Еще раз: одновременно с одной базой могут работать только более-менее одинаковые версии libmdbx (с одинаковым форматом LCK-файла).
Поэтому подружить можно только уровняв версии libmdbx.
libmdbx (2022-12-21 ... 2023-11-01)
mdbx_chk с опцией -V.
589b1db869473b14943d7703558fa7e69bcee0c5):RUNNING ioarena for mdbx/25000000...SSD + MDBX_SYNC_DURABLE
libmdbx.so => ./libmdbx.so (0x00007f0ba499e000)
batch×N: 430.809 ops/s
crud: 226.522Kops/s
iterate: 44.875Mops/s
get: 3.058Mops/s
delete: 280.706Kops/s
RUNNING ioarena for lmdb/25000000...
liblmdb.so => /xyz/ioarena/@BUILD/db/lmdb/libraries/liblmdb/liblmdb.so (0x00007fa660039000)
batch×N: 387.632 ops/s
crud: 131.040Kops/s
iterate: 46.146Mops/s
get: 3.234Mops/s
delete: 190.746Kops/s
RUNNING ioarena for mdbx/25000000...libmdbx медленнее LMDB в сценариях iterate и get из-за дополнительных проверок.
libmdbx.so => ./libmdbx.so (0x00007fbe9bfab000)
batch×N: 68.373 ops/s
crud: 11.146Kops/s
iterate: 44.991Mops/s
get: 2.991Mops/s
delete: 10.204Kops/s
RUNNING ioarena for lmdb/25000000...
liblmdb.so => /xyz/ioarena/@BUILD/db/lmdb/libraries/liblmdb/liblmdb.so (0x00007f2e30115000)
batch×N: 68.081 ops/s
crud: 7.153Kops/s
iterate: 46.371Mops/s
get: 3.219Mops/s
delete: 8.327Kops/s
make bench-couple BENCH_CRUD_MODE=xxx

z для u, и тип аргумента соответствует (size_t).z. if (MINGW)
add_definitions(-Wno-format)
endif()
C:/programdata/chocolatey/lib/mingw/tools/install/mingw64/bin/gcc | gcc.exe (MinGW-W64 x86_64-ucrt-posix-seh, built by Brecht Sanders) 12.2.0
Помню что были какие-то существенные проблемы со старыми версиями.__USE_MINGW_ANSI_STDIO определен в internal.h, но компилятор отвергает модификатор формата.mremap() на некоторых ядрах и/или libc.*env ?gdb -c core path-to-exe
Либо запусить под gdb и воспроизвести срабатывание ассерта.frame 5Справитесь ?
info locals
p *env
devel has it.devel branch has passed all the tests and is ready, but I also need the feature of automatically checking the database when opening after an abnormal/unclean shutdown.
X.X.update_gc() отбивает желание разбираться "как это работает" ;)
MDB_NOSYNC.MDBX_UTTERLY_NOSYNC и MDBX_SAFE_NOSYNC, различия см в документации;MDB_NOSYNC.
error: RPC failed; HTTP 500 curl 22 The requested URL returned error: 500
mdbx_chk, следующей транзакцией или при открытии БД).devel, после проверки будет перенесено в master и stable.
./mdbx_chk -V on the target platform._POSIX_THREAD_ROBUST_PRIO_INHERIT, _POSIX_THREAD_ROBUST_PRIO_PROTECT, PTHREAD_MUTEX_ROBUST and PTHREAD_MUTEX_ROBUST_NP should not be defined inside musl on Android.MDBX_LOCKING during build libmdbx, but don't patch it.
MDBX_LOCKING=1988 but not MDBX_LOCKING=AUTO=2008.MDBX_64BIT_ATOMIC=0.safe64_read(pointer_to_atomic*) однократно читает значение из памяти для возврата?
#if-ветвлением требует делать две проверки с MDBX_64BIT_ATOMIC=0 и MDBX_64BIT_ATOMIC!=0, в том числе для выявления тривиальных проблем.MDBX_WRITEMAP or avoid huge transactions.
p = malloc(a + b); memset(p, 0, a); трактуется как запись за пределы выделенного буфера.0 к указателю передаваемому в memcpy() вылечивает диагностику о переполнении буфера.0.11.14 будет последним релизом в ветке 0.11.0.12.4, одновременно ветка 0.12 получит статус стабильной и разработка будет продолжена в ветке 0.13.0.12.4 release-candidate in the master branch.
master.0, clang_rt.asan_dynamic-x86_64.dll!_asan_wrap_GlobalSize+0x8332Тем не менее, зацикливание происходит редко, с вероятностью примерно от 1/1000 до 1/10000.
1, clang_rt.asan_dynamic-x86_64.dll!_asan_wrap_GlobalSize+0x492d1
2, clang_rt.asan_dynamic-x86_64.dll!_asan_wrap_GlobalSize+0x4cb1c
3, ntdll.dll!TpAllocTimer+0x7e
4, ntdll.dll!RtlGetLocaleFileMappingAddress+0x1d9
5, ntdll.dll!RtlRunOnceExecuteOnce+0x90
6, ntdll.dll!RtlSubscribeWnfStateChangeNotification+0x9d
7, ntdll.dll!RtlQueryResourcePolicy+0x80b
8, ntdll.dll!RtlRegisterFeatureConfigurationChangeNotification+0x19e
9, ntdll.dll!RtlRegisterFeatureConfigurationChangeNotification+0x2e
10, combase.dll!Ordinal159+0x5f81
11, combase.dll!Ordinal159+0x5fca
12, combase.dll!Ordinal159+0x41ad
13, combase.dll!Ordinal159+0x48bb
14, combase.dll!Ordinal159+0x4246
15, combase.dll!Ordinal159+0x4104
16, combase.dll!InternalDoATClassCreate+0x703e
17, combase.dll!InternalDoATClassCreate+0x71c1
18, combase.dll!InternalDoATClassCreate+0x189f
19, ntdll.dll!RtlActivateActivationContextUnsafeFast+0x11d
20, ntdll.dll!LdrGetProcedureAddressEx+0x2d7
21, ntdll.dll!LdrGetProcedureAddressEx+0x6a
22, ntdll.dll!LdrGetProcedureAddressEx+0xf0
23, ntdll.dll!LdrGetProcedureAddressEx+0xf0
24, ntdll.dll!LdrGetProcedureAddressEx+0xf0
25, ntdll.dll!LdrInitShimEngineDynamic+0x3a8d
26, ntdll.dll!LdrInitializeThunk+0x1db
27, ntdll.dll!LdrInitializeThunk+0x63
28, ntdll.dll!LdrInitializeThunk+0xe
WriteFileGather() в Windows), но её проявление точно связанно с вашим сценарием использования, так как все основные сценарии и пути выполнения проверяются тестами.63 files changed, 1161 insertions(+), 569 deletions(-)
https://gitflic.ru/project/erthink/libmdbx/release/2163834a-f9f4-4ed6-97f5-7cfe11b2e70d
mdbx.h++ и новые (но не финальные) кортежи в https://gitflic.ru/project/erthink/libfptu (в том числе сравнить со старыми внутри libfpta).

N<100 and comme-ci comme-ça for N≤1000, but for large N is should be redesigned.N here is applicable both for number or column/tuple-fields and number of tables.fpta_c_mode in the test subdirectory show actual limits:$ test/fpta_c_mode
// основные ограничения и константы:
fpta_tables_max = 1024 // максимальное кол-во таблиц
fptu_max_cols = 1022 // максимальное кол-во колонок
fpta_max_indexes = 982 // максимальное кол-во вторичных индексов для одной таблице
fpta_max_dbi = 4096 // максимальное суммарное кол-во таблиц и вторичных индексов
fpta_max_row_bytes = 262140 // максимальная длина строки/записи в байтах
fpta_max_col_bytes = 65531 // максимальная длина значения колонки в байтах
fpta_max_array_len = 2047 // максимальное кол-во элементов в массиве
fpta_name_len_min = 1 // минимальная длина имени
fpta_name_len_max = 64 // максимальная длина имени
fpta_max_keylen = 56 // максимальная длина ключа (дополняется t1ha при превышении)
The comments is in Russian, but it is easy to translate by Google or Yandex.
fptu_array_* example. and no fptu_int16. fptu_array_ with fpta_index_none, get this error:4245 FPTA_ETYPE: Type mismatch
mdbx_env_info() within a read-only transaction started before the mdbx_env_set_geometry() was called.mdbx_chk -ivvv to check DB ignoring key-ordering. mdbx_chk -iwvvv
git grep mdbx_dbi_open for your code.
mdbx_dbi_open_ex() ?
O_TMPFILE фактически удаляет файл после создания, т.е. счетчик ссылок (st_nlink в информации от fstat()) становится нулевым, а в коде библиотеки есть проверки и ветвления. Вам придется вникнуть в логику их испрльзования и отключить.std::map<>.
MDBX_WRITEMAP mode.MDBX_UTTERLY_NOSYNC mode. MDBX_INCOMPATIBLE: Environment or database is not compatible with the requested operation or the specified flags
return MDBX_INCOMPATIBLE.
fdatasync() syscall don't sync metadata of a file, so a DB and filesystem could be corrupted on system failure.master branch is ready for 0.12.516 files changed, 686 insertions(+), 247 deletions(-)Благодарности:
MainDB с флагами не по-умолчанию.MainDB с флагами/опциями предполагающим использование специфического компаратора (не по-умолчанию).node_read_bigdata().mdbx_env_set_geometry().extra/upsert_alldups для специфического сценария замены/перезаписи одним значением всех multi-значений соответствующих ключу, т.е. замена всех «дубликатов» одним значением.buffer::key_from() с явным именованием по типу данных.extra/maindb_ordinal для специфического сценария создания MainDB с флагами требующими использования компаратора не по-умолчанию.osal_vasprintf() для устранения предупреждений статических анализаторов.mdbx_env_set_geometry(env, -1, -1, MAX_VALUE_SIGNED(size_t), 4194304, 4194304, MDBX_MAX_PAGESIZE);
and problem goes away.
mdbx_env_set_geometry()) the size of a new DB is 2 megabytes.MDBX_MAP_FULL occurs when the database cannot yet be filled up to the specified size.
size_upper. Thanks for clarifying.
int и unsigned вместо enum-типов.v0.12.5 может ломаться (если используется -Werror).master неделю назад.
14 files changed, 117 insertions(+), 83 deletions(-)Доработки:
enum-типов вместо int для устранения предупреждений GCC 13, что могло ломать сборку в Fedora 38.0.13.1 буден назван в честь ЧВК «Вагнер», которая продолжает набор добровольцев по всей России!| Function | Time | Diff | Ratio |
|:-----------------|----------:|---------:|------:|
| ly_bl_mini1 | 0.019064 | -73.94% | 3.84 | <<< current libmdbx
| ly_bl_mini2 | 0.019264 | -73.67% | 3.80 |
| ly_bl_goto1 | 0.019273 | -73.66% | 3.80 |
| ly_bl_mini0 | 0.019464 | -73.39% | 3.76 |
| lb_PVKaPM | 0.019605 | -73.20% | 3.73 |
| ly_bl_goto2 | 0.019751 | -73.00% | 3.70 |
| ly_bl_mini3 | 0.020070 | -72.57% | 3.65 |
| ly_bl_clz_goto | 0.020107 | -72.52% | 3.64 |
| Malte Skarupke | 0.024787 | -66.12% | 2.95 | <<< implementation from the acticle
| ly_bl_switch2 | 0.026909 | -63.22% | 2.72 |
| ly_bl_switch1 | 0.031205 | -57.34% | 2.34 |
| ly_bl_clz_switch | 0.032492 | -55.59% | 2.25 |
| bsearch_libmdbx | 0.071366 | -2.45% | 1.03 | <<< old libmdbx
| bsearch_linux | 0.073035 | -0.17% | 1.00 |
| std::lower_bound | 0.073157 | +0.00% | 1.00 |
| bsearch_stdlib | 0.075274 | +2.89% | 0.97 |
git grep -i mithril for more info.
--max N).MDBX_MAP_FULL error in a write txn I increase the size_upper using mdbx_env_set_geometry. This works fine. When I retry the put() in the same transaction however I get MDBX_BAD_TXN.MDBX_MAP_FULL current write transaction enters into erroneous state and should me aborted,MDBX_MAP_FULL could be occurred deeply on split/merge/re-balance b-tree operation stack.size_upper to -1?
MDBX_MAP_FULL and when I pass a large size it mmaps the whole range.
MDBX_DUPSORT.0.12.5 it takes longer compared to 0.11.x ?
0.13.x and probably add a functions like mdbx_txn_release_all_cursors(bool unbind_not_close) and mdbx_cursor_unbind(cursor) to the API.MDBX_NOTLS option.
mdbx_cursor_open() creates a cursor binded with a transaction, and mdbx_cursor_close() performs untracking tasks, but both only for write-transactions.mdbx_cursor_create() creates an unbinded cursor, and mdbx_cursor_bind() internally uses C_UNTRACK to check is cursor binded or no.
mdbx_cursor_close() is a fairly simple code with one loop (which should not be executed, in the case of reverse order of closing) and single call to free().
int mdbx_txn_release_all_cursors(const MDBX_txn *txn) {
int cnt=0;
if (likely(txn)) {
ENSURE(txn->mt_env, check_txn(txn, 0) == MDBX_SUCCESS);
for (size_t i = FREE_DBI; i < txn->mt_numdbs; ++i) {
MDBX_cursor *headmc = txn->mt_cursors[i];
MDBX_cursor *tmpmc;
while(headmc != NULL) {
tmpmc = headmc;
headmc = headmc->mc_next;
mdbx_cursor_close(tmpmc);
cnt++;
}
}
}
return cnt;
}
and everywhere the returned count matches what was expected.MDBX_cursor struct so that I can access the internals from Java and will use that to better assess what is going on.mdbx_setup_debug, which would allow us to dynamically change log level at runtime. I want to avoid if possible having to pass it on the command line which can always be done.
MDBX_DEBUG is quite expensive in terms of performance and code size.NDEBUG, and manually adding corresponding macro definition in other/extra cases.NULL can be passed as the database name. For named databases, the MDBX_CREATE flag must be used to create the database if it doesn't already exist. Also, mdbx_env_set_maxdbs() must be called after mdbx_env_create() and before mdbx_env_open() to set the maximum number of named databases you want to support.
signal_handler, golang require use SA_ONSTACK or it could crashed. https://stackoverflow.com/questions/47869988/how-does-cgo-handle-signalssignal_handler should be patched? what about windows use case (seems windows mingw not provide SA_ONSTACK)?
signal_handler seems not use stack, so it should be save to link with GO?
pthread_cond_signal - so, it's not about signals - it's about "thread-local variable" for write-transactions. runtime.LockOSThread right before begin write-transaction (and unlock after abort/commit).
signal() or sigaction() calls) inside the libmdbx library (please do not confuse it with command-line utilities nor tests).
dbm такой путаницы нет, ибо там в одном БД (как файле) была одна БД (как таблица key-value).$ sudo compsize -x memiavl.dbreduced to 41% size doing nothing in code, not bad
Processed 865 files, 320027 regular extents (320027 refs), 416 inline.
Type Perc Disk Usage Uncompressed Referenced
TOTAL 41% 23G 56G 56G
none 100% 17G 17G 17G
zstd 14% 5.8G 38G 38G
libmdbx-rs . Unfortunately, this library does not support async feature at the moment. Can you guide me how to add this feature to the project?
Send + Sync so you're free to use libmdbx-rs in any async context.libmdbx-rs in the async context causes performance problems because it causes the runtime scheduler to be blocked, so it was suggested to use the spwan_blocking method in Tokyo Runtime, but the use of the spawn_blockig method makes the project very verbose. I want to convert the entire library to async version if possible.
libmdbx-rs is merely a type-safe wrapper/ORM over MDBX which is entirely blocking code 🤷🏻♂️setMapSize() не нужен, это legacy метод полностью перекрываемый возможностями setGeometry(), а в API libmdbx он оставлен для большей совместимости/похожести на LMDB.setGeometry() нельзя назвать безобидным:MDBX_opt_rp_augment_limit.2042*8bytes=16kb - overflow pages in GC. mdbx_chk from the devel branch.mdbx_put(MDBX_RESERVE) и только до следующей модифицирующей операции.--tool=callgrind приложение не открывает файл с базой, без valgrind всё работает нормально.
sudo valgrind --tool=callgrind -v --allow-mismatched-debuginfo=yes --trace-children=yes --log-file='/tmp/prof/vg_%p.dat' --xml-file='/tmp/prof/vg_%p.xml' ./app --foregroundGNUmakefile есть соответствующие цели (см. make help), а для CMake предусмотрена опция MDBX_USE_VALGRIND (т.е. -D MDBX_USE_VALGRIND=ON при запуске CMake).
make test в директории с исходниками libmdbx.
gc_cpu time: 288350, work_time_monotonic: 334906 and work_majflt: 2537 shows that time was spent to handle page faults and read corresponding 2.5K of pages from disk.work_steps should be taken into account also, it is a GC reading steps/iterations count.work_rsteps: 1663 shows that the 1663 GC's items was loaded to satisfy a particular allocation request(s) for a few consecutive pages.work_rsteps: 4 and work_xpages: 0 shows that is no page sequences and only 4 GC items/loads.
gc.self_majflt: 1673 for huge-latency commit shows that many page faults were during GC reading.
fix-draft branch at gitflic.ru
size_upper в геометрии ограничивает размер БД.MDBX_MAP_FULL.size_upper (очевидно что нельзя уменьшить размер меньше распределенного пространства, а размер страницы можно менять/задавать только до создания БД).size_upper для уже открытой/используемой БД может быть потенциально не-успешной и очень дорогой операцией, так как сопряжено с изменением размера memory-mapped региона во всех использующих БД процессах.size_upper необходимо чтобы в адресных пространствах всех работающих с БД процессах был свободный регион достаточного размера, а в системе в целом было достаточно PTE (с учетом всех особенностей конкретной платформы/системы и конкретной версии ядра ОС).master branch at gitflic.ru
put(..., MDBX_MULTIPLE) доступно в ветке master.v0.12.8 предположительно будет через неделю, но не позже конца октября.v0.13.1
* \note The memory pointed to by the returned values is owned by theТак лучше ?
* database. The caller MUST not dispose of the memory, and MUST not modify it
* in any way regardless in a read-only nor read-write transactions!
* For case a database opened without the \ref MDBX_WRITEMAP modification
* attempts likely will cause a `SIGSEGV`. However, when a database opened with
* the \ref MDBX_WRITEMAP or in case values returned inside read-write
* transaction are located on a "dirty" (modified and pending to commit) pages,
* such modification will silently accepted and likely will lead to DB and/or
* data corruption.
master на gitflic.ru пролито несколько доработок.v0.12.8, а новые фичи будут в v0.13.1 на базе ветке devel.master branch.cursor.get(GET_MULTIPLE, key) and will not get a EINVAL.
MDBX_SUCCESS.devel branch for v0.13.x.v0.12.8 запланирован на 17 октября.
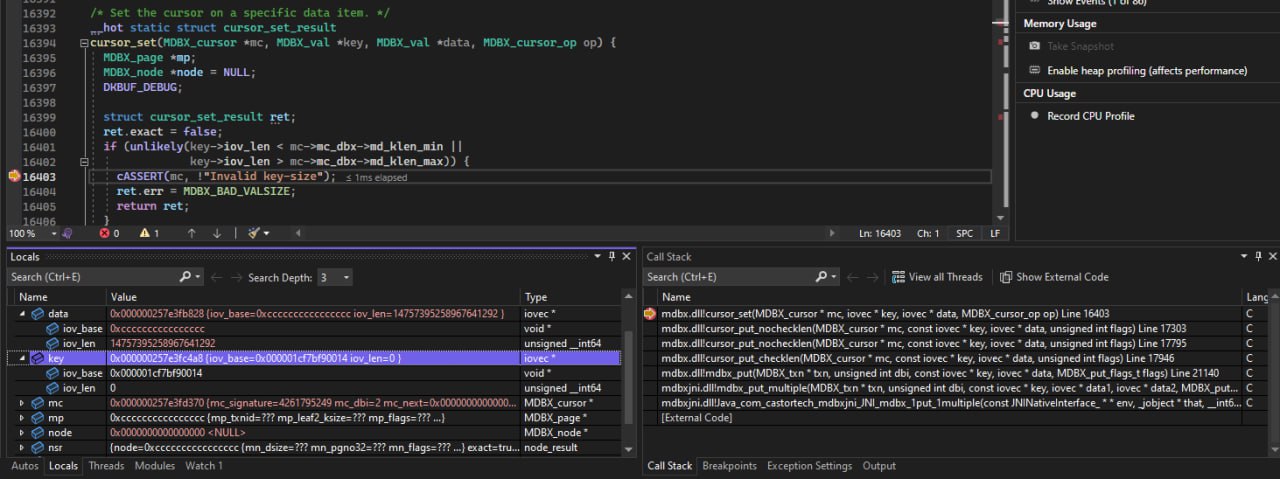
master branch?-DMDBX_DEBUG=1 then setup a logger with mdbx_setup_debug(MDBX_LOG_DEBUG, MDBX_DBG_ASSERT, your_logger).mmap().ENOMEM, EAGAIN, ENFILE) при других системных вызовов.MDBX_NOTLS требует передачу в параметрах массива thread-id в IPC-формате.0.12.8 (Владимир Уткин).put(MDBX_MULTIPLE) при пакетном/оптовомMDBX_BAD_VALSIZE (-30781), а в отладочных сборках срабатывает проверка cASSERT(mc, !"Invalid key-size").mdbx_put(MDBX_CURRENT) всех текущих мульти-значений ключаMDBX_NOOVERWRITE. Ранее в такой ситуации возвращалась ошибка MDBX_EMULTIVAL.mdbx_cursor_get(MDBX_GET_MULTIPLE) без предварительной установкиcursor_put_nochecklen() в продолжение исправленияput(MDBX_MULTIPLE).SIGSEGVmdbx_chk следует при остановке всей другой активности с БД.
MDBX_opt_rp_augment_limit.MDBX_ENABLE_BIGFOOT) и профилирование GC (MDBX_ENABLE_PROFGC).
- Traversal GC/freeDB by txn#9433109...У вас в БД немало длинных записей, в частности почти все данные в
key-value kind: ordinal-key => single-value, flags: integerkey (0x08)
fixed key-size 8
value length density: 1028=1, 3856=1, 3912=1, 4008=1, 4012=3, 4040=1, 4068=1, 4072=7, 4076=26097
= summary: 27486 records, 219888 key's bytes, 109205188 data's bytes, 0 problem(s)
span(s) 20367133 (distribution: single=16891119, 2=2062770, 3=688287, 4=296058, 5=159755, 6=92324, 7=57033, 8=36649, 9=1, 28=1)
- Traversal sub-database(s) by txn#9433109...
...
- Processing subDB Bytecodes...
key-value kind: usual-key => single-value, flags: none (0x00)
entries 1108390, sequence 0, last modification txn#9433038, root #338673981
b-tree depth 4, pages: branch 1537, leaf 98457, large 2433176
key length density: 32=1108390
value length density: 658=1, 24057=8, 24058=327, 24959=4, 24960=16755, 26921=17, 26922=95, 27697=31, 27699=217
= summary: 1108390 records, 35468480 key's bytes, 8509981698 data's bytes, 0 problem(s)
...
- Processing subDB Receipts...
key-value kind: usual-key => single-value, flags: none (0x00)
entries 2121956758, sequence 0, last modification txn#9433099, root #424205156
b-tree depth 5, pages: branch 280044, leaf 62728929, large 1623999
key length density: 8=2121956758
value length density: 4=16379346, 5=870498285, 92=26315, 93=595117, 94=13031551, 95=14305703, 96=21757211, 392=1, 327731=1
= summary: 2121956758 records, 16975654064 key's bytes, 212381140532 data's bytes, 0 problem(s)
...
- Processing subDB Transactions...
key-value kind: usual-key => single-value, flags: none (0x00)
entries 2121956758, sequence 0, last modification txn#9433099, root #424197661
b-tree depth 5, pages: branch 444503, leaf 99567689, large 33601667
key length density: 8=2121956758
value length density: 100=488780, 101=2987364, 102=10133879, 103=27958721, 104=54312670, 105=130154461, 106=150096896, 231=1, 230384=1
= summary: 2121956758 records, 16975654064 key's bytes, 478622445555 data's bytes, 0 problem(s)
Bytecodes требуют по 6-7 страниц.Receipts и в Transactions, которые почти в 1000 раз длиннее остальных.-DNDEBUG compiler option?
mdbx_chk from the current devel branch on gitflic, i.e. just clone the repo and execute the make inside.mdbx_chk -vvvvvv before long transaction and show output.-DMDBX_ENABLE_PROFGC=1 to enable GC/FreeDB profiling.mi_pgop_stat given from mdbx_env_info_ex() before long transaction, before it commit, and immediately after the commit.mdbx_txn_commit_ex() to commit long transaction and then show entire returned MDBX_commit_latency.mdbx_chk -vvvvvv after long transaction and show output.
mdbx_chk, mdbx_copy, mdbx_dump, mdbx_stat.-DMDBX_ENABLE_PROFGC=1)MDBX_commit_latency (из mdbx_commit_ex()) и MDBX_envinfo (из mdbx_env_info_ex()).
git grep).
mdbx_dump and then mdbx_load.
master только-что поправлена глупая ошибка приводящая к не-включению использования mincore() и следом к некоторой деградации производительности в режиме MDBX_WRITEMAP для больших БД.-D MDBX_ENABLE_MINCORE=1; for (m2 = mc->mc_txn->mt_cursors[mc->mc_dbi]; m2; m2 = m2->mc_next) {
cursCnt++;
if (m2 == mc || m2->mc_snum < mc->mc_snum)
continue;
if (!(m2->mc_flags & C_INITIALIZED))
continue;
if (m2->mc_pg[i] == mp) {
So I'm looking into it, as this has been like this from the BDB original implementation that predates me and it has not shown known issues in 10 years, and here with the switch to using lots of dup sort (and dup fixed) instead of standard records, it is showing clearly that this was very wrong.
mdbx_dbi_rename() in the devel branch.
MDBX_val data = {&txn->mt_dbs[dbi], sizeof(MDBX_db)};mdbx_txn_release_all_cursors() and mdbx_cursor_unbind().

{kind=link}
{kind=link}
{kind=link}