mdbx_txn_release_all_cursors() but have just pass 0 for the new argument
libmdbx (2023-11-01 ... 2024-09-27)
mdbx_txn_release_all_cursors() but have just pass 0 for the new argument
MDBX_GET_MULTIPLE just does:end - 1 of the current page. This -1 is the pre-compensation for subsequent MDBX_NEXT_DUP which performed internally during MDBX_NEXT_MULTIPLE.MDBX_NEXT_MULTIPLE just does:MDBX_NEXT_DUP from end - 1 of previous MDBX_GET_MULTIPLE's cursor position. The MDBX_NEXT_DUP used here since it is the simple way for move to the next sibling dupfixed-page without bloating the code.MDBX_GET_MULTIPLE.MDBX_GET_BOTH_RANGE, then check/expect taken data value, and then use MDBX_NEXT_MULTIPLE up on end of a range.
mdbx_env_warmup().MDBX_LOCKING build option).mdbx_env_resurrect_after_fork() from the devel branch at gitflic.
update_gc() не должна выделять последовательности overflow-страниц (только по одной).-DMDBX_ENABLE_BIGFOOT=0.
MdbxError (11) : Try again
EAGAIN (Resource temporarily unavailable) from a system call.strace utility to at least find out which system call ends with this error.
page_alloc_slowpath. Я уже посмотрел на документацию здесь, некоторые ответы в этом чате, тред здесь.page_alloc_slowpath идет по каждой записи в GC. Для каждой записи, он добавляет набор страниц из нее в txn->relist, затем проверяет, можно ли теперь найти необходимую последовательность в txn->relist. Если все записи в GC пройдены или мы достигли augment_limit, то можно пытаться начинать брать новые страницы или расширять размер файла. txn->tw.last_reclaimed + 1. Правда ли, что если каждая запись происходит в новой транзакции, то итерация по GC будет постоянной, т.к. счетчик будет обнуляться?
page_alloc_slowpath() сохранит в контексте транзакции ключ/номер последней считанной из GC записи и при следующем вызове (в рамках текущей транзакции) будет считывать следующие записи.update_gc().mdbx_copy.devel на gitflic пролито расширения API с обещанным "doubtless cursor positioning API", а также сопутствующие доработки.C API добавлены константы для mdbx_cursor_get():/* Doubtless cursor positioning at a specified key. */
MDBX_TO_KEY_LESSER_THAN,
MDBX_TO_KEY_LESSER_OR_EQUAL,
MDBX_TO_KEY_EQUAL,
MDBX_TO_KEY_GREATER_OR_EQUAL,
MDBX_TO_KEY_GREATER_THAN,
/* Doubtless cursor positioning at a specified key-value pair
* for dupsort/multi-value hives. */
MDBX_TO_EXACT_KEY_VALUE_LESSER_THAN,
MDBX_TO_EXACT_KEY_VALUE_LESSER_OR_EQUAL,
MDBX_TO_EXACT_KEY_VALUE_EQUAL,
MDBX_TO_EXACT_KEY_VALUE_GREATER_OR_EQUAL,
MDBX_TO_EXACT_KEY_VALUE_GREATER_THAN,
MDBX_TO_PAIR_LESSER_THAN,
MDBX_TO_PAIR_LESSER_OR_EQUAL,
MDBX_TO_PAIR_EQUAL,
MDBX_TO_PAIR_GREATER_OR_EQUAL,
MDBX_TO_PAIR_GREATER_THAN
С++ API добавлены элементы mdbx::cursor::move_operation:/* Doubtless cursor positioning at a specified key. */
key_lesser_than = MDBX_TO_KEY_LESSER_THAN,
key_lesser_or_equal = MDBX_TO_KEY_LESSER_OR_EQUAL,
key_equal = MDBX_TO_KEY_EQUAL,
key_greater_or_equal = MDBX_TO_KEY_GREATER_OR_EQUAL,
key_greater_than = MDBX_TO_KEY_GREATER_THAN,
/* Doubtless cursor positioning at a specified key-value pair
* for dupsort/multi-value hives. */
multi_exactkey_value_lesser_than = MDBX_TO_EXACT_KEY_VALUE_LESSER_THAN,
multi_exactkey_value_lesser_or_equal =
MDBX_TO_EXACT_KEY_VALUE_LESSER_OR_EQUAL,
multi_exactkey_value_equal = MDBX_TO_EXACT_KEY_VALUE_EQUAL,
multi_exactkey_value_greater_or_equal =
MDBX_TO_EXACT_KEY_VALUE_GREATER_OR_EQUAL,
multi_exactkey_value_greater = MDBX_TO_EXACT_KEY_VALUE_GREATER_THAN,
pair_lesser_than = MDBX_TO_PAIR_LESSER_THAN,
pair_lesser_or_equal = MDBX_TO_PAIR_LESSER_OR_EQUAL,
pair_equal = MDBX_TO_PAIR_EQUAL,
pair_exact = pair_equal,
pair_greater_or_equal = MDBX_TO_PAIR_GREATER_OR_EQUAL,
pair_greater_than = MDBX_TO_PAIR_GREATER_THAN
MDBX_opt_rp_augment_limit.
MDBX_opt_rp_augment_limit точно не решает проблему роста GC/freekbst. а усугубляет её ради ускорения вставки длинных записей.MDBX_opt_rp_augment_limit транзакции с длинными значениями стали быстрее.MDBX_opt_rp_augment_limit.devel, если обещаете сразу тестировать.
MDBX_opt_rp_augment_limit.
MDBX_opt_rp_augment_limit и тогда таймаут MDBX_opt_gc_time_limit будет отсчитываться почти сразу.MDBX_opt_gc_time_limit в том, чтобы не менялось поведение по-умолчанию.
-30791 это MDBX_DBS_FULL /* Environment maxdbs reached */.devel сейчас новый код инициализации, проверки и импорта dbi-хендлов в транзакциях.MDBX_opt_max_db всегда добавлялось +2, и добавляется сейчас).
MDBX_INTEGERKEY offers unsigned integer key comparison in native byte order (but without properly align) and key-length checking, no disanvantages.MDBX_ENABLE_PREFAULT, из-заMDBX_ENABLE_MINCORE не включалась автоматически, что приводилоMDBX_WRITEMAP.MDBX_ENV_CHECKPID при отключении использованияmadvise() посредством опции сборки MDBX_ENABLE_MADVISE=0.madvise(MADV_DONTFORK) не включался контроль pid.NULL при обработке MDBX_GET_MULTIPLE.coherency_check().const для начала и конца диапазона в аргументах mdbx_estimate_range().to_hex() и from_hex().MDBX_opt_rp_augment_limit по умолчанию до 1/3 от текущего количества страниц в БД.git diff' stat: 32 commits, 8 files changed, 667 insertions(+), 401 deletions(-)
base58 и base64.uint64_twhere is transaction id.uint32_t where is a list of pages, the [0] is the number of items and rest are the page numbers. In some rare cases a few unused cells may be at the end it.
MDB_NOLOCK since it is so dangerous for most users. memfd_create() + mdbx_env_copy2fd().
32765"?
uint16_t to uint32_t at least, as well as check the corresponding if/for, etc.MDBX_NOTLS, т.е. нет привязки к нативным потокам linux (не путать с файберами внутри Rust).
mdbx_env_set_hsr() и очищать утекшие транзакции.mdbx_env_copyXXX()) на медленный носитель тоже будет такой залипшей читающей транзакцией.
kill(pid_t pid, int sig).
waloff and lazy options.-l waloff-m sync follow Victor Smirnov suggestion
lazy and waloff options both.mdbx_dbi_open, parameter name, can I mix the use of named db and NULL db?mdbx_cursor_close: Assertion `mc->mc_signature == MDBX_MC_LIVE || mc->mc_signature == MDBX_MC_READY4CLOSE' failed
cursor_get with flag MDBX_FIRST (if count == 0) or MDBX_NEXT (if count > 0)
mdbx.h.For example, to list all key-value pairs in a database, use operation MDBX_FIRST for the first call to mdbx_cursor_get(), and MDBX_NEXT on subsequent calls, until the end is hit.
env_open
txn_begin
dbi_open
cursor_open
count = 0
loop do
rc = cursor_get(cur, key, val, count == 0 ? first : next)
break if rc != 0
do_something_with_kv
count++
end_loop
txn_renew
cursor_close
txn_renew
open_env with flag MDBX_WRITEMAP | MDBX_UTTERLY_NOSYNC and txn_begin with flag MDBX_SAFE_NOSYNC | MDBX_NOMETASYNC to create each write then commit transaction, it's very slow.snapshot isolation overhead?
devel branch.MDBX_DUPFIXED and MDBX_INTEGERDUP, but no with MDBX_DUPSORT.MDBX_DUPFIXED and MDBX_INTEGERDUP implies MDBX_DUPSORT.MDBX_DUPSORT | MDBX_DUPFIXED — affected;MDBX_DUPSORT | MDBX_INTEGERDUP — affected;MDBX_DUPSORT — not affected.
-DCMAKE_BUILD_TYPE:STRING=Release» безсмысленно.cmake --build . --verbose --config Release
P_LEAF2, а ошибка в том что из-за резервирования размер может получиться больше размера страницы БД (происходит переполнение, а далее повреждение структуры БД, стека и/или роспись памяти, etc).growth = IS_LEAF2(fp)
? EVEN(fp->mp_leaf2_ksize)
: (node_size(data, nullptr) + sizeof(indx_t));
if (page_room(fp) >= growth) {
/* На текущей под-странице есть место для добавления элемента.
* Оптимальнее продолжить использовать эту страницу, ибо
* добавление вложенного дерева увеличит WAF на одну страницу.
*/
goto cow_subpage;
}
/* На текущей под-странице нет места для еще одного элемента.
* Можно либо увеличить эту под-страницу, либо вынести куст
* значений во вложенное дерево.
*
* Продолжать использовать текущую под-страницу возможно
* только пока и если размер после добавления элемента будет
* меньше me_leaf_nodemax. Соответственно, при превышении
* просто сразу переходим на вложенное дерево. */
xdata.iov_len = olddata.iov_len + growth;
if (xdata.iov_len > env->me_leaf_nodemax)
goto prep_subDB;
/* Можно либо увеличить под-страницу, в том числе с некоторым
* запасом, либо перейти на вложенное поддерево.
*
* Резервирование места на под-странице представляется сомнительным:
* - Резервирование увеличит рыхлость страниц, в том числе
* вероятность разделения основной/гнездовой страницы;
* - Сложно предсказать полезный размер резервирования,
* особенно для не-MDBX_DUPFIXED;
* - Наличие резерва позволяет съекономить только на перемещении
* части элементов основной/гнездовой страницы при последующих
* добавлениях в нее элементов. Причем после первого изменения
* размера под-страницы, её тело будет примыкать
* к неиспользуемому месту на основной/гнездовой страницы,
* поэтому последующие последовательные добавления потребуют
* только передвижения в mp_ptrs[].
*
* Соответственно, более важным/определяющим представляется
* своевременный переход к вложеному дереву, но тут достаточно
* сложный конфликт интересов:
* - При склонности к переходу к вложенным деревьям, суммарно
* в БД будет большее кол-во более рыхлых страниц. Это увеличит
* WAF, а также RAF при последовательных чтениях большой БД.
* Однако, при коротких ключах и большом кол-ве
* дубликатов/мультизначений, плотность ключей в листовых
* страницах основного дерева будет выше. Соответственно, будет
* пропорционально меньше branch-страниц. Поэтому будет выше
* вероятность оседания/не-вымывания страниц основного дерева из
* LRU-кэша, а также попадания в write-back кэш при записи.
* - Наоботот, при склонности к использованию под-страниц, будут
* наблюдаться обратные эффекты. Плюс некоторые накладные расходы
* на лишнее копирование данных под-страниц в сценариях
* нескольких обонвлений дубликатов одного куста в одной
* транзакции.
*
* Суммарно наиболее рациональным представляется такая тактика:
* - Вводим три порога subpage_limit, subpage_room
* и subpage_reserve, которые могут быть заданы/скорректированы
* пользователем в ‰ от me_leaf_nodemax;
* - Используем под-страницу пока её размер меньше subpage_limit
* и на основной/гнездовой странице не-менее subpage_room
* свободного места;
* - Резервируем место только для 1-3 коротких dupfixed-элементов,
* расширяя размер под-страницы на размер кэш-линии ЦПУ, но
* только если на странице не менее subpage_reserve свободного
* места.
* - По-умолчанию устанавливаем subpage_limit = me_leaf_nodemax (1000‰),
* subpage_room = 0 и subpage_reserve = me_leaf_nodemax (1000‰).
*/
/dev/shm и вызывать mdbx_env_copy() (либо утилиту mdbx_copy) для копирования данных "из памяти" когда посчитаете необходимым.mdbx.h), а также поискать статьи по LMDB/MDBX в Сети.mdbx_txn_abort().malloc() и освобождается через free().mdbx_txn_reset() (транзакция будет прервана, но экземпляр не освобожден) и затем mdbx_txn_renew().
$ git grep "to enumerate the reader lock table"
mdbx.h:/** \brief A callback function used to enumerate the reader lock table.
devel подготовлено несколько существенных доработок, включая полное устранение проблемы.MDBX_INTEGER_KEY это только ограничения на размер ключа и фиксированный встроенный компаратор (функция сравнения).memcmp() при сравнении ключей.
master подготовлен версия-кандидат для выпуска v0.12.10.MDB_NOLOCK was removed from MDBX since it actually was a bad feature:mdbx_put() with the one transaction.
mdbx_cursor_put();MDBX_APPEND and/or MDBX_APPENDDUP;MDBX_LOCKING build option) must be able to release the lock from a different thread (which not owned the lock). This is system depended;MDBX_TXN_CHECKOWNER build option).
MDBX_NOTLS option, but including write transactions.Теперь можно обновить список выводов:
Запись + мало потоков => WiredTiger
Запись + много потоков => RocksDB
Чтение + DATA > RAM => RocksDB
Чтение + DATA < RAM => MDBX
Много потоков + DATA > RAM + Упаковка => Aerospike
> Добрый день, я изучаю samba ad и там используется lmdb подскажите насколько база mdbx
> быстрее чем lmdb и проводились ли какие либо тесты с этими базами? так как замечаю что
> lmdb на больших объемах данных уже не такая быстрая)
DUPSORT feature is the approach when multiple values associated with the same key are stored in nested b-tree.devel влита в master.NOTLS для пишущих транзакций (полная отвязка транзакций от потоков).v0.13.1 намечен на 9 апреля.
EOWNERDEAD with system-side recovery) was defined/standardized by POSIX-2008.
std::shared_mutex is for shared/exclusive locking, aka "rd-wr" (read-write lock), i.e. multiple readers (shared lock) either single writer (exclusive).0.13.x, то что сейчас уже в master ?gc_update() после доработок.MDBX_LOCKING and target OS.MDBX_LOCKING == MDBX_LOCKING_POSIX1988 (with POSIX-1 Shared anonymous semaphores).v0.13.1 был запланирован на 9 апреля, но пока откладывается из-за одного не устраненного регресса.MDBX_PROBLEM (-30779).add_subdirectory("lib/mbdx")). Как его попросить не перебилживаться каждый раз если поменяется внешний cmake, никак не связанныый с изменениями?
make dist внутри директории с локальным клоном git-репозитория и взять фалы из подкаталога ./dist.conan2 рецепт в центральном репозитории )
make dist будет сформирован набор файлов, которые вам достаточно просто добавить в ваш проект, можно прям как сейчас в lib/mdbx.git clone ..
cd my_prject
mkdir build
cd build
cmake ..
make
cd lib/mbdx
mkdir build
cd build
cmake ..
make dist
make dist или не будите использовать git-submodule или cmake-subproject.
In file included from /home/b/development/cpp/syncspirit/lib/mbdx/src/alloy.c:18:
/home/b/development/cpp/syncspirit/lib/mbdx/src/osal.c: In function 'osal_ioring_add':
/home/b/development/cpp/syncspirit/lib/mbdx/src/osal.c:704:24: warning: cast from pointer to integer of different size [-Wpointer-to-int-cast]
704 | (uintptr_t)(uint64_t)item->sgv[0].Buffer) &
| ^
i686-w64-mingw32-g++ ).
item->sgv это массив из FILE_SEGMENT_ELEMENT, в котором поле Buffer имеет тип PVOID64.Buffer 32-битным, а результирующий код может неожиданно сбоить в специфических ситуациях (в каких-то сценариях при запуске 32-битного приложения на 64-битной Windows);((uintptr_t)((uint64_t)(item->sgv[0].Buffer))), т.е. добавить скобочек чтобы четче увидеть подсветку в диагностике.
uintptr_t 32-х битный на 32х битной платформе. Собтсвенно по этому и ругается?
mdbx_env_create()
unsuitable page size 0
-- a/src/osal.c
+++ b/src/osal.c
@@ -1090,7 +1090,7 @@ MDBX_INTERNAL_FUNC void osal_ioring_reset(osal_ioring_t *ior) {
for (ior_item_t *item = ior->pool; item <= ior->last;) {
if (!HasOverlappedIoCompleted(&item->ov)) {
assert(ior->overlapped_fd);
- CancelIoEx(ior->overlapped_fd, &item->ov);
+ CancelIo(ior->overlapped_fd);
}
if (item->ov.hEvent && item->ov.hEvent != ior)
ior_put_event(ior, item->ov.hEvent);
DllMain().mdbx.h, в частности блок комментария со строки 695 в текущей master-ветки.mdbx_module_handler({}, {}, {}); вызывается). В принципе, мне не так важно. Ещё раз спасибо за фидбэк и наводки! 👍👍👍
/home/b/development/cpp/syncspirit/lib/mbdx/src/osal.c: In function 'osal_ioring_reset':
/home/b/development/cpp/syncspirit/lib/mbdx/src/osal.c:1093:9: warning: implicit declaration of function 'CancelIoEx'; did you mean 'CancelIo'? [-Wimplicit-function-declaration]
1093 | CancelIoEx(ior->overlapped_fd, &item->ov);
| ^~~~~~~~~~
| CancelIo
[ 3%] Linking C shared library libmdbx.dll
/home/b/development/cpp/mxe/usr/bin/i686-w64-mingw32.static-ld: CMakeFiles/mdbx.dir/objects.a(alloy.c.obj):alloy.c:(.text+0xb23): undefined reference to `CancelIoEx'
CancelIoEx() действительно ломает совместимость c Windows XP, повышая минимальные требования до Windows Vista.DllMain(), см. https://learn.microsoft.com/en-us/windows/win32/dlls/dllmainmdbx_module_handler((HMODULE)0, DLL_PROCESS_ATTACH, 0).
MDBX_LIFORECLAIM flag turns on LIFO policy for recycling a Garbage Collection items, instead of FIFO by default. On systems with a disk write-back cache, this can significantly increase write performance, up to several times in a best case scenario.
LIFO recycling policy means that for reuse pages will be taken which became unused the lastest (i.e. just now or most recently). Therefore the loop of database pages circulation becomes as short as possible. In other words, the number of pages, that are overwritten in memory and on disk during a series of write transactions, will be as small as possible. Thus creates ideal conditions for the efficient operation of the disk write-back cache.
MDBX_LOCKING build option).update_gc() improvements in the current code (the master branch) that lead to regression in certain rare case.MDBX_WRITEMAP mode.mdbx_txn_straggler() or mdbx_txn_info() to check to assess the situation and interrupt/restart the read transaction or scan as a whole.MDBX_hsr_func on the writer side and kick/kill sanner-reader by a signal.mdbx_cursor_scan() could be a best choice.
mdbx_cursor_get_batch(..., MDBX_GET_CURRENT) will be dropped in v0.13.x, but MDBX_FIRST and MDBX_NEXT will still work with batch-get.MDBX_GET_CURRENT на выходе из mdbx_cursor_get_batch() требуется оставлять курсор в неконсистентном внутреннем состоянии, когда курсор стоит за концом данных на текущей странице, но не переходит к следующей.mdbx_cursor_get_batch(..., MDBX_GET_CURRENT) у меня всегда вызывало большие сомнения, но такое поведение было реализовано для совместимости (см. https://libmdbx.dqdkfa.ru/dead-github/issues/236).
filemap_fault() в mm/filemap.c5.15.txn.mt_txnid, which is always set to head.txnid for a read-only transaction. Nested transactions can have the same txnid as their parent, but they aren't available for RO transactions.mmap() and OS unified page cache.MDBX_WRITEMAP) libmdbx internally uses modified (aka dirty) page list for https://en.wikipedia.org/wiki/Shadow_paging. Briefly it is a list of pages with should be written to a disk on transaction commit.MDBX_WRITEMAP) libmdbx prefers to minimize overhead, don’t use DPL and thus disables nested transactions.MDBX_WRITEMAP) uses a large memory for shadow paging (see above).
MDBX_NOSTICKYTHREADS, a read transactions must be binded/pinned to threads, and this requires using thread API in a non-portable way. Therefore cloning read transactions could be performed from a "target" threads which will be executed such transactions.int mdbx_txn_clone(const MDBX_txn *origin, MDBX_txn **clone) to the API.mmap() becomes completely useless in this case and just increase the size of page tables.
admin@erigon5900d:~/erigon$ vmtouch -v chaindata
vmtouch: WARNING: unable to stat chaindata (No such file or directory)
Files: 0
Directories: 0
Resident Pages: 0/0 0/0
Elapsed: 6.5e-05 seconds
admin@erigon5900d:~/erigon$ vmtouch -v gg/chaindata
gg/chaindata/mdbx.lck
[OOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOO] 251/251
gg/chaindata/mdbx.dat
[OOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOo] 1532416/1536000
Files: 2
Directories: 1
Resident Pages: 1532667/1536251 5G/5G 99.8%
Elapsed: 0.048304 seconds
write
* i.e. the summary duration of a `write()` syscalls during commit. */
uint32_t write;
MDBX_WRITEMAP the write-latency metric should be 0, since no write() syscall(s) should be, but only msync().MDBX_AVOID_MSYNC != 0 (it is a built-time option, especially for Windows where msync is madly slow).
COMMIT LATENCY
WRITE_LATENCY (ms) 15
SYNC_LATENCY (ms) 0
ENDING_LATENCY (ms) 0
WHOLE_LATENCY (ms) 15
struct MDBX_commit_latency.
struct MDBX_commit_latency {
/** \brief Duration of preparation (commit child transactions, update
* sub-databases records and cursors destroying). */
uint32_t preparation;
/** \brief Duration of GC update by wall clock. */
uint32_t gc_wallclock;
/** \brief Duration of internal audit if enabled. */
uint32_t audit;
/** \brief Duration of writing dirty/modified data pages to a filesystem,
* i.e. the summary duration of a `write()` syscalls during commit. */
uint32_t write;
/** \brief Duration of syncing written data to the disk/storage, i.e.
* the duration of a `fdatasync()` or a `msync()` syscall during commit. */
uint32_t sync;
/** \brief Duration of transaction ending (releasing resources). */
uint32_t ending;
/** \brief The total duration of a commit. */
uint32_t whole;
/** \brief User-mode CPU time spent on GC update. */
uint32_t gc_cputime;
....
fmt.Println("COMMIT LATENCY")
fmt.Println("WRITE_LATENCY (ms)", latency.Write.Milliseconds())
fmt.Println("SYNC_LATENCY (ms)", latency.Sync.Milliseconds())
fmt.Println("ENDING_LATENCY (ms)", latency.Ending.Milliseconds())
fmt.Println("WHOLE_LATENCY (ms)", latency.Whole.Milliseconds())
write() syscalls were, which should not been in "write map" mode.write() with non-sync/lazy fd-descriptor and subsequent fdatasync().write_latency == 15ms with sync_latency == 0 seems are impossible/invalid/wrong metrics.
devel уже доступна версия libmdbx, которая с минимальными ad hoc доработками станет очередным мажорным выпуском v0.13.1devel), где изложены причины/мотивация, а также соображения по поводу легитимности.MDBX_ENODATA) и этим пресекает развитие ситуации в сторону UB.MDBX_GET_BOTH, MDBX_GET_BOTH_RANGE, MDBX_SET, MDBX_SET_KEY).
ms_depth in a table using the MDBX_DUPSORT flag? As far as I understand, if a key has many values, the values will be stored in a new tree, so the depth for the different values could be different.
MDBX_DUPSORT a tree-structure may be nested, i.e. if a key (a tree' node) have a lot of multi-values ones will be stored in a nested tree attached to a such node.ms_depth always means the height of main/first tree, but knows nothing of any nested.mdbx_get_ex() and mdbx_cursor_count();n-bit means a presence of nested tree(s) height n) by mdbx_dbi_dupsort_depthmask().
O(Log(N) + N).O(Log(N)/N + 1).O(Log(N)/N + 1) is right basically.O(1) for single move-to-next operation.ms_branch_pages, ms_leaf_pages, and ms_overflow_pages? Are they also only for the main tree or for all the table?
ms_overflow_pages (since it not used for dupsort tables nor nested trees).master.158 files changed, 40280 insertions(+), 33403 deletions(-)
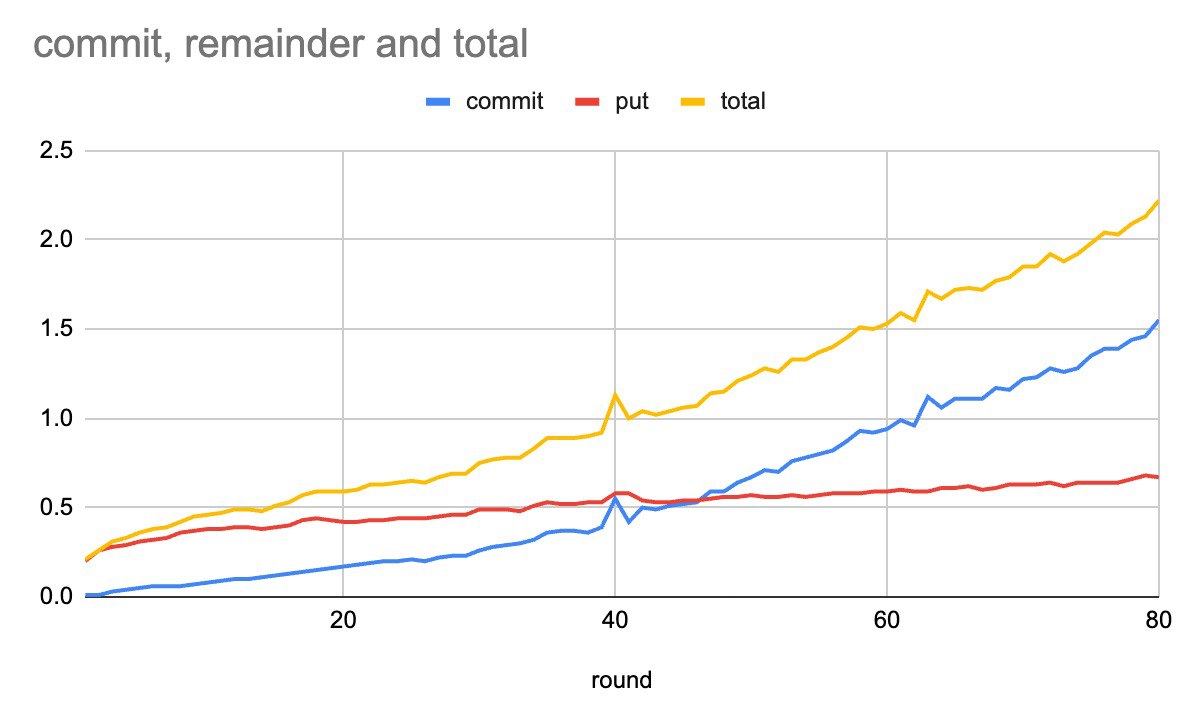
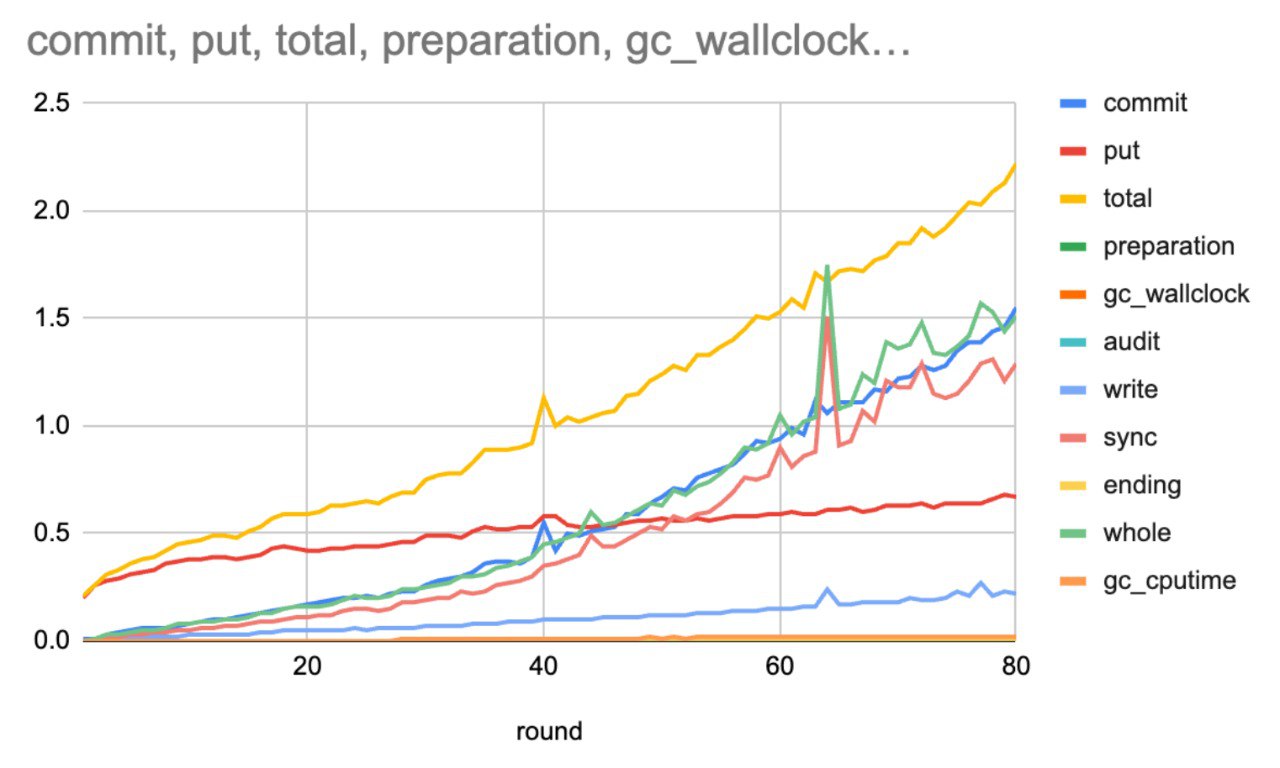
sync is the decisive factors here.
wops counter for non-MDBX_WRITEMAP mode, or the sync metric for writemap-mode).gc_wall clock has the most time, while gc_cpu time is close to zero.MDBX_ENABLE_BIGFOOT build option is enabled.mdbx_copy -c) to get rid of the large GC.
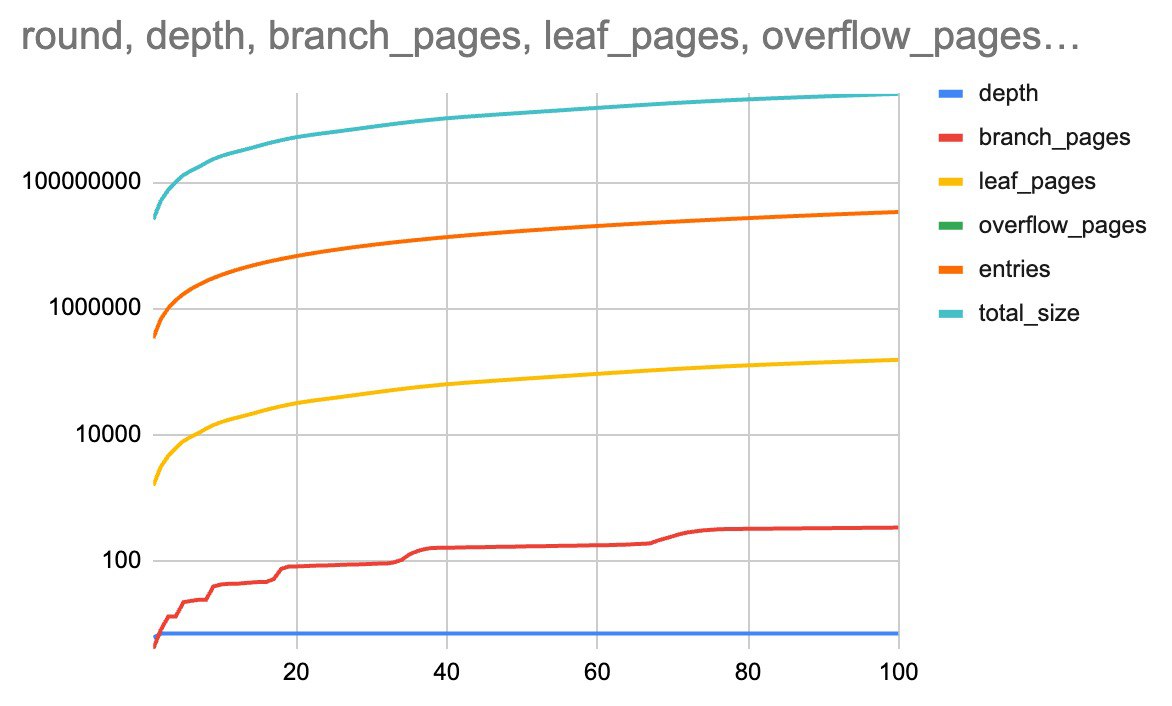
MDBX_BIGFOOT is enabled and we're using v0.12.10
sync is in a completely different complexity class than write.
write() syscall just put io-request in a queue, but sync() wait for these request(s) to complete and then issues a flush/sync command.MDBX_WRITEMAP mode libmdbx uses pwrite(lazy-fd)+fdatasync() for write many pages, but just pwrite(sync-fd) for a few page cases.MDBX_WRITEMAP only the msync() will be used on linux (MDBX_AVOID_MSYNC=0).mdbx_env_info_ex() to get a "page operation statistic" (mi_pgop_stat) and draw it.
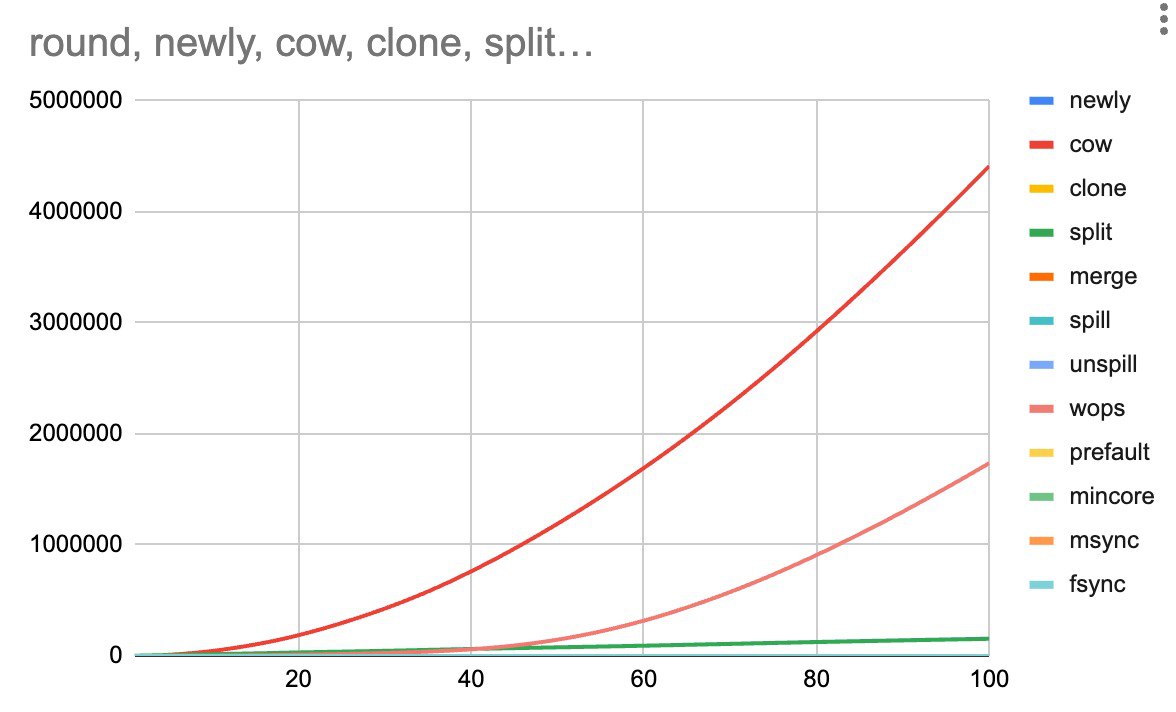
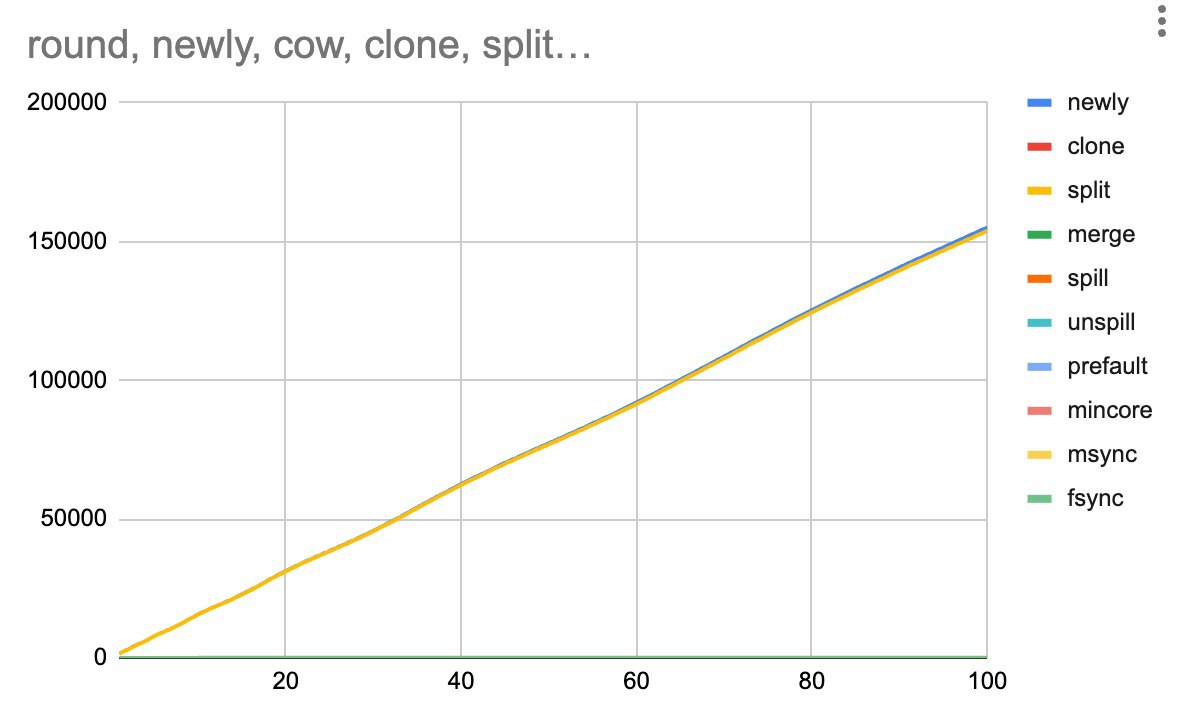
MDBX_WRITEMAP mode and analyze only wops (the number of write operations).MDBX_WRITEMAP is already turned off, but good point regarding the cumulative numbers. we'll have a look and see whether it matches our estimates
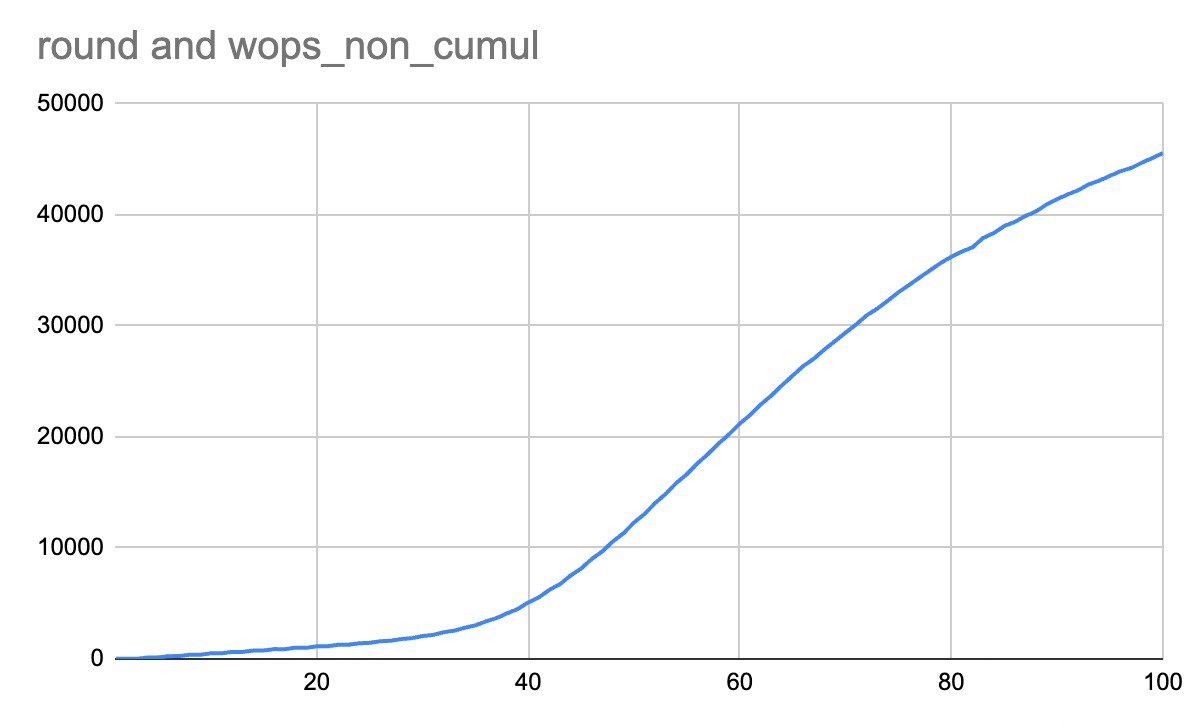
wops is a counter of operations, but not of written pages.write() syscall can write a few consecutive pages.master есть API для проверки целостности БД.subdb_filter,см MDBX_chk_callbacks.mdbx.h
master обнаружена проблема, с сожалению пока без сценария уверенного воспроизведения.env.close_map(testHandle);1 + 1 + 1 < 32767 - 1 - 1

MDBX_INTEGERKEY и 64-битный ключей, эти ключи будут интерпретироваться встроенной функцией сравнения как без-знаковые значения, т.е. помещенные в БД пары ключ-значение будут отсортированы по ключам как значениям типа uint64_t.int64_t.mdbx_key_from_int64(), а при чтении в обратную сторону посредством mdbx_int64_from_key().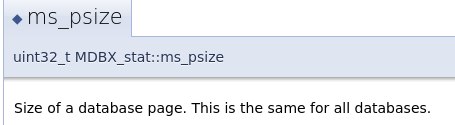
v0.13.1.v0.13.1 либо в следующую версию (v0.13.2).devel добавлена "парковка читающих транзакций":mmap() обеспечивает нулевые накладные расходы при чтении закешированных данных в памяти, но в замен добавляет расходов на подкачку этих данных с диска.mmap(), то встаёт вопрос кеширования.mincore()+O_DIRECT внутри mdbx_env_copy().mmap() тут выглядит заманчивым, но легко может создать еще один слой проблем из-за необходимости отслеживания старых снимков/файлов, вплоть до принудительного отстрела транзакций/процессов.d
mdbx_stat v0.12.9-16-gfff3fbd8 (2024-03-06T22:58:31+03:00, T-c5e6e3a4f75727b9e0039ad420ae167d3487d006)
Running for gg/chaindata/...
Environment Info
Pagesize: 8192
Dynamic datafile: 24576..13194139533312 bytes (+16777216/-33554432), 3..1610612736 pages (+2048/-4096)
Current mapsize: 13194139533312 bytes, 1610612736 pages
Current datafile: 14143193088 bytes, 1726464 pages
Last transaction ID: 456
Latter reader transaction ID: 446 (-10)
Max readers: 32114
Number of reader slots uses: 7
Garbage Collection
Pagesize: 8192
Tree depth: 1
Branch pages: 0
Leaf pages: 1
Overflow pages: 187
Entries: 208tatus of CommitmentVals
Pagesize: 8192
Tree depth: 4
Branch pages: 2911
Leaf pages: 481699
Overflow pages: 0
Entries: 6476355
mdbx_chk -vvv path-to-db to unsure that are no pages lost during alloc/free, etc.mdbx_chk -vvvvv (i.e. more v to verbosity) for "page filling" and/or "length density" of k/v statistics, etc.
mdbx_env_chk() and internals.
- Исправление для ОС Windows нарезки `FILE_SEGMENT_ELEMENT`.
Похоже что был потерян коммит входе работы над оптимизацией пути записи
на диск в ОС Windows. В текущем понимании, вероятность проявления ошибки
достаточно низкая, так как выявлена она была синтетическими тестами в
ходе других доработок, а соответствующих сообщений/жалоб не поступало. К
повреждению БД ошибка не приводила, так как сбой происходил до записи
данных с возвратом `ERROR_INVALID_PARAMETER` из системного вызова, т.е.
либо ошибка не проявлялась, либо транзакция не фиксировалась.
MDBX_commit_latency struct.work_counter?work_rsteps?work_majflt also include minor page faults?
mdbx_cursor_put() не подтвердилась.MDBX_DEBUG) и включенном режиме MDBX_WRITEMAP (при этом ведутся списки "грязных" страниц и в режиме отладки существенно увеличиваются затраты на их проверку).mdbx_cursor_del() за месяц воспроизвести не удалось.MDBX_ENODATA) позволил выявить несколько потенциально опасных мест в Erigon.mdbx_cursor_del(MDBX_CURRENT) или mdbx_cusor_get(MDBX_CURRENT), то могло происходить падение.2202208129956448 (Валентина В).libfpta, it is under development.mdbx_copy tool or mdbx_env_copy().mdbx_env_copy() didn't accepting a txn as argument, but start read txn internally.devel branch.mdbx_txn_copy2fd(), but likely it will work.MDBX_CP_THROTTLE_MVCC enforces using mdbx_txn_park()/mdbx_txn_unpark() during copy/write data;MDBX_CP_DONT_FLUSH you could avoid flush (which could be a while) before transaction end.EINVAL if MDBX_CP_THROTTLE_MVCC flags passed with read-write transaction.
mdbx_env_turn_for_recovery().mdbx_env_open_for_recovery(TARGET_META) + mdbx_env_turn_for_recovery().mdbx_txn_copy2pathname() was added.
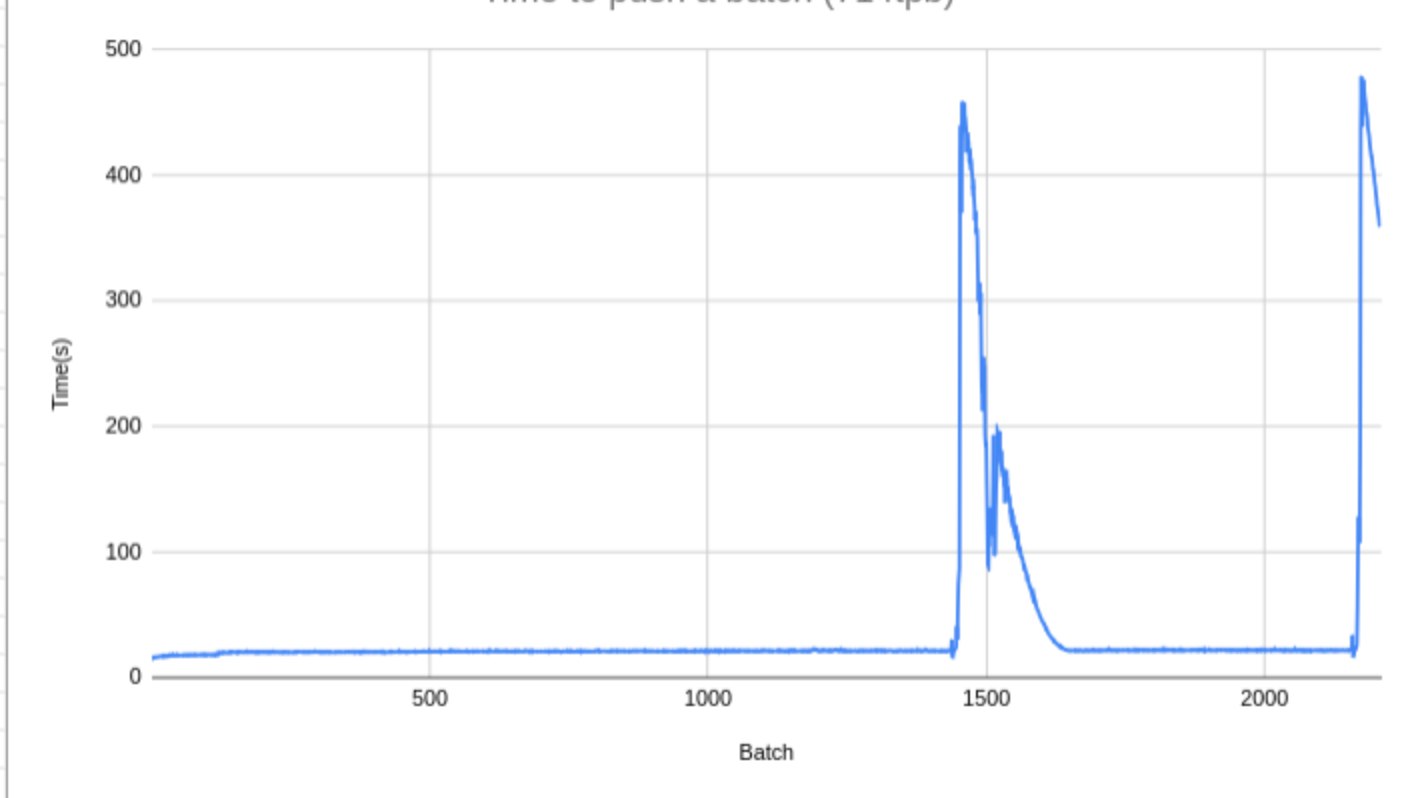
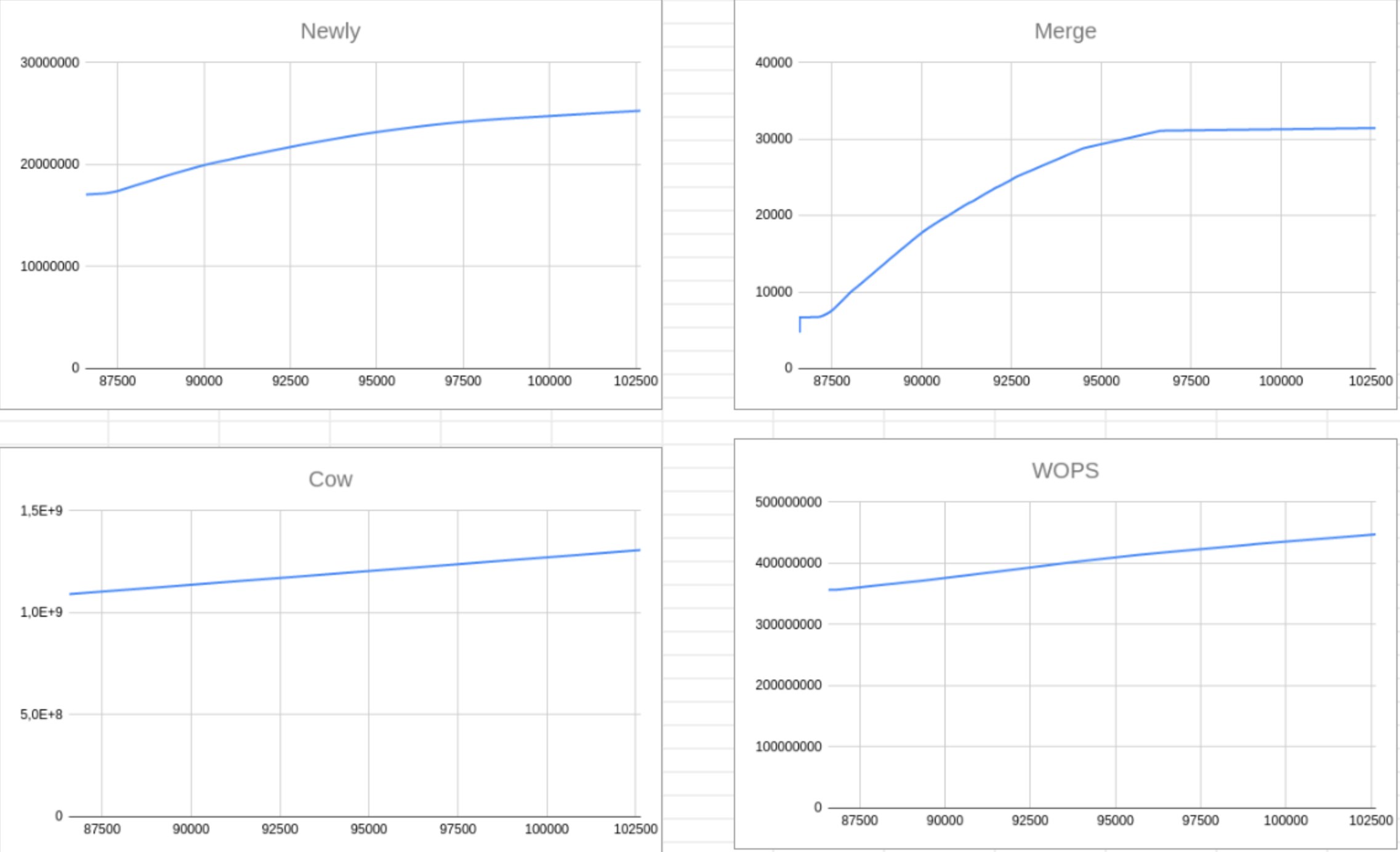
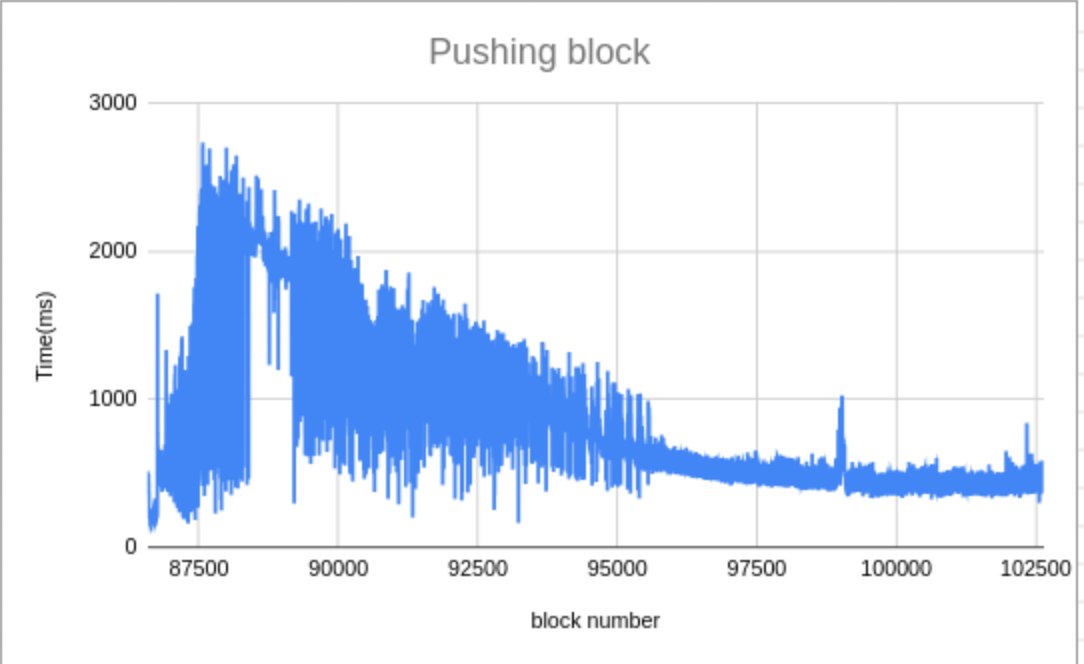
MDBX_commit_latency from mdbx_txn_commit_ex() for a some "stucked" transaction.mdbx_env_get_valsize4page_max() returns ?master-ветку пролиты как-бы последние правки перед формированием выпуска.mdbx_txn_copy2pathname() и mdbx_txn_copy2fd(), там устранены мелкие ошибки/недочеты, а также сделан переход на использование термина "таблица" вместо "sub-database" (включая использование "database" в значении "sub-database" согласно традициям BDB).master в качестве v0.13.1.
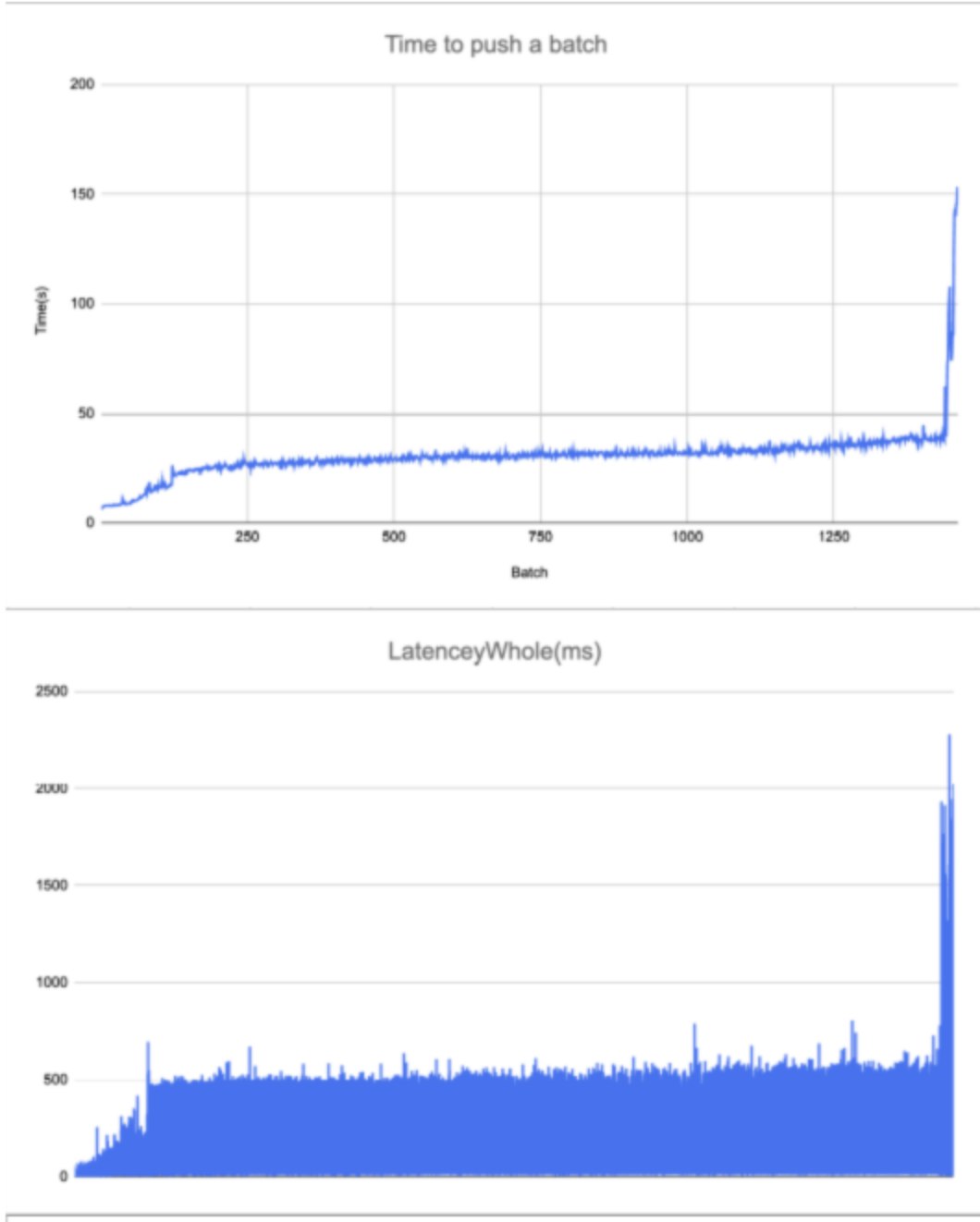
mdbx_env_get_valsize4page_max() returns by a factor of ~25x
mdbx_env_get_valsize4page_max().MDBX_commit_latency contains a sufficient number of fields to find out where delays occur and ones causes.-DMDBX_ENABLE_PROFGC=1 build-time option.gc_prof sub-structure of MDBX_commit_latency.
SIGSEGV при обращении к только-что добавленному сегменту.coherency_check() из-за того, что процесс "Б" не видит добавленный сегмент в своём виртуальном адресном пространстве.mdbx.h и просматриваем декларации в mdbx.h++;mdb_ -> mdbx_ и MDB_ -> MDBX_;mdb_dump и загружаем посредством mdbx_load.gc_update() — аналога mdb_freelist_save()).mdb_freelist_save() и gc_update() очень сложны, так как изменяют b-tree внутри которого хранятся списки свободных страниц, с использованием этих-же страниц.mdb_freelist_save() относительно простая (с одной извилиной) поэтому хорошо работает только в простых/тривиальных случаях, а в сложных может работать неприемлемо медленно, в том числе зацикливаться до бесконечности.gc_update() уже адски сложная/запутанная, но еще есть сценарии/случаи когда она может зацикливаться (в текущем понимании это не затрагивает пользователей, так как проблемные сценарии крайне специфичны и приведут к возврату ошибки, а не бесконечному циклу).mdbx_env_get_valsize4page_max()) она пока остается.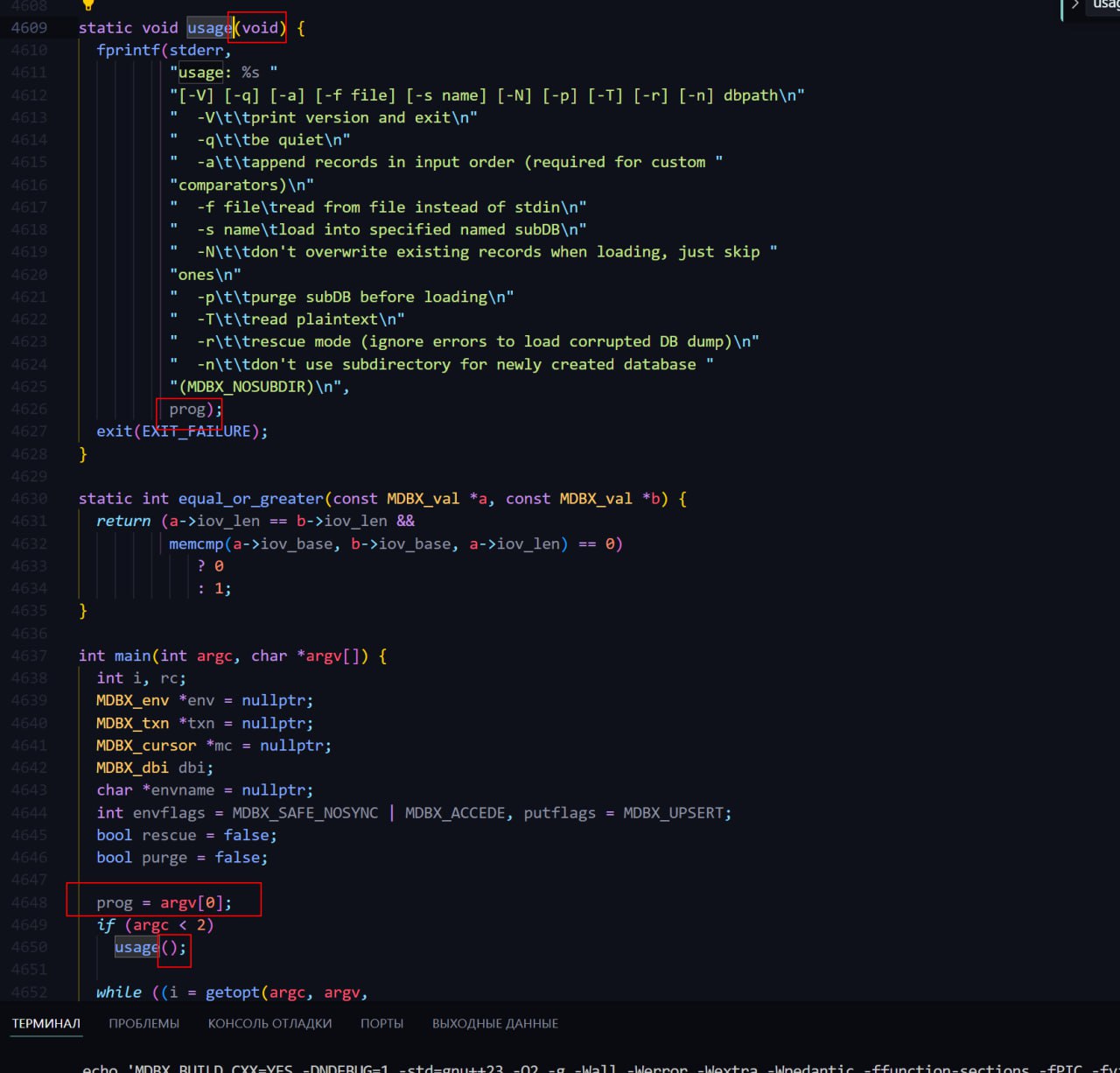
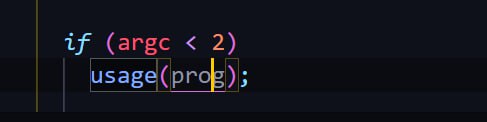
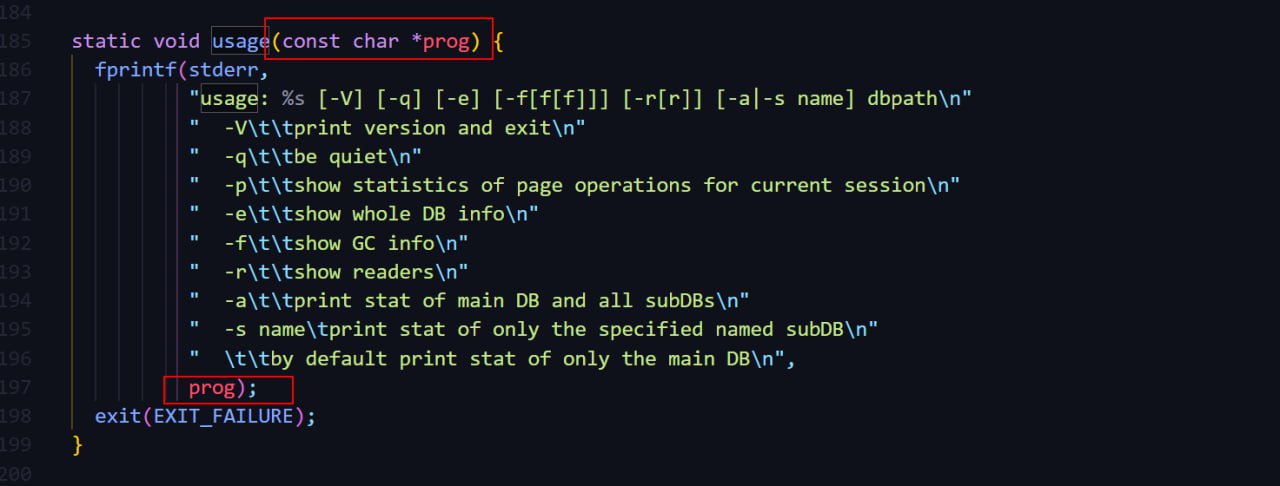
C и упускаете вполне очевидное.mdbx_load не со скомпилированными машинным исполнимым кодом, а вроде-бы с исходным кодом из mdbx_load.c.prog определена как static в глобальном контексте.usage() и -s выдает не компилятор, а shell или что-от типа этого.
make clean и затем make.
make dist.
PTHREAD_PROCESS_SHARED+PTHREAD_MUTEX_ROBUST POSIX-2008 mutexes.devel на Gitflic.stable-ветку, а также продвину master.
MDBX_CREATE), вместо возврата ошибки.
MDBX_CREATE пустая таблица успешно пересоздаётся с новыми флагами/опциями.MDBX_CREATE не указан, то будет возвращена ошибка.
stable-ветке не воспроизводится.DB_VALID или чего-либо похожего).
v0.13.1 проставлен, выпуск новой версии состоялся.MDBX_opt_rp_augment_limit to 1 achieve that?
MDBX_opt_gc_time_limit instead of MDBX_opt_rp_augment_limit.65 (which corresponds to 1 millisecond, since 65535/1000=65).
MDBX_opt_rp_augment_limit that guarantees that each time a page is needed, a search in the free list will be done before expanding the file? MDBX_opt_gc_time_limit suggestion, I see that this value will affect only if the MDBX_opt_rp_augment_limit limit has come, so I still need to configure MDBX_opt_rp_augment_limit with a small value.
MDBX_opt_rp_augment_limit нет — это целиком определяется сценарием использования, в том числе содержимым GC (что в общем случае зависит от всей истории операций с БД). Чтобы БД не увеличивалась зря нужно не ограничивать поиск вглубь GC, а все ограничения — это уже компромиссы.MDBX_opt_rp_augment_limit — this is entirely determined by the usage scenario, including the contents of the GC (which generally depends on the entire history of database operations). In order for the database not to increase in vain, it is necessary not to limit the GC search, and all restrictions are compromises.
MDBX_opt_rp_augment_limit only in the case where big objects need to be written to the end of the file without spending time searching in the free list, but small objects (and branch pages) need to be taken from the free list.
MDBX_opt_rp_augment_limit to one in some cases will cause an increase in the DB also when putting small values (and when there are still pages in the free list).
MDBX_ENABLE_BIGFOOT=1 (enabled by default for 64-bit arches).MDBX_opt_rp_augment_limit effects only big objects, and/or huge transactions if "big foot" feature disabled (i.e. MDBX_ENABLE_BIGFOOT=0).NOTICE в ваши проекты и т.п.);MDBX_NOSTICKYTHREADS).env в одном процессе.MDBX_DBG_LEGACY_MULTIOPEN, но этот режим не нужно использовать без явной необходимости./docs. mdbx.h > Would a libmdbx table be faster to lookup than the simple file offset?
> Would you recommend a better layout of the tables?
MDBX_INTEGERKEY + MDBX_DUPSORT;> I'm using MDBX_NOOVERWRITE to be 200% sure that I don't store a string twice, even though I already know they are unique at this time. Is it slower than MDBX_UPSERT?
> Would MDBX_APPEND speed up the insertion (keys are random-like and inserted in batches)
MDBX_APPEND affect only page splitting during insertion.MDBX_APPEND an each filled page split in the middle, which gives half-filled pages when insertions performed in keys-order.MDBX_APPEND a filled pages splits at the "right" edge, which gives full-filled pages when insertions performed in keys-order.MDBX_APPEND could speedup insertions on keys-order, since 2x-times reduces the number of a pages added to b-tree.MDBX_DUPFIXED, saving you 10 bytes per entry.
mdbx:14986: override_meta: Assertion `(!env->me_txn && !env->me_txn0) || (env->me_stuck_meta == (int)target && (env->me_flags & (MDBX_EXCLUSIVE | MDBX_RDONLY)) == MDBX_EXCLUSIVE)' failed.
v0.13.0
69df6e6a.master.
mdbx:17067: cursor_ops: Assertion `is_filled(mc) && !inner_filled(mc)' failed.
let dir = tempdir().unwrap();
let db = Database::open(&dir).unwrap();
let txn = db.begin_rw_txn().unwrap();
let table = txn
.create_table(None, TableFlags::DUP_SORT | TableFlags::DUP_FIXED)
.unwrap();
for (k, v) in [
(b"key1", b"val1"),
(b"key1", b"val2"),
(b"key1", b"val3"),
(b"key2", b"val1"),
(b"key2", b"val2"),
(b"key2", b"val3"),
] {
txn.put(&table, k, v, WriteFlags::empty()).unwrap();
}
let mut cursor = txn.cursor(&table).unwrap();
assert_eq!(cursor.first().unwrap(), Some((*b"key1", *b"val1")));
assert_eq!(cursor.get_multiple().unwrap(), Some(*b"val1val2val3"));
assert_eq!(cursor.next_multiple::<(), ()>().unwrap(), None);
!).env closing.mdbx_env_close() ?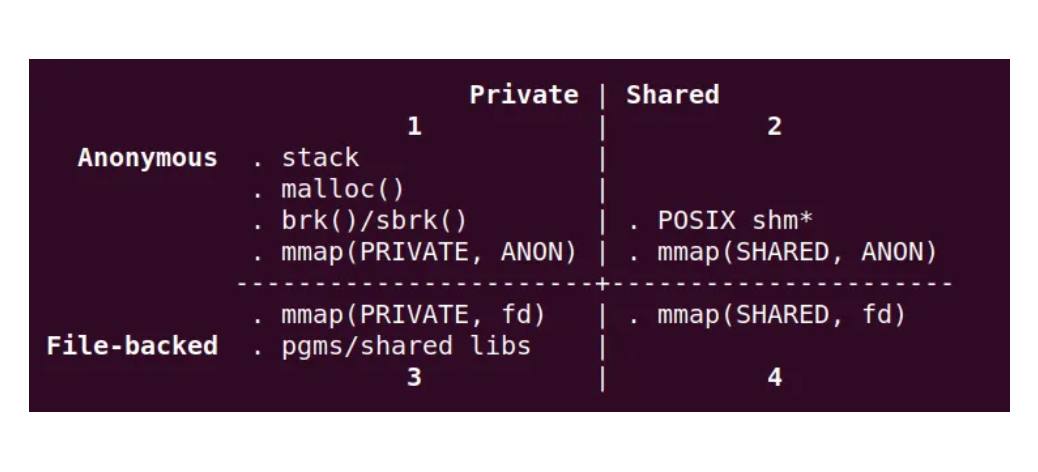
libmdbx.so via dlopen() + dlsym(), and then dlclose(). This will way will release all glibc' objects (maps, allocation, etc).



{kind=link}