libmdbx (2024-09-27 ... 2025-01-16)
Previous messages




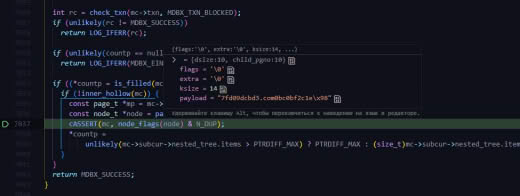
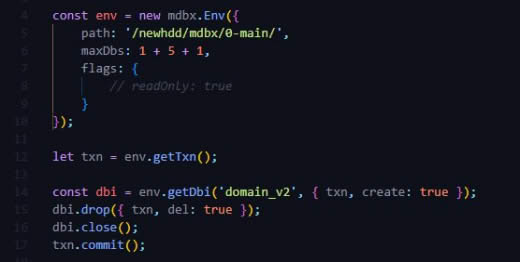
Что-то не догоняю... Почему свободно только 1.5 гб? Максимальный размер бд 2 тб. Занято 1109.32 гб.
Всё, понял... Там для read и write разные...
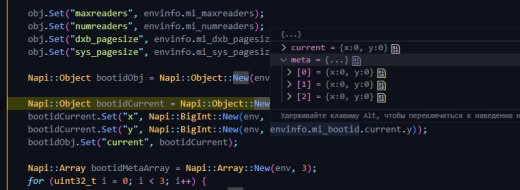


У меня был сервер Амазона где-то. Могу глянуть как там с bootid (какой там тип фса)
Отмена. Он не контейнерный

These seem to be the correct flags





So, no
27 September 2024
КА
21:06
Кемаль Ататюрк
In reply to this message
it reminds me about constantly open http connection (you can name it transaction) when literally it keeps up and connections stays open using sockets and some data traverse bi-directionally, aka web-sockets, it could potentially cause troubles even if it does not use resources, it still uses a lot of cpu cycles and network resources for no reason. one reason - quick response in milliseconds, cause you do not have a constant http hand shake 3-round algorithm once again every time
L
23:45
Louis
Hello!
I'm using MDBX_APPEND on a table that has MDBX_INTEGERKEY flag: it enforces key insertion in little-endian byte order, which corresponds to the doc that says it adheres to the native byte order.
However, when not using the MDBX_INTEGERKEY flag, then I must encode keys in big-endian, otherwise it fails.
Is this on purpose?
I'm using the rust bindings, I can publish a reproduction example to illustrate if needed.
Thank you!
I'm using MDBX_APPEND on a table that has MDBX_INTEGERKEY flag: it enforces key insertion in little-endian byte order, which corresponds to the doc that says it adheres to the native byte order.
However, when not using the MDBX_INTEGERKEY flag, then I must encode keys in big-endian, otherwise it fails.
Is this on purpose?
I'm using the rust bindings, I can publish a reproduction example to illustrate if needed.
Thank you!
28 September 2024
Л(
00:14
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Without
Next, the
So without
MDBX_INTEGERKEY the keys compared as an octet-strings, i.e. by the memcmp().Next, the
MDBX_APPEND requires (and checks) insertions comes with the keys sort/comparison order.So without
MDBX_INTEGERKEY and with MDBX_APPEND insertions must be comes in ascending order for octet-strings, and this will be done if integer-like keys will be big-endian encoded.
👍
L
L
00:25
Louis
I see! Makes sense, thanks!
🤝
Л(
w
07:53
walter
To build for iphone, this patch required:
diff --git a/src/osal.c b/src/osal.c
index d99cd630..71547acd 100644
--- a/src/osal.c
+++ b/src/osal.c
@@ -3512,7 +3512,11 @@ __cold int mdbx_get_sysraminfo(intptr_t *page_size, intptr_t *total_pages,
#if __GLIBC_PREREQ(2, 25) defined(__FreeBSD__) defined(__NetBSD__) || \
defined(__BSD__) defined(__bsdi__) defined(__DragonFly__) || \
defined(__APPLE__) || __has_include(<sys/random.h>)
+#ifdef __IPHONE_OS_VERSION_MIN_REQUIRED
+#include <CommonCrypto/CommonRandom.h>
+#else
#include <sys/random.h>
+#endif
#endif /* sys/random.h */
#if defined(_WIN32) || defined(_WIN64)
diff --git a/src/osal.c b/src/osal.c
index d99cd630..71547acd 100644
--- a/src/osal.c
+++ b/src/osal.c
@@ -3512,7 +3512,11 @@ __cold int mdbx_get_sysraminfo(intptr_t *page_size, intptr_t *total_pages,
#if __GLIBC_PREREQ(2, 25) defined(__FreeBSD__) defined(__NetBSD__) || \
defined(__BSD__) defined(__bsdi__) defined(__DragonFly__) || \
defined(__APPLE__) || __has_include(<sys/random.h>)
+#ifdef __IPHONE_OS_VERSION_MIN_REQUIRED
+#include <CommonCrypto/CommonRandom.h>
+#else
#include <sys/random.h>
+#endif
#endif /* sys/random.h */
#if defined(_WIN32) || defined(_WIN64)
👍
vH
КА
🤝
Л(
КА
07:57
Кемаль Ататюрк
commoncrypto/commonrandom.h actually very uncommon anywhere in the world except apple
Л(
07:58
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Thanks.
I will apply+commit this today.
I will apply+commit this today.
🥰
b
w
30 September 2024
Lazymio invited Lazymio
L
13:54
Lazymio
In reply to this message
Hello, may I ask if the values of
DUPSORT is also limited as key size? I can understand the key and subkey should be limited but why does values also have this limitation?
AA
14:18
Alexey Akhunov
In reply to this message
values are also limited to 512 bytes each. as far as I understand, an implemention without limitations is theoretically possible, but it would be more complex. The limitation is inherited from LMDB, I suspect
L
14:19
Lazymio
In reply to this message
I suspect too. This is a bit annoying and makes
DUPSORT less useful
AA
14:24
Alexey Akhunov
long time ago, I have generated some illustrations showing how dupsort values are stored physically in the pages (that was done for LMDB, but it is true for MDBX as well). Check it out: https://github.com/erigontech/erigon/wiki/LMDB-freelist-illustrated-guide#one-dupsort-table-with-a-large-number-of-values-for-one-of-the-keys
14:25
the picture shows 3 cases: for key with a single duplicate values, with 2 duplicate values, and with 1000 duplicate values
14:26
and note this sentence: "This makes DupSort sub-databases "exempt" from the challenges with the freelists that very long values have (due to overflow pages)"
Л(
14:33
Леонид Юрьев (Leonid Yuriev)
In reply to this message
1. dupsort-values (aka multi-values) stored as a keys in a nested b-tree.
2. MDBX store keys in-place on branch/leaf-pages, i.e. a long keys are not placed on separate pages.
3. see this comment in the code.
2. MDBX store keys in-place on branch/leaf-pages, i.e. a long keys are not placed on separate pages.
3. see this comment in the code.
L
14:34
Lazymio
In reply to this message
Cool, always learned a lot from erigon docs =) Honestly, your dupsort.md in erigon docs is also super helpful. I will have a closer look at the illustrations.
14:35
In reply to this message
That's exactly my question: why not store values elsewhere instead of in leaf nodes (like overflow pages here)? (Reading the docs)
Л(
14:39
Леонид Юрьев (Leonid Yuriev)
In reply to this message
A single-values (i.e. non-dupsort) soread only on a leaf-pages.
But multi-values (aka dupsort values, i.e. the sorted duplicates) stored in a nested b-tree as a keys.
Thus MDBX/MDBX could effective handle a lot-of-millions duplicated/multi-values, which is required for build indices.
But multi-values (aka dupsort values, i.e. the sorted duplicates) stored in a nested b-tree as a keys.
Thus MDBX/MDBX could effective handle a lot-of-millions duplicated/multi-values, which is required for build indices.
L
14:44
Lazymio
In reply to this message
I see. It makes more sense if the intended usage is building indices.
However, (I'm not DB expert so correct me if I'm wrong) why does nested b-tree requires dup values to store as keys? Say, why not the some pointers to larger pages instead of keys?
However, (I'm not DB expert so correct me if I'm wrong) why does nested b-tree requires dup values to store as keys? Say, why not the some pointers to larger pages instead of keys?
14:45
Like the illustrations above, LMDB/MDBX seems to be able to allocate larger pages on demand (?)
П
14:50
Павел
Добрый день! Подскажите, пожалуйста, возможно ли в геомерии задать максимальный размер бд такой, чтоб он автомаически ограничивался лишь физическим размером памяти, т.е. рос до тех пор пока есть место на диске. Сейчас просто подставляю достаточно большое число, но на разных ОС оно разное и приходится иметь логику переоткрытия с меньшими максимальными размерами при получении ошибки по этому поводу.
Л(
14:54
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Я не понимаю что вы спрашиваете. Задавайте размер какой вам требуется. Других вариантов просто не может быть.
СМ
14:59
Сергей Мирянов
я сталкивался примерно с этим при 32х битной сборке - если задать очень большой размер - оно возвращает ошибку. на 64 такого конечно нет (для наших размеров)
но тут мы просто определили максимальный размер для 32 битных версий и его и использовали - что могу посоветовать и Павлу выше
но тут мы просто определили максимальный размер для 32 битных версий и его и использовали - что могу посоветовать и Павлу выше
Л(
15:00
Леонид Юрьев (Leonid Yuriev)
In reply to this message
There are a lot of difficulties with long keys:
- space wasting
- extra memmove/memcpy operation on split/merge/rebalance pages
- extra memcmp for search
- prefix compression should be implemented.
So historically MDBX does not support long keys.
- space wasting
- extra memmove/memcpy operation on split/merge/rebalance pages
- extra memcmp for search
- prefix compression should be implemented.
So historically MDBX does not support long keys.
👍
L
П
15:05
Павел
In reply to this message
На данный момент делаю так:
1) перед окрытием бд вызываю mdbx_env_set_geometry, передавая в size_upper заведомо большое значение (0xFFFFFFFFFFF)
2) пытаюсь открыть бд, выполнив mdbx_env_open
3) проверяю результат. Если он MDBX_TOO_LARGE, то уменьшаю значение максимального размера на порядок, выставляю с ним геомерию и пробую открыть бд еще раз и так по кругу до определенных минимальным значений
Вопрос: Есть ли способ насроить бд так, чтоб максимальное значение автоматически вычислялось/переопределялось по физиеским пределам системы?
1) перед окрытием бд вызываю mdbx_env_set_geometry, передавая в size_upper заведомо большое значение (0xFFFFFFFFFFF)
2) пытаюсь открыть бд, выполнив mdbx_env_open
3) проверяю результат. Если он MDBX_TOO_LARGE, то уменьшаю значение максимального размера на порядок, выставляю с ним геомерию и пробую открыть бд еще раз и так по кругу до определенных минимальным значений
Вопрос: Есть ли способ насроить бд так, чтоб максимальное значение автоматически вычислялось/переопределялось по физиеским пределам системы?
Л(
15:20
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Вы ставите телегу впереди лошади и боретесь с последствиями.
Правильный путь в обратном направлении:
- знать сценарий использования
- понимать какой размер БД нужен для сценария использования
- сформировать требования к системе, включая размер ОЗУ исходя из требуемого размера БД и сценария использования.
На вашем неправильном пути можно дать только пару советов:
- на 32-битных системах реальный максимальный размер БД ограничивается примерно 1 Гб из-за ограничений ОС (правильно сконфигурированный linux позволит использовать до 3 Гб)
- на 64-битных системах вариативность больше, но при размере БД сильно больше ОЗУ могут быть очень большие тормоза из-за больших накладных расходов на поддержку огромных список PTE в ядре ОС.
- можно оттолкнуть от информации получаемой от
Правильный путь в обратном направлении:
- знать сценарий использования
- понимать какой размер БД нужен для сценария использования
- сформировать требования к системе, включая размер ОЗУ исходя из требуемого размера БД и сценария использования.
На вашем неправильном пути можно дать только пару советов:
- на 32-битных системах реальный максимальный размер БД ограничивается примерно 1 Гб из-за ограничений ОС (правильно сконфигурированный linux позволит использовать до 3 Гб)
- на 64-битных системах вариативность больше, но при размере БД сильно больше ОЗУ могут быть очень большие тормоза из-за больших накладных расходов на поддержку огромных список PTE в ядре ОС.
- можно оттолкнуть от информации получаемой от
mdbx_get_sysraminfo().
П
15:29
Павел
In reply to this message
Спасибо за ответ!
В моем случае ожидается постепенный постоянный рост бд. Пару лет спустя размер бд может достигнуть нескольких ТБ.
Но оперативная деятельность с бд идет в оконном режиме, т.е. за определенный период в память может подниматься относительно небольшое количество данных не превышающее размер ОЗУ (редко могут быть обращения за окно.
В моем случае ожидается постепенный постоянный рост бд. Пару лет спустя размер бд может достигнуть нескольких ТБ.
Но оперативная деятельность с бд идет в оконном режиме, т.е. за определенный период в память может подниматься относительно небольшое количество данных не превышающее размер ОЗУ (редко могут быть обращения за окно.
AS
L
AS
18:01
Alex Sharov
In reply to this message
And you want to search values by prefixes (of similar size)? Like: find value by 100kb prefix?
L
18:02
Lazymio
no, the schema is pretty like changeset, I have 80b key, 120b subkey and 0~100kb values
18:02
now I combine the key and subkey together (roughly 200b), dropping
DUPSORT
AS
L
18:04
Lazymio
yeah, yeah, like erigon did, another db for pointer index
18:05
actually I'm indexing logs (as values), and the key and subkey including topics, addresses and some other fields I'm interested
3 October 2024
b
21:29
basiliscos
In reply to this message
да, нет же, просто хотелось бы фишку типа "auto-resize on demand" + возможные политики или хук (типа x2 каждый раз + полная перестройка). Дело в том, что не всегда возможно оценить размеры, иногда это зависит от пользовотельских данных, например от количества файлов - иногда тысячи, а иногда миллиарды, и не хотелось бы эту обязанность по оценке прямо или косвенно делигировать пользователю.
Удобней было бы: "ок, растём в 2 раза", или "растём до такого-то предела", а дальше выдаём ошибку и пользователь сам решает: докупить оперативы или реогранизовать хранилище или ещё что.
Удобней было бы: "ок, растём в 2 раза", или "растём до такого-то предела", а дальше выдаём ошибку и пользователь сам решает: докупить оперативы или реогранизовать хранилище или ещё что.
Л(
21:32
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Вызов callback/hook вместо возврата ошибки при переполнении — принято, это рационально.
👍
EZ
b
4 October 2024
C M invited C M
CM
15:55
C M
anyone knows of any update of MithrilDB ?
6 October 2024
L
14:16
Lazymio
is there any way to replace a key (not value) instead of removing the key and putting the new one?
14:17
or why it is not possible?
L
19:17
Lazymio
Why
https://gitflic.ru/project/erthink/libmdbx/blob?file=src%2Fapi-env.c&branch=master#line-num-659
Does this affect
dont_sync is forced to true here?https://gitflic.ru/project/erthink/libmdbx/blob?file=src%2Fapi-env.c&branch=master#line-num-659
Does this affect
SAFE_NOSYNC ?
Л(
20:04
In reply to this message
If we exclude special cases (when a new key is located in the same position in the sort order, etc.), then replacing a key always requires two operations (deletion and insertion) due to a nature of b-tree.
L
20:05
Lazymio
In reply to this message
Ohhh, you are correct. That makes sense. I forgot the sorting nature of b-tree.
Л(
20:11
Леонид Юрьев (Leonid Yuriev)
In reply to this message
No.
The
1. a env was don't mmaped (when
2. or a env opened read-only (
3. or a env have fatal error ((
4. or a env don't have no a "basal" write-transaction, (i.e. failed to allocate resources, etc).
The
dont_sync = true (i.e. the flag to not-perform sync-to-disk on closing) executed in the following cases:1. a env was don't mmaped (when
env->dxb_mmap.base == nullptr)2. or a env opened read-only (
(env->flags & MDBX_RDONLY) != 0)3. or a env have fatal error ((
(env->flags & ENV_FATAL_ERROR) != 0)4. or a env don't have no a "basal" write-transaction, (i.e. failed to allocate resources, etc).
❤
vH
L
L
20:19
Lazymio
In reply to this message
Ohhhhh, sorry I misunderstood the condition and didn’t notice that the else branch doesn’t have a bracket. Thanks for your patience and detailed explanation.
8 October 2024
Артём Смирнов (студент МФТИ) invited Артём Смирнов (студент МФТИ)
16 October 2024
Всеволод invited Всеволод
KostyaSevastyanov invited KostyaSevastyanov
19 October 2024
A
16:26
Alain
I am looking to build a text search with either an inverted tree or even more likely a Trie. Searching here I found a bit of an answer from a few years ago, about using DUP_SORT for inverted index. I also found a recent reference to Trie that was never built-in and would be a re-write. So just to confirm. inverted index is simple with DUP_SORT and for Trie, no good way to do it with MDBX?
Л(
16:45
Леонид Юрьев (Leonid Yuriev)
In reply to this message
In principle, all this is true, but I am confused by the mention of Trie.
Obviously, it is impossible to build a trie (aka prefix tree) inside a ready-made b-tree implementation, because these are similar, but fundamentally different data structures.
Nonetheless, you can apply a bit of graph theory and store Trie as a set of pairs (parent node -> child node, or vice versa), etc.
Depending on the task/needs/scenario, you can store both nodes directly, links to ones (i.e. node IDs), or combine all this with an admixture of the necessary attributes/features/data.
Obviously, it is impossible to build a trie (aka prefix tree) inside a ready-made b-tree implementation, because these are similar, but fundamentally different data structures.
Nonetheless, you can apply a bit of graph theory and store Trie as a set of pairs (parent node -> child node, or vice versa), etc.
Depending on the task/needs/scenario, you can store both nodes directly, links to ones (i.e. node IDs), or combine all this with an admixture of the necessary attributes/features/data.
vH
17:02
vnvisa.top Hello
In reply to this message
FYI, I am researching this to make inverted index
https://github.com/powturbo/TurboPFor-Integer-Compression/blob/master/lib/idxcr.c
https://github.com/powturbo/TurboPFor-Integer-Compression/blob/master/lib/idxcr.c
20 October 2024
Л(
11:12
Леонид Юрьев (Leonid Yuriev)
In reply to this message
No, this is not safe.
There are only two valid cases with DB on a remove filesystem:
- exclusive mode, i.e. only SINGLE process open/work with a DB on a remove filesystem, no any onthe (i.e. "local") are possible.
- "full" readonly mode, where a several process(es) open/work with a DB on a TRUE READ-ONLY remote filesystem.
The general trouble/issue with a "remote" cases is that a remote process could not aducuate see through it own local address space the updates/writes to DB which performs any other process. Since for a remote processes such updates/writes becomes visible asynchronous and out-of-order because of memory-mapped files nature.
There are only two valid cases with DB on a remove filesystem:
- exclusive mode, i.e. only SINGLE process open/work with a DB on a remove filesystem, no any onthe (i.e. "local") are possible.
- "full" readonly mode, where a several process(es) open/work with a DB on a TRUE READ-ONLY remote filesystem.
The general trouble/issue with a "remote" cases is that a remote process could not aducuate see through it own local address space the updates/writes to DB which performs any other process. Since for a remote processes such updates/writes becomes visible asynchronous and out-of-order because of memory-mapped files nature.
11:14
Thus:
- only single process can write to remote DB, i.e. the MDBX_EXCLUSIVE case.
- no any writes are possible, i.e. the FULL READ-ONLY case.
No options.
- only single process can write to remote DB, i.e. the MDBX_EXCLUSIVE case.
- no any writes are possible, i.e. the FULL READ-ONLY case.
No options.
11:20
In reply to this message
However, this is potentially not safe, as it is possible to violate/bypass checks inside MDBX.
In other words, a reasonable amount of checks is done inside the library, but there is no guarantee that there will not be some way to trick them and open the DB on a remote file system more than once in read-write mode.
+ The main problem here is that there is no simple and reliable way to check whether the database is located on a remote file system. All such checks depend on the system/platform and are quite tedious/time-consuming, etc.
In other words, a reasonable amount of checks is done inside the library, but there is no guarantee that there will not be some way to trick them and open the DB on a remote file system more than once in read-write mode.
+ The main problem here is that there is no simple and reliable way to check whether the database is located on a remote file system. All such checks depend on the system/platform and are quite tedious/time-consuming, etc.
A
12:49
Alain
In reply to this message
Thanks Leonid, I might just use trigram with an inverted index (and here DUPSORT).
🤝
Л(
21 October 2024
kon5t invited kon5t
Л(
18:31
Леонид Юрьев (Leonid Yuriev)
In reply to this message
No!
You should avoid open the same DB twice in a single process.
https://libmdbx.dqdkfa.ru/intro.html#autotoc_md20
You should avoid open the same DB twice in a single process.
https://libmdbx.dqdkfa.ru/intro.html#autotoc_md20
24 October 2024
Л(
22:45
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Рекомендую использовать привязки к Rust от @vorot93.
В reth устаревшая версия mdbx.
В reth устаревшая версия mdbx.
25 October 2024
Л(
07:56
Леонид Юрьев (Leonid Yuriev)
In reply to this message
This is wrong way.
You should use current/actual
Reth break this rules since uses obsolete release with a set of bugs which were fixed (see the Changelog).
Please don't do that.
You should use current/actual
master branch for any development, the last release for staging/testing (and then for production), and later a stable branch when the hive of used release get out to stable phase (i.e. got rid of any feature development but bugfix only).Reth break this rules since uses obsolete release with a set of bugs which were fixed (see the Changelog).
Please don't do that.
08:03
In reply to this message
The database format is frozen, i..e .the DXB-file, but not the LCK-file (which recreates/overwrite each time by the first process opens a DB).
Anyway such a total-break compatibility changes will be noted in the Changelog if this even happens.
Anyway such a total-break compatibility changes will be noted in the Changelog if this even happens.
👍
L
27 October 2024
Л(
13:15
Леонид Юрьев (Leonid Yuriev)
libmdbx 0.12.12 (Доллежаль)
Поддерживающий выпуск с исправлением обнаруженных ошибок и устранением недочетов, в память о советском ученом-энергетике Николае Антоновиче Доллежаль в день 125-летия со дня его рождения.
Это последний выпуск куста стабильных версий 0.12.x, спустя более двух лет после выпуска 0.12.1. Последующие выпуски 0.12.x будут формироваться только в случае существенных проблем/ошибок, вероятность чего близка к нулю. Для всех проектов находящихся в стадии активной разработки рекомендуется использовать ветку master.
https://gitflic.ru/project/erthink/libmdbx/release/1d9b4f5d-1f59-4d92-bcf7-a23b5d3688ab
Поддерживающий выпуск с исправлением обнаруженных ошибок и устранением недочетов, в память о советском ученом-энергетике Николае Антоновиче Доллежаль в день 125-летия со дня его рождения.
Это последний выпуск куста стабильных версий 0.12.x, спустя более двух лет после выпуска 0.12.1. Последующие выпуски 0.12.x будут формироваться только в случае существенных проблем/ошибок, вероятность чего близка к нулю. Для всех проектов находящихся в стадии активной разработки рекомендуется использовать ветку master.
git diff' stat: 6 commits, 5 files changed, 239 insertions(+), 6 deletions(-)https://gitflic.ru/project/erthink/libmdbx/release/1d9b4f5d-1f59-4d92-bcf7-a23b5d3688ab
🔥
A
AS
СМ
4
30 October 2024
5FIDDY invited 5FIDDY
2 November 2024
L
10:04
Lazymio
Are the values of DUP_SORT table sorted? The question seems weird but I observed my values not being sorted.
Л(
L
10:12
Lazymio
In reply to this message
Thanks for the confirmation. I'm running
mdbx_dump to double-check. I observed that the values inserted afterwhile are not sorted when traversing with MDBX_NEXT_DUP. For instance, I inserted 1, 2, 4, 3 and iterating gives exactly 1, 2, 4, 3 but not 1, 2, 3, 4. The key is the same of course.
10:20
In reply to this message
Thanks (again) for quick answering. I found it is due to my key design issue. It is indeed sorted.
3 November 2024
damar invited damar
d
21:17
damar
sorry for the oot, I wanted to know what you guys think about this database and their claims are real?
https://github.com/crossdb-org/crossdb
https://github.com/crossdb-org/crossdb
VS
d
21:35
damar
In reply to this message
no, I just searched for a nonsql database (kv) on github found it, for now I just use LMDB in node.js
КА
d
21:45
damar
In reply to this message
because I only want to use a nosql database for social media bot.
5
21:47
5FIDDY
In reply to this message
mongo, redis, a map/dict/hash{map,set}, loads of options brother
21:49
libmdbx official is only C afaik
d
21:50
damar
In reply to this message
for mongo, redis or other platforms that require installation before use it's not worth it in my case, I just need a ready db when the script is run.
5
21:50
5FIDDY
do you need persistence?
d
5
21:55
5FIDDY
mongo offer a free like 500mb online service no install iirc - if you cant install a db idk many other ways besides saas services to achieve persistence
d
5
d
22:11
damar
In reply to this message
Do you have any other alternative for nonsql databases besides mdb/mdbx? I'm still looking for others that support ACID.
5
22:14
5FIDDY
theres lmdb but idk others besides the ones i mentioned off the top of my head - badger, rocksdb, pebble, tigerbeatle (might be sql idk), p sure those are all acid afaik
22:15
pebble is fastest outside of tigerbeetle afaik (i think that may be sql tho) pebble is good to use
4 November 2024
КА
00:36
Кемаль Ататюрк
In reply to this message
there are no alternatives to mongo, imho. probably considering setup on a vpc with docker + portainer
vH
КА
09:36
Кемаль Ататюрк
In reply to this message
ACID quite hard to implement, imho, keeping in mind CAP theorem. sometimes that worth checking out, sometimes not
d
5 November 2024
КА
08:52
Кемаль Ататюрк
In reply to this message
Thats because Ukrainian terrorists make some comments violating code of conduct or EULA or community rules
8 November 2024
Л(
22:54
Леонид Юрьев (Leonid Yuriev)
В libmdbx удалось устранить/поправить давнюю (но крайне редко проявляющуюся) проблему возврата ошибки
Подробности в комментарии коммита https://gitflic.ru/project/erthink/libmdbx/commit/6c56ed97bbd8ca46abac61886a113ba31e5f1291
Тестирование требует потребует еще минимум недели, а то и двух.
Если недочетов выявлено не будет, то во второй половину будет выпуск libmdbx 0.13.2 и в конце года ветка 0.13.x получит статус стабильной (а 0.12.x отправится в архив).
MDBX_PROBLEM при фиксации транзакций.Подробности в комментарии коммита https://gitflic.ru/project/erthink/libmdbx/commit/6c56ed97bbd8ca46abac61886a113ba31e5f1291
Тестирование требует потребует еще минимум недели, а то и двух.
Если недочетов выявлено не будет, то во второй половину будет выпуск libmdbx 0.13.2 и в конце года ветка 0.13.x получит статус стабильной (а 0.12.x отправится в архив).
👍
w
N
VS
9 November 2024
A
15:25
Alain
A few months ago I made an Infinispan store using MDBX and that has been working fine, but we've noticed that on startup of our application we sometime get an MDBX exception. Our service restarts and finally gets through, but this can cause long startup time and its not correct.
The error is: mdbxjni.Env - Function:mdbx_cursor_close, line:18984, msg:assert: check_txn(txn, 0) == MDBX_SUCCESS
Here is the mdbx_close, where I've underlined the origin:
```
void mdbx_cursor_close(MDBX_cursor *mc) {
if (likely(mc)) {
if (unlikely(mc->mc_signature != MDBX_MC_READY4CLOSE &&
mc->mc_signature != MDBX_MC_LIVE)) {
DEBUG("closing cursor with signature [%d]", mc->mc_signature);
}
ENSURE(NULL, mc->mc_signature == MDBX_MC_LIVE ||
mc->mc_signature == MDBX_MC_READY4CLOSE);
MDBX_txn *const txn = mc->mc_txn;
if (!mc->mc_backup) {
mc->mc_txn = NULL;
/* Unlink from txn, if tracked. */
if (mc->mc_flags & C_UNTRACK) {
ENSURE(txn->mt_env, check_txn(txn, 0) == MDBX_SUCCESS);
MDBX_cursor **prev = &txn->mt_cursors[mc->mc_dbi];
while (*prev && *prev != mc)
prev = &(*prev)->mc_next;
tASSERT(txn, *prev == mc);
*prev = mc->mc_next;
}
mc->mc_signature = 0;
mc->mc_next = mc;
osal_free(mc);
} else {
/* Cursor closed before nested txn ends */
tASSERT(txn, mc->mc_signature == MDBX_MC_LIVE);
ENSURE(txn->mt_env, check_txn_rw(txn, 0) == MDBX_SUCCESS);
mc->mc_signature = MDBX_MC_WAIT4EOT;
}
}
}
```
My question is what can be causing this. The Infinispan framework is using flowables and I suspect that we get a request to close at a time that nothing should be closable yet. So would appreciate insight into the error that might help me avoid it.
Thanks
The error is: mdbxjni.Env - Function:mdbx_cursor_close, line:18984, msg:assert: check_txn(txn, 0) == MDBX_SUCCESS
Here is the mdbx_close, where I've underlined the origin:
```
void mdbx_cursor_close(MDBX_cursor *mc) {
if (likely(mc)) {
if (unlikely(mc->mc_signature != MDBX_MC_READY4CLOSE &&
mc->mc_signature != MDBX_MC_LIVE)) {
DEBUG("closing cursor with signature [%d]", mc->mc_signature);
}
ENSURE(NULL, mc->mc_signature == MDBX_MC_LIVE ||
mc->mc_signature == MDBX_MC_READY4CLOSE);
MDBX_txn *const txn = mc->mc_txn;
if (!mc->mc_backup) {
mc->mc_txn = NULL;
/* Unlink from txn, if tracked. */
if (mc->mc_flags & C_UNTRACK) {
ENSURE(txn->mt_env, check_txn(txn, 0) == MDBX_SUCCESS);
MDBX_cursor **prev = &txn->mt_cursors[mc->mc_dbi];
while (*prev && *prev != mc)
prev = &(*prev)->mc_next;
tASSERT(txn, *prev == mc);
*prev = mc->mc_next;
}
mc->mc_signature = 0;
mc->mc_next = mc;
osal_free(mc);
} else {
/* Cursor closed before nested txn ends */
tASSERT(txn, mc->mc_signature == MDBX_MC_LIVE);
ENSURE(txn->mt_env, check_txn_rw(txn, 0) == MDBX_SUCCESS);
mc->mc_signature = MDBX_MC_WAIT4EOT;
}
}
}
```
My question is what can be causing this. The Infinispan framework is using flowables and I suspect that we get a request to close at a time that nothing should be closable yet. So would appreciate insight into the error that might help me avoid it.
Thanks
10 November 2024
Л(
00:01
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Thank for reporting, I will check/dig this.
Alexander R invited Alexander R
Л(
02:30
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Hm, no idea for now (
I had a suspicion of some kind of recently introduced bug/regression.
So I added a small/trivial test (available in the
--
In short, when closing a cursor, there are two possible cases: either a cursor closes before a transaction is finished, or after.
In first case, when cursor closed before transaction, then shown code fragment checks a transaction object and then detach the given cursor from the linked list within a transaction.
In second case, when transaction terminated while cursor(s) are still live, it unlink all opened/not-closed cursor(s) and clean the C_UNTRACT state-flag each of ones. So later, during closing a cursor, the shown code will bypassed at
In your case a transaction was not terminated and/or at least a cursor(s) still linked within it, but the transaction instance is not valid. Seems like a bug related to handling of cursors linked list, etc.
Please check your case with the current
It is likely someone related bug was fixed.
I had a suspicion of some kind of recently introduced bug/regression.
So I added a small/trivial test (available in the
devel branch), but it just works (on the devel and stable branches both).--
In short, when closing a cursor, there are two possible cases: either a cursor closes before a transaction is finished, or after.
In first case, when cursor closed before transaction, then shown code fragment checks a transaction object and then detach the given cursor from the linked list within a transaction.
In second case, when transaction terminated while cursor(s) are still live, it unlink all opened/not-closed cursor(s) and clean the C_UNTRACT state-flag each of ones. So later, during closing a cursor, the shown code will bypassed at
if (mc->mc_flags & C_UNTRACK).In your case a transaction was not terminated and/or at least a cursor(s) still linked within it, but the transaction instance is not valid. Seems like a bug related to handling of cursors linked list, etc.
Please check your case with the current
stable and/or the master branches.It is likely someone related bug was fixed.
zztopd Zachetnov D. Iv. invited zztopd Zachetnov D. Iv.
A
14:08
Alain
Ok, I will try to add some checks.Like I said this is in a new usage and it happens only (AFAICT) on certain conditions early in the startup stage, almost feels like trying to close something that wasn't fully opened. Also it has been observed in only 2 environments, where the number of such store is larger that the norm. Will keep you posted of what I'm finding
🤝
Л(
vH
15:59
vnvisa.top Hello
What are the required steps to use multiple read_only transactions?
If I make multiple
If I call
If I make multiple
txn_begin calls with parent always NULL, it returned MDBX_BAD_RSLOT: Invalid reuse of reader locktable slot, e.g. read-transaction already run for current threadIf I call
txn_begin with parent is the last successful txn, it returned MDBX_BAD_TXN: Transaction is not valid for requested operation, e.g. had errored and be must aborted, has a child, or is invalid
A
16:04
Alain
In reply to this message
If you look here https://libmdbx.dqdkfa.ru/usage.html#autotoc_md47 it clearly states: "Do not start more than one transaction for a one thread. If you think about this, it's really strange to do something with two data snapshots at once, which may be different. MDBX checks and preventing this by returning corresponding error code (MDBX_TXN_OVERLAPPING, MDBX_BAD_RSLOT, MDBX_BUSY) unless you using MDBX_NOSTICKYTHREADS option on the environment. Nonetheless, with the MDBX_NOSTICKYTHREADS option, you must know exactly what you are doing, otherwise you will get deadlocks or reading an alien data."
👍
vH
Л(
Л(
16:04
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Are you using MDBX_NOSTICKYTHREADS (>= v0.13) or MDBX_NOTLS (< 0.13)?
16:14
In reply to this message
Just in case — are you sure that you don't have a competition/collision between cursor(s) closing and transaction(s) completion in different threads ?
A
16:15
Alain
Sure? Absolutely not and that could in theory very well be the type of issue that I'm facing here.
vH
16:17
vnvisa.top Hello
In reply to this message
I neither use these. Just think it's normal to read_only, becase RO cannot break data.
And maybe MDBX_NOSTICKYTHREADS should be uniqly used for WR txn, doesn't it?
And maybe MDBX_NOSTICKYTHREADS should be uniqly used for WR txn, doesn't it?
Л(
16:20
Леонид Юрьев (Leonid Yuriev)
In reply to this message
A read-only txn(s) needs "locking" of used MVCC-snapshot(s).
So the whole picture is much complex.
So the whole picture is much complex.
16:27
In reply to this message
MDBX_NOTLS is for read-only txns.
MDBX_NOSTICKYTHREADS works like MDBX_NOTLS for read-only txn, but for write-txn disable checking the transaction thread owner.
Please use google-translate (or a similar tool) for the URLs which I given above.
MDBX_NOSTICKYTHREADS works like MDBX_NOTLS for read-only txn, but for write-txn disable checking the transaction thread owner.
Please use google-translate (or a similar tool) for the URLs which I given above.
🆒
vH
13 November 2024
Л(
21:32
Леонид Юрьев (Leonid Yuriev)
Нужна ли поддержка Conan ?
На всякий уточню, что размещение libmdbx в основном Conan-центре не возможно, так как он находится на Github (навечно в черном списке).
На всякий уточню, что размещение libmdbx в основном Conan-центре не возможно, так как он находится на Github (навечно в черном списке).
VS
21:37
Victor Smirnov
И VCpkg, если можно. Последний — децентрализованный. Складывать всё в центральный репозитарий не нужно.
Л(
b
15 November 2024
A
18:06
Alain
In reply to this message
Finally hit the breakpoint, almost taught I had an Heisenberg here. It is a thread issue:
here we see a valid pair of logs followed by the offending one (the other is not shown as after the breakpoint, The one difference with all the others is the thread (non-blocking-thread--p2-t12) being used. Will have to look deeper into this and maybe check with the Infinispan folks about this.
Thanks for your help here, greatly appreciated.
09:42:45.371 [blocking-thread--p3-t2] ::: TRACE o.i.persistence.mdbx.MdbxDbStore - Closing cursor Cursor[Id:1570174338, db:Database [id=21, name=datasegmentdb_19], txn:Transaction [ThreadId=259, Id=836]
09:42:45.371 [blocking-thread--p3-t2] ::: TRACE o.i.persistence.mdbx.MdbxDbStore - Closing transaction Transaction [ThreadId=259, Id=836]
09:42:45.389 [non-blocking-thread--p2-t12] ::: TRACE o.i.persistence.mdbx.MdbxDbStore - Closing cursor Cursor[Id:1324656279, db:Database [id=22, name=datasegmentdb_20], txn:Transaction [ThreadId=259, Id=836]
here we see a valid pair of logs followed by the offending one (the other is not shown as after the breakpoint, The one difference with all the others is the thread (non-blocking-thread--p2-t12) being used. Will have to look deeper into this and maybe check with the Infinispan folks about this.
Thanks for your help here, greatly appreciated.
🤝
Л(
17 November 2024
Ivan invited Ivan
25 November 2024
b
21:22
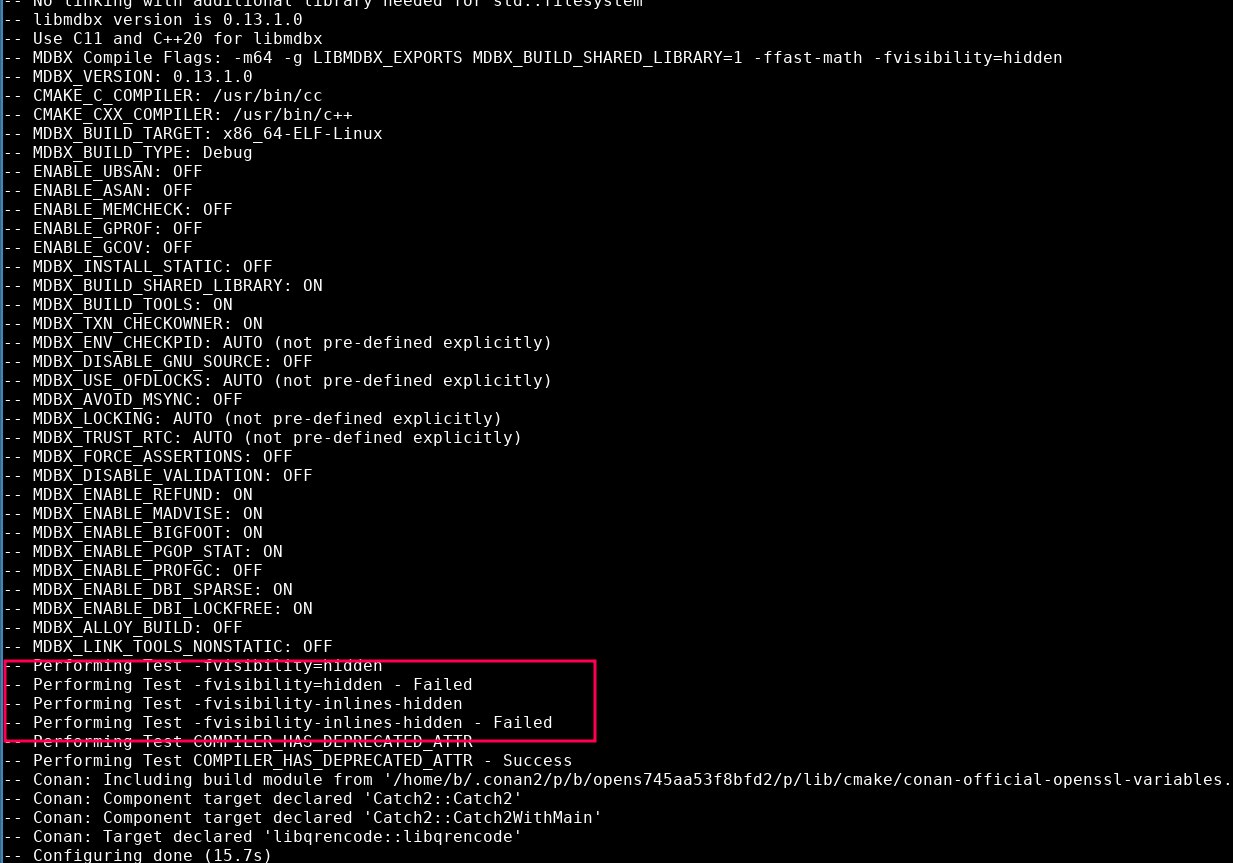
basiliscos
21:23
не подскажете, из-за чего такое может быть? Использую связку conan + cmake, mdbx через FetchContent пробую подключить
Л(
21:25
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Надо в логи CMake при сборке смотреть, иначе никак.
b
21:34
зачем-то
-D пробрасывается.
Л(
21:43
Леонид Юрьев (Leonid Yuriev)
Скорее всего у вас логические ошибки в CMake-скриптах.
b
21:57
basiliscos
если я как
add_subdirectory подключаю, то всё ок. Пока там оставлю.
26 November 2024
Л(
09:38
Леонид Юрьев (Leonid Yuriev)
In reply to this message
запуская
cmake —trace --trace-expand вы точно сможете найти причину появления -D.
b
10:15
basiliscos
In reply to this message
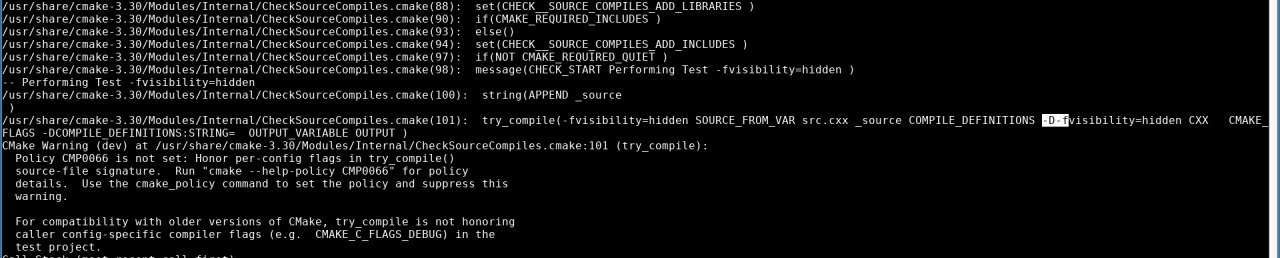
Спасибо. Вот отсюда приезжает: https://github.com/Kitware/CMake/blob/master/Modules/Internal/CheckSourceCompiles.cmake#L110 , если что cmake у меня версии 3.30.1
10:16
а вот кусочек как эспандится
Л(
10:20
Леонид Юрьев (Leonid Yuriev)
In reply to this message
У вас где-то выше по стеку CMAKE_REQUIRED_DEFINITIONS вместо CMAKE_REQUIRED_FLAGS. Скорее всего в пробнике/проверке проверяющей
-fvisibility.
10:24
Вероятно вместо
check_c_compiler_flag() для проверки -fvisibility ошибочно используется что-то другое.
28 November 2024
professional fish invited professional fish
Л(
11:39
Леонид Юрьев (Leonid Yuriev)
A
Л(
20:14
Леонид Юрьев (Leonid Yuriev)
Ветка
Просьба попробовать.
Если не будет сообщений о недочетах, то в течение нескольких дней будет выпуск.
master на Gitflic готова для выпуска версии 0.13.2.Просьба попробовать.
Если не будет сообщений о недочетах, то в течение нескольких дней будет выпуск.
👍
w
YS
1 December 2024
R invited R
3 December 2024
Л(
09:33
Леонид Юрьев (Leonid Yuriev)
Добавлена поддержка Conan.
Создание пакета сейчас требует GNU Make, так как экспорт исходных текстов в Conan выполняется посредство амальгамирования (
Поэтому
Создание пакета сейчас требует GNU Make, так как экспорт исходных текстов в Conan выполняется посредство амальгамирования (
make dist).Поэтому
conan create пока не работает в Windows, но последующая сборка при использовании пакета конечно работает.
b
10:15
basiliscos
крутяк. А дока есть, как подключить?
Л(
10:25
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Ну это достаточно очевидно, необходимо уметь пользоваться самим conan.
Если без Conan-сервера (с использованием только локального кеша):
- в каталоге с libmdbx выполняете
Если с Conan-серверо:
- в каталоге с libmdbx выполняете
А в целевых/зависимых проектах подключаете libmdbx согласно доке conan.
Если без Conan-сервера (с использованием только локального кеша):
- в каталоге с libmdbx выполняете
conan create .Если с Conan-серверо:
- в каталоге с libmdbx выполняете
conan create ., затем conan upload -r SERVER 'libmdbx/*'А в целевых/зависимых проектах подключаете libmdbx согласно доке conan.
👍
b
b
10:27
basiliscos
я тогда когда релизнется, залью рецепт на конан центер, если не против?
Л(
10:36
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Залить рецепт не проблема, но его потом надо поддерживать.
Т.е. анализировать сообщения/жалобы пользователей, разбираться с ними, обновлять и т.п.
Кроме этого, конан-центр находится на github, а гитхаб уже удалял/блокировал всё и поэтому в черном списке.
Поэтому рецепт на конан-центре никогда не сможет быть поддерживаемым мной, иметь статус "официального" (если так можно сказать).
Т.е. анализировать сообщения/жалобы пользователей, разбираться с ними, обновлять и т.п.
Кроме этого, конан-центр находится на github, а гитхаб уже удалял/блокировал всё и поэтому в черном списке.
Поэтому рецепт на конан-центре никогда не сможет быть поддерживаемым мной, иметь статус "официального" (если так можно сказать).
b
10:39
basiliscos
да, я понял. У меня есть рецепт там уже своей либы, ваш залью со своего аккаунта, неофициальный. По идее ничего сложного. (Хотя проблема с visibility=hidden выше, как раз, возможно, на стыке с конаном пролазит).
Л(
10:40
Леонид Юрьев (Leonid Yuriev)
In reply to this message
С visibility проблема где-то в ваших скриптах, скорее всего.
6 December 2024
Л(
16:47
Леонид Юрьев (Leonid Yuriev)
Для спонсорства/донатов создан Ethereum счет
Все прочие счета давно закрыты и/или не контролируются мной.
Приём средств приостанавливался из-за ухода криптобирж, не-очевидностью путей обналичивания "крипты", декларирования доходов и уплаты налогов.
В текущем понимании, сейчас с этим проблем нет.
0xD104d8f8B2dC312aaD74899F83EBf3EEBDC1EA3A.Все прочие счета давно закрыты и/или не контролируются мной.
Приём средств приостанавливался из-за ухода криптобирж, не-очевидностью путей обналичивания "крипты", декларирования доходов и уплаты налогов.
В текущем понимании, сейчас с этим проблем нет.
7 December 2024
АК
18:26
Алексей (Keller) Костюк 😐
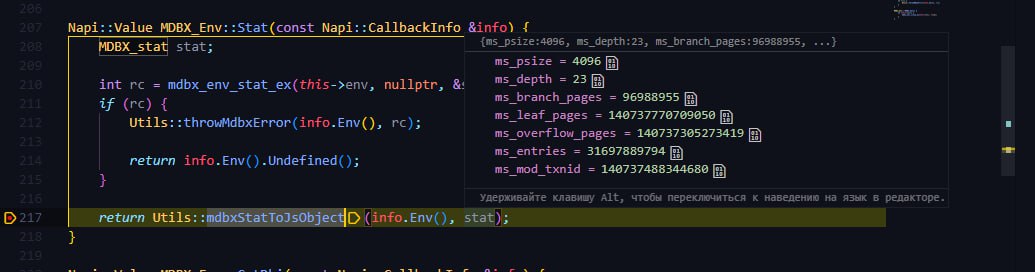
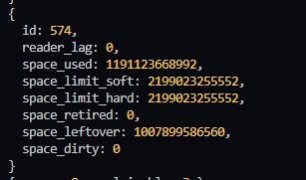
Здравствуйте. Есть небольшой вопрос. Почему такие большие значения для env stat выдаёт? По идее же должно выдавать значения "корневой" бд, как и в LMDB... Но тут больше случайные как-будто
18:28
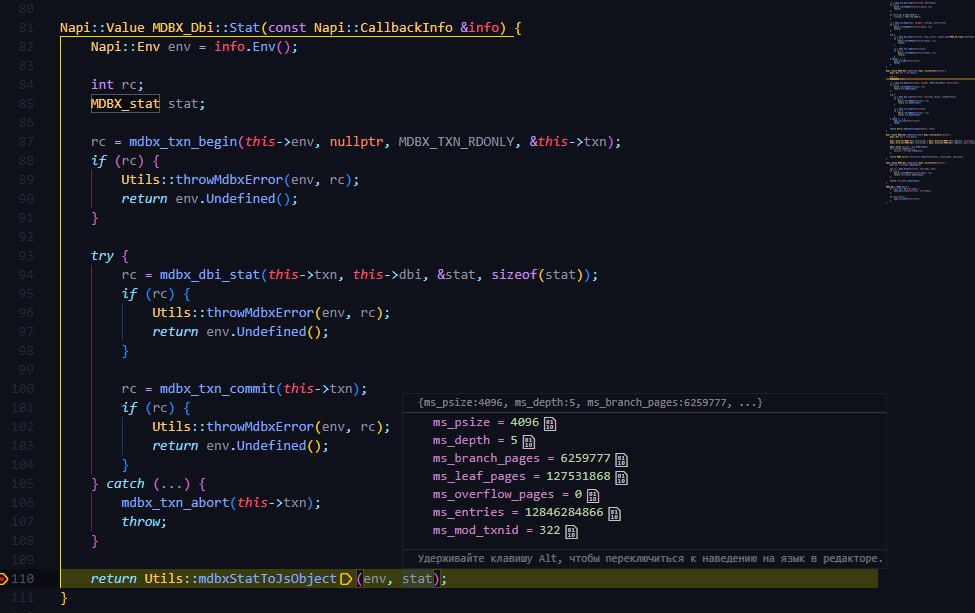
У dbi с этим всё ок
Л(
18:38
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Хм, похоже на регресс, который я уже исправлял. Как-будто коммит потерялся (
Сейчас посмотрю...
Сейчас посмотрю...
АК
18:40
mdbx_stat version 0.13.1.0
- source: v0.13.1-0-g5fc7a6b1 2024-08-30T00:01:07+03:00, commit 5fc7a6b1077794789b97bb2a56f5a4eb541a0bc0, tree 4ad05c5f867a963162def46b68eff5f7130b81ca
- anchor: 4ef6bfc2012bedf4af0bcd644ec87ace207f395c5d5e103573649032ec2cb6e8_v0_13_1_0_g5fc7a6b1
- build: 2024-12-07T18:39:55+0300 for x86_64-linux-gnu by cc (Debian 12.2.0-14) 12.2.0
- flags: MDBX_BUILD_CXX=YES -DNDEBUG=1 -std=gnu++23 -O2 -g -Wall -Werror -Wextra -Wpedantic -ffunction-sections -fPIC -fvisibility=hidden -pthread -Wno-error=attributes -fno-semantic-interposition -Wno-unused-command-line-argument -Wno-tautological-compare -Wl,--gc-sections,-z,relro,-O1 -Wl,--allow-multiple-definition -lstdc++fs -lm -lrt
- options: MDBX_DEBUG=0 MDBX_WORDBITS=64 BYTE_ORDER=LITTLE_ENDIAN MDBX_ENABLE_BIGFOOT=1 MDBX_ENV_CHECKPID=AUTO=0 MDBX_TXN_CHECKOWNER=AUTO=1 MDBX_64BIT_ATOMIC=AUTO=1 MDBX_64BIT_CAS=AUTO=1 MDBX_TRUST_RTC=AUTO=0 MDBX_AVOID_MSYNC=0 MDBX_ENABLE_REFUND=1 MDBX_ENABLE_MADVISE=1 MDBX_ENABLE_MINCORE=1 MDBX_ENABLE_PGOP_STAT=1 MDBX_ENABLE_PROFGC=0 _GNU_SOURCE=YES MDBX_LOCKING=AUTO=2008 MDBX_USE_OFDLOCKS=AUTO=1 MDBX_CACHELINE_SIZE=64 MDBX_CPU_WRITEBACK_INCOHERENT=0 MDBX_MMAP_INCOHERENT_CPU_CACHE=0 MDBX_MMAP_INCOHERENT_FILE_WRITE=0 MDBX_UNALIGNED_OK=8 MDBX_PNL_ASCENDING=0
Л(
18:54
Леонид Юрьев (Leonid Yuriev)
In reply to this message
При рефакторинге потерялся очищающий
Буду выяснять как у меня так получилось.
Поправил в ветке
memset().Буду выяснять как у меня так получилось.
Поправил в ветке
devel, чуть позже пролью в master.
9 December 2024
Алексей Пряников invited Алексей Пряников
10 December 2024
Л(
11:25
Леонид Юрьев (Leonid Yuriev)
libmdbx 0.13.2 will be released this week, most likely tomorrow.
🔥
w
AS
3
👍
SD
2
11 December 2024
Aleksandr Druzhinin invited Aleksandr Druzhinin
Л(
19:17
Леонид Юрьев (Leonid Yuriev)
Упс, с выпуском 0.13.2 техническая ошибка. Через 1-2 часа...
❤
SD
SD
21:21
Sayan J. Das
Hi from India. Is there any way to compile libMDBX without
Thanks.
evex512 optimizations? I can't seem to be able to find any build flag for this. This is really needed as a lot of my users don't have avx512 CPUs.Thanks.
Л(
21:28
Леонид Юрьев (Leonid Yuriev)
In reply to this message
You shouldn't have to worry about that.
Functions with AVX512 / AVX2 / AVX instructions will be used only if the such instructions are supported by the specific processor.
Functions with AVX512 / AVX2 / AVX instructions will be used only if the such instructions are supported by the specific processor.
👍
ЮС
SD
21:31
Sayan J. Das
In reply to this message
Basically I'm writing a Zig binding library to libmdbx (https://github.com/theseyan/lmdbx-zig), so the amalgamated sources are compiled using
I'm fairly sure I'm doing something wrong as trying to compile for a target without
build.zig (this has the advantage of easy cross-compilation).I'm fairly sure I'm doing something wrong as trying to compile for a target without
exev512 support results in a cascade of errors, such as the attached screenshot
21:32
any C definition/macro I should pass from zig to make the feature detection work properly in mdbx?
21:35
(this works perfect if I do build including
evex512 target, but then it doesn't work on any older x86_64 cpu)
21:38
> "-std=gnu11",
"-O2",
"-g",
"-Wall",
"-ffunction-sections",
"-fvisibility=hidden",
"-pthread",
"-Wno-error=attributes",
"-fno-semantic-interposition",
"-Wno-unused-command-line-argument",
"-Wno-tautological-compare",
"-DMDBX_BUILD_FLAGS=\"DNDEBUG=1\"",
"-ULIBMDBX_EXPORTS",
these are the flags passed by Zig (clang)
"-O2",
"-g",
"-Wall",
"-ffunction-sections",
"-fvisibility=hidden",
"-pthread",
"-Wno-error=attributes",
"-fno-semantic-interposition",
"-Wno-unused-command-line-argument",
"-Wno-tautological-compare",
"-DMDBX_BUILD_FLAGS=\"DNDEBUG=1\"",
"-ULIBMDBX_EXPORTS",
these are the flags passed by Zig (clang)
Л(
21:38
Леонид Юрьев (Leonid Yuriev)
In reply to this message
This is a zig toolchain bug, sure.
You could try to build libmdbx with definition
However, I am not sure that this will help, because the compiler may actually not support more other features that it reports as supported.
You could try to build libmdbx with definition
MDBX_HAVE_BUILTIN_CPU_SUPPORTS=0.However, I am not sure that this will help, because the compiler may actually not support more other features that it reports as supported.
SD
21:59
Sayan J. Das
In reply to this message
Using
Also, it seems that on Apple/Bionic devices, optimizations are disabled. I can add that behaviour to
MDBX_HAVE_BUILTIN_CPU_SUPPORTS=0, the build seems to work! But drawback seems that on x86/x64 the optimizations will be disabled. If I compile with evex512 in build.zig with this flag, will AVX512 optimizations work on a supported device?Also, it seems that on Apple/Bionic devices, optimizations are disabled. I can add that behaviour to
build.zig
SD
22:19
Sayan J. Das
You are right, this is a zig compiler regression (https://github.com/ziglang/zig/issues/20414)
АК
22:26
Алексей (Keller) Костюк 😐
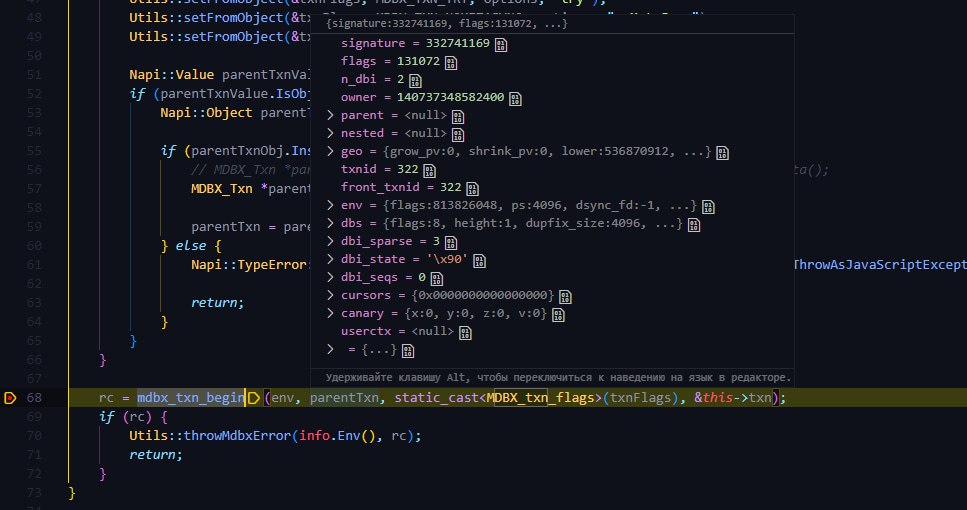
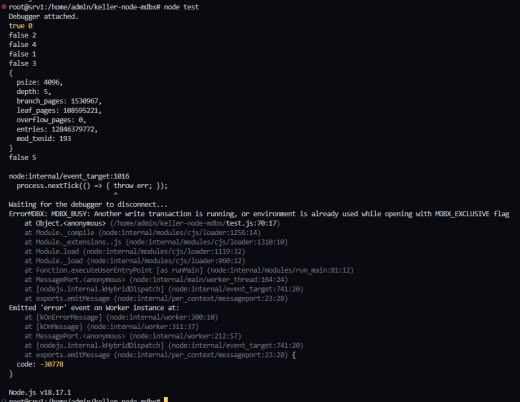
@erthink Леонид здравствуйте. Пытаюсь реализовать вложенные транзакции, но получаю:
MDBX_BAD_TXN: Transaction is not valid for requested operation, e.g. had errored and be must aborted, has a child, or is invalid
Не подскажите, в чём может быть проблема?
MDBX_BAD_TXN: Transaction is not valid for requested operation, e.g. had errored and be must aborted, has a child, or is invalid
Не подскажите, в чём может быть проблема?
MDBX_Txn::MDBX_Txn(const Napi::CallbackInfo &info) : Napi::ObjectWrap<MDBX_Txn>(info) {
unsigned int envFlags;
unsigned int txnFlags = MDBX_TXN_READWRITE;
int rc;
MDBX_txn *parentTxn = nullptr;
MDBX_env *env = info[0].As<Napi::External<MDBX_env>>().Data();
// MDBX_Txn parentTxn = info[1].As<Napi::External<MDBX_Txn>>().Data();
rc = mdbx_env_get_flags(env, &envFlags);
if (rc) {
Utils::throwMdbxError(info.Env(), rc);
return;
}
if (envFlags & MDBX_RDONLY) {
txnFlags = MDBX_TXN_RDONLY;
}
if (info[1].IsObject()) {
Napi::Object options = info[1].ToObject();
Utils::setFromObject(&txnFlags, MDBX_TXN_RDONLY, options, "readOnly");
Utils::setFromObject(&txnFlags, MDBX_TXN_RDONLY_PREPARE, options, "prepare");
Utils::setFromObject(&txnFlags, MDBX_TXN_TRY, options, "try");
Utils::setFromObject(&txnFlags, MDBX_TXN_NOMETASYNC, options, "noMetaSync");
Utils::setFromObject(&txnFlags, MDBX_TXN_NOSYNC, options, "noSync");
Napi::Value parentTxnValue = options.Get("parentTxn");
if (parentTxnValue.IsObject()) {
Napi::Object parentTxnObj = parentTxnValue.ToObject();
if (parentTxnObj.InstanceOf(MDBX_Txn::constructor.Value())) {
// MDBX_Txn *parentTxnClass = parentTxnValue.As<Napi::External<MDBX_Txn>>().Data();
MDBX_Txn *parentTxnClass = Napi::ObjectWrap<MDBX_Txn>::Unwrap(parentTxnObj);
parentTxn = parentTxnClass->txn;
} else {
Napi::TypeError::New(info.Env(), "Invalid parentTxn: not an instance of Txn").ThrowAsJavaScriptException();
return;
}
}
}
rc = mdbx_txn_begin(env, parentTxn, static_cast<MDBX_txn_flags>(txnFlags), &this->txn);
if (rc) {
Utils::throwMdbxError(info.Env(), rc);
return;
}
}const txn1 = env.getTxn();
const txn2 = env.getTxn({
parentTxn: txn1
});
console.log(txn2.info())
txn1.abort();
Л(
22:29
Леонид Юрьев (Leonid Yuriev)
In reply to this message
На вскидку — вложенные транзакции только пишущие, read-only вложенными быть не могут.
АК
22:29
Алексей (Keller) Костюк 😐
In reply to this message
Ааа... Не знал... Спасибо
А как тогда несколько открыть для чтения?
Получаю:
MDBX_BAD_RSLOT: Invalid reuse of reader locktable slot, e.g. read-transaction already run for current thread
А как тогда несколько открыть для чтения?
Получаю:
MDBX_BAD_RSLOT: Invalid reuse of reader locktable slot, e.g. read-transaction already run for current thread
Л(
22:30
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Ну доку прочитать для начала )
+ А еще важно понимать зачем вам несколько read-only тразнакций и как они будут связаны с тредами
+ А еще важно понимать зачем вам несколько read-only тразнакций и как они будут связаны с тредами
АК
22:33
А ну вроде нашёл что-то:
One thread - One transaction
A thread can only use one transaction at a time, plus any nested read-write transactions in the non-writemap mode. Each transaction belongs to one thread. The MDBX_NOSTICKYTHREADS flag changes this, see below.
Do not start more than one transaction for a one thread. If you think about this, it's really strange to do something with two data snapshots at once, which may be different. MDBX checks and preventing this by returning corresponding error code (MDBX_TXN_OVERLAPPING, MDBX_BAD_RSLOT, MDBX_BUSY) unless you using MDBX_NOSTICKYTHREADS option on the environment. Nonetheless, with the MDBX_NOSTICKYTHREADS option, you must know exactly what you are doing, otherwise you will get deadlocks or reading an alien data.
One thread - One transaction
A thread can only use one transaction at a time, plus any nested read-write transactions in the non-writemap mode. Each transaction belongs to one thread. The MDBX_NOSTICKYTHREADS flag changes this, see below.
Do not start more than one transaction for a one thread. If you think about this, it's really strange to do something with two data snapshots at once, which may be different. MDBX checks and preventing this by returning corresponding error code (MDBX_TXN_OVERLAPPING, MDBX_BAD_RSLOT, MDBX_BUSY) unless you using MDBX_NOSTICKYTHREADS option on the environment. Nonetheless, with the MDBX_NOSTICKYTHREADS option, you must know exactly what you are doing, otherwise you will get deadlocks or reading an alien data.
👍
Л(
Л(
22:42
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Apple/Bionic toolchains also have similar bugs (at least some versions) with
The main problem is that design of
__builtin_cpu_supports().The main problem is that design of
__builtin_cpu_supports() feature requires support both from compiler and libc.
22:45
In reply to this message
В LMDB что-то не проверяется, что-то просто не работает и/или падает в подобных ситуациях неверного использования API.
Кроме этого, есть опция
Кроме этого, есть опция
MDB_NOTLS которая во многом аналогична MDBX_NOSTICKYTHREADS.
❤
АК
Л(
23:17
Леонид Юрьев (Leonid Yuriev)
libmdbx 0.13.2 "Прошлогодний Снег" (Last Year's Snow)
Поддерживающий выпуск с исправлением обнаруженных ошибок и устранением недочетов в день рождения и в память об Алекса́ндре Миха́йловиче Тата́рском, российском режиссёре-мультипликаторе, создавшем такие знаменитые мультфильмы как “Падал прошлогодний снег”, “Пластилиновая ворона”, заставку “Спокойной ночи, малыши!” и многие другие шедевры нашего детства.
The support release on the birthday and in memory of Alexander Mikhailovich Tatarsky, the Russian director-animator who created such famous cartoons as “Last Year's Snow Was Falling”, “Plasticine Crow”, the splash of “Good night, kids!” and many other masterpieces of our childhood.
https://gitflic.ru/project/erthink/libmdbx/release/6a1bfb7d-3192-4315-8d3f-d1b95a614bd3
Поддерживающий выпуск с исправлением обнаруженных ошибок и устранением недочетов в день рождения и в память об Алекса́ндре Миха́йловиче Тата́рском, российском режиссёре-мультипликаторе, создавшем такие знаменитые мультфильмы как “Падал прошлогодний снег”, “Пластилиновая ворона”, заставку “Спокойной ночи, малыши!” и многие другие шедевры нашего детства.
151 files changed, 10647 insertions(+), 14952 deletions(-)The support release on the birthday and in memory of Alexander Mikhailovich Tatarsky, the Russian director-animator who created such famous cartoons as “Last Year's Snow Was Falling”, “Plasticine Crow”, the splash of “Good night, kids!” and many other masterpieces of our childhood.
https://gitflic.ru/project/erthink/libmdbx/release/6a1bfb7d-3192-4315-8d3f-d1b95a614bd3
👍
A
e
8
🔥
2
❤
e
12 December 2024
Леонид Юрьев (Leonid Yuriev) changed group photo

SD
15:43
Sayan J. Das
In reply to this message
Is it possible to add ability to disable SSE2/AVX2/AVX512 optimizations individually using some flags like
MDBX_DISABLE_SSE2=1?
Л(
15:55
Леонид Юрьев (Leonid Yuriev)
In reply to this message
No.
For this purpose, the source code already uses conditional C-preprocessor directives that check the definition of specific macros (
if a compiler predefines such macros, but fails to compile corresponding code, then it is terribly broken.
For this purpose, the source code already uses conditional C-preprocessor directives that check the definition of specific macros (
__AVX512BW__, __ AVX2__, __SSE2__, __ARM_NEON__).if a compiler predefines such macros, but fails to compile corresponding code, then it is terribly broken.
👍
SD
vH
16:25
vnvisa.top Hello
In reply to this message
Could you give a try in terminal
export CC=/usr/bin/clang before compiling?
Леонид Юрьев (Leonid Yuriev) changed group photo

SD
16:47
Sayan J. Das
In reply to this message
clang and gcc don't have this problem, only zig since 0.13 (even though zig internally uses clang)
16:48
One way to work around is to compile object with clang then link with Zig, but I think I will rather wait until zig compiler is fixed.
16:49
For now, I disable SIMD completely as workaround..
Л(
16:50
Леонид Юрьев (Leonid Yuriev)
In reply to this message
You could try to undefine pre-refined macros by cli-options, i.e. pass the
-U__AVX512BW__ -U__AVX2__ -U__SSE2__ -U__ARM_NEON__ to zig compiler.
SD
17:39
Sayan J. Das
In reply to this message
I tried this, but doesn't seem to work. It's no problem though, will wait for Zig fix upstream. 👍
🤝
Л(
SD
22:38
Sayan J. Das
In the docs, it's stated that in
> This may be slightly faster for DBs that fit entirely in RAM, but is slower for DBs larger than RAM.
however, I was reading the chat history, and it was previously stated that for 1TB database and 16 GiB ram (DB much larger than ram), the writemap mode almost doubles performance, depending on transaction size.
MDBX_WRITEMAP mode,> This may be slightly faster for DBs that fit entirely in RAM, but is slower for DBs larger than RAM.
however, I was reading the chat history, and it was previously stated that for 1TB database and 16 GiB ram (DB much larger than ram), the writemap mode almost doubles performance, depending on transaction size.
22:39
I understand that WRITEMAP allows to easily corrupt the database with stray pointer writes, but is there any more drawback?
Please clarify.
Please clarify.
👍
ЮС
Л(
23:18
Леонид Юрьев (Leonid Yuriev)
In reply to this message
This is highly depends on OS kernel and a whole use case' picture.
In non-MDBX_WRITEMAP mode, or in MDBX_WRITEMAP but when libmdbx build with MDBX_AVOID_MSYNC=ON, libmdbx will track dirty pages and spill/oust ones when reached the
Elsewise an OS kernel will do the same (i.e. track dirty/modified pages in LRU-manner and swap-out oldest ones to disk).
However, libmdbx performs very precise tracking and outs only pages strictly to LRU-policy, whereas the OS kernel can only perform primitive/rough tracking, or even swap-out random pages.
In non-MDBX_WRITEMAP mode, or in MDBX_WRITEMAP but when libmdbx build with MDBX_AVOID_MSYNC=ON, libmdbx will track dirty pages and spill/oust ones when reached the
MDBX_opt_txn_dp_limit.Elsewise an OS kernel will do the same (i.e. track dirty/modified pages in LRU-manner and swap-out oldest ones to disk).
However, libmdbx performs very precise tracking and outs only pages strictly to LRU-policy, whereas the OS kernel can only perform primitive/rough tracking, or even swap-out random pages.
23:28
In reply to this message
Yes, MDBX_WRITEMAP mode is more dangerous.
However, you should rationally consider a risks, but not panic.
For instance, if pointers are used incorrectly, you always have a chance to corrupt a database, even in non-MDBX_WRITEMAP mode:
- it is possible to corrupt a dirty page in-memory before it will written to a DB file;
- it is possible to corrupt in memory an one of internal libmdbx structure;
- etc.
However, you should rationally consider a risks, but not panic.
For instance, if pointers are used incorrectly, you always have a chance to corrupt a database, even in non-MDBX_WRITEMAP mode:
- it is possible to corrupt a dirty page in-memory before it will written to a DB file;
- it is possible to corrupt in memory an one of internal libmdbx structure;
- etc.
13 December 2024
АК
00:27
Алексей (Keller) Костюк 😐
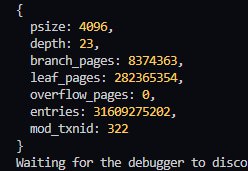
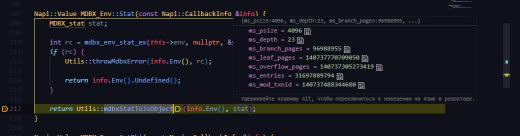
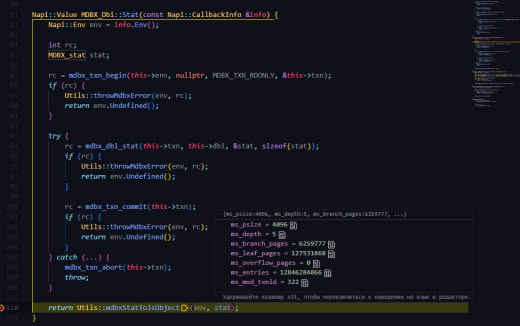
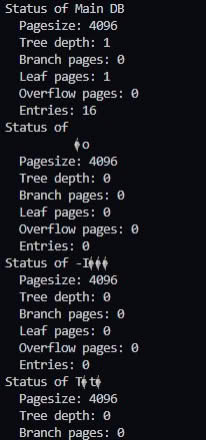
@erthink здравствуйте ещё раз. Почему env.stat выдаёт "плюсованные" значения, когда в теории должно данные для корневой бд выдавать, аналогично LMDB... Или в этом плане MDBX поменяла логику env?
Вы не подумайте, что я как-то принижаю ваши заслуги)) Просто сейчас постепенно внедряю вашу БД, вытесняя LMDB, находя такие несостыковочки :)
Вы не подумайте, что я как-то принижаю ваши заслуги)) Просто сейчас постепенно внедряю вашу БД, вытесняя LMDB, находя такие несостыковочки :)
Л(
00:33
Леонид Юрьев (Leonid Yuriev)
In reply to this message
mdbx_env_stat() выдает информацию по _всей_ БД, поэтому суммирование тут вполне логично.
А для получения информации о первичной таблице следует использовать mdbx_dbi_stat(dbi = 1).
А для получения информации о первичной таблице следует использовать mdbx_dbi_stat(dbi = 1).
00:40
Как в LMDB откровенно не помню, но в API исходно было много самых разных "моментов".
Какие-то первые правки/доработки в 2014 я делал просто по-месту, по сиюминутной необходимости.
Тогда еще не планировалось (вообще не предполагалось) что будет некий сильно развитый fork, и часть этих первых доработок было сделано как было нужно/удобнее для ReOpenLDAP и/или МегаФона, без оглядки на какую-либо совместимость с LMDB.
А уже после это нельзя было менять, чтобы не сломать что-то в МегаФоне.
Поэтому подобные расхождения есть, но мало, если это не единственное.
Как-то так.
Какие-то первые правки/доработки в 2014 я делал просто по-месту, по сиюминутной необходимости.
Тогда еще не планировалось (вообще не предполагалось) что будет некий сильно развитый fork, и часть этих первых доработок было сделано как было нужно/удобнее для ReOpenLDAP и/или МегаФона, без оглядки на какую-либо совместимость с LMDB.
А уже после это нельзя было менять, чтобы не сломать что-то в МегаФоне.
Поэтому подобные расхождения есть, но мало, если это не единственное.
Как-то так.
❤
АК
АК
01:36
Алексей (Keller) Костюк 😐
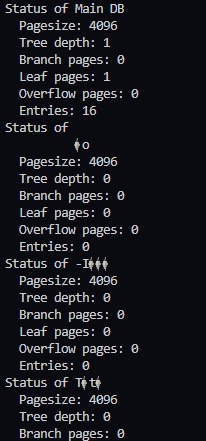
@erthink возникла проблемка :)
Случайно создал мусорные бд, и имена содержат рандом (проиграл видимо в поинтеры и c_str...) По имени оно их не находит, если брать из курсора и прокидывать в mdbx_dbi_open... Как можно удалить бы их?
Случайно создал мусорные бд, и имена содержат рандом (проиграл видимо в поинтеры и c_str...) По имени оно их не находит, если брать из курсора и прокидывать в mdbx_dbi_open... Как можно удалить бы их?
Л(
01:37
Леонид Юрьев (Leonid Yuriev)
In reply to this message
В API есть функции удаления принимающие имена в MDBX_val и std::string_view в C++ API.
АК
01:37
Алексей (Keller) Костюк 😐
Ммм... Спасибо
АК
АК
07:30
Алексей (Keller) Костюк 😐

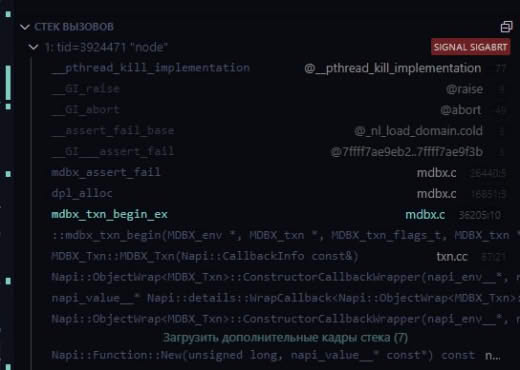
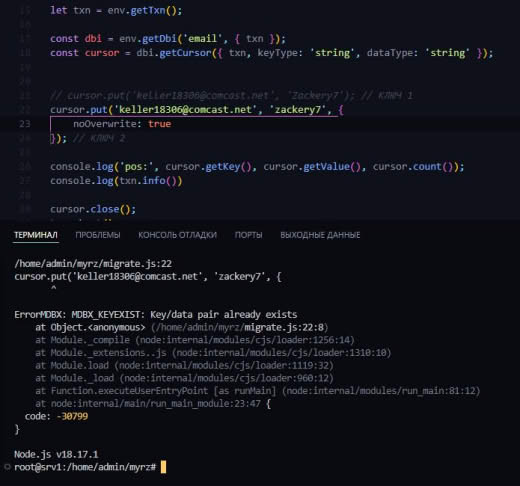
Если пытаюсь открыть дочернюю транзакцию, как readOnly (а иначе я не смогу прочитать GC таблицу), то:
node: mdbx:16851: dpl_alloc: Assertion `(txn->flags & MDBX_TXN_RDONLY) == 0' failed.
Segmentation fault
07:30
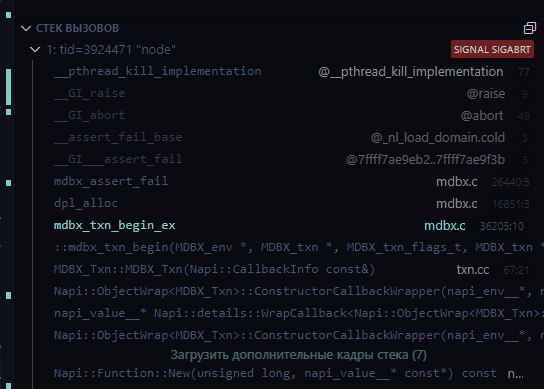
Л(
07:37
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Вложенность транзакций поддерживается только для пишущих транзакций, уже писал про это.
Если при попытке запустить вложенную транзакцию с MDBX_TXN_RDONLY не возвращается ошибка, то это какой-то регресс — посмотрю.
Если при попытке запустить вложенную транзакцию с MDBX_TXN_RDONLY не возвращается ошибка, то это какой-то регресс — посмотрю.
АК
07:38
Алексей (Keller) Костюк 😐
In reply to this message
А как создать курсор для gc таблицы тогда? Придётся завершить текущую и отдельно открывать только для чтения?
Л(
07:41
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Никак.
GC — это внутренняя структура и к ней не надо обращаться в пишущей транзакции.
Связанное с этим поведение уже менялось и может поменяться еще.
GC — это внутренняя структура и к ней не надо обращаться в пишущей транзакции.
Связанное с этим поведение уже менялось и может поменяться еще.
АК
07:42
Алексей (Keller) Костюк 😐
In reply to this message
Просто у нас в графану статистика пишется по "свободному" месту. Кроме, как из GC, её больше нигде не взять же?
Л(
07:46
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Вот совсем не надо гланды через Ж доставать...
Есть
Есть не задаваться целью проверить корректность использования страницы (отсутствие потерянных или использованных более одного раза), то объем страниц в GC проще посчитать как разницу между выделенными и использованными страницами.
Есть
mdbx_txn_info(), а для получения объема GC не следует её читать — это может быть очень накладно в экстремальных случаях.Есть не задаваться целью проверить корректность использования страницы (отсутствие потерянных или использованных более одного раза), то объем страниц в GC проще посчитать как разницу между выделенными и использованными страницами.
АК
08:20
Алексей (Keller) Костюк 😐
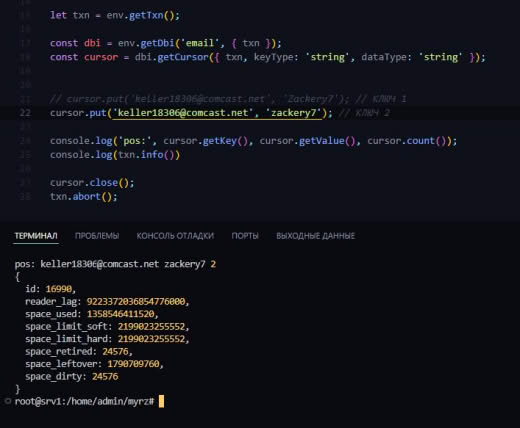
In reply to this message

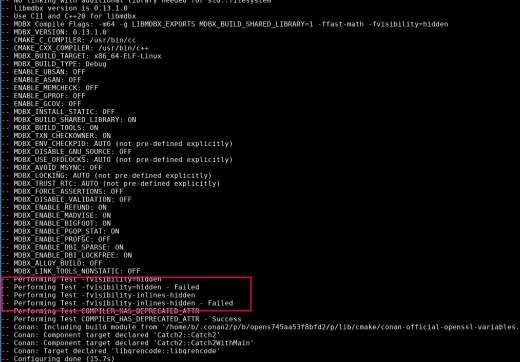
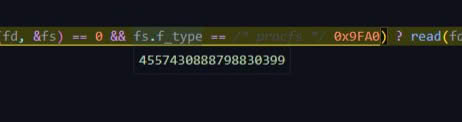
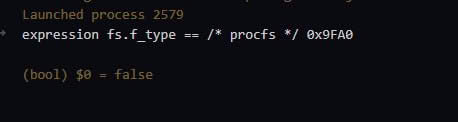
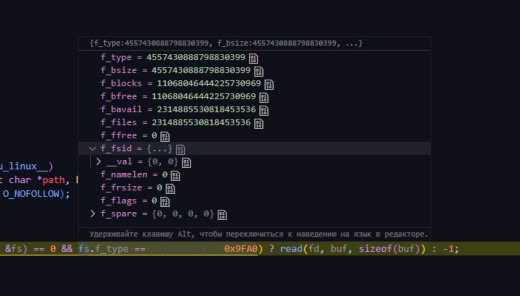
Всё, понял... Там для read и write разные...
08:27

08:27
08:28
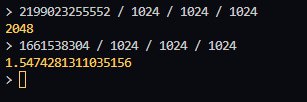
Так это просто вывод "макс размер"-"последняя занятая"...
08:29
Получается, если удалить всё из бд, то это значение не изменится... Ведь не учитываются таблицы на переработку...
Л(
08:33
Леонид Юрьев (Leonid Yuriev)
Не только.
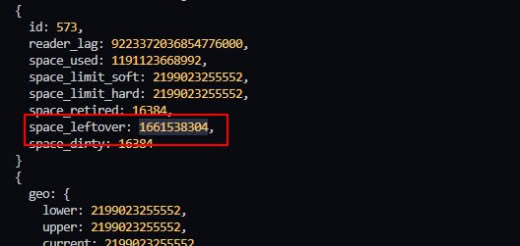
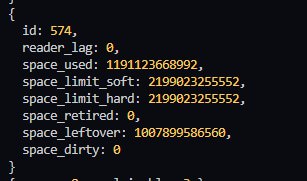
В leftover не входит GC, там только не-распределенные страницы.
Чтобы получить полный свободный размер (с учетом переработки GC) нужно из space_used вычесть размер всех таблиц и 3 мета-страницы.
См вывод
В leftover не входит GC, там только не-распределенные страницы.
Чтобы получить полный свободный размер (с учетом переработки GC) нужно из space_used вычесть размер всех таблиц и 3 мета-страницы.
См вывод
mdbx_stat -ef / mdbx_chk -vvv и соответствующий исходный код.
АК
08:42
Алексей (Keller) Костюк 😐
In reply to this message
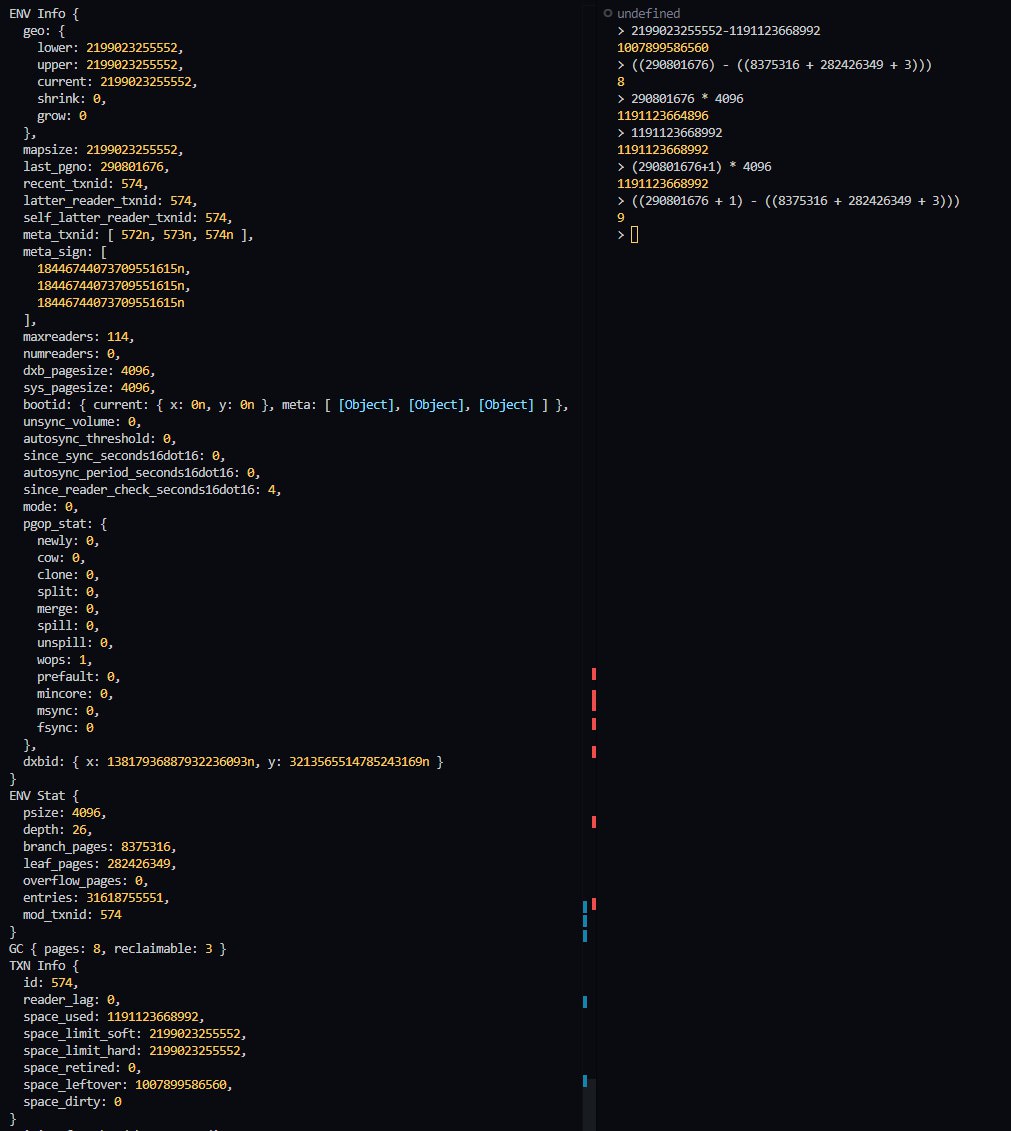
Вроде почти совпало... Но куда-то одна таблица подевалась... Не то, чтобы я сильно её ищу, но всё же)
Л(
10:51
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Что именно у вас потерялось и почему вы так считаете — не понятно.
Но если есть сомнения, то сравните полученные значения с выводом
Но если есть сомнения, то сравните полученные значения с выводом
mdbx_chk -vvv и/или mdbx_stat -efa.
Л(
12:09
Леонид Юрьев (Leonid Yuriev)
In reply to this message
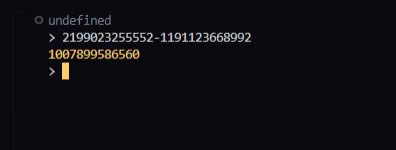
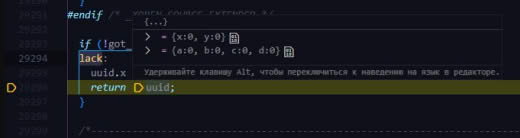
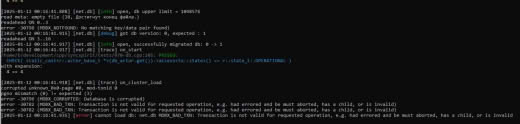
Еще крайне странно, что у вас нет bootid. Это явный признай какой-то ошибки и/или проблемы.
SD
12:13
Sayan J. Das
In reply to this message
Okay, so when DB size exceeds RAM, and
Am I correct?
MDBX_WRITEMAP enabled, then OS will be responsible for swapping which is not accurate as libmdbx itself; and that's why the performance may suffer. But as long as DB can fit in memory, swapping out is minimal so WRITEMAP reduces overhead of tracking pages, etc and hence improves performance.Am I correct?
Л(
SD
12:14
Sayan J. Das
i.e I should enable WRITEMAP considering the 1. risk of corrupting DB and 2. reduction of performance in big DB scenarios
Л(
12:28
In reply to this message
Nonetheless, some clarification about performance.
Depending on the operating system, database size, and usage scenario, enabling MDBX_WRITEMAP can both increase or decrease performance.
In most cases, performance is higher using MDBX_WRITEMAP, but there is no universal rule here.
Here are some factors:
- Windows has very poor performance of msync(), i.e.
- on OpenBSD actually MDBX_WRITEMAP is required, since no unified page cache in the OS kernel;
- on many system/kernels performance my degrade in large-DB cases because of scanning large PTE-tables and/or rough LRU-tracking;
+ in large-update cases it is to hard predict/estimate what is will be faster/cheaper: a file I/O and shadowed update of page cache chained to mmap-region, or a scanning of large PTE-tables with LRU-eviction of dirty-pages.
Depending on the operating system, database size, and usage scenario, enabling MDBX_WRITEMAP can both increase or decrease performance.
In most cases, performance is higher using MDBX_WRITEMAP, but there is no universal rule here.
Here are some factors:
- Windows has very poor performance of msync(), i.e.
FlushViewOfFile();- on OpenBSD actually MDBX_WRITEMAP is required, since no unified page cache in the OS kernel;
- on many system/kernels performance my degrade in large-DB cases because of scanning large PTE-tables and/or rough LRU-tracking;
+ in large-update cases it is to hard predict/estimate what is will be faster/cheaper: a file I/O and shadowed update of page cache chained to mmap-region, or a scanning of large PTE-tables with LRU-eviction of dirty-pages.
Andrew Ashikhmin invited Andrew Ashikhmin
Milen Filatov invited Milen Filatov
SD
14:31
Sayan J. Das
In reply to this message
Thanks for the explanation. 👍
In my case, I'm building a general purpose document DB using libmdbx, where the value sizes can range anywhere from 100 bytes to 16 KiB per record. So I decided to use 8 KiB as pagesize.
From this discussion, it's clear that it might not be worth it to enable WRITEMAP as I intend to support few terabytes size of DB.
In my case, I'm building a general purpose document DB using libmdbx, where the value sizes can range anywhere from 100 bytes to 16 KiB per record. So I decided to use 8 KiB as pagesize.
From this discussion, it's clear that it might not be worth it to enable WRITEMAP as I intend to support few terabytes size of DB.
vH
15:42
vnvisa.top Hello
In reply to this message
It would be great if you have time to benchmark your terabytes size of DB with and without WRITEMAP.
👍
SD
АК
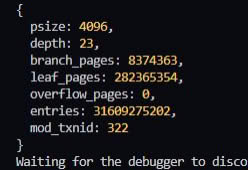
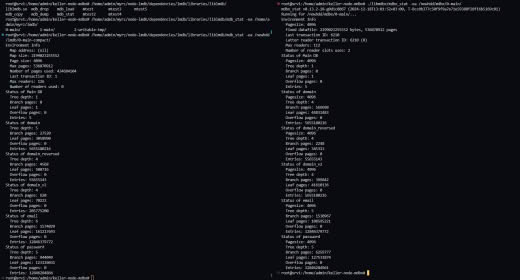
17:26
Алексей (Keller) Костюк 😐
In reply to this message
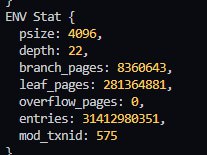
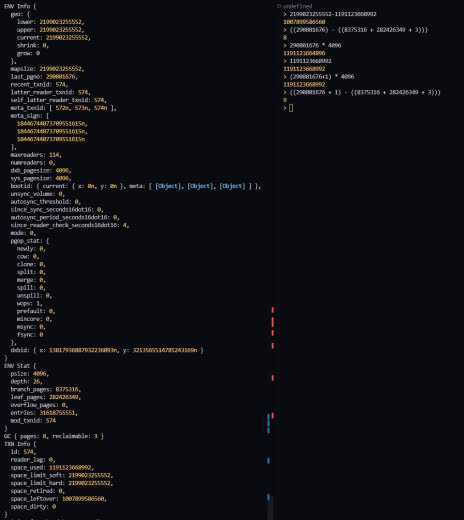
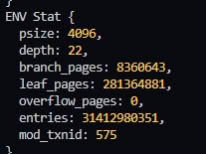
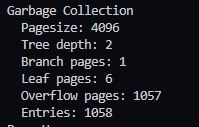
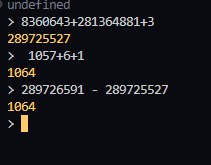
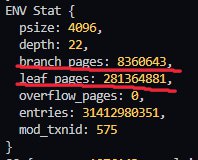
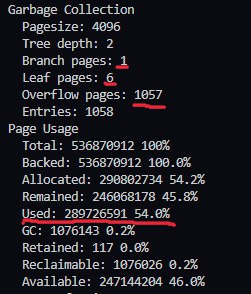
В gc 8 таблиц, когда у меня после вычислений получается 9
Если сплюсовать env.branch_pages+env.leaf_pages+3 и сравнить с mdbx_stat, то указанный used из вывода тоже будет на один больше.
Сейчас, как я выяснил, проблема в том, что env_stat не учитывает stat GC таблицы
Если сплюсовать env.branch_pages+env.leaf_pages+3 и сравнить с mdbx_stat, то указанный used из вывода тоже будет на один больше.
Сейчас, как я выяснил, проблема в том, что env_stat не учитывает stat GC таблицы
17:33
In reply to this message
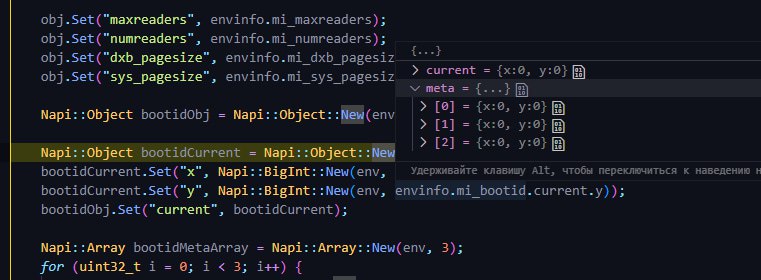
а что за он? Как я могу проверить это?
Такой выдаёт env_info(
Может из-за того, что я бд делал через mdbx_load?
Или потому, что у меня сервер - LXC контейнер?
Такой выдаёт env_info(
Может из-за того, что я бд делал через mdbx_load?
Или потому, что у меня сервер - LXC контейнер?
Л(
17:51
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Не уверен что я понял вас, а вы меня.
Со статистикой использования страниц идея примерно такая:
- есть кол-во распределенных (allocated) страниц, технически внутри структур БД это номер первой не-распределенной страницы.
- можно получить суммарное кол-во страниц используемых корневой таблицей и таблицами пользователя.
- еще есть 3 мета-страницы.
- всё остальное в GC, т.е. разница между распределенными/allocated и используемыми страницами.
При этом предполагается что:
- пользователю нет дела до конкретного содержания GC (сколько страниц в списках внутри GC, а сколько занято под b-tree самой GC).
- при сомнениях что есть потерянные и/или дважды использованные страницы, т.е. сомнениях в целостности БД, следует использовать утилиту mdbx_chk или mdbx_env_chk().
Ничего не мешает добавить в API некую интроспекцию GC, но вопрос — зачем ?
Кроме этого, текущее API в принципе позволяет получить такую информацию в читающих транзакциях, а mdbx_env_chk() предусматривает обратные вызовы на все случаи.
Со статистикой использования страниц идея примерно такая:
- есть кол-во распределенных (allocated) страниц, технически внутри структур БД это номер первой не-распределенной страницы.
- можно получить суммарное кол-во страниц используемых корневой таблицей и таблицами пользователя.
- еще есть 3 мета-страницы.
- всё остальное в GC, т.е. разница между распределенными/allocated и используемыми страницами.
При этом предполагается что:
- пользователю нет дела до конкретного содержания GC (сколько страниц в списках внутри GC, а сколько занято под b-tree самой GC).
- при сомнениях что есть потерянные и/или дважды использованные страницы, т.е. сомнениях в целостности БД, следует использовать утилиту mdbx_chk или mdbx_env_chk().
Ничего не мешает добавить в API некую интроспекцию GC, но вопрос — зачем ?
Кроме этого, текущее API в принципе позволяет получить такую информацию в читающих транзакциях, а mdbx_env_chk() предусматривает обратные вызовы на все случаи.
👌
b
17:53
In reply to this message
Видимо в вашем контейнере не доступен
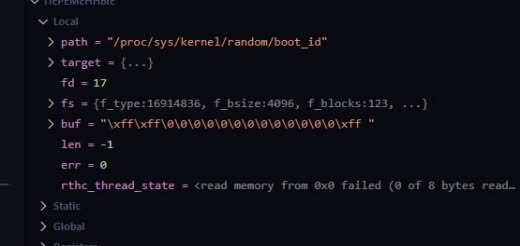
/proc/sys/kernel/random/boot_id.
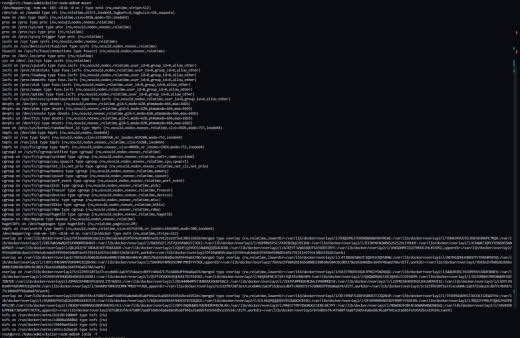
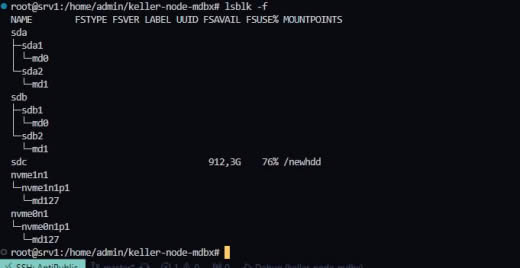
АК
Л(
17:56
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Хм, в целом надо разбираться.
Где-то в скриншотах выше было видно что в bootid нули.
А что показывает
Где-то в скриншотах выше было видно что в bootid нули.
А что показывает
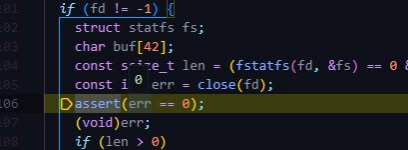
mdbx_chk -vv ?
АК
17:57
Алексей (Keller) Костюк 😐
In reply to this message
К сожалению, LMDB оставила очень большую боль с GC... Поэтому мы вынуждены были жёстко считать её, чтобы вовремя отлавливать проблемы. Для этого мы и решили перейти на MDBX.
Но удалять подсчёт не хотелось бы, пока на проде не откатаем
Но удалять подсчёт не хотелось бы, пока на проде не откатаем
17:59
In reply to this message
mdbx_chk v0.13.2-0-gb687e835 (2024-12-11T21:51:56+03:00, T-5c7ffd4bbdaaf3578a64afed16bac16f06db2837)
Running for /newhdd/mdbx/0-main/ in 'read-only' mode with verbosity level 2 (of 0..9)...
open-MADV_DONTNEED 290802734..536870912
readahead OFF 0..290802734
- Taking lock... done
dxb-id bfc32c6395f7b13d-2c98e0cf3b384021
current boot-id is unavailable
- Peek the meta-pages...
pagesize 4096 (4096 system), max keysize 1980..2022, max readers 114
mapsize 2199023255552 (2.00 TiB)
fixed datafile: 2199023255552 (2.00 TiB), 536870912 pages
= transactions: recent 1726, latter reader 1726, lag 0
- Traversal B-Trees by txn#1726...
18:00
Остальная инфа явно будет только через день, ибо бд большая :)
Л(
18:03
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Остальное и не надо. Уже видно
Желательно понять в чем дело.
Может
"current boot-id is unavailable".Желательно понять в чем дело.
Может
/proc/sys/kernel/random/boot_id не доступен пользователю от имени которого работает софт ?
АК
18:03
Алексей (Keller) Костюк 😐
In reply to this message
всё от рута
скажите где можно продебажить, гляну
скажите где можно продебажить, гляну
Л(
18:14
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Да, очень хотелось-бы понять что происходит, ибо это потенциальная проблема.
1.
В
2.
Функция
3.
Функция
Предполагаю что ломается на
Если так, то мне нужно знать код ошибки после вызова
1.
В
src/global.c есть __attribute__((__constructor__)) mdbx_global_constructor(), оттуда вызывается mdbx_init() и далее osal_ctor().2.
Функция
osal_ctor() находится в src/osal.c и в её конце есть globals.bootid = osal_bootid();.3.
Функция
osal_bootid() относительно проста для случая Linux, и вот желательно понять доходит ли до неё управление, а если доходит то почему не отрабатывает.Предполагаю что ломается на
fstatfs(fd, &fs) == 0 && fs.f_type == /* procfs */ 0x9FA0.Если так, то мне нужно знать код ошибки после вызова
fstatfs() или значение fs.f_type, если вызов fstatfs успешен.
АК
18:17
Алексей (Keller) Костюк 😐
18:18

тут по нулям выдаёт
Л(
18:20
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Да, это уже понятно. Гляньте пожалуйста что там с fstatfs()
АК
18:38
Алексей (Keller) Костюк 😐
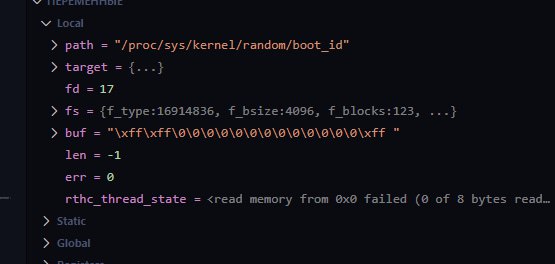
18:38

18:39
18:40
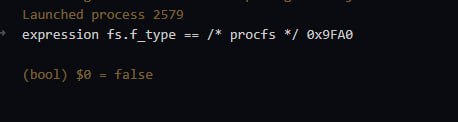
18:41
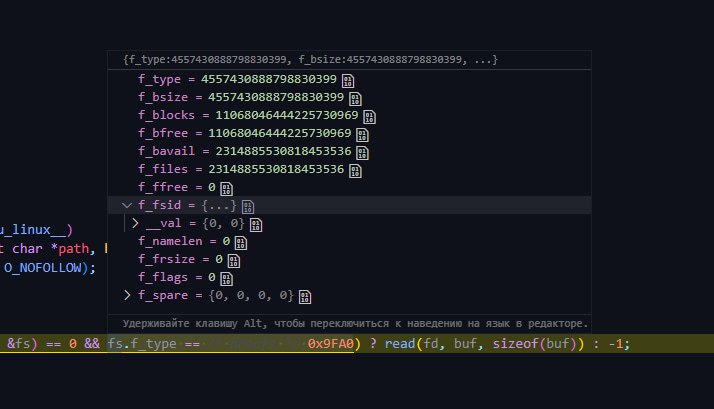
не знаю, может пригодится
Л(
АК
Л(
18:47
Леонид Юрьев (Leonid Yuriev)
Если я правильно понял, то после вызова fstatfs() значение fs.f_type = 16914836 = 0x1021994.
А потом затирается 4557430888798830399 (это просто байт 0x3f).
Так ?
А потом затирается 4557430888798830399 (это просто байт 0x3f).
Так ?
19:02
In reply to this message
Запустите в вашем контейнере вот этот простой код:
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/vfs.h>
int main(int argc, char *argv[]) {
const int fd = open("/proc/sys/kernel/random/boot_id", O_RDONLY | O_NOFOLLOW);
if (fd == -1) {
perror("open(/proc/sys/kernel/random/boot_id)");
return EXIT_FAILURE;
}
struct statfs fs;
if (fstatfs(fd, &fs) != 0) {
perror("fstatfs()");
return EXIT_FAILURE;
}
printf("fs.f_type = 0x%lX\n", fs.f_type);
return EXIT_SUCCESS;
}
👍
АК
19:02
Что он выдаёт ?
АК
Л(
19:08
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Хм, это еще более странное. Ибо
O_NOFOLLOW определен в fcntl.h уже лет 25
АК
Л(
19:09
Леонид Юрьев (Leonid Yuriev)
А так это в WSL-песочнице что-ли ?
АК
19:10
Алексей (Keller) Костюк 😐
In reply to this message
не, какой-то физический сервер, на котором LXC контейнер с моим сервером (как я понял, это нужно сис админу для бекапов жёстких)
19:12

хах. Мб из-за того, что внешний диск смонтировали или из-за LVM
19:14
А ДА. В LXC /proc монтируется отдельно, вот он и TMP
Л(
19:14
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Тогда у меня к вам еще несколько вопросов:
Что выдают
Что выдают
mount и lsblk -f в контейнере ?
АК
19:15
Алексей (Keller) Костюк 😐
Л(
АК
19:16
Алексей (Keller) Костюк 😐

19:16
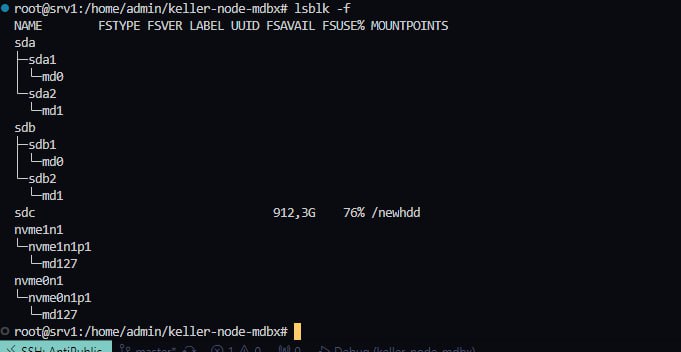
19:18
none on /proc/sys/kernel/random/boot_id type tmpfs (ro,nosuid,nodev,noexec,relatime,size=492k,mode=755,inode64)
Л(
19:30
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Странно, но фактически вместо нормального bootid намерено смонтирована заглушка.
Что с этим делать не понятно, поскольку нет гарантий:
1. Что после реальной перезагрузки такой bootid будет новым/уникальным.
Если bootid не изменится, то у libmdbx НЕ будет возможность заметить факт перезагрузки и потенциальное повреждение БД.
2. Что при рестарте контейнера (не ядра) и сохранении очередей ввода-вывода (т.е. без утраты данных еще не записанных на диск).
Если bootid сменится, то libmdbx откатит состояние БД до крайней точки фиксации со сбором всех данных на диск, либо откажется открывать БД если такой точки нет.
Что с этим делать не понятно, поскольку нет гарантий:
1. Что после реальной перезагрузки такой bootid будет новым/уникальным.
Если bootid не изменится, то у libmdbx НЕ будет возможность заметить факт перезагрузки и потенциальное повреждение БД.
2. Что при рестарте контейнера (не ядра) и сохранении очередей ввода-вывода (т.е. без утраты данных еще не записанных на диск).
Если bootid сменится, то libmdbx откатит состояние БД до крайней точки фиксации со сбором всех данных на диск, либо откажется открывать БД если такой точки нет.
19:31
Пока оставлю всё как есть, ибо такой bootid нельзя считать работающим/надежным.
АК
19:39
Алексей (Keller) Костюк 😐
In reply to this message
Могу спросить у сис админа, как это работает
Л(
19:41
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Как работает я и сам могу рассказать. Но вот хотелось-бы услышат пояснения "почему именно так", а не как в докере по-умолчанию.
АК
19:42
Алексей (Keller) Костюк 😐
In reply to this message
По той же причине, почему и Amazon AWS. Там точно также с контейнерами
(на сервере не один контейнер, которые жёстко изолированы)
(на сервере не один контейнер, которые жёстко изолированы)
Л(
19:44
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Там настоящий bootid скрывается чтобы нельзя было найти/идентифицировать хост и провести атаку (через сторонние каналы и т.п.).
Но там (вроде-бы) не tmpfs, а всё-таки procfs.
Но там (вроде-бы) не tmpfs, а всё-таки procfs.
19:47
А мне надо как-то либо отлавливать эту ситуацию, либо считать что bootid нет.
Проблема в том, что так можно буквально выкинуть данные пользователя, посчитав что они утрачены, хотя на самом деле всё целое.
Проблема в том, что так можно буквально выкинуть данные пользователя, посчитав что они утрачены, хотя на самом деле всё целое.
АК
19:48
Алексей (Keller) Костюк 😐
In reply to this message
Почему бы это не оставить на решение пользователя через флаг?
Л(
19:49
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Половина сделает не правильно и будет винить в проблемах сами знаете кого ;)
🤣
АК
19:49
Попробую найти соответствующие рекомендации от амазона и т.п.
АК
19:49
Алексей (Keller) Костюк 😐
In reply to this message
То есть, если bootid нет, то при повреждении просто можно будет вручную откатиться? Бд скажет, что повреждено или неизвестно?
19:50
In reply to this message
Отмена. Он не контейнерный
АК
21:59
Л(
22:00
Леонид Юрьев (Leonid Yuriev)
In reply to this message
1.
Всё это относится только к no-sync-режимам с отложенной записью на диск (MDBX_SAFE_NOSYNC, MDBX_NOMETASYNC, MDBX_UTTERLY_NOSYNC).
А в обычных режимах работы (MDBX_SYNC_DURABLE) все данные всегда полностью записываются на диск при фиксации транзакции.
2.
bootid используется для проверки — была ли перезагрузка после последней записи в БД или нет.
Если bootid не изменился, то перезагрузки не было, а все изменения в ОЗУ в отображенном файле или записанные в файл не пропали даже если еще не записались на диск.
Поэтому при том-же bootid не нужно делать отката к БД к точке, когда был сделан fdatasync().
3.
Если же bootid не доступен (нулевой), то будет сделан откат даже когда в этом нет необходимости.
Всё это относится только к no-sync-режимам с отложенной записью на диск (MDBX_SAFE_NOSYNC, MDBX_NOMETASYNC, MDBX_UTTERLY_NOSYNC).
А в обычных режимах работы (MDBX_SYNC_DURABLE) все данные всегда полностью записываются на диск при фиксации транзакции.
2.
bootid используется для проверки — была ли перезагрузка после последней записи в БД или нет.
Если bootid не изменился, то перезагрузки не было, а все изменения в ОЗУ в отображенном файле или записанные в файл не пропали даже если еще не записались на диск.
Поэтому при том-же bootid не нужно делать отката к БД к точке, когда был сделан fdatasync().
3.
Если же bootid не доступен (нулевой), то будет сделан откат даже когда в этом нет необходимости.
Л(
22:40
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Попробуйте ветку
devel, т.е. собрать и запустить mdbx_chk -vv
14 December 2024
Happy invited Happy
Hopinheimer invited Hopinheimer
15 December 2024
Евгений Гросбейн invited Евгений Гросбейн
e invited e
Andreyka invited Andreyka
АК
18:38
Алексей (Keller) Костюк 😐
In reply to this message
Простите, что так долго. В понедельник может займусь этим. Очень трудно качать с gitflic...
18:40
In reply to this message
А в чём прикол? Почему ему вдруг count не нравится? Вся таблица же dup
(причём, 90 раз до этого всё нормально считало)
(причём, 90 раз до этого всё нормально считало)
Л(
19:34
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Хм, это не нормально. Надо смотреть как у вас так удачно получилось.
Ассерт сработал так как состояние курсора не корректно для текущей позиции.
Основной (не вложенный) курсор стоит на строке без флага N_DUP, поэтому вложенный курсор (для хождения по вложенному b-tree со значениями "дубликатов") должен быть в hollow-состоянии.
Давайте сценарий воспроизведения и показывайте ваш код.
Ассерт сработал так как состояние курсора не корректно для текущей позиции.
Основной (не вложенный) курсор стоит на строке без флага N_DUP, поэтому вложенный курсор (для хождения по вложенному b-tree со значениями "дубликатов") должен быть в hollow-состоянии.
Давайте сценарий воспроизведения и показывайте ваш код.
АК
19:40
Алексей (Keller) Костюк 😐
In reply to this message
Не думаю, что смогу адекватный пример дать... Вот что на JS у меня
19:41
а вот на плюсах
19:43
может это поможет?
Л(
АК
19:49
Алексей (Keller) Костюк 😐
In reply to this message
ща чуть продебажил - проблема именно на writeCursor... Мб не видит не закоммиченные данные хз
Л(
22:43
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Поправил, пока только в ветке
Суть проблемы в комментарии коммита.
Пролью в
Спасибо за сообщения об ошибках/проблемах.
devel.Суть проблемы в комментарии коммита.
Пролью в
master как подтвердите что у вас всё хорошо, включая bootid внутри LXC.Спасибо за сообщения об ошибках/проблемах.
Л(
23:03
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Еще в вашем JS-коде логическая проблема, никак не связанная с замеченной ошибкой и срабатыванием ассерта.
У вас там внутри цикла выполняется пере-привязка курсора к новой транзакции, в следом в условии цикла
Это не будет работать, так как
Поэтому
Однако, это будет неким образом работать (но, видимо, не как вы задумали), так как исторически свежие курсоры (сразу после создания/инициализации) поддерживают авто-установку в начало данных. Проще говоря, вызов
На всякий — сохранить состояние/позицию курсора в такой ситуации не возможно, так как в новой транзакции уже другой MVCC снимок, в котором вся БД может иметь новое состояние.
У вас там внутри цикла выполняется пере-привязка курсора к новой транзакции, в следом в условии цикла
cursor.next().Это не будет работать, так как
cursor.bind() полностью сбрасывает состояние курсора, т.е. его позицию т.д.,Поэтому
next() с продолжением уже не возможен.Однако, это будет неким образом работать (но, видимо, не как вы задумали), так как исторически свежие курсоры (сразу после создания/инициализации) поддерживают авто-установку в начало данных. Проще говоря, вызов
cursor.next() сразу после cursor.bind() аналогичен вызову cursor.first().На всякий — сохранить состояние/позицию курсора в такой ситуации не возможно, так как в новой транзакции уже другой MVCC снимок, в котором вся БД может иметь новое состояние.
АК
23:04
Алексей (Keller) Костюк 😐
Я на стороне плюсов сделал при bind ставить курсор KEY_SET на прошлые данные
Л(
АК
23:07
23:10
In reply to this message
Я вот кстати хотел у вас спросить. Это единственный вариант, что нужно постоянно перемещать курсор вручную после каждого коммита+ребинда транзакции? Или может есть более "оптимальный" вариант?
Л(
23:31
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Сейчас это единственный способ, по-другому через текущее API не получится.
Если же задаться целью сделать быстрее, то гипотетически можно добавить функции быстрого сохранения/восстановления позиции курсора с переходом границы транзакций, для случая когда целевая таблица не меняется.
Т.е. если не было изменений, то можно восстановить позицию курсора без поиска по b-tree.
Но всё это представляется слишком надуманным переинженерингом, т.к. будет экономить спички и работать не во всех случаях, а только пока нет изменений (соответственно, всё равно потребуется fallback через поиск).
Если же задаться целью сделать быстрее, то гипотетически можно добавить функции быстрого сохранения/восстановления позиции курсора с переходом границы транзакций, для случая когда целевая таблица не меняется.
Т.е. если не было изменений, то можно восстановить позицию курсора без поиска по b-tree.
Но всё это представляется слишком надуманным переинженерингом, т.к. будет экономить спички и работать не во всех случаях, а только пока нет изменений (соответственно, всё равно потребуется fallback через поиск).
АК
23:32
Алексей (Keller) Костюк 😐
In reply to this message
ну я доверяю кэшу фс диска, поэтому я не сильно переживал по этому поводу... Но всё равно заставило задуматься о целесообразности :)
АК

Л(
23:51
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Да, в вашем случае можно не обращать внимания (либо установить cmake).
АК
23:55
Алексей (Keller) Костюк 😐
In reply to this message
root@srv1:/home/admin/keller-node-mdbx/libmdbx# ./mdbx_chk -vv /newhdd/mdbx/0-main/
mdbx_chk v0.13.2-4-gccdb6255 (2024-12-13T08:26:55+03:00, T-d5724ae9078d590b13d807bd628aae9f762d6e13)
Running for /newhdd/mdbx/0-main/ in 'read-only' mode with verbosity level 2 (of 0..9)...
open-MADV_DONTNEED 290802734..536870912
readahead OFF 0..290802734
- Taking lock... done
dxb-id bfc32c6395f7b13d-2c98e0cf3b384021
current boot-id is unavailable
- Peek the meta-pages...
pagesize 4096 (4096 system), max keysize 1980..2022, max readers 114
mapsize 2199023255552 (2.00 TiB)
fixed datafile: 2199023255552 (2.00 TiB), 536870912 pages
= transactions: recent 2434, latter reader 2434, lag 0
- Traversal B-Trees by txn#2434...^C
- Processing @GC by txn#2434...
! used pages mismatch (40792(walked) != 290802734(allocated - GC))
! GC pages mismatch (290761942(expected) != 0(GC))
- Page allocation:
backed by file: 536870912 pages (100.0%), 0 left to boundary (0.0%)
used: 40792 page(s), 0.0% of backed, 0.0% of boundary
remained: 246068178 page(s) (45.8%) of backed, 246068178 to boundary (45.8% of boundary)
reclaimable: 0 (0.0% of backed, 0.0% of boundary), GC 0 (0.0% of backed, 0.0% of boundary)
detained by reader(s): 0 (0.0% of backed, 0.0% of boundary), 1 reader(s), lag 0
allocated: 290802734 page(s), 54.2% of backed, 54.2% of boundary
available: 246068178 page(s) (45.8%) of backed, 246068178 to boundary (45.8% of boundary)
= total 536870912 pages, backed 536870912 (100.0%), allocated 290802734 (54.2%), available 246068178 (45.8%)
- Processing @MAIN... summary: 0 records, 0 tables, 0 key's bytes, 0 data's bytes, 0 problem(s)
No table(s)

23:58

Версия вроде обновилась...
Л(
23:58
Леонид Юрьев (Leonid Yuriev)
Вы что-то не то собрали, либо не скачали изменения.
Должно быть
Должно быть
v0.13.2-6-ga845522d
23:59
Т.е. у вас нет двух последних коммитов.
АК
23:59
Алексей (Keller) Костюк 😐
А. а чё они.. не выгрузились... Ща
16 December 2024
АК
00:00
Алексей (Keller) Костюк 😐
Вот что значит привык к GUI... Давно не менял ветки через CLI
00:03
mdbx_chk v0.13.2-6-ga845522d (2024-12-15T22:17:12+03:00, T-0456e64ae0a85075d41430caf7e9c9a26a7b4d26)
Running for /newhdd/mdbx/0-main/ in 'read-only' mode with verbosity level 2 (of 0..9)...
open-MADV_DONTNEED 290802734..536870912
readahead OFF 0..290802734
- Taking lock... done
dxb-id bfc32c6395f7b13d-2c98e0cf3b384021
current boot-id b8998f38b295dcd2-748320f5b4174451
- Peek the meta-pages...
pagesize 4096 (4096 system), max keysize 1980..2022, max readers 114
mapsize 2199023255552 (2.00 TiB)
fixed datafile: 2199023255552 (2.00 TiB), 536870912 pages
= transactions: recent 2434, latter reader 2434, lag 0
- Traversal B-Trees by txn#2434...^C
- Processing @GC by txn#2434...
! used pages mismatch (10974(walked) != 290802734(allocated - GC))
! GC pages mismatch (290791760(expected) != 0(GC))
- Page allocation:
backed by file: 536870912 pages (100.0%), 0 left to boundary (0.0%)
used: 10974 page(s), 0.0% of backed, 0.0% of boundary
remained: 246068178 page(s) (45.8%) of backed, 246068178 to boundary (45.8% of boundary)
reclaimable: 0 (0.0% of backed, 0.0% of boundary), GC 0 (0.0% of backed, 0.0% of boundary)
detained by reader(s): 0 (0.0% of backed, 0.0% of boundary), 1 reader(s), lag 0
allocated: 290802734 page(s), 54.2% of backed, 54.2% of boundary
available: 246068178 page(s) (45.8%) of backed, 246068178 to boundary (45.8% of boundary)
= total 536870912 pages, backed 536870912 (100.0%), allocated 290802734 (54.2%), available 246068178 (45.8%)
- Processing @MAIN... summary: 0 records, 0 tables, 0 key's bytes, 0 data's bytes, 0 problem(s)
No table(s)
Л(
АК
00:04
Алексей (Keller) Костюк 😐
In reply to this message
я прервал тест сразу же
не хочу ждать день:)
не хочу ждать день:)
00:05
count вроде тоже исправлен
Л(
АК
00:05
Алексей (Keller) Костюк 😐
Всё, спасибо. Спокойной
🤝
Л(
Л(
00:05
Леонид Юрьев (Leonid Yuriev)
Ладно, до завтра. Спокойной.
АК
00:28
Алексей (Keller) Костюк 😐
In reply to this message
Знаю, что вы уже спите скорее всего, но лучше сейчас спрошу, чтобы завтра не забыть.
Насколько я помню, LMDB для DUP таблиц возвращала какое-то бредовое значение страниц (а точнее только ключи, но не значения или типа того). Как я понял, у MDBX это исправлено... А есть возможность узнать сколько страниц занимают все DUP значения определённого ключа?
Также есть ещё вопрос. dbi_info() возвращает кол-во (entries) всех значений, а есть возможность получить кол-во самих ключей (уникальных для DUP), а не считать самому при вставке?
Насколько я помню, LMDB для DUP таблиц возвращала какое-то бредовое значение страниц (а точнее только ключи, но не значения или типа того). Как я понял, у MDBX это исправлено... А есть возможность узнать сколько страниц занимают все DUP значения определённого ключа?
Также есть ещё вопрос. dbi_info() возвращает кол-во (entries) всех значений, а есть возможность получить кол-во самих ключей (уникальных для DUP), а не считать самому при вставке?
Nik Grebnev invited Nik Grebnev
Л(
10:30
Леонид Юрьев (Leonid Yuriev)
In reply to this message
1. Да.
Насколько помню LMDB не подсчитывает страницы вложенных b-tree, в которых хранятся значения "дубликатов".
В MDBX этот подсчет реализован, но сейчас в API нет возможности получить кол-во страниц занятых multivalue-данными ключа.
Технически это несложно добавить — по аналогии с
(на всякий, малое кол-во значений может храниться на вложенной странице, без выделения полной).
2. Нет.
Получить кол-во уникальных ключей (без "дубликатов") сейчас нельзя.
Исторически (еще в Berkeley DB) ключи с multivalue назывались дубликатами и внутри БД хранились именно как дубликаты (не-уникальные ключи), поэтому в статистике был один счетчик, который содержал кол-во записей (т.е. включая дубликаты).
В LMDB по-возможности сохранено API Berkeley DB, включая семантику "дубликатов" (хотя на самом деле ключи строго уникальны, зато хранится много значений).
В MDBX не было причин это менять, поэтому в структуре b-tree есть только один счетчик.
Гипотетически можно нарушить бинарную совместимость по формату БД и добавить еще одно поле. Однако, если "пускаться во все тяжкие" с изменением формата БД, то просится еще много тонн изменений — тогда это уже будет другая БД, которой нужно другое API, а еще все это нужно отладить, 100 раз проверить и стабилизировать...
Насколько помню LMDB не подсчитывает страницы вложенных b-tree, в которых хранятся значения "дубликатов".
В MDBX этот подсчет реализован, но сейчас в API нет возможности получить кол-во страниц занятых multivalue-данными ключа.
Технически это несложно добавить — по аналогии с
mdbx_cursor_count() прочитать просуммировать pages-счетчики структуры mc->subcur->nested_tree (на всякий, малое кол-во значений может храниться на вложенной странице, без выделения полной).
2. Нет.
Получить кол-во уникальных ключей (без "дубликатов") сейчас нельзя.
Исторически (еще в Berkeley DB) ключи с multivalue назывались дубликатами и внутри БД хранились именно как дубликаты (не-уникальные ключи), поэтому в статистике был один счетчик, который содержал кол-во записей (т.е. включая дубликаты).
В LMDB по-возможности сохранено API Berkeley DB, включая семантику "дубликатов" (хотя на самом деле ключи строго уникальны, зато хранится много значений).
В MDBX не было причин это менять, поэтому в структуре b-tree есть только один счетчик.
Гипотетически можно нарушить бинарную совместимость по формату БД и добавить еще одно поле. Однако, если "пускаться во все тяжкие" с изменением формата БД, то просится еще много тонн изменений — тогда это уже будет другая БД, которой нужно другое API, а еще все это нужно отладить, 100 раз проверить и стабилизировать...
💯
e
fiatjaf invited fiatjaf
f
17:07
fiatjaf
good morning, can I ask a question in English?
Л(
f
17:08
fiatjaf
on github.com/fiatjaf/eventstore I have basically the same code running with LMDB and MDBX, and my stupid benchmarks saying LMDB is 7x faster
Л(
f
17:09
fiatjaf
sorry for the horrible screenshot, it's on linux
17:11
you can run it with
go test ./test -run=Nothing -bench=MDBX -benchmem (yes, I forgot to mention it is using the golang bindings)
17:13
I didn't realize the insert benchmark was so much faster though, I don't understand why -- all the others are just reading
17:14
the reading is done using a convoluted query system I came up with that opens multiple iterators at the same time and iterates through them in small batches in order to fill a final slice of ordered results -- but the logic is exactly the same for LMDB and MDBX
Л(
17:17
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Yes, I'll look at it later.
There is always a chance that some small thing was broken during refactoring.
However, the main reasons for such results are usually that of:
- MDBX_SAFE_NOSYNC != MDB_NOSYNC;
- NDEBUG was not defined, i.e. assertion-checking is enabled.
There is always a chance that some small thing was broken during refactoring.
However, the main reasons for such results are usually that of:
- MDBX_SAFE_NOSYNC != MDB_NOSYNC;
- NDEBUG was not defined, i.e. assertion-checking is enabled.
f
17:27
fiatjaf
I'm not doing NOSYNC anywhere, but the NDEBUG one could be it?
17:29
hmm, looks like mdbx.go already defines -DNDEBUG=1, and I didn't change anything there, so that part should be ok?
17:32
ok, well, I'm not complaining about anything, I just wondered if I was missing some setting or I was doing something wrong.
I read a bunch of stuff about MDBX and parts of the manual, but couldn't find any information about anything that I should do differently than what I was doing with LMDB (I saw some differences, but they seem to be irrelevant to my use case)
I read a bunch of stuff about MDBX and parts of the manual, but couldn't find any information about anything that I should do differently than what I was doing with LMDB (I saw some differences, but they seem to be irrelevant to my use case)
Л(
17:32
Леонид Юрьев (Leonid Yuriev)
In reply to this message
I think so, but I can't confirm with certainty (needs to look).
17:36
In reply to this message
Closer to night (Moscow time) I'll run benchmarks myself and look at yours.
But right now I have to go find my cat. We have a snowstorm here.
Shortly: I heard you, please wait a few hours.
But right now I have to go find my cat. We have a snowstorm here.
Shortly: I heard you, please wait a few hours.
f
17:39
fiatjaf
ok, don't worry about me and thank you very much. good luck with the cat.
🤝
Л(
Vasiliy invited Vasiliy
Л(
22:49
Леонид Юрьев (Leonid Yuriev)
In reply to this message
I did a few checks and didn't notice any performance issues.
Tomorrow I will continue, but it is unlikely that I will find reasons in libmdbx clear the slowdown you are observing.
I guess it's about the bindings.
There are other use cases in Erigon — there are long huge transactions, but you have a lot of small ones.
So an overhead of starting and/or completing a transaction in Erigon is invisible, but in your case this can ruin performance (if I correctly understood your scenario).
I think it's better to consult with @AskAlexSharov.
Another minor problem is the version: the current libmdbx version is 0.13.2, but inside bindings I see the
Tomorrow I will continue, but it is unlikely that I will find reasons in libmdbx clear the slowdown you are observing.
I guess it's about the bindings.
There are other use cases in Erigon — there are long huge transactions, but you have a lot of small ones.
So an overhead of starting and/or completing a transaction in Erigon is invisible, but in your case this can ruin performance (if I correctly understood your scenario).
I think it's better to consult with @AskAlexSharov.
Another minor problem is the version: the current libmdbx version is 0.13.2, but inside bindings I see the
v0_12_9_16_gfff3fbd8.
f
23:03
fiatjaf
thank you for looking
23:04
well, my in my benchmarks each "run" is using a single transaction, so I think that can't be the reason, but I don't know
23:06
I don't know who made these bindings, they are the "official" erigon bindings I believe, and they seem to be based on the LMDB golang bindings also because the API is almost the same.
23:06
is it ok to bother @AskAlexSharov with this? is this in his interest?
Л(
23:09
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Reading the go code, it is difficult for me to reliably understand your scenario in terms of the libmdbx API.
I think it will be very useful if you describe in words what your benchmark does.
I think it will be very useful if you describe in words what your benchmark does.
23:12
In reply to this message
I think he's interested in making everything work well and quickly.
And since he knows GoLang-API much better than me, there is a chance that he will immediately points us to the problem is.
And since he knows GoLang-API much better than me, there is a chance that he will immediately points us to the problem is.
SD
23:13
Sayan J. Das
Let me distract for a bit.
Does MDBX use locks in write transactions, if I can guarantee that all writes will always happen from a single thread, and the process is in exclusive mode?
Is it possible and is there any benefit in disabling such locks?
Does MDBX use locks in write transactions, if I can guarantee that all writes will always happen from a single thread, and the process is in exclusive mode?
Is it possible and is there any benefit in disabling such locks?
Л(
23:22
Леонид Юрьев (Leonid Yuriev)
In reply to this message
In a whole picture the overhead of locking is insignificant, unless you are running a lot of a micro transactions.
On the other hand, disabling locks is quite dangerous and (as a rule) developers who have no experience and/or are looking for easy ways tend to do this. Accordingly (as a rule) it ends badly.
Therefore, I refused to support
Nonetheless, you can easily disable a write-transaction lock by making edits to your copy of the code.
On the other hand, disabling locks is quite dangerous and (as a rule) developers who have no experience and/or are looking for easy ways tend to do this. Accordingly (as a rule) it ends badly.
Therefore, I refused to support
MDB_NOLOCK mode, which is available in LMDB.Nonetheless, you can easily disable a write-transaction lock by making edits to your copy of the code.
👍
w
SD
23:26
In addition, for similar reasons, I also deliberately used file locks on Windows (which are quite slow there).
But this makes impossible to get a broken copy of a database by copying its file while the writing transaction is running.
But this makes impossible to get a broken copy of a database by copying its file while the writing transaction is running.
SD
23:32
Sayan J. Das
In reply to this message
It would be very helpful if u can point out the line number / function name where the lock is implemented
I can't seem to find it..
I can't seem to find it..
23:32
Or a Gitflic permalink
Л(
23:37
Леонид Юрьев (Leonid Yuriev)
In reply to this message
src/lck-posix.c line 827: const int err = osal_ipclock_lock(env, &env->lck->wrt_lock, dont_wait)src/lck-posix.c line 844: int err = osal_ipclock_unlock(env, &env->lck->wrt_lock);
❤
w
SD
23:43
In reply to this message
For Windows please dig the same functions
lck_txn_lock() and lck_txn_unlock() inside src/lck-windows.c
SD
23:44
Sayan J. Das
You are right, according to my benchmark, no lock makes almost no difference even for small transactions 🙂
🤝
Л(
17 December 2024
Zeke Mostov invited Zeke Mostov
ZM
03:59
Zeke Mostov
Hi! What ordering rules does the cursor iteration use?
AS
04:16
Alex Sharov
In reply to this message
1. db.extraFlags = mdbx.TxNoSync it’s flag of Tx, not DB.
2. If you will plan to do parallel small updates/inserts - then nee this pattern to increase throughput: https://github.com/etcd-io/bbolt?tab=readme-ov-file#batch-read-write-transactions
2. If you will plan to do parallel small updates/inserts - then nee this pattern to increase throughput: https://github.com/etcd-io/bbolt?tab=readme-ov-file#batch-read-write-transactions
f
04:19
fiatjaf
In reply to this message
thank you for looking, but:
1. the TxNoSync stuff confused me, but I didn't worry about it because it is not used in the benchmark, only on the tests, I was planning on taking a better look at all the flags later.
2. in all my benchmarks except the last one called "insert" I am only doing reads, no writes.
1. the TxNoSync stuff confused me, but I didn't worry about it because it is not used in the benchmark, only on the tests, I was planning on taking a better look at all the flags later.
2. in all my benchmarks except the last one called "insert" I am only doing reads, no writes.
04:23
In reply to this message
on every "run" of the benchmark I open a single mdbx readonly transaction, then I read from two different dbis: one is the chosen "index" for the query, the other is the dbi that holds the "raw" data, so I open something between 5 and 20 (it varies) cursors on the "index" and go through each of them in sequence, fetching like ~5 records from each, then for each of these I do one "get" operation on the "raw" dbi, then I do stuff with this data, then go back to the cursors and fetch more ~5 records from each and so on until I have all the results I need
AS
04:44
Alex Sharov
In reply to this message
I don’t know where is this benchmark - send me link.
Try to run it with pprof:
go tool pprof -png http://127.0.0.1:6060/debug/pprof/profile/?seconds\=20 > cpu.png
go tool pprof -alloc_objects -png http://127.0.0.1:6060/debug/pprof/heap?seconds\=20 > mem.png
Try to run it with pprof:
go tool pprof -png http://127.0.0.1:6060/debug/pprof/profile/?seconds\=20 > cpu.png
go tool pprof -alloc_objects -png http://127.0.0.1:6060/debug/pprof/heap?seconds\=20 > mem.png
AS
f
06:21
fiatjaf
In reply to this message
https://t.me/libmdbx/6574 it's here, http://github.com/fiatjaf/eventstore
you can run it with
you can run it with
go test ./test -run=Nothing -bench=MDBX -benchmem
06:23
thank you, I will try pprof tomorrow
AS
07:11
Alex Sharov
In reply to this message
in
master:-bench=LMDB does nil-ptr-bench=MDBX no such bench
SD
09:16
Sayan J. Das
Hi, it seems the
This might be my fault (due to some code changes I made), but regardless I would like to know more about this error code.
It is opened in EXCLUSIVE mode btw.
mdbx_env_open is returning a non-zero integer 11, which doesn't match with any defined error.This might be my fault (due to some code changes I made), but regardless I would like to know more about this error code.
It is opened in EXCLUSIVE mode btw.
СМ
09:17
Сергей Мирянов
11 (errno > 0) - system error
👍
w
SD
SD
09:22
Sayan J. Das
Interesting, it's the error code for
Database seems to work fine when starting new, but when the folder already exists,
EAGAIN.Database seems to work fine when starting new, but when the folder already exists,
mdbx_env_open throwing this error.
КА
09:25
Кемаль Ататюрк
does the folder being used by another process?
SD
09:35
Sayan J. Das
Nope, I suspect it's because some code changes I made is not properly calling
mdbx_env_close so the lock file is not "unlocked"
09:40
Yep, that was the issue.
КА
09:40
Кемаль Ататюрк
okay, nice
Л(
11:25
Леонид Юрьев (Leonid Yuriev)
In reply to this message
No.
libmdbx able to reliable recovery locks after process-owner unproperly terminates.
And there a lot of test for this.
Most likely IDE and/or debugger failed to terminate target process and/or ones leaves it a zobie.
libmdbx able to reliable recovery locks after process-owner unproperly terminates.
And there a lot of test for this.
Most likely IDE and/or debugger failed to terminate target process and/or ones leaves it a zobie.
SD
11:26
Sayan J. Das
In reply to this message
Yes, forgot to update: the process on Linux was running as zombie and I failed to notice. That was main reason for the error. 👍
11:27
(but in the process I also discovered a bug in my own code that doesn't properly call
mdbx_env_close)
🤝
Л(
f
Л(
12:51
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Got this.
Seems it is an extra-lightweight read-only case, without deep/heavy operations within a DB.
So an any overhead costs (e.g. cursor creation) may play a main role.
I think we need to deal with the situation and find out the reasons.
A few points for this:
1.
libmdbx performs MORE CHECKS (2-3 times more compared to LMDB) for parameters passed to API, internal states/signatures, DB structures, etc.
Thus, in a "doing nothing" and akin cases, libmdbx may be slightly slower (~1-5%) than LMDB.
2.
libmdbx implements different behavior for cursors than LMDB: all cursors my be reused, regardless of type and/or owned transaction, but ones should be closed explicitly.
Thus, the behavior of libmdbx is more uniform and (theoretically) should facilitate to fewer bugs.
However, sometimes this generates unexpected effects and performance degradations:
- internally libmdbx uses a single-linked lists to chaining cursors for tracking, etc.
- so releasing the cursor in a "unlucky" order will lead to a full scan such list, which is O(N) costly (the
3.
Present benchmark/tests covers DB operations, but did not a some lightweight cases like this, where an API overhead is significant.
So I will do fix this.
Seems it is an extra-lightweight read-only case, without deep/heavy operations within a DB.
So an any overhead costs (e.g. cursor creation) may play a main role.
I think we need to deal with the situation and find out the reasons.
A few points for this:
1.
libmdbx performs MORE CHECKS (2-3 times more compared to LMDB) for parameters passed to API, internal states/signatures, DB structures, etc.
Thus, in a "doing nothing" and akin cases, libmdbx may be slightly slower (~1-5%) than LMDB.
2.
libmdbx implements different behavior for cursors than LMDB: all cursors my be reused, regardless of type and/or owned transaction, but ones should be closed explicitly.
Thus, the behavior of libmdbx is more uniform and (theoretically) should facilitate to fewer bugs.
However, sometimes this generates unexpected effects and performance degradations:
- internally libmdbx uses a single-linked lists to chaining cursors for tracking, etc.
- so releasing the cursor in a "unlucky" order will lead to a full scan such list, which is O(N) costly (the
mdbx_txn_release_all_cursors() is for such cases).3.
Present benchmark/tests covers DB operations, but did not a some lightweight cases like this, where an API overhead is significant.
So I will do fix this.
👍
SD
❤
w
🆒
vH
f
13:33
fiatjaf
In reply to this message
should I do something to reuse these read txns? and somehow reuse their cursors too? would that improve things?
SD
16:54
Sayan J. Das
Is there a way to define a custom
For eg.
malloc and free function for use by mdbx?For eg.
#define MDBX_malloc mi_malloc (mimalloc)
16:55
Or, I can maybe override using a header file.
Overall, it's not unsafe to do so, right?
Overall, it's not unsafe to do so, right?
SD
17:49
Sayan J. Das
#define osal_malloc malloc
#define osal_calloc calloc
#define osal_realloc realloc
#define osal_free free
These seem to be the correct flags
Л(
19:09
Леонид Юрьев (Leonid Yuriev)
In reply to this message
1. Yes, you can do this, but should care about
malloc_usable_size() too.
SD
19:10
Sayan J. Das
Yep, I just got it working this very second, after fixing error related to usable_size
19:10
But I didn't override any of the
osal_ defines, instead used mimalloc-overrides.h which overrides the platform malloc functions
19:14
Had to change
to
Otherwise was facing an error
mi_decl_nodiscard mi_decl_export size_t mi_usable_size(const void* p) mi_attr_noexcept;
to
mi_decl_nodiscard mi_decl_export size_t mi_usable_size(void* p) mi_attr_noexcept;
Otherwise was facing an error
error: conflicting types for 'malloc_usable_size'
Л(
19:14
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Oh, however, this makes little sense ;)
To avoid unnecessary allocations, just a read transactions and cursors should be reused.
libmdbx already does everything else (it is enough to use the API optimally).
For debugging/sanity Valgrind and ASAN should be used.
To avoid unnecessary allocations, just a read transactions and cursors should be reused.
libmdbx already does everything else (it is enough to use the API optimally).
For debugging/sanity Valgrind and ASAN should be used.
SD
19:16
Sayan J. Das
In reply to this message
Actually, main reason is I switched my database from default Zig's
c_allocator to mimalloc, and don't want MDBX to be using a different allocator (glibc).
19:17
Sounds more "safe", although you would know better :)
Л(
19:27
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Oh, actually it is a no-op mostly:
- glibc uses it own malloc/free any way.
- libmdbx don't return anything which should be released/free externally, and don't accept such parameters.
- therefore, the glibc' allocator will still be active, and the behavior of libmdbx will only change if the new allocator will a nightmare.
So nothing will be changes, but in the worst case, you may get problems due to the oddities of a new allocator.
- glibc uses it own malloc/free any way.
- libmdbx don't return anything which should be released/free externally, and don't accept such parameters.
- therefore, the glibc' allocator will still be active, and the behavior of libmdbx will only change if the new allocator will a nightmare.
So nothing will be changes, but in the worst case, you may get problems due to the oddities of a new allocator.
👍
SD
SD
19:33
Sayan J. Das
In reply to this message
All great points 🙂
So, I'll not use
but continue to use
So, I'll not use
mimalloc for MDBX, as my benchmark also indicates no improvement (like you said)but continue to use
mimalloc in Zig
18 December 2024
Л(
01:12
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Cursor steps forward/backward over a keys, which are in sort order.
Please RTFM instead of asking questions with obvious answers.
Please RTFM instead of asking questions with obvious answers.
ZM
01:50
Zeke Mostov
In reply to this message
I'm aware of that. But the docs don't cover the ordering rules of iteration
Q ZZZ invited Q ZZZ
АК
07:35
Алексей (Keller) Костюк 😐
@erthink доброе утро. Есть вопросик... Почему БД блокируется, пока идёт запись, тем самым, когда я её пытаюсь открывать в новом процессе, приходится ждать, пока закончится запись...
Такая фича была и у LMDB, но я тупо ставил NO_LOCK, ибо всё равно открываю только на чтение... Но всё же, как с этим можно справится?
Такая фича была и у LMDB, но я тупо ставил NO_LOCK, ибо всё равно открываю только на чтение... Но всё же, как с этим можно справится?
07:39
И ещё, что это значит?)
Deleted invited Deleted Account
Л(
10:09
Леонид Юрьев (Leonid Yuriev)
In reply to this message
MDBX (как и LMDB) основывается на подходе "один писатель".
Это позволяет использовать один мьютекс вместо массы дорогих сложных блокировок и получить полную сериализацию транзакций.
Поэтому в каждый момент времени может быть не более одной пишущей транзакции.
Однако выполняющаяся транзакция не мешает запускать пишущие и/или открыть БД в другом процессе.
Если у вас по как-то причине при открытии БД в приложении запускаетсячитающая пишущая транзакция, то в этой точке приложение будет блокировать до завершения уже выполняющейся транзакции. В LMDB примерно также.
Работа без блокировок в MDBX не поддерживается, этот режим (флажок
По этому поводу, с пояснением причин, отвечал вчера (см. сообщения в группе).
Это позволяет использовать один мьютекс вместо массы дорогих сложных блокировок и получить полную сериализацию транзакций.
Поэтому в каждый момент времени может быть не более одной пишущей транзакции.
Однако выполняющаяся транзакция не мешает запускать пишущие и/или открыть БД в другом процессе.
Если у вас по как-то причине при открытии БД в приложении запускается
Работа без блокировок в MDBX не поддерживается, этот режим (флажок
MDB_NOLOCK) удален.По этому поводу, с пояснением причин, отвечал вчера (см. сообщения в группе).
10:23
In reply to this message
Если я правильно понимаю, то тут система вернула код ошибки
Возможные причины:
- у системы СЕЙЧАС нет ресурсов чтобы выполнить системный вызов, например mmap() или open() при открытии БД.
- некий ресурс временно заблокирован и операцию можно попробовать повторить.
EAGAIN=11.Возможные причины:
- у системы СЕЙЧАС нет ресурсов чтобы выполнить системный вызов, например mmap() или open() при открытии БД.
- некий ресурс временно заблокирован и операцию можно попробовать повторить.
Л(
12:00
Леонид Юрьев (Leonid Yuriev)
In reply to this message
В API добавлена функция mdbx_cursor_count_ex(), т.е. теперь можно получить информацию о страницах во вложенном dupsort-дереве.
12:07
Небольшая просьба:
Вверху ChangeLog есть ссылки на online переводчики Google и Yandex.
Перевод посредством Yandex у меня сейчас не работает из-за "Не удалось найти IP-адрес сервера translated.turbopages.org" и есть подозрение что это локальная проблема.
Просьба проверить перевод яндексом и ответить здесь.
Вверху ChangeLog есть ссылки на online переводчики Google и Yandex.
Перевод посредством Yandex у меня сейчас не работает из-за "Не удалось найти IP-адрес сервера translated.turbopages.org" и есть подозрение что это локальная проблема.
Просьба проверить перевод яндексом и ответить здесь.
b
12:12
basiliscos
у меня там пустая страница показывается (из РБ)
Л(
12:16
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Ох, это уже GitFlic шалит.
Видимо придется переезжать — постоянные глюки самых разных мастей, и уже несколько лет не хотят чинить редактор markdown (хотя-бы просто дать painnext вместо текущего глюкала).
@kozmasX, fyi
Видимо придется переезжать — постоянные глюки самых разных мастей, и уже несколько лет не хотят чинить редактор markdown (хотя-бы просто дать painnext вместо текущего глюкала).
@kozmasX, fyi
A
12:18
Aleksandr Druzhinin
мне кажется тут дело в переводчике. в нем показывает пустую страницу, а напрямую gitflic все показывает
Л(
b
12:38
basiliscos
yep
👍
Л(
A
Gabriel invited Gabriel
Л(
14:54
Леонид Юрьев (Leonid Yuriev)
Gabriel, Hi!
Sorry, I don't work with C#, so I don't have my own bindings for dotNet. In particular, I do not have the opportunity to develop, maintain or search for ready-made ones on the Web.
Alas, here you will have to rely on your own strength or ask for help from the members of this group.
I think you need to accept the inevitable and learn how to build libmdbx for Windows yourself.
In fact, it's really simple and I'm sure there are ready-made examples of connecting/using CMake projects in dotNet projects are on the Network.
I do not keep records of projects using libmdbx, but it is for sure that libmdbx is used in Ethereum (Eragon, Silkworm, Akula, Reth) and several commercial products of Positive Technologies.
The CI is running for Linux, Windows, MacOS, Android, iOS.
The long-running stochastic tests are on Linux is mostly, but also on Windows.
Tests on FreeBSD, DragonFly, Solaris, OpenSolaris, OpenIndiana, NetBSD, OpenBSD, etc are done on request / necessity, in fact rarely.
I've found the .so and .dll libraries for LMDB in decent versions on the internet. I haven't found this library for libmdbx. There is an old version found in an .Net binding, but it seems to be obsolete.
Sorry, I don't work with C#, so I don't have my own bindings for dotNet. In particular, I do not have the opportunity to develop, maintain or search for ready-made ones on the Web.
Alas, here you will have to rely on your own strength or ask for help from the members of this group.
Should you compile the latest version of lmdx for each platform, or at least Windows and Linux, and add it to a repository somewhere ?
I think you need to accept the inevitable and learn how to build libmdbx for Windows yourself.
In fact, it's really simple and I'm sure there are ready-made examples of connecting/using CMake projects in dotNet projects are on the Network.
Do you use it in production ?
I do not keep records of projects using libmdbx, but it is for sure that libmdbx is used in Ethereum (Eragon, Silkworm, Akula, Reth) and several commercial products of Positive Technologies.
Which platforms have you deeply tested ?
The CI is running for Linux, Windows, MacOS, Android, iOS.
The long-running stochastic tests are on Linux is mostly, but also on Windows.
Tests on FreeBSD, DragonFly, Solaris, OpenSolaris, OpenIndiana, NetBSD, OpenBSD, etc are done on request / necessity, in fact rarely.
👍
G
АК
16:25
Алексей (Keller) Костюк 😐
In reply to this message
Но почему так? Если данные пишутся, то они пишутся в "слепок". По идее это не должно мешать взять и открыть предыдущий слепок. Тем более, что я во втором процессе открываю бд только для чтения. Так почему происходит блокировка, если открытие только для чтения?
16:32
Ещё бы получение информации из gc о свободных страницах без перекопирования цикла (при аргументе -f) из ./mdb_stat, и было бы замечательно :))))))
Л(
16:32
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Хм, а вы точно прочитали мой ответ ?
MDBX обеспечивает lockfree для читателей, точнее говоря блокировка требуется только при регистрации треда, а при использовании
Поэтому то что вы хотите работает "из каробки", буквально.
А если не работает, то видимо причина в вашем коде.
MDBX обеспечивает lockfree для читателей, точнее говоря блокировка требуется только при регистрации треда, а при использовании
MDBX_NOSTICKYTHREADS при первом использовании _инстанции_ читающей транзакции (сам объект транзакции связан со слотом в таблице читателей, но может быть переиспользован без блокировок).Поэтому то что вы хотите работает "из каробки", буквально.
А если не работает, то видимо причина в вашем коде.
АК
16:56
Алексей (Keller) Костюк 😐
Получается только во время регистрации блокировка... Печалька, придётся ждать завершения...
Просто у меня сейчас на фоне запущена "миграция", а то я плохо спроектировал данные для бд. Я ещё начал на LMDB мигрировать, но там как раз и захлебнулась она в большом количестве FREELIST.
Ну а пока идёт вставка в бд, я сейчас постепенно переписываю проект под MDBX... Вот и приходится постоянно перезапускать процесс, который открывает бд только для чтения. А так как у меня коммит миграции только раз в минуту, то приходится ждать...
Просто у меня сейчас на фоне запущена "миграция", а то я плохо спроектировал данные для бд. Я ещё начал на LMDB мигрировать, но там как раз и захлебнулась она в большом количестве FREELIST.
Ну а пока идёт вставка в бд, я сейчас постепенно переписываю проект под MDBX... Вот и приходится постоянно перезапускать процесс, который открывает бд только для чтения. А так как у меня коммит миграции только раз в минуту, то приходится ждать...
Л(
16:59
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Так нет же, не должно быть блокировки. У вас что-то не так.
Регистрация — это очень короткая процедура, моментальная. Там нечему блокироваться.
Регистрация — это очень короткая процедура, моментальная. Там нечему блокироваться.
АК
17:02
Алексей (Keller) Костюк 😐
In reply to this message
Процесс 1:
Открывает write транзакцию. Пишет в течении минуты данные и коммитит их
Процесс 2:
Иногда запускается как read-only. Однако ждёт, пока процесс 1 не сделает коммит
Открывает write транзакцию. Пишет в течении минуты данные и коммитит их
Процесс 2:
Иногда запускается как read-only. Однако ждёт, пока процесс 1 не сделает коммит
17:02
Я перепроверю конечно, ещё раз, что может быть не так
АК
18:22
Алексей (Keller) Костюк 😐
In reply to this message
Да вы правы, спасибо... Readonly я всё-таки не передал))
🤝
Л(
Катя invited Катя
G
18:58
Gabriel
In reply to this message
Thank you very much !
For the compiled lib, I'm looking for an already compiled Windows and Linux, as you probably compile it in your CI (in Release mode, with all optimizations, ready to integrate in a C / C++ project).
In .Net, using C#, I have my own native to managed interop library for LMDB : it may be easy to create it for libmdbx, opening directly the C library ".dll" under windows, ".so" under Linux.
For the compiled lib, I'm looking for an already compiled Windows and Linux, as you probably compile it in your CI (in Release mode, with all optimizations, ready to integrate in a C / C++ project).
In .Net, using C#, I have my own native to managed interop library for LMDB : it may be easy to create it for libmdbx, opening directly the C library ".dll" under windows, ".so" under Linux.
Л(
19:58
Леонид Юрьев (Leonid Yuriev)
In reply to this message
1. It's not difficult for me to give you a "caught fish", but at least once try to catch it yourself, because the "fishing rod" is at your fingertips.
2. I think creating such a clone is not the best idea.
On the contrary, I am sure that it is fundamentally better to re-create/re-write the modern C++ API in C#.
2. I think creating such a clone is not the best idea.
On the contrary, I am sure that it is fundamentally better to re-create/re-write the modern C++ API in C#.
G
21:14
Gabriel
1) Ok, I will download the repo and try to rebuild the libs on Windows first, and on Linux next. May take few hours, I hope, perhaps days.
2) Yes, It is possible that your C++ wrapper is more efficient / secure, yeah. There is 3 layers :
- the pure technical binding between managed .Net world and native C methods : it is a needed thin layer that retreive methods pointer offsets, and for each methods convert params values from the managed stack to the C format stack (Cdecl) to be able to call each method and catch returned values.
- a C# class library that implement all concepts, and manage lifetime of all of the libmdbx elements (Evironement, Trasaction, Cursor...) taking care of Garbage Collector for non deterministic release of classes instances.
- The "database" layer, which permit to store / retreive objects using an high level API : this is where the advanced features are organized, like tables, indexes, tracking of modifications, migrations, schema record, etc.
I must be able to compile it, first...
2) Yes, It is possible that your C++ wrapper is more efficient / secure, yeah. There is 3 layers :
- the pure technical binding between managed .Net world and native C methods : it is a needed thin layer that retreive methods pointer offsets, and for each methods convert params values from the managed stack to the C format stack (Cdecl) to be able to call each method and catch returned values.
- a C# class library that implement all concepts, and manage lifetime of all of the libmdbx elements (Evironement, Trasaction, Cursor...) taking care of Garbage Collector for non deterministic release of classes instances.
- The "database" layer, which permit to store / retreive objects using an high level API : this is where the advanced features are organized, like tables, indexes, tracking of modifications, migrations, schema record, etc.
I must be able to compile it, first...
🤝
Л(
Л(
23:07
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Some clarification for a "database" layer.
libmdbx is a key-value storage, so no indices here.
With the exception that each key-value table (actually a key-to-value mapping) can be treated as a primary clustered index.
The main problem with indexes (actually secondary indexes) is a tuples with type system is needed.
Tuples imply some specific serialization format, which should be convenient, compact, and high-performance.
Next, with tuples, there are issues of representing NIL/NULL values, reducing the cost of serialization/deserialization, quick read access to the fields, and the effectiveness of modification operations.
--
All the tuple implementations that I have seen had at least one (imho significant) drawback.
So I made my own tuples.
However, it turned out that few people understand how they work, and many of my colleagues were embarrassed to admit ones ;)
Therefore, on the one hand, I would advise you not to mess with all this, but to concentrate on convenient operations with buffers and slices (there are corresponding classes in the C++ API).
On the other hand, if you will still think about tuples and secondary indexes, then don't forget to look at my tuples ;)
Here is the link with the machine translation.
libmdbx is a key-value storage, so no indices here.
With the exception that each key-value table (actually a key-to-value mapping) can be treated as a primary clustered index.
The main problem with indexes (actually secondary indexes) is a tuples with type system is needed.
Tuples imply some specific serialization format, which should be convenient, compact, and high-performance.
Next, with tuples, there are issues of representing NIL/NULL values, reducing the cost of serialization/deserialization, quick read access to the fields, and the effectiveness of modification operations.
--
All the tuple implementations that I have seen had at least one (imho significant) drawback.
So I made my own tuples.
However, it turned out that few people understand how they work, and many of my colleagues were embarrassed to admit ones ;)
Therefore, on the one hand, I would advise you not to mess with all this, but to concentrate on convenient operations with buffers and slices (there are corresponding classes in the C++ API).
On the other hand, if you will still think about tuples and secondary indexes, then don't forget to look at my tuples ;)
Here is the link with the machine translation.
SD
23:30
Sayan J. Das
In reply to this message
Actually, I read a lot about your tuples library a few days ago while decided which serialization format to use for my database.
But the fact that there is no nested keys (like JSON) made me decide against it, as I am building a "document database". Regardless, I'm sure fptu is insanely fast, which justifies it's design decisions :)
But the fact that there is no nested keys (like JSON) made me decide against it, as I am building a "document database". Regardless, I'm sure fptu is insanely fast, which justifies it's design decisions :)
👍
Л(
23:32
I ended up choosing MessagePack (
A big problem is it's not "zero-copy" deserialization which is a perfect use-case for memory mapped DBs like LMDB/MDBX.
mpack C library) because it supports JSON-like documents and is pretty fast (few microseconds to parse and encode).A big problem is it's not "zero-copy" deserialization which is a perfect use-case for memory mapped DBs like LMDB/MDBX.
👍
VS
Л(
23:43
Леонид Юрьев (Leonid Yuriev)
In reply to this message
I have some ideas on how to solve the problems that arise. In particular, to provide the possibility of replacing/customizing the type system and a specific serialization format.
However, (yet?) I did not find a convenient API form in C++ terms that would be convenient and at the same time make it easy to describe the scheme (preferably without a separate code generator and/or IDL).
Some time ago, I intended to think about this with an eye on Rust or intensive use of C++20/23 (consteval, etc.).
However, I postponed it, since the result was not in demand in any particular project (and without this, any solution would be rotten).
However, (yet?) I did not find a convenient API form in C++ terms that would be convenient and at the same time make it easy to describe the scheme (preferably without a separate code generator and/or IDL).
Some time ago, I intended to think about this with an eye on Rust or intensive use of C++20/23 (consteval, etc.).
However, I postponed it, since the result was not in demand in any particular project (and without this, any solution would be rotten).
👍
e
G
23:46
Gabriel
Exactly. My "database engine" is not copying data, it read fields of flat DTO objects directly in the LMDB memory space !
If you read a field "city" in a "customer" object stored in LMDB, i MUST NOT copy the whole binary data, unpack (or deserialize it), and read the field "city" : i have to get the pointer of the binary block, compute the offset to get the "city" string. This is the only way to get the REAL performances that are provided by LMDB !
This is what I've done with LMDB with .Net C# managed langage, with a large code base to generate code that manage sub single block of memory allocation : and because the memory allocations are far lower than with classical "pointer for each string or array" approach, it is faster than native C# objects.
If you read a field "city" in a "customer" object stored in LMDB, i MUST NOT copy the whole binary data, unpack (or deserialize it), and read the field "city" : i have to get the pointer of the binary block, compute the offset to get the "city" string. This is the only way to get the REAL performances that are provided by LMDB !
This is what I've done with LMDB with .Net C# managed langage, with a large code base to generate code that manage sub single block of memory allocation : and because the memory allocations are far lower than with classical "pointer for each string or array" approach, it is faster than native C# objects.
Л(
23:47
Леонид Юрьев (Leonid Yuriev)
In reply to this message
I think you should also look at the implementation of tuples inside the tarantool.io source code.
Basically there is msgpack too, but with a simple index that gives a very significant acceleration.
Basically there is msgpack too, but with a simple index that gives a very significant acceleration.
✍
e
👍
СМ
🙏
e
G
23:48
Gabriel
Non, it will be very slower than compute an addition on the pointer to get each fields. This is what I'm doing, and nothing can be faster. Nothing.
23:51
The hard work is to make Programmer Friendly. In my system, developpers use T4 files to generate classes that manage all the unmanaged native pointers magics, and manage the situation where the pointer is alone, un an memory mapped file, in LMDB memory space, etc. All transparently for the developper. The system manage implicite version migration...
👍
Л(
SD
23:53
Sayan J. Das
Well, my current use case would ideally benefit from a format that:
- Is self-describing (format is not known at compile time, only during runtime, may be different for many objects), field names must be present in the binary format
- Fast seeks to desired field, might be nested deep
- Can read value directly from the buffer, no de-serialization required
- On-disk format should be CPU architecture independent
- Update only desired field without a big serialization step
- Is self-describing (format is not known at compile time, only during runtime, may be different for many objects), field names must be present in the binary format
- Fast seeks to desired field, might be nested deep
- Can read value directly from the buffer, no de-serialization required
- On-disk format should be CPU architecture independent
- Update only desired field without a big serialization step
G
23:53
Gabriel
Here an sample :
Definition => Usage like any other object => insert in a LMDB based repository
Definition => Usage like any other object => insert in a LMDB based repository
👍
Л(
Л(
23:54
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Just for clarity - noted tuples are for a case you have a 1000M rows with 100 fields each, so you need 1000M*100*8 bytes to store (only) a pointers for a these fields.
SD
G
23:55
Gabriel
Yeah ! You contraints (self descriptive) are too high for static definition like I've done...
👍
SD
SD
23:58
Sayan J. Das
In reply to this message
I have tried to write a custom format for this, but the performance might be similar to MessagePack at this point 😂
19 December 2024
G
00:00
Gabriel
Your use case is really hard ! My use case is for relationnal-like data store, like an SQL serveur, but where tables are object collection of the same type. I call it "Object Repository". The schema is staticly defined, so it is really different and code generation fit perfectly. I have only to store the type identifier and version for each object.
👍
Л(
SD
00:01
Thank you for all this informations !
Л(
00:05
Леонид Юрьев (Leonid Yuriev)
In reply to this message
the trick = try to benchmark/profile your code on CPU without branch-prediction, optimize/tune it, and then you got 200% on modern cores.
👍
SD
АК
01:57
Алексей (Keller) Костюк 😐
@erthink Леонид, ещё раз здравствуйте. Возникла проблема с открытием бд в нескольких потоках. MDBX_NOSTICKYTHREADS также не помогает. Знаю, что есть mdbx_env_resurrect_after_fork(), но как-то не нашёл примера использования... Но видимо он вызывается вместо mdbx_env_open(). А как оно тогда поймёт, какую бд открыть, если у меня в дочернем открывается, например две?
01:57
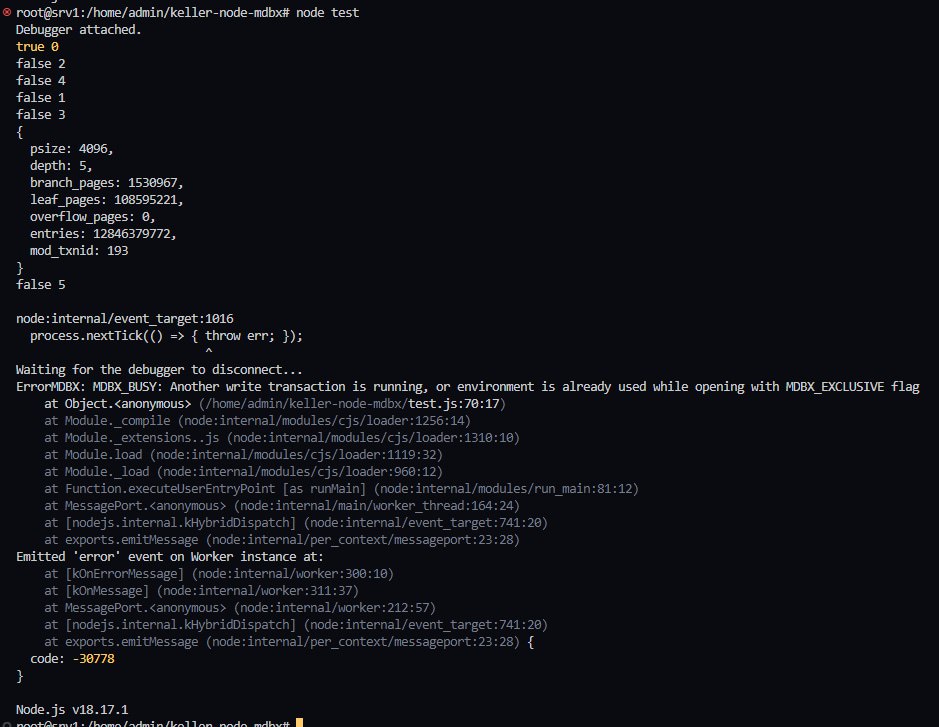
Л(
01:59
Леонид Юрьев (Leonid Yuriev)
In reply to this message
БД нельзя открывать в одном процессе более одного раза.
RTFM и спокойной ночи ;)
RTFM и спокойной ночи ;)
😁
b
雕 沙 invited 雕 沙
Л(
11:59
Леонид Юрьев (Leonid Yuriev)

AI imaginations of libmdbx, just for fun ;)
🔥
e
VS
b
6
11:59

11:59

11:59

11:59

12:04
In reply to this message
mdbx_env_resurrect_after_fork() в качестве аргумента принимает указатель на экземпляр MDBX_env, который необходимо "воскресить" в дочернем процессе после вызова fork(). Но это не имеет никакого отношения ни к повторному открытию БД, ни к использованию БД из нескольких потоков.
АК
13:03
Для жс смог придумать только один костыль, в виде сохранение ссылок на env где-то глобально на плюсах. А после по пути к файлу получать уже открытые... Ибо а жс я хз как между потоками иначе можно передать env. Только если путь к файлу могу по std передать...
Л(
13:07
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Посмотрите Deno и рядом с ним.
Там где-то даже бингинги были, вроде-бы рабочие (но автор разочаровался, так как у него под windows на мелких транзакциях mdbx работала медленнее lmdb).
Там где-то даже бингинги были, вроде-бы рабочие (но автор разочаровался, так как у него под windows на мелких транзакциях mdbx работала медленнее lmdb).
АК
13:09
Алексей (Keller) Костюк 😐
In reply to this message
Я видел все биндинги под жс... Мне ничего не понравилось. Поэтому и пришлось с нуля сейчас всё сделать самому с теми функциями, которые мне нужны.
Там в тех библиотеках к слову тоже нету работы в многопотоке
Там в тех библиотеках к слову тоже нету работы в многопотоке
Л(
13:14
Леонид Юрьев (Leonid Yuriev)
In reply to this message
В языках/средах_выполнения с подобной идеономикой, как правило, реализуется некий глобальный статический каталог.
В случае в mdbx вы можете именно так и поступить — помещать в него открытые экземпляры БД используя канонизированный полный путь к БД как ключ.
В случае в mdbx вы можете именно так и поступить — помещать в него открытые экземпляры БД используя канонизированный полный путь к БД как ключ.
АК
СМ
АК
13:16
Алексей (Keller) Костюк 😐
In reply to this message
На данный момент, чтобы хотя бы проверить работу на проекте, заюзал setup_debug legacy multiopen... Вполне тоже неплохо, хотя и понимаю, что не правильно
👍
Л(
G
16:34
Gabriel
Hi. I reach the goal to compile all (amalgame version) with CMake on Windows, both for win and linux. Cool. Now, I have to wire the interop. WIP
One question about MDBX vx LMDB : using LMDB, in production, when a Read transaction is still openned for a long time, the file is rapidly inflating at a size where the file is N times the size of the real stored binaries. I read that you have enhanced the code to make the size goes down to the necessary size :
- is this true ? If I remove all data (with no concurrent Read Tnx opened), the file size will go down to the "empty" size ?
If true :is there a procedure to "compact" all the data in one single transaction ?
Using LMDB, I've started to create a virtualization of a periodic copy of the store, to make it deflated and compacted transparently from user point of view (or developper point of view), at runtime, in paralelle of the
One question about MDBX vx LMDB : using LMDB, in production, when a Read transaction is still openned for a long time, the file is rapidly inflating at a size where the file is N times the size of the real stored binaries. I read that you have enhanced the code to make the size goes down to the necessary size :
- is this true ? If I remove all data (with no concurrent Read Tnx opened), the file size will go down to the "empty" size ?
If true :is there a procedure to "compact" all the data in one single transaction ?
Using LMDB, I've started to create a virtualization of a periodic copy of the store, to make it deflated and compacted transparently from user point of view (or developper point of view), at runtime, in paralelle of the
16:37
Using LMDB, I've started to create a virtualization of a periodic copy of the store, to make it deflated and compacted transparently from user point of view (or developper point of view), at runtime, in paralelle of the work. It is really hard because at a given time I have to switch to the new DB, store writes in a buffer journal to apply changes to the copy before swap to the new DB, well... a machinery to work around the perpetual inflation of the file size.
Is Libmdbx can help ?
Is Libmdbx can help ?
Л(
17:04
Леонид Юрьев (Leonid Yuriev)
In reply to this message
1.
Please read the Restrictions and Caveats section.
I hope it will become a little clearer to you what is happening under the hood and why such difficulties arise.
2.
When you remove at all in some transaction DB could be reached to a "zero-length" because:
- your transaction just create the new MVCC snapshot which comes visile AFTER successufll commit.
- but until this commit the previously (actually there current DB state) MVCC snapshot MUST be alive and untouched.
- so committing a "remote all" transaction just make available previously used space to be reclaimed (assuming no any readers use it).
3.
libmdbx provides "Automatic continuous zero-overhead database compactification" (see README).
Just "during each commit libmdbx merges a freeing pages which adjacent with the unallocated area at the end of file, and then truncates unused space when a lot enough of".
So this feature is mostly zero-cost, but such compactification always stops on a last used page, and such "detent" last page can remain in use indefinitely (at least until the data located in it will changed or deleted).
4.
libmdbx provides
But for now don't provide API to expcilit inplace defragmentation/compactification.
Such an API is planned for implementation.
Algorithmically, (simplify) we need to go through the b-tree and execute page_touch() for some of the pages close to the last used page.
Please read the Restrictions and Caveats section.
I hope it will become a little clearer to you what is happening under the hood and why such difficulties arise.
2.
When you remove at all in some transaction DB could be reached to a "zero-length" because:
- your transaction just create the new MVCC snapshot which comes visile AFTER successufll commit.
- but until this commit the previously (actually there current DB state) MVCC snapshot MUST be alive and untouched.
- so committing a "remote all" transaction just make available previously used space to be reclaimed (assuming no any readers use it).
3.
libmdbx provides "Automatic continuous zero-overhead database compactification" (see README).
Just "during each commit libmdbx merges a freeing pages which adjacent with the unallocated area at the end of file, and then truncates unused space when a lot enough of".
So this feature is mostly zero-cost, but such compactification always stops on a last used page, and such "detent" last page can remain in use indefinitely (at least until the data located in it will changed or deleted).
4.
libmdbx provides
mdbx_env_copy() and friends functions to make online backup/copy with optional compactification.But for now don't provide API to expcilit inplace defragmentation/compactification.
Such an API is planned for implementation.
Algorithmically, (simplify) we need to go through the b-tree and execute page_touch() for some of the pages close to the last used page.
СМ
17:08
Сергей Мирянов
In reply to this message
mdbx_env_copy + MDBX_CP_COMPACT works well for me - it shrinks DB a lot.
👍
G
AS
17:17
Alex Sharov
In reply to this message
Иногда действительно кажется что из экрана на меня бросится.
С новым годом.
С новым годом.
😁
Л(
20 December 2024
L
16:42
Lazymio
How is libmdbx python binding going
АК
23:15
Алексей (Keller) Костюк 😐
In reply to this message
Здравствуйте. Могу ли узнать, ваша библиотека есть в открытом доступе?
СМ
23:17
Сергей Мирянов
Добрый день, нет, в открытом доступе ее нет. И так получилось что изначальные биндинги превратились в довольно тонкий слой над libmdbx , внутри большей системы.
👍
АК
21 December 2024
АК
00:18
Алексей (Keller) Костюк 😐
@erthink доброй ночи. Можно ли использовать shared_ptr для env? И через .get() его подставлять везде, где он нужен? Просто close() будет использовать в разных потоках JS... Поэтому считаю, что лучше закрывать env тогда, когда все потоки JS у себя закроют... А это думаю лучше подсчитывать через ссылки shared_ptr...
Или я слишком мудрю?
Или я слишком мудрю?
Л(
00:23
Леонид Юрьев (Leonid Yuriev)
In reply to this message
1.
Лучше используйте C++ API. Хотя-бы поймите что там и как.
2.
Использовать shared_ptr вы конечно можете, но в 99% случаев это заканчивается false sharing и жутчайшими накладными расходами, от которых можно избавится только переписав весь код.
Лучше используйте C++ API. Хотя-бы поймите что там и как.
2.
Использовать shared_ptr вы конечно можете, но в 99% случаев это заканчивается false sharing и жутчайшими накладными расходами, от которых можно избавится только переписав весь код.
00:24
In reply to this message
Еще советую посмотреть как семантика владения реализована в привязках Rust и поговорить об этом с @vorot93.
🫡
AV
АК
00:30
Алексей (Keller) Костюк 😐
In reply to this message
Я как начинал делать биндинги и правда хотел использовать его... Но у меня правда не удалось разобраться как там всё... Для обычного апи хоть можно найти примеры использования в утилитах, а тут никак( Может быть я смог бы, если бы был опыт в С++... Но знаком с ним только вот на LMDB, Napi, MDBX...
Л(
00:37
Леонид Юрьев (Leonid Yuriev)
In reply to this message
В плюсовом API меньше десятка (по-сути 5) классов, вы потратьте хотя-бы час "тупо" на чтение доки.
00:41
Если честно, то меня всегда удивляет, как люди "жрут кактус" (ну почти буквально) и пишут парсеры на
Но упрямо игнорируют элементарно удобные и простые вещи ;)
boost::spirit или что-то мутят на wave...Но упрямо игнорируют элементарно удобные и простые вещи ;)
АК
АК
03:23
поставил брейк. Оно два раза вызывается. Первый во время открытия (но всё ок), второй во время закрытия и получаю это
03:24
Код если что (закрытие выполняется сборщиком мусора)
03:30
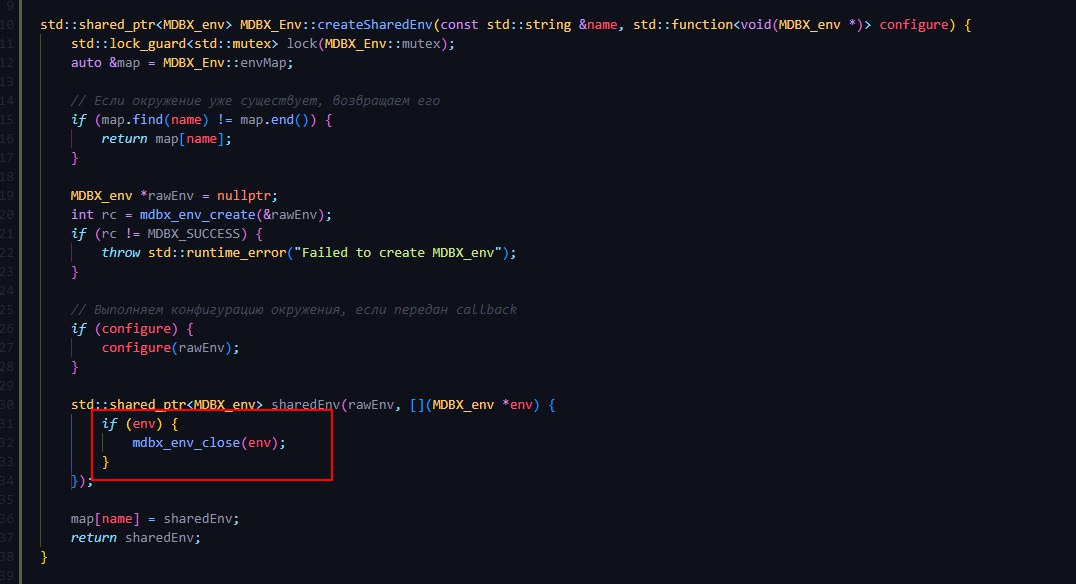
L
Л(
08:41
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Что у вас происходит в точности понять сейчас нельзя. Для это нужны полные стеки вызовов, причем как вашего JS-кода, так и нативного "сишного" выше и ниже JS.
Ассерт-проверка срабатывает из-за того то при удалении TLS-ключа выясняется что его нет, т.е. он уже был удален.
TLS в данном случае означает Thread Local Storage, т.е. это место где хранятся экземпляры переменных связанных с каждым конкретным потоком выполнения, причем поток выполнения тут строго нативный, т.е. именно сишный thread.
Наиболее вероятная причина в том, что сборщик мусора начинает вызывать деструкторы объектов (и вызывает
Ассерт-проверка срабатывает из-за того то при удалении TLS-ключа выясняется что его нет, т.е. он уже был удален.
TLS в данном случае означает Thread Local Storage, т.е. это место где хранятся экземпляры переменных связанных с каждым конкретным потоком выполнения, причем поток выполнения тут строго нативный, т.е. именно сишный thread.
Наиболее вероятная причина в том, что сборщик мусора начинает вызывать деструкторы объектов (и вызывает
mdbx_env_close()) уже после того как отработал глобальный деструктор libmdbx, вызываемый системой на уровне ABI разделяемых библиотек. Другими словами, скорее всего у вас mdbx_env_close() вызывается как-бы после выгрузки libmdbx.dll, т.е. после отработки вызова DllMain(DLL_PROCESS_DETACH) и отработки`mdbx_fini()`.
АК
16:04
Алексей (Keller) Костюк 😐
In reply to this message
Скорее всего... Но я уже переписал на чуть более другой вариант, чтобы закрывалось путём сборщика мусора V8, а не С++
L
17:17
Lazymio
In reply to this message
https://pypi.org/project/libmdbx/0.1.1/
Revive! This contains wheels for Linux, macOS and Windows and passes all original tests.
I will continue working on it, mostly to support more pythonnic api like
Update: 0.1.1 fixes missing wheels and sdist.
Revive! This contains wheels for Linux, macOS and Windows and passes all original tests.
I will continue working on it, mostly to support more pythonnic api like
with Env(...) as env etcUpdate: 0.1.1 fixes missing wheels and sdist.
👍
e
СМ
Л(
Л(
17:36
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Great!
Thank you!
Some tips/suggestions from me:
1. Use the
2. On Windows, it is better to use widechar-versions of path-related functions, otherwise multiple transcoding will occur, which usually creates a lot of problems.
3. The C API is inherited from LMDB and has quite a lot of oddities and inconveniences. Therefore, it is better to strive to reproduce the C++ API in any bindings.
Thank you!
Some tips/suggestions from me:
1. Use the
master branch for development, rather that stable (which is for support already-in-production project).2. On Windows, it is better to use widechar-versions of path-related functions, otherwise multiple transcoding will occur, which usually creates a lot of problems.
3. The C API is inherited from LMDB and has quite a lot of oddities and inconveniences. Therefore, it is better to strive to reproduce the C++ API in any bindings.
L
17:40
Lazymio
In reply to this message
1. Sure, I just chosen the ones I'm familir (0.12.x) and I'm planning to migrate to 0.13
2. Yeah, I knew that but Windows is not my top priority so I just leave it as it is.
3. I'm going to have a bit "biased" design for the API, more similar to current rust bindings I have worked for a while (and that's why I didn't send it to libmdbx project directly). Instead of making a all-in-one binding, which there is already one for pure ctypes bindings, I would like to focus more on the most common operations, like just open the different dbs to operate as if it is a python dict. This is a tradeoff for performance and easy-to-use. Thanks to the brilliant code quality of libmdbx, I can accept less performant but more productive code =)
2. Yeah, I knew that but Windows is not my top priority so I just leave it as it is.
3. I'm going to have a bit "biased" design for the API, more similar to current rust bindings I have worked for a while (and that's why I didn't send it to libmdbx project directly). Instead of making a all-in-one binding, which there is already one for pure ctypes bindings, I would like to focus more on the most common operations, like just open the different dbs to operate as if it is a python dict. This is a tradeoff for performance and easy-to-use. Thanks to the brilliant code quality of libmdbx, I can accept less performant but more productive code =)
👍
VS
Л(
22 December 2024
АК
05:45
Алексей (Keller) Костюк 😐
@erthink Леонид здравствуйте. Происходит ошибка при удалении/переименовании DBI. Таблица на самом деле удаляется, но при закрытии env ошибка. Это я что-то не так сделал или ещё что-то?
node: mdbx:9939: mdbx_env_close_ex: Assertion `osal_fastmutex_destroy(&env->dbi_lock) == MDBX_SUCCESS' failed.
node: mdbx:9939: mdbx_env_close_ex: Assertion `osal_fastmutex_destroy(&env->dbi_lock) == MDBX_SUCCESS' failed.
Л(
10:35
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Вы не совсем верно используете API, но зато очень удачно (для меня) простукиваете его на наличие багов/регрессов.
Удаление таблицы (не очистка, и именно удаление) также сразу закрывает dbi-хендл, так как ему просто не с чем быть связанным.
Однако, в mdbx_dbi_close() был регресс, который проявлялся именно в такой ситуации — при попытке повторного закрытия dbi-хендла.
В результате в mdbx_dbi_close() захватывался, но не отпускался мьютекс, из-за чего при закрытии Env возникала ошибка при разрушении этого мьютекса.
Исправил.
Удаление таблицы (не очистка, и именно удаление) также сразу закрывает dbi-хендл, так как ему просто не с чем быть связанным.
Однако, в mdbx_dbi_close() был регресс, который проявлялся именно в такой ситуации — при попытке повторного закрытия dbi-хендла.
В результате в mdbx_dbi_close() захватывался, но не отпускался мьютекс, из-за чего при закрытии Env возникала ошибка при разрушении этого мьютекса.
Исправил.
👍
SD
w
e
4
😁
1
🤣
1
23 December 2024
Л(
16:19
Леонид Юрьев (Leonid Yuriev)
@Кстати, @keller18306, если я правильно понимаю, то ваши привязки (в том числе для LMDB) можно использовать для бенчмаркинга в https://k6.io/
Если у вас дойдут до это руки, но напишите о результатах.
И в целом всё это может быть интересно для @bongerka.
Если у вас дойдут до это руки, но напишите о результатах.
И в целом всё это может быть интересно для @bongerka.
АК
16:53
Алексей (Keller) Костюк 😐
In reply to this message
Это вроде для http... Это на отказоустойчивость тесты?
Л(
16:55
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Сам на этом "мопеде" я не катался, опираюсь на мнение @alexey_kopytov (автор sysbench).
АК
16:56
Алексей (Keller) Костюк 😐
In reply to this message
Мне проще цикл написать, который будет читать рандомные данные :)
Ибо тут упор больше будет в сеть/цп
Ибо тут упор больше будет в сеть/цп
Л(
17:00
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Ну я внутрь не смотрел, но думаю там легко прикручивается бенчмаркиг чего-угодно (примерно как в sysbench).
Соответственно, бенчмаркинг libmdbx (или любого другого движка хранения) делается вызовом привязкок вместо маршалинга в http.
Соответственно, бенчмаркинг libmdbx (или любого другого движка хранения) делается вызовом привязкок вместо маршалинга в http.
17:02
In reply to this message
Ну и большой плюс делать это через подобный "фреймворк" в возможности прикрутить драйверы/привязки к другим движкам (и провести сравнение), а также сравнить результаты с "голым С" (результаты от ioarena).
АК
17:02
Алексей (Keller) Костюк 😐
In reply to this message
Ну... У нас сервера пытались ддосить через k6... Поэтому думаю он больше создан для таких целей в плане тестирования...
17:05
In reply to this message
Для тестов именно по скорости внутри приложения, в nodejs используется это:
https://github.com/nodejs/node/blob/main/doc/contributing/writing-and-running-benchmarks.md
https://github.com/nodejs/node/blob/main/doc/contributing/writing-and-running-benchmarks.md
Л(
17:05
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Так любой подобный "фреймворк" состоит из трех частей:
- некой общей инфраструктуры;
- кастомизируемых/скриптовых сценариев, в том числе ddos-подобных;
- драйверов к конкретным тестируемым объектам (движкам хранения, http, и т.п.).
- некой общей инфраструктуры;
- кастомизируемых/скриптовых сценариев, в том числе ddos-подобных;
- драйверов к конкретным тестируемым объектам (движкам хранения, http, и т.п.).
АК
17:07
Алексей (Keller) Костюк 😐
In reply to this message
Ща спросил у гпт, k6 только для сетевых создан :)
Да, k6 в основном предназначен для нагрузочного тестирования веб-приложений и API, то есть для сетевых тестов. Он оптимизирован для симуляции большого количества HTTP-запросов к веб-серверам и оценки их производительности под нагрузкой. K6 позволяет анализировать такие аспекты, как время отклика, пропускная способность и стабильность системы при определенном объеме трафика.
17:08
In reply to this message
Если интересно, мне не сложно написать тесты под lmdb и mdbx для ноды... Всё равно хотелось узнать, насколько всё хреново/отлично было/стало
Л(
17:12
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Это всё разумными усилиями "натягивается" на вызов привязок к локальным (не сетевым) API, примерно как в sysbench.
Но конечно с поправкой на возможные затруднение с нативной многопоточкой.
Но конечно с поправкой на возможные затруднение с нативной многопоточкой.
17:19
In reply to this message
Бесспорно это будет не-бесполезно, но ioarena это уже позволяет.
Однако, получаемые при этом результаты, как прогнозируемы, так и далеки от сценариев где MDBX реально начинает сильно опережать LMDB.
Например, ioarena показывает что libmdbx чуть медленнее при включенных проверках и чуть быстрее при их отключении. Но в простых сценариях это на уровне стат-погрешности.
Реально же libmdbx начинает опережать LMDB в 10-100-1000 раз в долгих (многодневных) сценариях с очень большими транзакциями, в очень больших БД, в том числе с длинными значениями.
Однако, получаемые при этом результаты, как прогнозируемы, так и далеки от сценариев где MDBX реально начинает сильно опережать LMDB.
Например, ioarena показывает что libmdbx чуть медленнее при включенных проверках и чуть быстрее при их отключении. Но в простых сценариях это на уровне стат-погрешности.
Реально же libmdbx начинает опережать LMDB в 10-100-1000 раз в долгих (многодневных) сценариях с очень большими транзакциями, в очень больших БД, в том числе с длинными значениями.
АК
17:21
Алексей (Keller) Костюк 😐
In reply to this message
Вот и потесчу у нас на проде :)
Правда у меня никак не удастся одновременно lmdb и mdbx разместить на одном диске, ибо места нет
Правда у меня никак не удастся одновременно lmdb и mdbx разместить на одном диске, ибо места нет
17:22
Один плюс что я заметил - размер бд (именно реальных данных, а не пустоты) гораздо меньше у MDBX, чем LMDB... Правда не знаю даже, с чем это связано
Л(
17:23
Леонид Юрьев (Leonid Yuriev)
Так вот, ценность большого кастомизированного фреймворка в том, что там можно "ортогонально" добавлять как сценарии, так и драйверы к конкретным движкам хранения.
Например, так можно получить инструмент не только для сравнения движков, но и для опробирования/анализа доработок и новых движков.
В частности, для моего "орешника" (aka MithrilDB) такой инструмент точно необходим.
Например, так можно получить инструмент не только для сравнения движков, но и для опробирования/анализа доработок и новых движков.
В частности, для моего "орешника" (aka MithrilDB) такой инструмент точно необходим.
АК
17:26
Алексей (Keller) Костюк 😐
In reply to this message
Честно хз даже, что могу предложить... Но k6 очень трудно будет приспособить к этому... Как минимум потому, что в доке нигде не нашёл про такие виды тестирования :(
Там всё только про Web
Там всё только про Web
Л(
17:28
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Если есть заинтересованность, то можно попробовать выяснить:
- после выполнения тестов сравнить объем GC, если у MDBX существенно меньше, то сработала авто-компактификация.
- сравнить кол-во листовых страниц, если в MDBX существенно меньше, то сработало исправление багов.
- сравнить высоту b-деревьев, в том числе для вложенных b-tree, если в MDBX меньше, то сработала доработка тактики слияния страниц.
- после выполнения тестов сравнить объем GC, если у MDBX существенно меньше, то сработала авто-компактификация.
- сравнить кол-во листовых страниц, если в MDBX существенно меньше, то сработало исправление багов.
- сравнить высоту b-деревьев, в том числе для вложенных b-tree, если в MDBX меньше, то сработала доработка тактики слияния страниц.
17:29
In reply to this message
Ну так это понятно. Тут первым пунктом потребуется добавление еще одного протокола, что-нибудь вроде "local calls".
АК
17:31
Алексей (Keller) Костюк 😐
In reply to this message
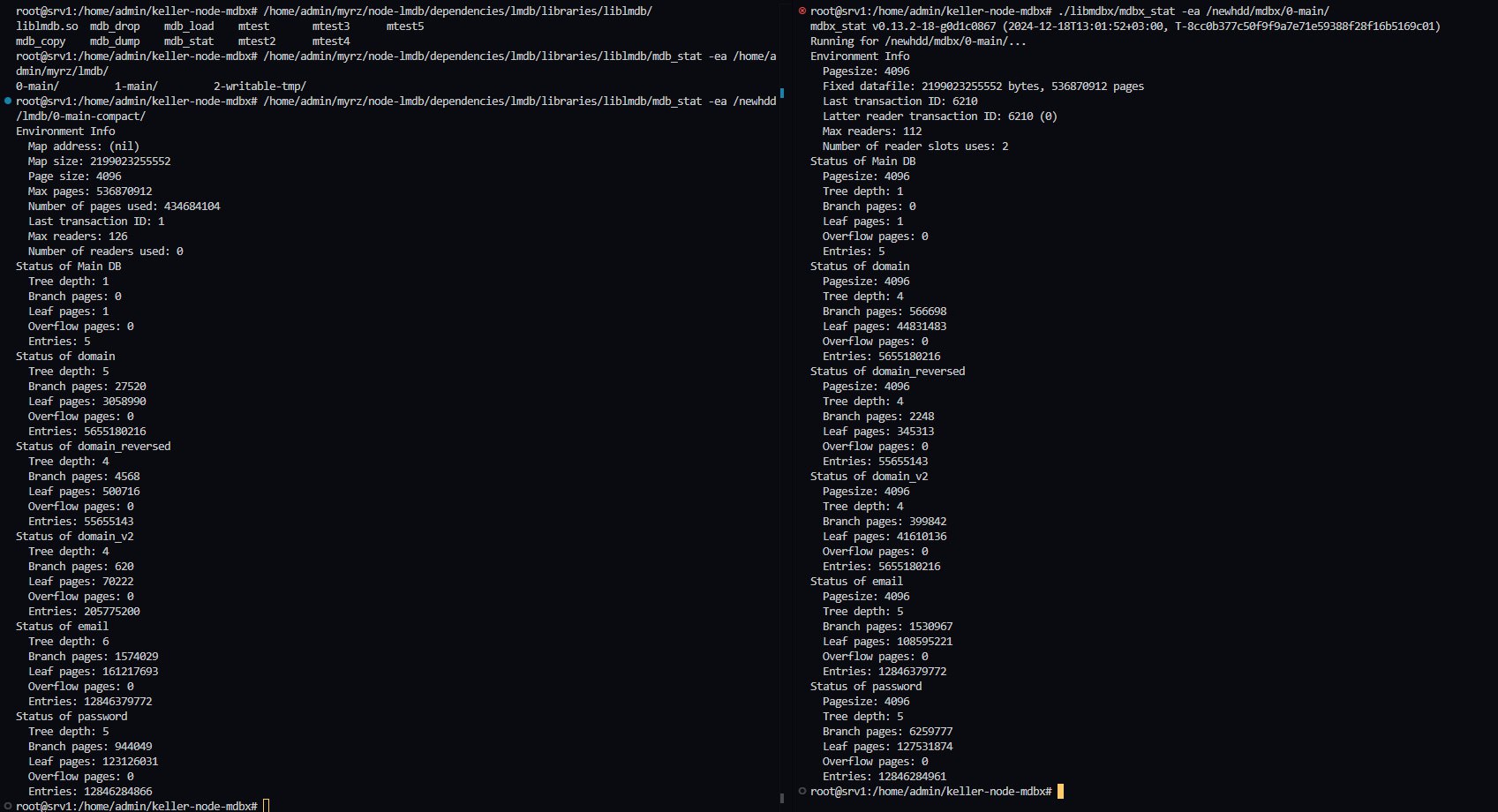
но у меня почти везде DUP, а lmdb не считает его нормально, поэтому не узнать
17:34
Вот domain_reversed не DUP, поэтому можно сравнить более-менее нормально... У mdbx в два раза меньше страниц при идентичных данных 🤷♂️
Магия оптимизаций
Магия оптимизаций
❤
Л(
17:37
In reply to this message
К концу недели вторая бд закончит миграцию, и можно будет перемещать основную БД на SSD, предварительно удалив LMDB... Там уже окончательно смогу сказать результаты
Л(
17:39
Леонид Юрьев (Leonid Yuriev)
In reply to this message
А можете показать вывод
Ну и теоретически можно доработать mdb_stat, так чтобы утилита обходила всё дерево и правильно подсчитывала страницы и т.п.
mdbx_chk -vvv для domain_reverse, там много чего подсчитывается (заполнение страницы, средняя длина клюей/значнений и т.п.) ?Ну и теоретически можно доработать mdb_stat, так чтобы утилита обходила всё дерево и правильно подсчитывала страницы и т.п.
A
17:41
Aleksandr Druzhinin
In reply to this message
А какой у вас размер БД в байтах и кол-ве записей, если не секрет? чтобы понимать на каком объеме данных используются lmdb/mdbx
АК
17:42
Алексей (Keller) Костюк 😐
In reply to this message
Кажется это долго будет считаться :) Минимум неделю. У меня на полное чтение всех данных из одной только таблицы (email) на SSD уходит месяц, если приходится искать "лишние" данные для чистки бд...
17:44
In reply to this message
кол-во для каждой таблицы написано выше на скрине
размер для lmdb: 1.6TB (хотя сам файл уже 2ТБ, ибо FREELIST всё - умер)
размер для mdbx: 1.2TB
размер для lmdb: 1.6TB (хотя сам файл уже 2ТБ, ибо FREELIST всё - умер)
размер для mdbx: 1.2TB
17:45
+ и ещё побочная (writable) база (чтобы не писать в главную, ибо как я говорил FREELIST всё) 200GB
Л(
17:48
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Ну и если не секрет , "у вас на проде" — это где именно ?
17:50
In reply to this message
На всякий, есть "широко известная в узких кругах" информация от Erigon.
👍
A
АК
17:51
Алексей (Keller) Костюк 😐
In reply to this message
Ну меня вроде просили особо не говорить, хотя скрины сами говорят за себя:)
У нас фактически аналог leakcheck (проверка паролей на утечки), как дочерний проект одного из популярного форума в ру сегменте
У нас фактически аналог leakcheck (проверка паролей на утечки), как дочерний проект одного из популярного форума в ру сегменте
Л(
18:12
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Тут два момента:
1.
Всё чаще поступают вопросы "А где libmdbx работает в проде ?", и кроме "ethereum" и "positive tecnhologies" народ явно хочет услышать/увидеть ещё несколько козырей.
2.
Мне нужно оценить/спланировать "доходную часть бюджета", т.е. понять как много libmdbx приносит бизнесу и насколько этот бизнес склонен участвовать в спонсировании разработки и/или оплате поддержки.
Только сразу оговорюсь, тут дело не в выклянчивании подачек, а выстраивании доверительных и взаимовыгодных отношений с тем бизнесом, который уже успешен.
1.
Всё чаще поступают вопросы "А где libmdbx работает в проде ?", и кроме "ethereum" и "positive tecnhologies" народ явно хочет услышать/увидеть ещё несколько козырей.
2.
Мне нужно оценить/спланировать "доходную часть бюджета", т.е. понять как много libmdbx приносит бизнесу и насколько этот бизнес склонен участвовать в спонсировании разработки и/или оплате поддержки.
Только сразу оговорюсь, тут дело не в выклянчивании подачек, а выстраивании доверительных и взаимовыгодных отношений с тем бизнесом, который уже успешен.
АК
18:13
Алексей (Keller) Костюк 😐
In reply to this message
Тогда я вам сейчас отпишу в лс... Второе тоже было интересно узнать у вас
e
19:35
e
Для nodejs/bun/cpp бенчей еще можете посмотреть https://github.com/evanwashere/mitata
- hw-counters
- графики
- авто-gc перед каждым бенчем с node --expose-gc или bun
- легкая интеграция со своим cpp-кодом
Пока самое удобное, что нашел, использую для бенчей своего libmdbx-bun:ffi биндига
- hw-counters
- графики
- авто-gc перед каждым бенчем с node --expose-gc или bun
- легкая интеграция со своим cpp-кодом
#include "src/mitata.hpp"
int fibonacci(int n) {
if (n <= 1) return n;
return fibonacci(n - 1) + fibonacci(n - 2);
}
int main() {
mitata::runner runner;
runner.bench("noop", []() { });
runner.summary([&]() {
runner.bench("empty fn", []() { });
runner.bench("fibonacci", []() { fibonacci(20); });
});
auto stats = runner.run();
}
Пока самое удобное, что нашел, использую для бенчей своего libmdbx-bun:ffi биндига
Л(
19:45
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Для взаимопонимания — нет проблемы пробенчить пару функций или что-то подобное.
Задача/хотелка более обширная: иметь некий легко кастомизируемый "фрейморк", в котором можно отдельно разрабатывать сценарии и подключать движки хранения через плагины/драйверы.
Например:
- иметь для sysbench/k6 сценарий воспроизводящий работу Erigon (тот же объем данных и их распределение, те же операции, но всё псевдослучайно и без реальной логики работы блокчейна);
- иметь драйверы RockDB, LMDB, libmdbx, итд, сравнить эти движки буквально в одном сценарии, но _очень_ близкому к реальному применению.
- иметь возможность добавить драйвер для MithrilDB и смотреть как себя ведут экспериментальные фишки...
Задача/хотелка более обширная: иметь некий легко кастомизируемый "фрейморк", в котором можно отдельно разрабатывать сценарии и подключать движки хранения через плагины/драйверы.
Например:
- иметь для sysbench/k6 сценарий воспроизводящий работу Erigon (тот же объем данных и их распределение, те же операции, но всё псевдослучайно и без реальной логики работы блокчейна);
- иметь драйверы RockDB, LMDB, libmdbx, итд, сравнить эти движки буквально в одном сценарии, но _очень_ близкому к реальному применению.
- иметь возможность добавить драйвер для MithrilDB и смотреть как себя ведут экспериментальные фишки...
👍
e
e
19:54
e
Да, я понимаю) Это так, скинул, если на данном этапе кому-то понадобится +- удобный инструмент пробенчить пару функций в своих биндингах
👍
Л(
حسن invited حسن
max invited max
Виктор Логунов invited Виктор Логунов
24 December 2024
Павел Мисуркин PM invited Павел Мисуркин PM
Л(
01:58
Леонид Юрьев (Leonid Yuriev)
同志们,这里有来自中国的人吗?
我看到有关libmdbx文档的网站被许多来自中国的访问者阅读
但他们都没有在这里说话,还是我不准确?
我看到有关libmdbx文档的网站被许多来自中国的访问者阅读
但他们都没有在这里说话,还是我不准确?
👌
w
L
АК
04:16
Алексей (Keller) Костюк 😐
In reply to this message
У китайцев нет телеги, ибо у них она заблокирована, насколько я помню:)
У них вроде WeChat в основном используется только, хотя и могу ошибаться
У них вроде WeChat в основном используется только, хотя и могу ошибаться
L
04:43
Lazymio
In reply to this message
Chinese people seldom uses Telegram and even less people speaks fluent English so you hardly see them (or us :p) here.
libmdbx is also much less known than other kv databases in most our forums.
libmdbx is also much less known than other kv databases in most our forums.
e
04:45
e
In reply to this message
Телеграм у них есть, как и всё остальное) Живут за фаерволом достаточно долго, чтобы научиться его обходить
Но потребность возникает реже, т.к. развиты внутренние ресурсы/сообщества (csdn, gitee, cnki..), поэтому они переводят статьи, зеркалят репозитории и общаются уже там между собой :)
Но потребность возникает реже, т.к. развиты внутренние ресурсы/сообщества (csdn, gitee, cnki..), поэтому они переводят статьи, зеркалят репозитории и общаются уже там между собой :)
L
05:09
Lazymio
exactly, many people may just prefer the translated articles
w
08:19
walter
Dear libmdbx Maintainers,
I am requesting a feature to support page-level operations for efficient data synchronization between different libmdbx instances. (like SQLite Virtual Table)
Requested Functionality
1) Page Traversal in single read Transaction:
An API to iterate through database pages containing actual raw-page-data.
Metadata pages should be excluded, as metadata may differ between instances due to GC or other factors.
2) Page Writing in single write Transaction:
Allow writing multiple pages in a single transaction while maintaining database integrity and consistency.
3) Use Case
This feature is aimed at incremental synchronization and backup, and maybe real-time replication. By accessing key-value data at the page level:
Changes can be tracked and synchronized between instances efficiently.
Only modified data needs to be transferred, minimizing overhead.
Let me know if more details are needed.
I am requesting a feature to support page-level operations for efficient data synchronization between different libmdbx instances. (like SQLite Virtual Table)
Requested Functionality
1) Page Traversal in single read Transaction:
An API to iterate through database pages containing actual raw-page-data.
Metadata pages should be excluded, as metadata may differ between instances due to GC or other factors.
2) Page Writing in single write Transaction:
Allow writing multiple pages in a single transaction while maintaining database integrity and consistency.
3) Use Case
This feature is aimed at incremental synchronization and backup, and maybe real-time replication. By accessing key-value data at the page level:
Changes can be tracked and synchronized between instances efficiently.
Only modified data needs to be transferred, minimizing overhead.
Let me know if more details are needed.
Л(
08:43
Леонид Юрьев (Leonid Yuriev)
In reply to this message
How do you rate the quality of machine translation? Is it very clumsy?
w
08:48
walter
If the intention can be accurately expressed and misunderstanding can be avoided, I have no more requirements for machine translation.
Serg invited Serg
Л(
09:48
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Let me try to explain the difficulties, etc.
Page-level synchronization has certain problems with the current situation:
1. B-Tree's branch pages cannot be manipulated directly, this is no sense.
Such pages contain links to child pages (their numbers) and the values of the page-top keys.
In other words, ones content is determined by the content and ids/numbers of the child pages.
So it makes no sense to do anything with ones, except to fill/update them completely automatically.
2. The binary contents of the leaf pages may be fundamentally different even the contents of the database completely match.
libmdbx, like all (or slightly less than all) b-tree databases, performs page splitting and merging only when necessary.
This is very reasonable as it minimizes the number of these expensive operations.
However, this means that there is a hysteresis between the levels of split and merge.
Therefore, deleting an entry after insertion, which required splitting the pages, will rarely lead to a merge.
Similarly, inserting a record after deleting that required pages merging will rarely result in a split.
In general, this means that the binary contents of the leaf pages depend not only on the contents of the database, but also on the literal sequence of all data modification operations.
Thus, page-level synchronization can quickly turn into full copying.
Moreover, the efficiency of such synchronization will be less than the smart use of the pipeline like
It should also be noted that the page numbers may be different, since GC processing depends on the presence of readers using MVCC snapshots, which depends on the processes using the database, their behavior, and the actions of the OS scheduler -- all of ones could be different on local and remote sides of replication.
3. Effective implementation of replication both at the page level and based on the rsync algorithm requires a Merkle Tree.
The main problem is something else — it requires changing the database format.
Changing the format means that there is another version of the database engine that needs to be supported. But if this format does not allow me to implement all the important/ necessary features and solve all the main problems, then I will have to change it again, and then again ... each time getting another version that needs to be supported.
This leads to a dispersion of resources, which I don't have the time or energy for. It is also impossible to abandon support, as this means ignoring the problems and requests from users of such intermediate versions. In turn, if I declare the short life of the versions and their experimental status, then few people will use ones.
In general, this is a rather difficult dilemma of choosing and planning resources. In the end, vote with money, you really need something.
Page-level synchronization has certain problems with the current situation:
1. B-Tree's branch pages cannot be manipulated directly, this is no sense.
Such pages contain links to child pages (their numbers) and the values of the page-top keys.
In other words, ones content is determined by the content and ids/numbers of the child pages.
So it makes no sense to do anything with ones, except to fill/update them completely automatically.
2. The binary contents of the leaf pages may be fundamentally different even the contents of the database completely match.
libmdbx, like all (or slightly less than all) b-tree databases, performs page splitting and merging only when necessary.
This is very reasonable as it minimizes the number of these expensive operations.
However, this means that there is a hysteresis between the levels of split and merge.
Therefore, deleting an entry after insertion, which required splitting the pages, will rarely lead to a merge.
Similarly, inserting a record after deleting that required pages merging will rarely result in a split.
In general, this means that the binary contents of the leaf pages depend not only on the contents of the database, but also on the literal sequence of all data modification operations.
Thus, page-level synchronization can quickly turn into full copying.
Moreover, the efficiency of such synchronization will be less than the smart use of the pipeline like
mdbx_dump | lz4 | nc | lz4 -d | mdbx_load.It should also be noted that the page numbers may be different, since GC processing depends on the presence of readers using MVCC snapshots, which depends on the processes using the database, their behavior, and the actions of the OS scheduler -- all of ones could be different on local and remote sides of replication.
3. Effective implementation of replication both at the page level and based on the rsync algorithm requires a Merkle Tree.
The main problem is something else — it requires changing the database format.
Changing the format means that there is another version of the database engine that needs to be supported. But if this format does not allow me to implement all the important/ necessary features and solve all the main problems, then I will have to change it again, and then again ... each time getting another version that needs to be supported.
This leads to a dispersion of resources, which I don't have the time or energy for. It is also impossible to abandon support, as this means ignoring the problems and requests from users of such intermediate versions. In turn, if I declare the short life of the versions and their experimental status, then few people will use ones.
In general, this is a rather difficult dilemma of choosing and planning resources. In the end, vote with money, you really need something.
L
09:57
Lazymio
why not use APPEND for incremental sync
Л(
10:02
Леонид Юрьев (Leonid Yuriev)
I plan to implement replication/synchronization based on RFC-4533, as I have extensive experience in fixing/refining such replication (with support of multi-master topology) in ReOpenLDAP for industrial operation in the infrastructure of a huge Russian mobile operator.
But this requires several more improvements. In particular, non-linear GC recycling/reclaiming, which also eliminates one of the huge architectural challenges. In turn, this requires several basic improvements, which result in the possibility of online DB defragmentation/shrinking. That is, such defragmentation will be a logical intermediate step and an independent useful feature on the way to nonlinear GC processing.
However, all this takes time and effort, and now I need (as I mentioned yesterday) to "assess the revenue side of the budget", since starting next year, the development and support of libmdbx will no longer be funded by Positive Technologies.
But this requires several more improvements. In particular, non-linear GC recycling/reclaiming, which also eliminates one of the huge architectural challenges. In turn, this requires several basic improvements, which result in the possibility of online DB defragmentation/shrinking. That is, such defragmentation will be a logical intermediate step and an independent useful feature on the way to nonlinear GC processing.
However, all this takes time and effort, and now I need (as I mentioned yesterday) to "assess the revenue side of the budget", since starting next year, the development and support of libmdbx will no longer be funded by Positive Technologies.
w
10:04
walter
Thank you so much for your detailed explanation and patience!
The use-case can be a master/slave backup process, If they can be syned at 10s delay or less.
By traversal page and use fast hash, I can quickly generate a small snapshot. by compare 2 snapshot I know which page need to be backup.
I will set page size very big (like 64KB or more), and do batch write. each key/value is very small like 8 byte key, 16byte value. but the database can be huge like 20GB or more.
mdbx_dump will not work because the total size will be too big.
Write frequency wil be like 100 QPS or less, but each batch has a lot key/value updated.
The sqlite has a design allow you reserved few byte for each page, and update them by vfs page write call. I can save 8 byte as hash in here to support fast comare by page-id+reserved value. (so by traversal sqlite page I can avoid recalculate hash )
I'm not sure if this makes sense.
The use-case can be a master/slave backup process, If they can be syned at 10s delay or less.
By traversal page and use fast hash, I can quickly generate a small snapshot. by compare 2 snapshot I know which page need to be backup.
I will set page size very big (like 64KB or more), and do batch write. each key/value is very small like 8 byte key, 16byte value. but the database can be huge like 20GB or more.
mdbx_dump will not work because the total size will be too big.
Write frequency wil be like 100 QPS or less, but each batch has a lot key/value updated.
The sqlite has a design allow you reserved few byte for each page, and update them by vfs page write call. I can save 8 byte as hash in here to support fast comare by page-id+reserved value. (so by traversal sqlite page I can avoid recalculate hash )
I'm not sure if this makes sense.
10:08
each batch keys update has affinity, so the updated page is likely near to each other. (but also need rare long distance key update transactions)
10:09
the change will send into other GEO location, that is why mdbx_dump will not work well.
10:19
This also suit for s3 backup, so each time you get a few page changed and save them into cloud. (so they can sync in short time window)
Л(
10:23
Леонид Юрьев (Leonid Yuriev)
In reply to this message
It seems that the batch/page-by-page data acquisition API will be enough for you to implement this, just like
In other words, you will be able to get a page image and an MDBX_val array/vector for all key-value pairs on such page at once, and within this page.
At the same time, for hashing, you will need to provide a hash function that works in streaming mode, so as not to depend on the order of offsets within the page and uniformly process long values placed on separate pages (aka large/overflow pages).
however, I need to think about how it will work on the receiving side, i.e. where the update will be performed.
MDBX_GET_MULTUPLE currently works.In other words, you will be able to get a page image and an MDBX_val array/vector for all key-value pairs on such page at once, and within this page.
At the same time, for hashing, you will need to provide a hash function that works in streaming mode, so as not to depend on the order of offsets within the page and uniformly process long values placed on separate pages (aka large/overflow pages).
however, I need to think about how it will work on the receiving side, i.e. where the update will be performed.
w
10:28
walter
Thanks again for your detailed instruction and explaintion.
Л(
10:45
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Think about the API you would like to have. Adjusted for I tend to use an internal hash, because this will significantly reduce overhead costs.
And if you want to get this functionality faster, then you should think about prototyping, preferably in the form of a unit test (initilaly with mock) using the C++ API.
Then it is very likely that I will be able to do it in January.
And if you want to get this functionality faster, then you should think about prototyping, preferably in the form of a unit test (initilaly with mock) using the C++ API.
Then it is very likely that I will be able to do it in January.
❤
w
w
10:46
walter
In reply to this message
If we can iterate over each page, by page-id, global monotonically increasing version number, and page content tuple. there will no need to per-page-hash.
And you only keep a global monotonically increasing version number, by compare them to know which page need to be backup.
And you only keep a global monotonically increasing version number, by compare them to know which page need to be backup.
11:00
In reply to this message
uint64_t mdbx_page_count(const MDBX_txn* txn, MDBX_dbi dbi, uint64_t* txn_latest_global_version);
uint64_t mdbx_page_get(const MDBX_txn* txn, MDBX_dbi dbi, uint64_t page_id, uint64_t* page_global_version, uint* page_size, void* page_content);
uint64_t mdbx_page_put(const MDBX_txn* txn, MDBX_dbi dbi, uint64_t page_id, uint64_t page_global_version, uint* page_size, void* page_content);
and a flags to enable the global_version, and one more flags to limit this is a batch page write transaction. (so you can not write normal key value change)
uint64_t mdbx_page_get(const MDBX_txn* txn, MDBX_dbi dbi, uint64_t page_id, uint64_t* page_global_version, uint* page_size, void* page_content);
uint64_t mdbx_page_put(const MDBX_txn* txn, MDBX_dbi dbi, uint64_t page_id, uint64_t page_global_version, uint* page_size, void* page_content);
and a flags to enable the global_version, and one more flags to limit this is a batch page write transaction. (so you can not write normal key value change)
Л(
11:03
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Unfortunately, this requires changing the database format.
The mdbx already has a transaction number on each page.
However, it is not suitable for these purposes, since in this case the transaction numbers on the local and remote sides must match (i.e. the entire history of name changes must match with chaining to specific writing transactions).
So, no
The mdbx already has a transaction number on each page.
However, it is not suitable for these purposes, since in this case the transaction numbers on the local and remote sides must match (i.e. the entire history of name changes must match with chaining to specific writing transactions).
So, no
global_version at all (
w
11:07
walter
In future versions, is it possible to add functionality similar to the sqlite page reserved byte? and let user provide callbak to decide what context it should be at each page update.
It can be a Historically incompatible upgrades by Compile-time options
It can be a Historically incompatible upgrades by Compile-time options
Л(
11:08
Леонид Юрьев (Leonid Yuriev)
mdbx_page_count() — OK, since it is the mdbx_dbi_stat() actually.mdbx_page_get(id) — NO, since this means getting the page not by its linear number in the database file, but by its ordinal number in the b-tree, which requires traversing the tree (at least to build such a map).So, no
page-id at all in such manner.
11:12
In fact, the pages of the tree can only be accessed in the context of a page-by-page traversal of the tree, i.e. some enumeration of them via a callback.
11:13
walter, I'm sorry, I have something else to do. I'll be back in 7-8 hours.
w
11:13
walter
uint64_t mdbx_page_count(const MDBX_txn* txn, MDBX_dbi dbi);
MDBX_page_cursor* mdbx_page_cursor_create(const MDBX_txn* txn, MDBX_dbi dbi);
void* mdbx_page_cursor_close(MDBX_page_cursor*);
bool mdbx_page_next(MDBX_page_cursor*, uint64_t btree_id, uint* page_size, void* page_content);
uint64_t mdbx_page_put(const MDBX_txn* txn, MDBX_dbi dbi, uint64_t btree_id, uint* page_size, void* page_content);
MDBX_page_cursor* mdbx_page_cursor_create(const MDBX_txn* txn, MDBX_dbi dbi);
void* mdbx_page_cursor_close(MDBX_page_cursor*);
bool mdbx_page_next(MDBX_page_cursor*, uint64_t btree_id, uint* page_size, void* page_content);
uint64_t mdbx_page_put(const MDBX_txn* txn, MDBX_dbi dbi, uint64_t btree_id, uint* page_size, void* page_content);
Л(
11:17
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Take look to the obsolete 0.12.x page-walking API.
LIBMDBX_API int mdbx_env_pgwalk(MDBX_txn *txn, MDBX_pgvisitor_func *visitor,
void *ctx, bool dont_check_keys_ordering);
👌
w
11:32
In reply to this message
One last note before I leave.
A single
Because there are a nested b-tree for multi-values (aka duplicates) and a large/overflow pages for long values.
Seems we should have a page type (regular leaf, nested dupsort-leaf, large-overflow) and a vector of MDBX_val.
Nonetheless, I still need to think about how best to handle nested subpages (ones are smaller and stored inside regular leaf pages).
A single
page_content pointer is impossible, but an array/vector of a pair of MDBX_val for key-values pairs.Because there are a nested b-tree for multi-values (aka duplicates) and a large/overflow pages for long values.
Seems we should have a page type (regular leaf, nested dupsort-leaf, large-overflow) and a vector of MDBX_val.
Nonetheless, I still need to think about how best to handle nested subpages (ones are smaller and stored inside regular leaf pages).
👌
w
w
12:37
walter
In reply to this message
If the transaction numbers is monotonically increasing, it will be helpful to decide which page is updated since last backup. (I can just compare the number, but not sent number to remote for write)
Л(
19:06
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Your solution will work, but, alas, it is actually fragile and does not provide any significant advantages.
For clarity:
As the local and remote transaction numbers could be different, then it follows from this that we cannot compare local and remote transaction numbers. But can only store the master-side transaction number on the slave-side with which we synchronized, and next get all the pages that were changed on the master-side after that.
The only advantage of this solution is that on the slave side there is no need to read the pages to decide whether they should be synchronized.
i.e. it is a less I/O on the slave.
But disadvantages there are several, and ones seem significant to me:
1. A master-side is unreplaceable, unless you resync slaves from a scratch.
Actually you cannot "rewind" transaction number on a master without complete resyncing slaves.
So recreating, compactifying (
2. Only unidirectional replication topology from a single master to a slave(s) is possible.
i.e. no any kind of multi-master nor mesh.
3. There is no integrity control, including absolutely no protection against bugs in the logic and/or implementation of replication itself.
In contrast, the hashing-based approach requires reading all the leafs on the slave, but in return has no other drawbacks noted above.
In other words, it just works ;)
For clarity:
As the local and remote transaction numbers could be different, then it follows from this that we cannot compare local and remote transaction numbers. But can only store the master-side transaction number on the slave-side with which we synchronized, and next get all the pages that were changed on the master-side after that.
The only advantage of this solution is that on the slave side there is no need to read the pages to decide whether they should be synchronized.
i.e. it is a less I/O on the slave.
But disadvantages there are several, and ones seem significant to me:
1. A master-side is unreplaceable, unless you resync slaves from a scratch.
Actually you cannot "rewind" transaction number on a master without complete resyncing slaves.
So recreating, compactifying (
mdbx_copy -c), or restoring from a database backup on the master breaks everything.2. Only unidirectional replication topology from a single master to a slave(s) is possible.
i.e. no any kind of multi-master nor mesh.
3. There is no integrity control, including absolutely no protection against bugs in the logic and/or implementation of replication itself.
In contrast, the hashing-based approach requires reading all the leafs on the slave, but in return has no other drawbacks noted above.
In other words, it just works ;)
❤
w
25 December 2024
Л(
09:03
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Have you found the reason for the slowdown ?
Maybe you have the assertions enabled (i.e.
or make/CFLAGS
Maybe you have the assertions enabled (i.e.
CMake -D MDBX_FORCE_ASSERTIONS=ONor make/CFLAGS
-DMDBX_FORCE_ASSERTIONS=1) ?
f
11:14
I don't have anything enabled, unless perhaps the golang wrapper has it
Л(
11:18
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Could you show the flamegraphs both for libmdbx and LMDB of your case ?
f
11:19
fiatjaf
I don't know how to do that
😨
Л(
Л(
11:23
Леонид Юрьев (Leonid Yuriev)
In reply to this message
@AskAlexSharov, можешь глянуть что у него там?
Может у тебя в привязках просто включена сборка с MDBX_FORCE_ASSERTIONS=1 ?
Даже если там что-то несущественное, то ваш Erigon это будет также тормозить.
Может у тебя в привязках просто включена сборка с MDBX_FORCE_ASSERTIONS=1 ?
Даже если там что-то несущественное, то ваш Erigon это будет также тормозить.
AS
11:27
Alex Sharov
In reply to this message
Default compile-time flags: https://github.com/erigontech/mdbx-go/blob/18718661de1e219ca2827e670cb6840545ef5a4e/mdbx/mdbx.go#L130
Default runtime flags: https://github.com/erigontech/mdbx-go/blob/18718661de1e219ca2827e670cb6840545ef5a4e/mdbx/env.go#L159
Default runtime flags: https://github.com/erigontech/mdbx-go/blob/18718661de1e219ca2827e670cb6840545ef5a4e/mdbx/env.go#L159
Л(
11:34
Леонид Юрьев (Leonid Yuriev)
In reply to this message
В ближайшие несколько дней у меня не будет времени чтобы заниматься этим.
Попробуйте сами научиться получать flamegraph, в Сети полно руководств и примеров.
Попробуйте сами научиться получать flamegraph, в Сети полно руководств и примеров.
Л(
12:59
Леонид Юрьев (Leonid Yuriev)
In reply to this message
I don't have time to do this for the next few days.
Try to learn how to make flamegraph yourself, the Web is full of guides and examples.
If you need your case/code to be handled and directly assisted, then I think it's wise considering paid support.
I'm preparing to provide paid support starting next year.
But since payment outside of Russia will be in ETH, there are no obstacles to start now (0.1 ETH/month, 1 ETH/year).
However, you can always rely on free support under generally accepted open-source conditions.
Try to learn how to make flamegraph yourself, the Web is full of guides and examples.
If you need your case/code to be handled and directly assisted, then I think it's wise considering paid support.
I'm preparing to provide paid support starting next year.
But since payment outside of Russia will be in ETH, there are no obstacles to start now (0.1 ETH/month, 1 ETH/year).
However, you can always rely on free support under generally accepted open-source conditions.
f
13:26
I don't want you to handle my case specifically nor I expected that, but I also don't have time to debug this myself or learn how to make a flame graph, I brought the case here because I thought I could be making a very obvious and also because I thought the data point could interest you given that you seem to care about mdbx performance
🤝
Л(
13:27
with all that said I think it's ok for us to forget about it for now and I will try mdbx again in the future
13:28
thank you very much for the support you gave me and for offering an alternative to LMDB on the market for free like you do
Л(
13:29
Леонид Юрьев (Leonid Yuriev)
In reply to this message
AFAIK bindings was updated last days for libmdbx 0.13.x
Л(
L
18:43
Lazymio
Ah no, it's my program fault I guess so I deleted my messages.
18:44
The memory consumed by the pending read-write transactions seems nothing to do with the amount of uncommitted data.
Л(
18:48
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Hm, NO.
Without the MDBX_WRITEMAP mode/flag, all modified (aka dirty) pages accumulate in RAM until the transaction is completed or the limit is exceeded (and then the oldest of them will be spilled to disk).
Without the MDBX_WRITEMAP mode/flag, all modified (aka dirty) pages accumulate in RAM until the transaction is completed or the limit is exceeded (and then the oldest of them will be spilled to disk).
L
18:48
Lazymio
In reply to this message
Ah yeah, I mean there seems some limit but not as large as 60GB I seen.
Л(
L
18:54
Lazymio
So the default limit is 65536 * 16384 (mine using 16k page size) = 1G. Thanks for the reference =)
18:56
This aligns with the observations of my quick experiment which indicates my program's fault
Л(
19:09
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Oh/oops, the documentation is incorrect (outdated).
In fact, there's a simple auto-tune now.
In fact, there's a simple auto-tune now.
size_t reasonable_dpl_limit = (size_t)(total_ram_pages + avail_ram_pages) / 42;
L
19:10
Lazymio
really, how does 42 get decided? a fair dice roll?
Л(

L
19:14
Lazymio
So I have 64GB in total and almost all of them are free and this indicates 128GB / 42, roughly 3GB?
Л(
L
19:14
Lazymio
I observed ~2GB with the same data (from htop, so not precise), seemed similar
19:15
Anyway, thanks for quick answering
Л(
19:15
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Try
int err = mdbx_get_sysraminfo(&page_size, &total_ram_pages, &avail_ram_pages);
L
19:17
Lazymio
Thanks! I would set the option later, though the high memory usage mostly comes from other part of my program
26 December 2024
felipe stival (v0idpwn) invited felipe stival (v0idpwn)
Victor invited Victor
28 December 2024
Л(
10:16
Леонид Юрьев (Leonid Yuriev)
Выпуск
В текущем понимании ветка
Одновременно с этим:
- ветка 0.12.x перестанет поддерживаться и отправиться в
- ветка 0.13.x станет
- техническим тегом 0.14.0 будет отмечено начало разработки 0.14.x;
В 0.14.x в начале 2025 года планируется реализовать:
- раннюю очистку GC, что требуется для последующих доработок;
- online-дефрагментацию;
- нелинейную переработку GC, что сведет близко теоретическому минимуму последствия проблемы "застрявших читателей".
Если кому-то нужны еще какие-либо доработки, то спонсируйте (координаты в закрепленном сообщении сверху).
--
Со следующего года Positive Technologies прекращает финансирование разработки и поддержки libmdbx.
Большое спасибо за 8 лет сотрудничества!
Пора двигаться вперед.
0.13.3 планируется через 10 дней.В текущем понимании ветка
master уже готова к этому (см. ChangeLog).Одновременно с этим:
- ветка 0.12.x перестанет поддерживаться и отправиться в
архив/0.12;- ветка 0.13.x станет
stable;- техническим тегом 0.14.0 будет отмечено начало разработки 0.14.x;
В 0.14.x в начале 2025 года планируется реализовать:
- раннюю очистку GC, что требуется для последующих доработок;
- online-дефрагментацию;
- нелинейную переработку GC, что сведет близко теоретическому минимуму последствия проблемы "застрявших читателей".
Если кому-то нужны еще какие-либо доработки, то спонсируйте (координаты в закрепленном сообщении сверху).
--
Со следующего года Positive Technologies прекращает финансирование разработки и поддержки libmdbx.
Большое спасибо за 8 лет сотрудничества!
Пора двигаться вперед.
🔥
1
b
10:18
basiliscos
In reply to this message
это значит что mdbx будет заброшена? или что только фиксы буду появляться?
Л(
10:32
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Пардон, но ведь буквально озвучены планы разработки и перевод текущей мастер-ветки в статус stable (как-бы LTS).
Поддержка 0.13.x нужна Erigon (уже спонсируют) и вроде-бы "Позитиву".
Но маловероятно что "Позитив" будет как-либо помогать, ибо "и так всё работает", а бумажной волокиты больше чем денег ;)
Поддержка 0.13.x нужна Erigon (уже спонсируют) и вроде-бы "Позитиву".
Но маловероятно что "Позитив" будет как-либо помогать, ибо "и так всё работает", а бумажной волокиты больше чем денег ;)
👍
b
10:34
In reply to this message
Что касается исправлений (не путать с разработкой новых фичей), то они точно будут достаточно долго.
Тем не менее, я надеюсь что в 0.13.x кол-во багов близко к нулю :)
Тем не менее, я надеюсь что в 0.13.x кол-во багов близко к нулю :)
👍
AK
f(
Л(
30 December 2024
Л(
10:16
Леонид Юрьев (Leonid Yuriev)
Mirna, security question against bots: What is the 42nd digit in the 1.0/3.0 result?
👍
AK
5 January 2025
SD
19:27
Sayan J. Das
In reply to this message
> - online defragmentation;
- non-linear GC processing, which will reduce the consequences of the "stuck readers" problem to a theoretical minimum.
Very excited for 0.14! Can you explain a bit about "online defragmentation" and the "stuck readers" problem? Does it mean the problem of long running reads causing exponential database growth?
- non-linear GC processing, which will reduce the consequences of the "stuck readers" problem to a theoretical minimum.
Very excited for 0.14! Can you explain a bit about "online defragmentation" and the "stuck readers" problem? Does it mean the problem of long running reads causing exponential database growth?
Л(
19:51
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Yes, but please read the "Long-lived read transactions" and the next "Large data items and huge transactions" sections.
👍
SD
9 January 2025
АК
07:34
Алексей (Keller) Костюк 😐
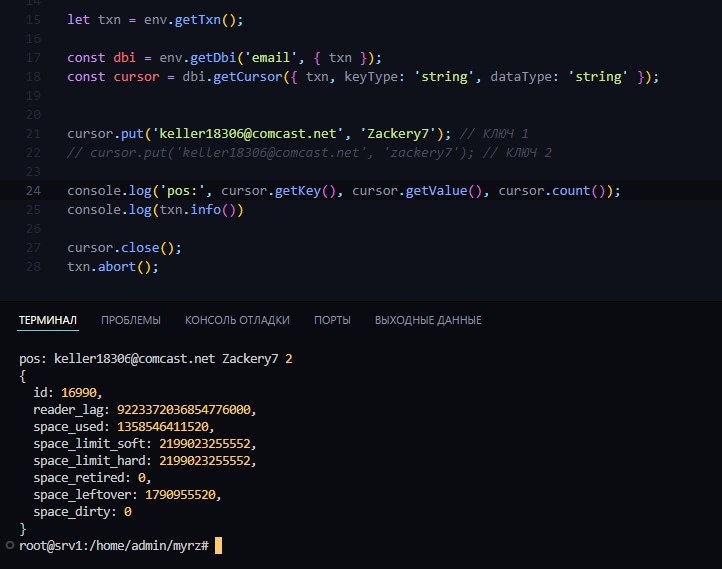
@erthink Леонид, доброе утро. Есть вопрос по логике вставке в dup таблицы.
Есть "ключ", который уже содержит в себе 2 dupSort значения.
Если я выполняю вставку уже существующего 1-го зачения, то space_dirty не меняется.
Однако, если выполняю вставку существующего - 2-го ключа, то space_dirty вырастает.
Они оба уже существуют в таблице, что подтверждается флагом NO_OVERWRITE...
Почему так?
Если что, версия: v0.13.2-39-g1e4e2eb3
Есть "ключ", который уже содержит в себе 2 dupSort значения.
Если я выполняю вставку уже существующего 1-го зачения, то space_dirty не меняется.
Однако, если выполняю вставку существующего - 2-го ключа, то space_dirty вырастает.
Они оба уже существуют в таблице, что подтверждается флагом NO_OVERWRITE...
Почему так?
Если что, версия: v0.13.2-39-g1e4e2eb3
07:34
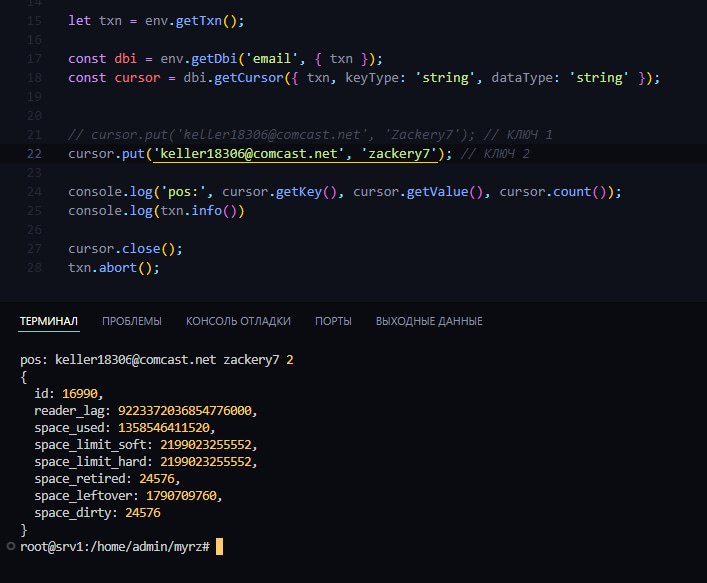
07:34
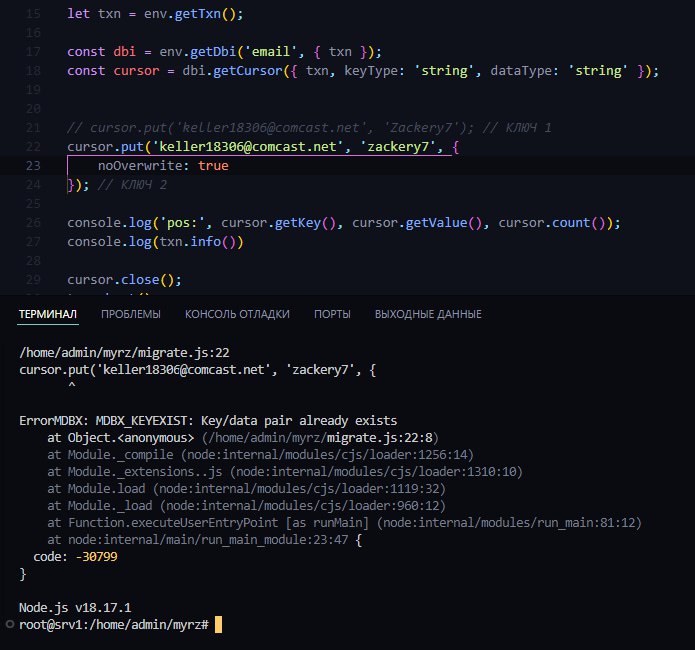
Л(
11:42
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Приветствую.
В целом движок старается избежать ненужных операций, особенно во всех случаях когда это можно сделать "бесплатно", без других дополнительных операция поиска и т.п.
Но в ситуациях когда требуются какие-то дополнительные действия возникает дилемма — стоит ли увеличивать накладные расходы для экономии в специфических случаях ?
Например, в случае с dupsort-таблицами сейчас именно так:
- При повторном помещении первого значения используются результаты поиска самого ключа (при этом поиске также возвращается первое из multi-значений). Соответственно действия прекращаются так как переданное значение уже есть (совпадает с уже получаемым), dirty-space не растет.
- А для второго значения наличие аналогичного значения обнаруживается уже после того как целевая страница (и весь стек от корня дерева) скопирован для CoW-обновления.
Это можно поправить небольшой доработкой, которую я скоро предложу вам попробовать.
Но нужно ли это вливать в master-ветку — отдельный вопрос, нужно посмотреть какой будет просадка в банчмарках.
Да, понятно что в сценариях с повторным добавлением будет сильно быстрее, но бенчмарки проверяют другие (более распространенные) случаи, и если будет заметное замедление то в master-ветку это не попадет.
Ибо если бенчмарки замедлятся, то кто-то где-то заметит это в своём простейшем сценарии и напишет "на самом деле libmdbx медленнее LMDB, я проверил, а автор врёт...".
Для устранения недостатка без замедления нужно переделывать внутреннее API курсоров.
А чтобы код при этом не стал еще больше похож на ребус, требуется делать глубокий рефакторинг с большим риском регрессов.
Думаю когда-нибудь руки дойдут, но это точно не самое важное сейчас.
В целом движок старается избежать ненужных операций, особенно во всех случаях когда это можно сделать "бесплатно", без других дополнительных операция поиска и т.п.
Но в ситуациях когда требуются какие-то дополнительные действия возникает дилемма — стоит ли увеличивать накладные расходы для экономии в специфических случаях ?
Например, в случае с dupsort-таблицами сейчас именно так:
- При повторном помещении первого значения используются результаты поиска самого ключа (при этом поиске также возвращается первое из multi-значений). Соответственно действия прекращаются так как переданное значение уже есть (совпадает с уже получаемым), dirty-space не растет.
- А для второго значения наличие аналогичного значения обнаруживается уже после того как целевая страница (и весь стек от корня дерева) скопирован для CoW-обновления.
Это можно поправить небольшой доработкой, которую я скоро предложу вам попробовать.
Но нужно ли это вливать в master-ветку — отдельный вопрос, нужно посмотреть какой будет просадка в банчмарках.
Да, понятно что в сценариях с повторным добавлением будет сильно быстрее, но бенчмарки проверяют другие (более распространенные) случаи, и если будет заметное замедление то в master-ветку это не попадет.
Ибо если бенчмарки замедлятся, то кто-то где-то заметит это в своём простейшем сценарии и напишет "на самом деле libmdbx медленнее LMDB, я проверил, а автор врёт...".
Для устранения недостатка без замедления нужно переделывать внутреннее API курсоров.
А чтобы код при этом не стал еще больше похож на ребус, требуется делать глубокий рефакторинг с большим риском регрессов.
Думаю когда-нибудь руки дойдут, но это точно не самое важное сейчас.
АК
11:52
Алексей (Keller) Костюк 😐
In reply to this message
Как вариант, дополнительным флагом во время компиляции? (либо флагом во время вставки) Соответственно перенести ответственность на тех, кто собирает библиотеку "вне стандартного сценария".
На самом деле я сейчас попробую перед вставкой проверять существует ли связка. Не знаю, насколько это сильно замедлит/ускорит вставку, но всё же лучше так, чем в лишний раз перекопировать всё дерево и отправлять на переработку, тем самым фрагментируя бд :)
(хотя мне почему-то кажется, что ускорит... Ибо повторный поиск быстрее благодаря кэшу диска... И данные не перезаписываются в пустую... Чтение всё-же быстрее записи...)
На самом деле я сейчас попробую перед вставкой проверять существует ли связка. Не знаю, насколько это сильно замедлит/ускорит вставку, но всё же лучше так, чем в лишний раз перекопировать всё дерево и отправлять на переработку, тем самым фрагментируя бд :)
(хотя мне почему-то кажется, что ускорит... Ибо повторный поиск быстрее благодаря кэшу диска... И данные не перезаписываются в пустую... Чтение всё-же быстрее записи...)
Л(
23:27
Леонид Юрьев (Leonid Yuriev)
In reply to this message
В ветку
Пожалуйста попробуйте и отпишите.
devel на Gitflic пролита предварительная версия запрошенной вами доработки.Пожалуйста попробуйте и отпишите.
10 January 2025
АК
{kind=link}
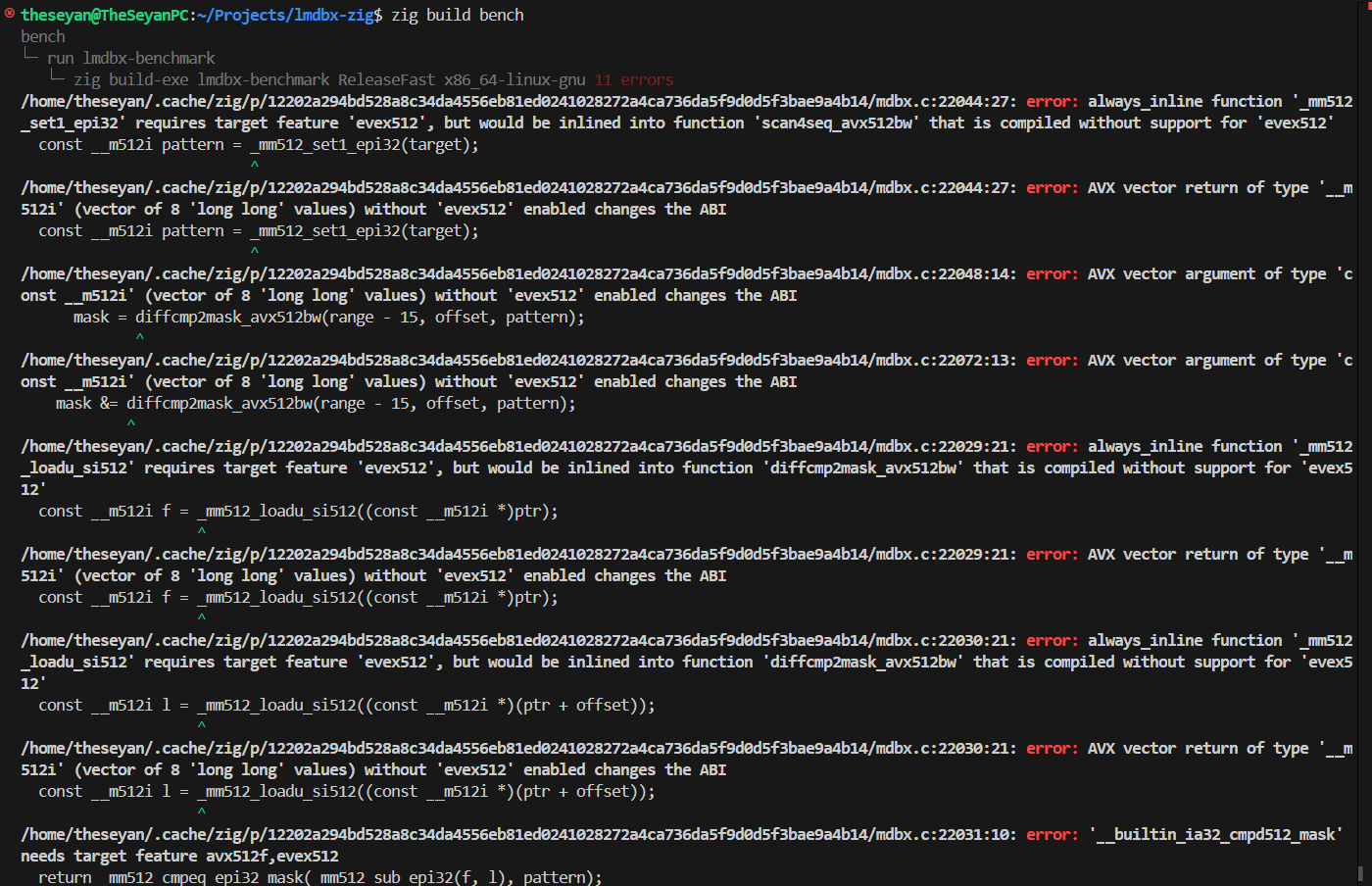{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Sudeep joined group by request
11 January 2025
Л(
13:57
Леонид Юрьев (Leonid Yuriev)
В ветке
Кроме исправлений замеченных ошибок/недочетов (спасибо @keller18306) собраны все доработки не связанные с рисками регрессов, см ChangeLog.
В ветке
1. Ранняя (не-отложенная) очистка GC и рефакторинг обновления GC, самостоятельной видимой для пользователя ценности не имеет, но требуется для последующих пунктов.
Будет реализовано в 0.14.1.
2. Явная дефрагментация БД. В API будет добавлена функция с двумя парами параметров:
- минимальный (требуемый) объем дефрагментации (уменьшения БД) и минимальное время, которое следует потратить;
- максимальный (ограничивающий) объем дефрагментации и максимальной время, которое допустимо потратить.
Упрощенно, алгоритмически явная дефрагментация сводиться к сканированию b-tree с формированием списка страниц расположенных близко к концу БД, а затем копирование этих страниц в не-используемые, но расположенные ближе к началу БД.
Будет реализовано в 0.14.2.
3. Нелинейная переработка GC, без остановки переработки мусора на старом MVCC-снимке используемом долгой транзакцией чтения.
Будет реализовано предположительно в 0.14.3, 0.14.4 или даже в 0.15.x. Перенос в 0.15.x оправдан возможностью переноса функционала дефрагментации в stable-ветку, но посмотри как пойдут дела.
---
Завтра, после выпуска 0.13.3:
- текущая ветка
- ветка
- ветка
master подготовлена версия для выпуска 0.13.3, а сам выпуск запланирован на завтра.Кроме исправлений замеченных ошибок/недочетов (спасибо @keller18306) собраны все доработки не связанные с рисками регрессов, см ChangeLog.
В ветке
devel подготовлено больше изменений, включая рефакторинг необходимый для реализации запланированных новых возможностей 0.14.x:1. Ранняя (не-отложенная) очистка GC и рефакторинг обновления GC, самостоятельной видимой для пользователя ценности не имеет, но требуется для последующих пунктов.
Будет реализовано в 0.14.1.
2. Явная дефрагментация БД. В API будет добавлена функция с двумя парами параметров:
- минимальный (требуемый) объем дефрагментации (уменьшения БД) и минимальное время, которое следует потратить;
- максимальный (ограничивающий) объем дефрагментации и максимальной время, которое допустимо потратить.
Упрощенно, алгоритмически явная дефрагментация сводиться к сканированию b-tree с формированием списка страниц расположенных близко к концу БД, а затем копирование этих страниц в не-используемые, но расположенные ближе к началу БД.
Будет реализовано в 0.14.2.
3. Нелинейная переработка GC, без остановки переработки мусора на старом MVCC-снимке используемом долгой транзакцией чтения.
Будет реализовано предположительно в 0.14.3, 0.14.4 или даже в 0.15.x. Перенос в 0.15.x оправдан возможностью переноса функционала дефрагментации в stable-ветку, но посмотри как пойдут дела.
---
Завтра, после выпуска 0.13.3:
- текущая ветка
stable пойдет в архив как архив/0.12;- ветка
master станет stable, где будет продолжена поддержка линейки 0.13.x;- ветка
devel будет влита в master, а дальше в devel будет продолжена разработка 0.14.x.
👍
e
5
🔥
SD
e
4
АК
14:45
Алексей (Keller) Костюк 😐
In reply to this message
Получается "не-используемые" - это которые находятся в GC? Но а если таких нет, то дефрагментация невозможна?
14:59
Помню использовал Auslogics Disk Defrag. Особенность в том, что она визуально отображает процесс дефрагментации.
Так там было так, что сперва освобождалось место в начале, копируя всё в конец или раскидывая по свободным местам на диске.
А потом всё постепенно перемещалось в начало диска в нужном порядке
Так там было так, что сперва освобождалось место в начале, копируя всё в конец или раскидывая по свободным местам на диске.
А потом всё постепенно перемещалось в начало диска в нужном порядке
Л(
15:10
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Тут видимо не совсем уместно использовать термин "дефрагментация", ибо b-tree не возможно (а главное бессмысленно) выпрямлять в линейную/упорядоченную форму.
Тем не менее, если разделить страницы только на "используемые" и "не используемые", то можно дефрагментировать используемое пространство, т.е. "выдавить" из него не-используемые страницы и уменьшить размер файла БД.
Кроме этого, возможна "дефрагментация" последовательностей не-используемых страниц для размещения длинных/больших кусков данных. От описанной выше алгоритмики отличается только выбором/фильтрацией используемых страниц для CoW-копирования (с целью их освобождения).
Тем не менее, если разделить страницы только на "используемые" и "не используемые", то можно дефрагментировать используемое пространство, т.е. "выдавить" из него не-используемые страницы и уменьшить размер файла БД.
Кроме этого, возможна "дефрагментация" последовательностей не-используемых страниц для размещения длинных/больших кусков данных. От описанной выше алгоритмики отличается только выбором/фильтрацией используемых страниц для CoW-копирования (с целью их освобождения).
АК
15:24
Алексей (Keller) Костюк 😐
Ещё же, как я понял, есть пустое/зарезервированное место в самих страницах. Его же тоже можно по идее вытеснять? Или от этого нет смысла?
Л(
15:41
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Страницы заполняются "встречно", данными переменной длины с конца к началу и смещениями/индексами к этим данным от начала к концу.
Поэтому в середине большинства страниц действительно есть неиспользуемое место.
Но дефрагментировать содержимое страниц есть смысл только если в дальнейшем НЕ предполагается вставка данных или их обновление с увеличением длины.
Иначе после дефрагментации первое-же обновление потребует разделения листовой страницы и почти всех родительских, так как в них нет места.
И такое будет продолжаться пока ситуация не вернется к исходной до дефрагментации.
При желании/любопытстве ситуацию можно пощупать/попробовать уже сейчас без особых усилий — достаточно сделать дамп базы посредством
Поэтому в середине большинства страниц действительно есть неиспользуемое место.
Но дефрагментировать содержимое страниц есть смысл только если в дальнейшем НЕ предполагается вставка данных или их обновление с увеличением длины.
Иначе после дефрагментации первое-же обновление потребует разделения листовой страницы и почти всех родительских, так как в них нет места.
И такое будет продолжаться пока ситуация не вернется к исходной до дефрагментации.
При желании/любопытстве ситуацию можно пощупать/попробовать уже сейчас без особых усилий — достаточно сделать дамп базы посредством
mdbx_dump и восстановить посредством mdbx_load -a.
АК
15:48
Алексей (Keller) Костюк 😐
In reply to this message
Да, я же копировался от lmdb с помощью mdb_load. И сейчас начал объединение двух бд mdbx. И понял, что общий их размер без учёта GC начал расти (хотя я даже думал, что будет уменьшаться, ибо будут удаляться индексы специфичные для нашего проекта). Подумав я как раз и понял, что это из-за деления страниц на два.
Возможно поэтому на LMDB размер всех данных был 1.8тб, а при миграции на Mdbx через append все пустоты удалились...
Если очень грубо посчитать: если я объединяю бд в 200 гигов в общую, которая компактно забита, то в теории размер общей бд вырастет на 400 в самом худшем случаи
Возможно поэтому на LMDB размер всех данных был 1.8тб, а при миграции на Mdbx через append все пустоты удалились...
Если очень грубо посчитать: если я объединяю бд в 200 гигов в общую, которая компактно забита, то в теории размер общей бд вырастет на 400 в самом худшем случаи
Л(
17:48
Леонид Юрьев (Leonid Yuriev)
@keller18306, на всякий напоминаю, что в
devel-ветке я переписываю историю, и достаточно часто (особенно при рефакторинге и сортировке коммитов перед релизами).
АК
Л(
SD
23:42
Sayan J. Das
Hi, is it correct that inserting data in sorted order by key (not MDBX_APPEND, just writes) helps in reducing extra space and fragmentation (other than improving performance)?
i.e in the final B-tree, is there a difference if I insert in this order of keys: 1 -> 9 -> 5 -> 2
And this order: 1 -> 2 -> 5 -> 9
i.e in the final B-tree, is there a difference if I insert in this order of keys: 1 -> 9 -> 5 -> 2
And this order: 1 -> 2 -> 5 -> 9
23:51
In my testing, I've noticed that it's always faster to sort the data in memory before committing the transaction
12 January 2025
b
00:11
basiliscos
00:12
не подскажете что делать/куда смотреть? Появляется только в win32 для winxp сборки (32 бита)... 0.13.2
Л(
00:26
Леонид Юрьев (Leonid Yuriev)
In reply to this message
I already answered this question once, and for some reason it seems to me that it was for you ;)
Inserting data means that the pages in the b-tree will fill up and they will have to be splitted.
When inserting unsorted data (in random order or close), the key is inserted in most cases not at the edge of the page. Therefore, for most inserts leading to page split, it will occur close to the middle of a page (since it is the most optimal strategy). Then after insertion, instead of one filled page, there will be two filled by about 50%. Thus, the average page occupancy in DB will be between 50% and 100%, i.e. approximately 75%.
When inserting a large amount of sorted data, in most cases the key insertion will be occured either at the beginning or at the end of the pages, i.e. close to the edge of the page. In this case, it can be assumed that it is the sorted data that is being inserted (and will be continue), and then you can divide the pages not in the middle, but so that one page is almost full, and the other is where the data will be inserted next — empty or almost empty. When inserting sorted data, this is a more optimal strategy, as a result of which the pages will be almost completely filled, i.e. there will be fewer of ones. This is exactly what happens in libmdbx.
Inserting data means that the pages in the b-tree will fill up and they will have to be splitted.
When inserting unsorted data (in random order or close), the key is inserted in most cases not at the edge of the page. Therefore, for most inserts leading to page split, it will occur close to the middle of a page (since it is the most optimal strategy). Then after insertion, instead of one filled page, there will be two filled by about 50%. Thus, the average page occupancy in DB will be between 50% and 100%, i.e. approximately 75%.
When inserting a large amount of sorted data, in most cases the key insertion will be occured either at the beginning or at the end of the pages, i.e. close to the edge of the page. In this case, it can be assumed that it is the sorted data that is being inserted (and will be continue), and then you can divide the pages not in the middle, but so that one page is almost full, and the other is where the data will be inserted next — empty or almost empty. When inserting sorted data, this is a more optimal strategy, as a result of which the pages will be almost completely filled, i.e. there will be fewer of ones. This is exactly what happens in libmdbx.
👍
SD
00:30
In reply to this message
Варианта примерно два:
1. Предоставить изолированный минимальный сценарий воспроизведения, лучше на C++ API.
2. Пробовать самостоятельно:
- взять текущую master-ветку;
- собрать с опцией MDBX_DEBUG=2, это включит максимум проверок (но может сильно медленно);
- установить логгер и смотреть что происходит (может быть уменьшить детализацию логирования, хотя-бы в начале).
1. Предоставить изолированный минимальный сценарий воспроизведения, лучше на C++ API.
2. Пробовать самостоятельно:
- взять текущую master-ветку;
- собрать с опцией MDBX_DEBUG=2, это включит максимум проверок (но может сильно медленно);
- установить логгер и смотреть что происходит (может быть уменьшить детализацию логирования, хотя-бы в начале).
b
00:37
basiliscos
In reply to this message
нашёл приблизительно. Уже 2-й раз сталкиваюсь (до этого было boost-filesystem): если запущаю тесты на замапленном VirtualBox в винду диске с (linux:
Багу заводил на VirtualBox... но это ж Оракл, они просто забили, даже ничего не сказали.
/tmp, windows: t:\), то выстреливает ошибка выше. Если всё копирую на c:\ и оттуда запускаю - всё ок. Багу заводил на VirtualBox... но это ж Оракл, они просто забили, даже ничего не сказали.
Л(
00:48
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Ох, так это вариант работы с БД на "сетевом диске"...
По-хорошему нужно в
Если будет возможность, то попробуйте по-отлаживаться и собрать информацию.
Хотя-бы просто пройти по шагам функцию
Но если не удастся надежно обнаруживать такие ситуации под WinXP, то я просто откажусь от её поддержки в
По-хорошему нужно в
osal_check_fs_local() добавить проверку этого случая (замапленый в винду диск linux) и возвращать ошибку при открытии БД.Если будет возможность, то попробуйте по-отлаживаться и собрать информацию.
Хотя-бы просто пройти по шагам функцию
osal_check_fs_local(), посмотреть какие есть системные функции и что они возвращают.Но если не удастся надежно обнаруживать такие ситуации под WinXP, то я просто откажусь от её поддержки в
0.14.x, т.е. оставлю в минимальных требованиях 7-ку или даже 10-ку.
b
00:54
basiliscos
хорошо, попробую. Скорей всего не специфичная для xp штука (я просто нативные тесты запускал на диске).
00:54
Попробую завтра отладить
Л(
00:58
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Дело не в этом, не важно специфично это или нет.
Тут дело в том, что "не работает", и нужно определять эту ситуацию и возвращать ошибку, либо вообще отказываться от поддержки WinXP (в текущем понимании на актуальных версиях винды проверка срабатывает, а на XP нет, ибо нет нужных функций в API и т.п.).
Тут дело в том, что "не работает", и нужно определять эту ситуацию и возвращать ошибку, либо вообще отказываться от поддержки WinXP (в текущем понимании на актуальных версиях винды проверка срабатывает, а на XP нет, ибо нет нужных функций в API и т.п.).
👌
b
b
17:59
basiliscos
In reply to this message
дело не в XP, как я писал ранее. Сделал 64-битный бинарь и запускаю его в VirtualBox в win10 на примаунченном диске, таже ошибка.
Л(
18:12
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Принято. Тогда еще более нужна ваша помощь с отладкой.
Л(
19:43
Леонид Юрьев (Leonid Yuriev)
libmdbx 0.13.3 "Королёв".
Поддерживающий выпуск с исправлением обнаруженных ошибок и устранением недочетов в день рождения и в память об Серге́е Па́вловиче Королёве, советском учёном и Главном конструкторе ракетно-космических систем.
https://gitflic.ru/project/erthink/libmdbx/release/d2a2c8cb-7d60-4d2a-aea7-b75a79c2adaa
Поддерживающий выпуск с исправлением обнаруженных ошибок и устранением недочетов в день рождения и в память об Серге́е Па́вловиче Королёве, советском учёном и Главном конструкторе ракетно-космических систем.
67 files changed, 3514 insertions(+), 3004 deletions(-)https://gitflic.ru/project/erthink/libmdbx/release/d2a2c8cb-7d60-4d2a-aea7-b75a79c2adaa
14 January 2025
Syntezoid Zografos joined group by request
MI
22:46
Marin Ivanov
In reply to this message
{kind=link}
The old emblem of my high school - PMG "Akad. Sergey Pavlovich Korolyov", Blagoevgrad.
👍
LP
🤝
Л(
15 January 2025
Л(
17:30
Леонид Юрьев (Leonid Yuriev)
In reply to this message
Запрошенные вами доработки сейчас в ветке
Поэтому с очень большой вероятностью эти доработки в текущем виде попадут в ближайшие релизы.
Т.е. ими уже можно пользоваться, и история переписываться не будет.
Тем не менее, на микро-бенчмарках снижение производительности всё-таки есть.
Примерно на один лишний вызов функции-компаратора для каждой вставки данных.
Это можно и нужно починить, но займусь этим после текущих переделок GC.
master и в текущем понимании не приводят к заметному снижению производительность.Поэтому с очень большой вероятностью эти доработки в текущем виде попадут в ближайшие релизы.
Т.е. ими уже можно пользоваться, и история переписываться не будет.
Тем не менее, на микро-бенчмарках снижение производительности всё-таки есть.
Примерно на один лишний вызов функции-компаратора для каждой вставки данных.
Это можно и нужно починить, но займусь этим после текущих переделок GC.
👍
YS
e
MI
6
Андрей joined group by request
16 January 2025
b
23:37
basiliscos
Проапгрейдился до
0.13.3, всё отлично. Отдельное спасибо за "Если посредством mdbx_env_set_option(MDBX_opt_txn_dp_limit) пользователем не задано собственно значение, то выполняется подстройка dirty-pages-limit" - огонь опция. Для end-user GUI приложений, самое то!
🤝
w
Л(