdb.so => /home/xyz/ioarena/@BUILD/db/lmdb/libraries/liblmdb/liblmdb.so (0x00007fb4860d0000)
libmdbx.so => ./libmdbx.so (0x00007fb486064000)
libm.so.6 => /lib/x86_64-linux-gnu/libm.so.6 (0x00007fb485f67000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007fb485d3f000)
libstdc++.so.6 => /lib/x86_64-linux-gnu/libstdc++.so.6 (0x00007fb485b13000)
libgcc_s.so.1 => /lib/x86_64-linux-gnu/libgcc_s.so.1 (0x00007fb485af3000)
/lib64/ld-linux-x86-64.so.2 (0x00007fb4860ff000)
throughput: 199.566Kops/s
throughput: 46.082Mops/s
throughput: 3.075Mops/s
RUNNING ioarena for lmdb/25000000...
linux-vdso.so.1 (0x00007ffefadeb000)
liblmdb.so => /home/xyz/ioarena/@BUILD/db/lmdb/libraries/liblmdb/liblmdb.so (0x00007f99e1d0c000)
libmdbx.so => ./libmdbx.so (0x00007f99e1ca0000)
libm.so.6 => /lib/x86_64-linux-gnu/libm.so.6 (0x00007f99e1ba3000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f99e197b000)
libstdc++.so.6 => /lib/x86_64-linux-gnu/libstdc++.so.6 (0x00007f99e174f000)
libgcc_s.so.1 => /lib/x86_64-linux-gnu/libgcc_s.so.1 (0x00007f99e172f000)
/lib64/ld-linux-x86-64.so.2 (0x00007f99e1d3b000)
throughput: 171.387Kops/s
throughput: 42.069Mops/s
throughput: 2.339Mops/s
🔥
SC
16 December 2022
17:36
Deleted Account
I want to let other process know my change ASAP, so I do mdbx_dbi_close and mdbx_txn_commit_ex after mdbx_put.
but there always a error when call mdbx_dbi_close
-30780: MDBX_BAD_DBI: The specified DBI-handle is invalid or changed by another thread/transaction
I test last release and master branch, should I ignore this ?
(I start new txn and dbi at each write)
but there always a error when call mdbx_dbi_close
-30780: MDBX_BAD_DBI: The specified DBI-handle is invalid or changed by another thread/transaction
I test last release and master branch, should I ignore this ?
(I start new txn and dbi at each write)
17:45
the call is one by one, and only one thread is used it. and only one task, but still get MDBX_BAD_DBI
Л(
17:49
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Hmm, but when do you call
mdbx_dbi_open() ?
17:49
Deleted Account
mdbx_dbi_open just after mdbx_txn_begin_ex
17:50
ENV_FLAGS = MDBX_NOSUBDIR | MDBX_COALESCE | MDBX_LIFORECLAIM | MDBX_SAFE_NOSYNC | MDBX_WRITEMAP
Л(
17:51
Леонид Юрьев (Leonid Yuriev)
Ok, and what error code and what value are returned ?
17:51
Deleted Account
mdbx_txn_begin_ex(m_env, null, MDBX_TXN_READWRITE, &txn, null);
mdbx_dbi_open(txn, null, MDBX_INTEGERKEY | MDBX_CREATE, &dbi);
mdbx_put(txn, dbi, &k, &v, 0);
mdbx_dbi_close(m_env, dbi); = MDBX_BAD_DBI
mdbx_dbi_open(txn, null, MDBX_INTEGERKEY | MDBX_CREATE, &dbi);
mdbx_put(txn, dbi, &k, &v, 0);
mdbx_dbi_close(m_env, dbi); = MDBX_BAD_DBI
17:52
I check every step error, all zero but at mdbx_dbi_close get MDBX_BAD_DBI
17:54
after mdbx_put and mdbx_dbi_close,
I wil call mdbx_txn_commit_ex if put ok, if put error then I call mdbx_txn_abort
I wil call mdbx_txn_commit_ex if put ok, if put error then I call mdbx_txn_abort
Л(
17:54
Леонид Юрьев (Leonid Yuriev)
Now it's clear what's going on...
18:00
Deleted Account
It is in the one uv_loop thread, so it is a single thread. so I think there is no other thread op in it.
Л(
18:00
Леонид Юрьев (Leonid Yuriev)
You are use "unnamed" DB, which actually is MAIN_DBI =
In this case, the mdbx_dbi_open() only checks the compatibility of the flags, and mdbx_dbi_close() is not needed.
Such a strange API is inherited from LMDB.
However, I think I need to make a change so that mdbx_dbi_close() does not return an error in the such case.
1.In this case, the mdbx_dbi_open() only checks the compatibility of the flags, and mdbx_dbi_close() is not needed.
Such a strange API is inherited from LMDB.
However, I think I need to make a change so that mdbx_dbi_close() does not return an error in the such case.
18:03
Deleted Account
OK, I will skip the mdbx_dbi_close step.
one more quest, can I reuse the txt and dbi in this single thread case ?
I mean open txn and dbi when start app, and call mdbx_txn_commit_ex after every commit ?
one more quest, can I reuse the txt and dbi in this single thread case ?
I mean open txn and dbi when start app, and call mdbx_txn_commit_ex after every commit ?
Л(
18:14
Леонид Юрьев (Leonid Yuriev)
In reply to this message
1. You should always start a new write transaction.
However, for a non-nested writing transaction, you will always get a pointer to the same instance in memory, since libmdbx supports only one writer and therefore reuses the transaction internally.
In addition, you should not forget that another process can change a DB while the current process is not running a writing transaction.
2. You may reuse DBI-handle.
However, for a non-nested writing transaction, you will always get a pointer to the same instance in memory, since libmdbx supports only one writer and therefore reuses the transaction internally.
In addition, you should not forget that another process can change a DB while the current process is not running a writing transaction.
2. You may reuse DBI-handle.
18:16
Deleted Account
Thanks very much for the explain. I am sure there is no nested write.
so my step will be this:
mdbx_txn_begin_ex(m_env, null, MDBX_TXN_READWRITE, &txn, null);
mdbx_dbi_open(txn, null, MDBX_INTEGERKEY | MDBX_CREATE, &dbi);
mdbx_put(txn, dbi, &k, &v, 0);
mdbx_txn_commit_ex or mdbx_txn_abort.
even I am not reuse the same txn dbi var, they still reuse a same object instance right ?
so my step will be this:
mdbx_txn_begin_ex(m_env, null, MDBX_TXN_READWRITE, &txn, null);
mdbx_dbi_open(txn, null, MDBX_INTEGERKEY | MDBX_CREATE, &dbi);
mdbx_put(txn, dbi, &k, &v, 0);
mdbx_txn_commit_ex or mdbx_txn_abort.
even I am not reuse the same txn dbi var, they still reuse a same object instance right ?
18:17
you man I can skip the mdbx_dbi_open step after first time open it ?
18:21
I just test I can reuse dbi in write process.
I have one write process, and multi read process (open env with MDBX_RDONLY).
in the write process, only one thread write in main event loop.
in the read process, there is multi thread read case.
my question is if in read process with mul thread, should I create TLS dbi and reuse it ?
or can I use MDBX_NOTLS and one global dbi ?
I have one write process, and multi read process (open env with MDBX_RDONLY).
in the write process, only one thread write in main event loop.
in the read process, there is multi thread read case.
my question is if in read process with mul thread, should I create TLS dbi and reuse it ?
or can I use MDBX_NOTLS and one global dbi ?
Л(
18:31
Леонид Юрьев (Leonid Yuriev)
Sorry, I can't spend much time on consultations.
Please see the documentation and try to improve it if possible.
Please see the documentation and try to improve it if possible.
18:33
Deleted Account
I will read more docs and do my test.
Thanks very much for this great project. I enjoy use it.
Thanks very much for this great project. I enjoy use it.
👍
Л(
17 December 2022
AS
04:56
Alex Sharov
Hi. I not fully understand: how much begin(no_sync) can be done in a row. As i understand: if within 10ms i will do 10 begin(no_sync)+commit, likely mdbx will do 7-9 blocking “sync” - because mdbx has only 3 meta pages and can’t afford to keep 10 unsynced transactions (in my head: commit of 2-nd no_sync txn will wait for sync, if 1-st not synced yet).
Or in this case (10 sequential no_sync txs in 1 thread) better use sub-txs instead of begin(no_sync)?
Or in this case (10 sequential no_sync txs in 1 thread) better use sub-txs instead of begin(no_sync)?
Л(
09:36
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Basically, one of meta-pages will be "steady" and will not be touched during non-synced commits, and two other will be interleave-update.
AS
09:37
Alex Sharov
In reply to this message
Interesting. Thank you. Then several no_sync will just work.
Л(
09:38
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Yes, but please read the docs for all cons/pros.
10:28
Deleted Account
mdbx:14393: cmp_int_align2: Assertion `a->iov_len == b->iov_len' failed.
Л(
10:46
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Seems you are mixing integer and non-integers keys, either named subDb inside the MAIN_DBI.
Please provide the full use case, so I should add some checks to return errors early than assertions.
Please provide the full use case, so I should add some checks to return errors early than assertions.
10:47
Deleted Account
Thanks for explain, I reuse same database during the test. I will try remove it to clear dirty key.
15:18
Deleted Account
try build inside alpine3.7 with clang 14.0.6 and LLD 15.0.6, if link with LTO get this error:
error: relocation R_X86_64_TPOFF32 against rthc_thread_state cannot be used with -shared
The code is build with "-fPIC"
/usr/bin/clang-14 -msse2 -msse3 -msse4 -msse4.1 -mfma -mavx -mavx2 -maes --target=x86_64-alpine-linux-musl -std=gnu11 -funwind-tables -g -gdwarf-4 -DNDEBUG -O2 -ffunction-sections -fdata-sections -D_GNU_SOURCE -D__UNWIND_H__ -fvisibility=hidden -Wno-extra-semi-stmt -fPIC -flto=full -fmacro -fstack-protector-strong -pipe -DMDBX_BUILD_SHARED_LIBRARY=0 -DMDBX_CONFIG_H="mdbx/config.h" -D_HAS_EXCEPTIONS=1 -D__STDC_CONSTANT_MACROS=1 -D__STDC_FORMAT_MACROS=1 -D__STDC_LIMIT_MACROS=1 -I/opt/d/C/mdbx/src -I. -fno-common -ggdb -Wno-unknown-pragmas -Wextra -fvisibility=hidden -MD -MT CMakeFiles/mdbx-static.dir/src/alloy.c.o -MF CMakeFiles/mdbx-static.dir/src/alloy.c.o.d -o CMakeFiles/mdbx-static.dir/src/alloy.c.o -c mdbx/src/alloy.c
error: relocation R_X86_64_TPOFF32 against rthc_thread_state cannot be used with -shared
The code is build with "-fPIC"
/usr/bin/clang-14 -msse2 -msse3 -msse4 -msse4.1 -mfma -mavx -mavx2 -maes --target=x86_64-alpine-linux-musl -std=gnu11 -funwind-tables -g -gdwarf-4 -DNDEBUG -O2 -ffunction-sections -fdata-sections -D_GNU_SOURCE -D__UNWIND_H__ -fvisibility=hidden -Wno-extra-semi-stmt -fPIC -flto=full -fmacro -fstack-protector-strong -pipe -DMDBX_BUILD_SHARED_LIBRARY=0 -DMDBX_CONFIG_H="mdbx/config.h" -D_HAS_EXCEPTIONS=1 -D__STDC_CONSTANT_MACROS=1 -D__STDC_FORMAT_MACROS=1 -D__STDC_LIMIT_MACROS=1 -I/opt/d/C/mdbx/src -I. -fno-common -ggdb -Wno-unknown-pragmas -Wextra -fvisibility=hidden -MD -MT CMakeFiles/mdbx-static.dir/src/alloy.c.o -MF CMakeFiles/mdbx-static.dir/src/alloy.c.o.d -o CMakeFiles/mdbx-static.dir/src/alloy.c.o -c mdbx/src/alloy.c
Л(
16:03
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Oh, literally for unknown reason clang uses unavailable
Seems this is a clang' bug.
For instance, during LTO loose information that
At least the by-default tls-model is invalid for
Anyway this is the subject to fill an issue and/or notify Alpine' toolchain maintainer.
Suggest you to play with
See https://maskray.me/blog/2021-02-14-all-about-thread-local-storage for more information.
tls_model for the rthc_thread_state (which is a local-thread storage variable, i.e. defined with __thread).Seems this is a clang' bug.
For instance, during LTO loose information that
local-exec and initial-exec models are unavailable for __thread variable in a DSO with -shared.At least the by-default tls-model is invalid for
-fPIC and/or -shared cases.Anyway this is the subject to fill an issue and/or notify Alpine' toolchain maintainer.
Suggest you to play with
-ftls-model option, i.e. try -ftls-model global-dynamic.See https://maskray.me/blog/2021-02-14-all-about-thread-local-storage for more information.
16:05
Deleted Account
thanks for example, let me try tls-model global-dynamic
16:20
Deleted Account
try ‘global-dynamic’, ‘local-dynamic’, ‘local-exec’. get same link error.
one more question about shared vs static build process. If I start one process with shared mdbx library, and one with static link mdbx process . same version.
in this case, they will be ok to read from one mdbx database file ?
one more question about shared vs static build process. If I start one process with shared mdbx library, and one with static link mdbx process . same version.
in this case, they will be ok to read from one mdbx database file ?
Л(
16:25
Леонид Юрьев (Leonid Yuriev)
Please try
__attribute__((tls_model("local-dynamic"))), i.e.:diff --git a/src/core.c b/src/core.c
index 40336995..84c6dcad 100644
--- a/src/core.c
+++ b/src/core.c
@@ -1164,7 +1164,7 @@ static __inline uint64_t rthc_signature(const void *addr, uint8_t kind) {
#define MDBX_THREAD_RTHC_REGISTERED(addr) rthc_signature(addr, 0x0D)
#define MDBX_THREAD_RTHC_COUNTED(addr) rthc_signature(addr, 0xC0)
-static __thread uint64_t rthc_thread_state;
+static __thread uint64_t rthc_thread_state __attribute__((tls_model("local-dynamic")));
#if defined(__APPLE__) && defined(__SANITIZE_ADDRESS__) && \
!defined(MDBX_ATTRIBUTE_NO_SANITIZE_ADDRESS)
16:30
In reply to this message
No any problems, but you should avoid multiple instances of libmdbx code inside a single process: i.e. avoid statically linked libmdbx into exe and/or to a few dynamic libraries that are used.
16:47
confirm clang 15.0.6 fix the problem. with clang 14.0.6 will keep get this error.
sadly I has other tools not able to upgrade to llvm15, hope them fix the problem soon and upgrade to llvm15.
sadly I has other tools not able to upgrade to llvm15, hope them fix the problem soon and upgrade to llvm15.
18:41
Deleted Account
if one app start a read txn, then crashed without close, will this be a problem ?
Л(
18:50
Леонид Юрьев (Leonid Yuriev)
In reply to this message
No any problems.
Dead processes will be cleaned from readers-lock-table.
This is done automatically for all cases, but not performing immediately.
Nonetheless you can use
Dead processes will be cleaned from readers-lock-table.
This is done automatically for all cases, but not performing immediately.
Nonetheless you can use
mdbx_reader_check().
18:52
Deleted Account
This is very great .
20 December 2022
zzir invited zzir
11:03
Deleted Account
I find the window cross process delay is very high. I do this step
1) from process A, send a network request to Process B by HTTP request
2) Process B write the value into mdbx, and response with the value
3) process A get response, then read from mdbx , compare the value
on linux the value is always match, not not for window.
window not math when I get http response. I need do a sleep for 1ms then read from mdbx again, then value is math
1) from process A, send a network request to Process B by HTTP request
2) Process B write the value into mdbx, and response with the value
3) process A get response, then read from mdbx , compare the value
on linux the value is always match, not not for window.
window not math when I get http response. I need do a sleep for 1ms then read from mdbx again, then value is math
11:10
The response is send after txn commit.
Client get the server value first then read local read-only mdbx .
This is for test case
Client get the server value first then read local read-only mdbx .
This is for test case
Л(
15:15
Леонид Юрьев (Leonid Yuriev)
1. libmdbx is strictly ACID, so a changes made can only be seen in transactions started after the commit.
2. The so-called incoherence flaw of unified page cache is known, when data written to a memory-mapped file becomes visible in memory a little later than the return from a
However, according to available information, it was seen on a microsecond scale only on Linux precisely because of the very low delays in non-
3. On Windows most of undiminished/unavoidable latency is
So:
- ensure reading in the transaction which started after a commit, but not before;
- use read-only transactions;
- try MDBX_WRITEMAP to avoid "incoherence flaw".
2. The so-called incoherence flaw of unified page cache is known, when data written to a memory-mapped file becomes visible in memory a little later than the return from a
write() system call.However, according to available information, it was seen on a microsecond scale only on Linux precisely because of the very low delays in non-
MDBX_SYNC_DURABLE modes.3. On Windows most of undiminished/unavoidable latency is
LockFileEx() during staring write transaction, but not for read-only.So:
- ensure reading in the transaction which started after a commit, but not before;
- use read-only transactions;
- try MDBX_WRITEMAP to avoid "incoherence flaw".
17:20
Deleted Account
thanks again for the explain, I will try do mot test to confirm my code has bug or not.
21 December 2022
07:16
Deleted Account
In reply to this message
sorry for false report, it is a bug of my app not commit txn before response.
08:37
Deleted Account
with MDBX_WRITEMAP work as expect from windows.
Alex invited Alex
Aртём invited Aртём
A
15:41
Aртём
Hey folks, English only ?
Л(
15:43
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Нет. Можно и по-русски, см. закрепленное сообщение.
A
15:43
Aртём
хорошо, сейчас 2 вопросика задам.
15:49
Использую раст обвёртку над libmdbx. Пытаюсь присоединится к существующей открытой базе для чтения. Тоесть существующий поцесс пишет, раст аппликация только читает. При открытие еrr: "VersionMismatch" . Если процесс пишущий остановить, то открывает нормально. Я не понимаю или надо сеттер какой-то вызвать при открытие или может надо сбилдить руками либу с какими-то ключами?
let env = Environment::new()
.set_flags(Mode::ReadOnly.into())
.set_max_dbs(32)
.open(Path::new(dir))
.unwrap();
Л(
15:59
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Процессы одновременно работающие с БД должны использовать одинаковую версию libmdbx.
Технически формат БД (основного файла БД) зафиксирован.
Поэтому сами данные читаются/пишутся без каких-либо проблем совместимости
Но еще есть LCK-файл, с таблицей читателей и совместно используемым контекстом.
Этот файл очищается первым процессом открывающим БД, и его формат не зафиксирован.
Таким образом с одной БД могут работать разные версии libmdbx, но одновременно только одной версии (с совпадающим форматом LCK-файла).
Технически формат БД (основного файла БД) зафиксирован.
Поэтому сами данные читаются/пишутся без каких-либо проблем совместимости
Но еще есть LCK-файл, с таблицей читателей и совместно используемым контекстом.
Этот файл очищается первым процессом открывающим БД, и его формат не зафиксирован.
Таким образом с одной БД могут работать разные версии libmdbx, но одновременно только одной версии (с совпадающим форматом LCK-файла).
A
16:05
Aртём
спасибо за ответ! И второй, есть ли пример кода на чтение с максимальной производительностью (128Г рама, 32ядра) База сама несколько террабайт. Думаю открыть несколько кусросоров на чтение в разных тредах, у каждого курсора свой рэндж ключей.
Л(
16:15
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Так 99% времени у вас уйдет на page faults и чтение с диска.
Как сделать быстрее/лучше - большая инженерная тема на грани искусства.
Рекомендую обратиться к командам Akula/Erigon.
Как сделать быстрее/лучше - большая инженерная тема на грани искусства.
Рекомендую обратиться к командам Akula/Erigon.
A
16:17
Aртём
спасибо, посмотрю их сорцы
A
16:48
Aртём
с версиями разбираюсь: база Еригона версии: 0.12 https://github.com/torquem-ch/mdbx-go/blob/v0.27.0/mdbx/mdbx.h
в расте у меня libmdbx = "0.1.11" это 0.12.2-2 . В результате при открытие: VersionMismatch. Как их подружить? Не хочется Go брать.
в расте у меня libmdbx = "0.1.11" это 0.12.2-2 . В результате при открытие: VersionMismatch. Как их подружить? Не хочется Go брать.